netty源码解解析(4.0)-18 ChannelHandler: codec--编解码框架
编解码框架和一些常用的实现位于io.netty.handler.codec包中。
编解码框架包含两部分:Byte流和特定类型数据之间的编解码,也叫序列化和反序列化。不类型数据之间的转换。
下图是编解码框架的类继承体系:
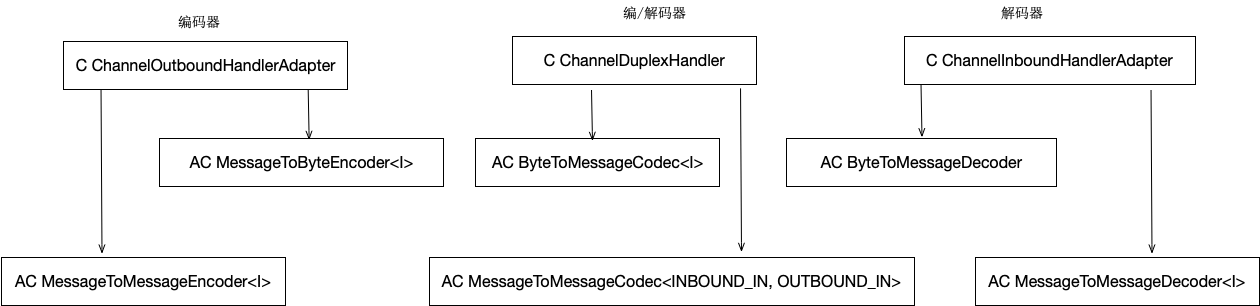
其中MessageToByteEncoder和ByteToMessageDecoder是实现了序列化和反序列化框架。 MessageToMessage是不同类型数据之间转换的框架。
序列化抽象实现: MessageToByteEncoder<I>
序列化是把 I 类型的数据转换成Byte流。这个抽象类通过实现ChannelOutboundHandler的write方法在写数据时把 I 类型的数据转换成Byte流,下面是write方法的实现:
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
buf = allocateBuffer(ctx, cast, preferDirect);
try {
encode(ctx, cast, buf);
} finally {
ReferenceCountUtil.release(cast);
} if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
if (buf != null) {
buf.release();
}
}
}
5行, 检查msg的类型,如果是 I 类型返回true, 否则返回false。
7-10行, 分配一块buffer, 并调用encode方法把msg编码成Byte流放进这个buffer中。
15-19行,对含有Byte流程数据的buffer继续执行写操作。(不清楚写操作流程的可以参考<<netty源码解解析(4.0)-15 Channel NIO实现:写数据>>)
23行,如果msg不是 I 类型,跳过这个Handler, 继续执行写操作。
这里调用的encode方法是一个抽象方法,留给子类实现定制的序列化操作。
反序列化抽象实现: ByteToMessageDecoder
这个抽象类型解决的主要问题是从Byte流中提取数据包。数据包是指刚好可以反序列化成一个特定类型Message的Byte数组。但是在数据包长度不确定的情况下,没办法每次刚好从Byte流中刚好分离一个数据包。每次从Byte流中读取数据有多种可能:
- 刚好是一个或多个完整的数据包。
- 不足一个完整的数据包,或错误的数据。
- 包含一个或多个完整的数据包,但有多余的数据不足一个完整的数据包或错误的数据。
这个问题本质上和"TCP粘包"问题相同。解决这个问题有两个关键点:
- 能够确定数据包在Byte流中的开始位置和长度。
- 需要暂时缓存不完整的数据包,等待后续数据拼接完整。
关于第(1)点,在这个抽象类中没有处理,只是定义了一个抽象方法decode,留给子类处理。关于第(2)点,这个类定义了一个Cumulator(堆积器)来处理,把不完整的数据包暂时堆积到Cumulator中。Cumulator有两个实现: MERGE_CUMULATOR(合并堆积器),COMPOSITE_CUMULATOR(组合堆积器)。默认使用的是MERGE_CUMULATOR。下面详细分析一下这两种Cumulator的实现。
MERGE_CUMULATOR的实现
这是一个合并堆积器,使用ByteBuf作为堆积缓冲区,把通过把数据写到堆积缓冲实现新旧数据合并堆积。
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
final ByteBuf buffer;
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation instanceof ReadOnlyByteBuf) {
// Expand cumulation (by replace it) when either there is not more room in the buffer
// or if the refCnt is greater then 1 which may happen when the user use slice().retain() or
// duplicate().retain() or if its read-only.
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
buffer.writeBytes(in);
in.release();
return buffer;
}
4-13行,如果当前的堆积缓冲区不能用了,分配一块新的,把旧缓冲区中的数据转移到新缓冲区中,并用新的替换旧的。当前堆积缓冲区不能用的条件是:
cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes(): 容量不够
或者 cumulation.refCnt() > 1 : 在其他地方本引用
或者 cumulation instanceof ReadOnlyByteBuf 是只读的
17行,把数据追加到堆积缓冲区中。
COMPOSITE_CUMULATOR的实现
这是一个合并堆积器,和MERGE_CUMULATOR不同的是他使用的是CompositeByteBuf作为堆积缓冲区。
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
if (cumulation.refCnt() > 1) {
// Expand cumulation (by replace it) when the refCnt is greater then 1 which may happen when the user
// use slice().retain() or duplicate().retain().
//
// See:
// - https://github.com/netty/netty/issues/2327
// - https://github.com/netty/netty/issues/1764
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
buffer.writeBytes(in);
in.release();
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
composite.addComponent(true, in);
buffer = composite;
}
return buffer;
}
4-13行,和MERGE_CUMULATOR一样。
15-23行,如果当前的堆积缓冲区不是CompositeByteBuf类型,使用一个新的CompositeByteBuf类型的堆积缓冲区代替,并把数据转移的新缓冲区中。
分离数据包的主流程
ByteToMessageDecoder是ChannelInboundHandlerAdapter的派生类,它通过覆盖channelRead实现了反序列化的主流程。这个主流程主要是对堆积缓冲区cumulation的管理,主要步骤是:
- 把Byte流数据追加到cumulation中。
- 调用decode方法从cumulation中分离出完整的数据包,并把数据包反序列化成特定类型的数据,直到不能分离数据包为止。
- 检查cumulation,如果没有剩余数据,就销毁掉这个cumulation。否则,增加读计数。如果读计数超过丢弃阈值,丢掉部分数据,这一步是为了防止cumulation中堆积的数据过多。
- 把反序列化得到的Message List传递到pipeline中的下一个ChannelInboundHandler处理。
由于使用了cumulation,ByteToMessageDecoder就变成了一个有状态的ChannelHandler, 它必须是独占的,不能使用ChannelHandler.@Sharable注解。
在channelRead中,并没有直接调用decode方法,而是通过callDecode间接调用。而callDecdoe也不是直接调用,而是调用了decodeRemovalReentryProtection方法,这个方法只是对decode调用的简单封装。参数in是堆积缓冲区cumulation。 这个方法主要实现上面描述的第2个步骤。
//在channelRead中调用方式:callDecode(ctx, cumulation, out);
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
while (in.isReadable()) {
int outSize = out.size(); if (outSize > 0) {
fireChannelRead(ctx, out, outSize);
out.clear(); // Check if this handler was removed before continuing with decoding.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See:
// - https://github.com/netty/netty/issues/4635
if (ctx.isRemoved()) {
break;
}
outSize = 0;
} int oldInputLength = in.readableBytes();
decodeRemovalReentryProtection(ctx, in, out); // Check if this handler was removed before continuing the loop.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See https://github.com/netty/netty/issues/1664
if (ctx.isRemoved()) {
break;
} if (outSize == out.size()) {
if (oldInputLength == in.readableBytes()) {
break;
} else {
continue;
}
} if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
} if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Exception cause) {
throw new DecoderException(cause);
}
}
5-19行,如果已经成功分离出了至少一个数据包并成功反序列化,就调用fireChannelRead把得到的Message传递给pipeline中的下一个Handler处理。fireChannelRead会对out中的每一个Message调用一次ctx.fireChannelRead。
22,23行,先记下in中的数据长度,再执行反序列化操作。
33,39行,如果outSize == out.size()(没有反序列化到新的Message), 且oldInputLength == in.readableBytes()(in中的数据长度没有变化)表示in中的数据不足以完成一次反序列化操作,跳出循环。否则,继续。
41行,出现了异常,完成了一次反序列化操作,但in中的数据没变化,凭空多了(或少了)一些反序列化的后Message。
同时可以进行序列化和反序列化的抽象类: ByteToMessageCodec<I>
这个类是ChannelDuplexHandler的派生类,可以同时序列化和反序列化操作。和前面两个类相比,它没什么特别是实现,内部使用MessageToByteEncoder<I>
序列化,使用ByteToMessageDecoder反序列化。
类型转换编码的抽象实现: MessageToMessageEncoder<I>
这个类是ChannelOutboundHandlerAdapter的派生类,它在功能是在write过程中,把 I 类型的数据转换成另一种类型的数据。它定义了抽象方法encode,有子类负责实现具体的转换操作。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
CodecOutputList out = null;
try {
if (acceptOutboundMessage(msg)) {
out = CodecOutputList.newInstance();
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
encode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
} if (out.isEmpty()) {
out.recycle();
out = null; throw new EncoderException(
StringUtil.simpleClassName(this) + " must produce at least one message.");
}
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable t) {
throw new EncoderException(t);
} finally {
if (out != null) {
final int sizeMinusOne = out.size() - 1;
if (sizeMinusOne == 0) {
ctx.write(out.get(0), promise);
} else if (sizeMinusOne > 0) {
// Check if we can use a voidPromise for our extra writes to reduce GC-Pressure
// See https://github.com/netty/netty/issues/2525
ChannelPromise voidPromise = ctx.voidPromise();
boolean isVoidPromise = promise == voidPromise;
for (int i = 0; i < sizeMinusOne; i ++) {
ChannelPromise p;
if (isVoidPromise) {
p = voidPromise;
} else {
p = ctx.newPromise();
}
ctx.write(out.getUnsafe(i), p);
}
ctx.write(out.getUnsafe(sizeMinusOne), promise);
}
out.recycle();
}
}
}
6-12行,如果msg是 I 类型的数据,调用encode把它转换成另一种类型。
16-20行,如果没有转换成功,抛出异常。
23行, 如果msg不是 I 类型,跳过当前的Handler。
31-50, 如果转换成功,把转换后的数据传到到下一个Handler处理。33行处理只有一个转换结果的情况。37-48行处理有多个转换结果的情况。
类型转换解码的抽象实现: MessageToMessageDecoder<I>
这个类是ChannelInboundHandlerAdapter的派生类,它的功能是在read的过程中,把 I 类型的数据转换成另一种类型的数据。它定义了抽象方法decode,有子类负责实现具体的转换操作。它的channelRead和上面的类实现相似,但更简单,这里就不再分析源码了。
类型转换编解码的抽象实现: MessageToMessageCodec<INBOUND_IN, OUTBOUND_IN>
这个类是ChannelDuplexHandler的派生类,它的功能是在write过程中把OUTBOUND_IN类型的数据转换成INBOUND_IN类型的数据,在read过程中进程相反的操作。它没有特别的实现,内部使用前面的两个类实现编解码。
netty源码解解析(4.0)-18 ChannelHandler: codec--编解码框架的更多相关文章
- netty源码解解析(4.0)-17 ChannelHandler: IdleStateHandler实现
io.netty.handler.timeout.IdleStateHandler功能是监测Channel上read, write或者这两者的空闲状态.当Channel超过了指定的空闲时间时,这个Ha ...
- netty源码解解析(4.0)-20 ChannelHandler: 自己实现一个自定义协议的服务器和客户端
本章不会直接分析Netty源码,而是通过使用Netty的能力实现一个自定义协议的服务器和客户端.通过这样的实践,可以更深刻地理解Netty的相关代码,同时可以了解,在设计实现自定义协议的过程中需要解决 ...
- netty源码解解析(4.0)-19 ChannelHandler: codec--常用编解码实现
数据包编解码过程中主要的工作就是:在编码过程中进行序列化,在解码过程中从Byte流中分离出数据包然后反序列化.在MessageToByteEncoder中,已经解决了序列化之后的问题,ByteToMe ...
- netty源码解解析(4.0)-16 ChannelHandler概览
本章开始分析ChannelHandler实现代码.ChannelHandler是netty为开发者提供的实现定制业务的主要接口,开发者在使用netty时,最主要的工作就是实现自己的ChannelHan ...
- netty源码解解析(4.0)-11 Channel NIO实现-概览
结构设计 Channel的NIO实现位于io.netty.channel.nio包和io.netty.channel.socket.nio包中,其中io.netty.channel.nio是抽象实 ...
- netty源码解解析(4.0)-10 ChannelPipleline的默认实现--事件传递及处理
事件触发.传递.处理是DefaultChannelPipleline实现的另一个核心能力.在前面在章节中粗略地讲过了事件的处理流程,本章将会详细地分析其中的所有关键细节.这些关键点包括: 事件触发接口 ...
- netty源码解解析(4.0)-15 Channel NIO实现:写数据
写数据是NIO Channel实现的另一个比较复杂的功能.每一个channel都有一个outboundBuffer,这是一个输出缓冲区.当调用channel的write方法写数据时,这个数据被一系列C ...
- netty源码解解析(4.0)-14 Channel NIO实现:读取数据
本章分析Nio Channel的数据读取功能的实现. Channel读取数据需要Channel和ChannelHandler配合使用,netty设计数据读取功能包括三个要素:Channel, Eve ...
- netty源码解解析(4.0)-12 Channel NIO实现:channel初始化
创建一个channel实例,并把它register到eventLoopGroup中之后,这个channel然后处于inactive状态,仍然是不可用的.只有在bind或connect方法调用成功之后才 ...
随机推荐
- android_MultiAutoCompleteTextView
package cn.com.sxp;import android.app.Activity;import android.os.Bundle;import android.view.View;imp ...
- javascript案例之放大镜效果
效果图 如何实现该效果呢?? 我们先来进行分析 实现思路 1.鼠标移入移出事件 1>移入:悬浮块和大图显示 2>移出:悬浮块和大图隐藏 2.鼠标移动(悬浮块随着鼠标移动) 1>获 ...
- 第一届合天杯河北科技大学网络安全技术大赛 web6 writeup
- 一个测试文件与源文件位于不同模块时Jacoco覆盖率配置的例子
问题描述: 我们有个多模块项目,由于种种原因(更常见的可能是需要集成测试)测试文件和源文件不在一个模块,Jacoco的覆盖率无法正确显示,查询了一些资料,发现中文的例子比较少,就把我自己的Demo贴一 ...
- C#3.0新增功能05 分部方法
连载目录 [已更新最新开发文章,点击查看详细] 分部类或结构可以包含分部方法. 类的一个部分包含方法的签名. 可以在同一部分或另一个部分中定义可选实现. 如果未提供该实现,则会在编译时删除 ...
- Java EE.JSP.概述
JSP最终会被转换成标准Servlet,该转换过程一般出现在第一次请求页面时. JSP页面的主要组成部分如下: HTML 脚本:嵌入Java代码 指令:从整体上控制Servlet的结构 动作:引入现有 ...
- PHP 防范xss攻击(转载)
XSS 全称为 Cross Site Scripting,用户在表单中有意或无意输入一些恶意字符,从而破坏页面的表现! 看看常见的恶意字符XSS 输入: 1.XSS 输入通常包含 JavaScript ...
- Linux系统命令。
help:命令用于显示shell内部命令的帮助信息.help命令只能显示shell内部的命令 帮助信息.而对于外部命令的帮助信息只能使用man或者info命令查看 m ...
- 【iOS】UIAlertController 弹出框
UIAlertView 虽然还能用,但已经废弃了.因此以后尽量用 UIAlertController.示例代码如下: UIAlertController *alert = [UIAlertContro ...
- .NET Core on K8S学习实践系列文章索引(Draft版)
一.关于这个系列 自从去年(2018年)底离开工作了3年的M公司加入X公司之后,开始了ASP.NET Core的实践,包括微服务架构与容器化等等.我们的实践是渐进的,当我们的微服务数量到了一定值时,发 ...