Hadoop_简介_01
1. Apache Hadoop
1.1 Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现的开源软件框架, 是一个开发和运行处理大规模数据的软件平台. 允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理. Hadoop不会跟某种具体的行业或者某个具体的业务挂钩, 他只是一种用来做海量数据分析处理的工具.

狭义上说, Hadoop指Apache这款开源框架, 其核心组件有:
HDFS (分布式文件系统) : 解决海量数据存储
YARN (作业调度和集群资源管理的框架) : 解决资源任务调度
MAPREDUCE (分布式运算编程框架) : 解决海量数据计算
广义上说, Hadoop通常是指一个更广泛的概念 -- Hadoop生态圈.
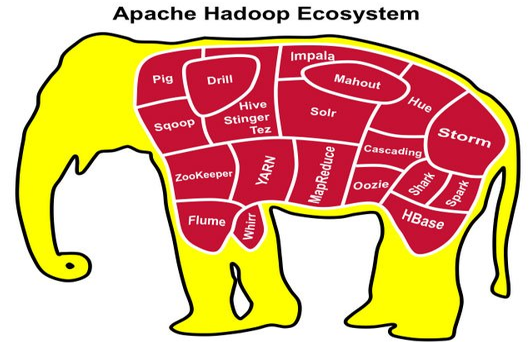
当下的Hadoop已经成长为一个庞大的体系.
HDFS: 分布式文件系统
MAPREDUCE: 分布式运算程序开发框架
HIVE: 基于Hadoop的分布式数据仓库, 提供基于SQL的查询数据操作
HBASE: 基于Hadoop的分布式海量数据数据库
ZOOKEEPER: 分布式协调服务基础组件
Mahout: 基于MR / Spark / Flink等分布式运算框架的机器学习算法库
OOZIE: 工作流调度框架
SQOOP: 数据导入导出工具 (比如用于mysql和HDFS之间)
FLUME: 日志数据采集框架
IMPALA: 基于Hive的实时sql查询分析
1.2 Hadoop发展简史
三篇Google论文:
1) 2003年Google发表的第一篇论文: GFS (Google分布式文件系统)
2) 2004年Google发表的第二篇论文: Google的MapReduce解决海量数据计算
同一时期,Doug Cutting基于Google的两篇论文开发出: HDFS (Hadoop的分布式文件系统) , MapReduce (基于Hadoop的分布式计算平台) 成为Apache的顶级项目.
3) 2006年Google发表的第三篇论文: BigTable, 开源界根据论文开发了HBase (基于Hadoop的分布式数据库) .
1.3 Hadoop特性优点
1) 扩容能力: Hadoop是在可用的计算机集群间分配数据并完成计算任务的, 这些集群可用方便的扩展到数以千计的节点中.
2) 成本低: Hadoop通过廉价的机器组成服务器集群来分发以及处理数据, 以至于成本很低.
3) 高效率: 通过并发数据,Hadoop可以在节点之间动态并行的移动数据, 使得速度非常快.
4) 可靠性: 能自动维护数据的多份复制, 并且在任务失败后自动的重新部署计算任务. 所以Hadoop的按位存储和处理数据的能力值得信赖.
2. Hadoop集群
2.1 发行版本
分为开源社区版和商业版
社区版: 由Apache软件基金会维护的版本, 是官方维护的版本体系.
优点: 功能最新, 免费.
缺点: 稳定性差, 兼容性差.
商业版: 由第三方商业公司在社区版基础上进行一些修改, 整合以及各个服务组件兼容性测试而发行的版本, 比如著名的cloudera的CDH, mapR, hortonWorks等.
优点: 稳定性好, 软件兼容性好.
缺点: 收费, 暂时不能使用最新的Hadoop版本.
Hadoop版本特殊, 是由多条分支并行的发展, 大的来看分为3个大的系列版本: 1.x, 2.x, 3.x.
Hadoop1.x由一个分布式文件系统HDFS和一个离线计算框架MR组成.
Hadoop2.x包含一个支持NameNode横向扩展的HDFS, 一个资源管理系统YARN和一个运行在YARN上的离线计算框架MR. 相比于Hadoop1.x, Hadoop2.x功能更加强大, 且具有更好的扩展性, 性能, 并支持多种计算框架. 现在是企业主流版本.
Hadoop3.x相比之前的Hadoop2.x有一系列的功能增强. 目前已经趋于稳定, 但是整个生态圈体系升级整合还未完毕, 所以商用还值得商榷.
2.2 集群简介
Hadoop集群具体来说包含两个集群: HDFS集群, YARN集群, 两者逻辑上分离, 但物理上常在一起.
1) HDFS集群负责海量数据的存储, 集群中的角色主要有: NameNode, DataNode, SecondaryNameNode.
2) YARN集群负责海量数据运算时的资源调度, 集群中的角色主要有: ResourceManager, NodeManager.
其中MR其实是一个分布式运算编程框架, 是应用程序开发包, 由用户按照编程规范进行程序开发, 后打包运行在HDFS集群上, 并且受到YARN集群的资源调度管理.
Hadoop部署方式分四种: Standalone mode (独立模式) , Pseudo-Distributed mode (伪分布式模式) , Cluster mode (集群模式) , HA high availability (高可用集群模式) 其中前两种都是在单机部署.
1) 独立模式又称为单机模式, 仅1个机器运行1个Java进程, 主要用于调试.
2) 伪分布模式也是在1个机器运行HDFS的NameNode和DataNode, YARN的ResourceManager和NodeManager, 但分别启动单独的Java进程, 主要用于调试.
3) 集群模式主要用于生产环境部署. 会使用N台主机组成一个集群, 这种部署模式下, 主节点和从节点会分开部署在不同的机器上.
4) 高可用集群模式主要解决单点故障, 保证集群的高可用, 提高可靠性
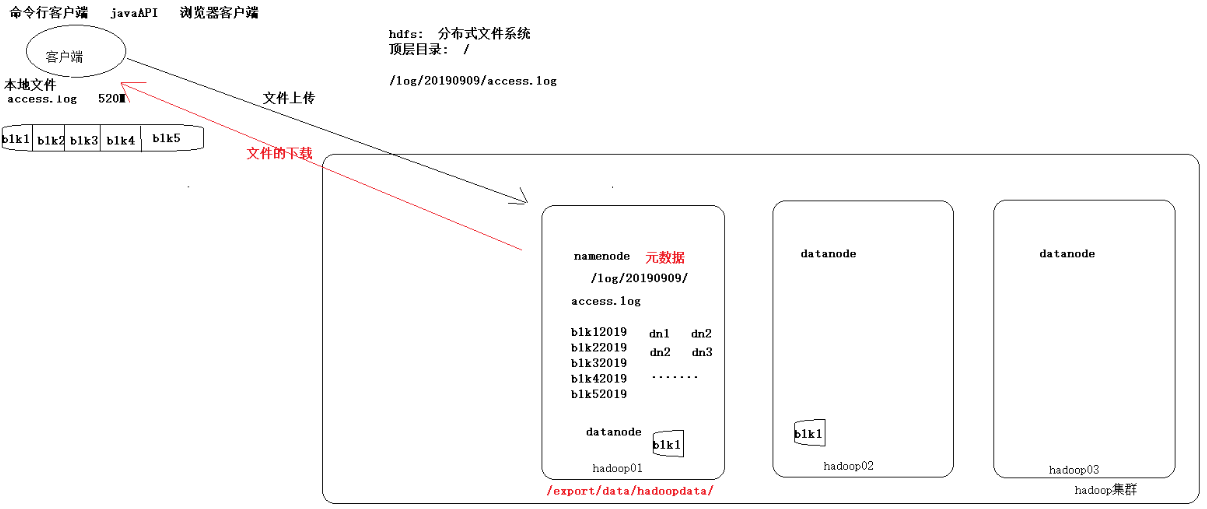
HDFS集群 (主从架构) :
主角色: NameNode (nn)
从角色: DataNode (dn)
主角色的辅助角色: SecondaryNameNode (snn)
YARN集群 (主从架构) :
主角色: ResourceManager (rm)
从角色: NodeManager (nm)
MR需要开发的程序组件:
Map组件
Reduce组件
Hadoop角色分布图:

HDFS原理图简单分析:
2.3 为什么CDH版本Hadoop要重新编译?
由于CDH的所有安装包版本都给出了对应的软件版本, 一般情况下是不需要自己进行编译的, 但是由于CDH给出的Hadoop的安装包没有提供带C程序访问的借口, 所有我们在使用本地库的时候就会出现问题. (本地库: 可以用来做压缩, 以及支持C程序等等)
1) Hadoop是使用Java语言开发的, 但是有一些需求和操作并不适合使用java, 所以就引入了本地库 (Native Libraries) 的概念. 说白了, 就是Hadoop的某些功能, 必须通过JNT来协调Java类文件和Native代码生成的库文件一起才能工作.
2) linux系统要运行Native代码, 首先要将Native编译成目标CPU架构的 [.so] 文件. 而不同的处理器架构, 需要编译出相应平台的动态库 [.so] 文件, 才能被正确的执行, 所以最好重新编译一次hadoop源码, 让 [.so] 文件与自己处理器相对应. 注意: windows平台是动态库 [.dll] 文件
总结: 主要是要重新编译本地库 (Native Libraries) 代码 (Linux下对应 [.so] 文件,window下对应 [.dlI] 文件) , 也就是编译生成linux下的 [.so] 文件.
源码编译后压缩包路径:

源码编译后结果:
2.4 Hadoop安装包目录结构
目录结构如下:
bin: Hadoop最基本的管理脚本和使用脚本的目录.
etc: Hadoop配置文件所在的目录.
include: 对外提供的编程库头文件 (具体动态库和静态库在lib目录中) .
lib: 包含了Hadoop对外提供的编程动态库和静态库, 与include目录中的头文件结合使用.
libexec: 各个服务对用的shell配置文件所在的目录, 可用于配置日志输出, 启动参数等基本信息.
sbin: Hadoop管理脚本所在的目录, 主要包括HDFS和YARN中各类服务的启动 / 关闭脚本.
share: Hadoop各个模块编译后的jar包所在的目录, 官方自带实例.
2.5 集群规划
集群规划: 在我们准备的三台服务器上如何搭建hadoop集群
原则:
1) 优先满足软件需要的硬件资源
2) 尽量避免有冲突的软件不要在一起
3) 有依赖的软件尽量部署在一起
规划安排:
hadoop01: NameNode DataNode | ResourceManager NodeManager
hadoop02: DataNode SecondaryNameNode | NodeManager
hadoop03: DataNode | NodeManager
未来扩展:
hadoop04: DataNode NodeManager
hadoop05: DataNode NodeManager
hadoop06: DataNode NodeManager
......
2.6 启动, Web-UI
要启动Hadoop集群, 需要启动HDFS和YARN两个集群, 首次启动HDFS时, 必须对其进行格式化操作. 本质上是一些清理和准备工作, 因此此时的HDFS在物理上还是不存在的.
Hadoop集群启动并允许, 可以通过web-ui进行查看
NameNode: http://nn_host:port/ 默认50070.
ResourceManager: http://rm_host:port/ 默认8088.
2.7 MapReduce JobHistory
JobHistory用来记录已经finished的MR运行日志, 日志信息存放于HDFS目录中, 默认情况下没有开启此功能, 需要在mapred-site.xml中配置并手动启动.
可以通过web-ui进行查看
http://nn_host:port/ 默认19888.
3. HDFS的垃圾桶机制
3.1 垃圾桶机制解析
每一个文件系统都会有垃圾桶机制, 便于将删除的数据回收到垃圾桶里, 避免某些误操作删除一些重要文件. 回收到垃圾桶里的资料数据, 都可以进行恢复.
3.2 垃圾桶机制配置
HDFS的垃圾回收的默认配置属性为0, 也就是说, 如果不小心误删了, 那么这个操作是不可恢复的. 修改core-site.xml , 那么可以按照生产上的需求设置回收站的保存时间, 这个时间以分钟为单位, 例如1440 = 24h = 1天.
3.3 垃圾桶机制验证
如果启用垃圾桶配置, dfs命令删除的文件不会立即从HDFS中删除. 相反, HDFS将其移动到垃圾目录 (每个用户在 /user/<username>/.Trash 下都有自己的垃圾目录). 只要文件保留在垃圾箱中, 文件可以快速回复.
使用skipTrash选项删除文件, 该选项不会将文件发送到垃圾桶, 它将从HDFS中完全删除.
Hadoop_简介_01的更多相关文章
- 阶段3 2.Spring_01.Spring框架简介_01.spring课程四天安排
spring共四天 第一天:spring框架的概述以及spring中基于XML的IOC配置 第二天:spring中基于注解的IOC和ioc的案例 第三天:spring中的aop和基于XML以及注解的A ...
- HIBERNATE 01
2017年1月8日 {LJ?Dragon}[标题]Hibernate基础知识简介_01 {LJ?Dragon}[Links]Hibernate注解详解 {LJ?Dragon}[Daily]特种部队2, ...
- KVM -> 虚拟化简介&虚拟机安装_01
什么是虚拟化? 在计算机技术中,虚拟化(技术)或虚拟技术(英语:Virtualization)是一种资源管理技术,是将计算机的各种实体资源(CPU.内存.磁盘空间.网络适配器等),予以抽象.转换后呈现 ...
- mysql -> 简介&体系结构_01
数据库简介 数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增.截取.更新.删除等操作. 所谓“数据库”系以一定方式储存在一起.能予多个用户共享.具有尽可能小的 ...
- ASP.NET Core 1.1 简介
ASP.NET Core 1.1 于2016年11月16日发布.这个版本包括许多伟大的新功能以及许多错误修复和一般的增强.这个版本包含了多个新的中间件组件.针对Windows的WebListener服 ...
- MVVM模式和在WPF中的实现(一)MVVM模式简介
MVVM模式解析和在WPF中的实现(一) MVVM模式简介 系列目录: MVVM模式解析和在WPF中的实现(一)MVVM模式简介 MVVM模式解析和在WPF中的实现(二)数据绑定 MVVM模式解析和在 ...
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
- REST简介
一说到REST,我想大家的第一反应就是“啊,就是那种前后台通信方式.”但是在要求详细讲述它所提出的各个约束,以及如何开始搭建REST服务时,却很少有人能够清晰地说出它到底是什么,需要遵守什么样的准则. ...
- Microservice架构模式简介
在2014年,Sam Newman,Martin Fowler在ThoughtWorks的一位同事,出版了一本新书<Building Microservices>.该书描述了如何按照Mic ...
随机推荐
- 01-tornado练习-tornado简介
# coding = utf-8 """ 启动一个tornado的web服务 """ import tornado.web from tor ...
- sortColors
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the ...
- Centos 7 启动 Tomcat 7、8 慢的问题
查看原因 首先查看日志信息,查看因为什么而启动慢 在CentOS7启动Tomcat时,启动过程很慢,需要几分钟,经过查看日志,发现耗时在这里:是session引起的随机数问题导致的.Tocmat的Se ...
- PowerMock学习(十一)之Mock private methods的使用
Mock private methods 就是mock私有方法啦,学到这不难发现,我们其实大部分都是通过反射去完成单元测试的,但是在实际中,某个类中的私有方法,个人不建议使用反射来测试,因为有时候会 ...
- C数据结构(文件操作,随机数,排序,栈和队列,图和遍历,最小生成树,最短路径)程序例子
文件操作 文件打开方式 意义 ”r” 只读打开一个文本文件,只允许读数据 ”w” 只写打开或建立一个文本文件,只允许写数据 ”a” 追加打开一个文本 ...
- 即将到来的“分布式云”(DPaaS):分布式计算+ DB +存储即服务
我在区块链会议上就即将到来的公共"分布式云"系统进行了讨论,该系统将主流的公共云平台(如AWS,Azure,Google Cloud,Heroku等)与区块链和P2P网络相结合,比 ...
- Prometheus笔记(二)监控go项目实时给grafana展示
欢迎加入go语言学习交流群 636728449 Prometheus笔记(二)监控go项目实时给grafana展示 Prometheus笔记(一)metric type 文章目录 一.promethe ...
- Nginx(http协议代理 搭建虚拟主机 服务的反向代理 在反向代理中配置集群的负载均衡)
Nginx 简介 Nginx (engine x) 是一个高性能的 HTTP 和反向代理服务.Nginx 是由伊戈尔·赛索耶夫为俄罗斯访问量第二的 Rambler.ru 站点(俄文:Рамблер)开 ...
- Round-number
Description Most of the time when rounding a given number, it is customary to round to some multiple ...
- Codeves 4279 线段树练习5
有n个数和5种操作 add a b c:把区间[a,b]内的所有数都增加c set a b c:把区间[a,b]内的所有数都设为c sum a b:查询区间[a,b]的区间和 max a b:查询区间 ...