分布式全文搜索引擎ElasticSearch—超详细
1 ElasticSearch
1.1 ES的概念和特点
ES:全文检索的框架,专门做搜索,支持分布式、集群。封装的Lucene。
特点:
- 原生的Lucene使用的不足,优化了Lucene的调用方式
- 高可用的分布式集群,处理PB级别的数据
- 目的是通过简单的restful API来隐藏Lucene的复杂性,从而使全文检索变得简单,达到“开瓶即饮”的效果
Lucene:全文检索,api比较麻烦,操作全文检索的最底层技术。
核心:创建索引,搜索索引
1.2 ES的对手
Solr和ES的区别:
(1) Solr重量级,支持很多种类型操作,支持分布式,它里面有很多功能,但是在实时领域上没有ES好。
(2) ES轻量级,支持json的操作格式,在实时搜索领域里面做得不错,如果想使用其他的功能,需要额外安装插件。
2 ElasticSearch安装及使用说明
2.1 安装ES
ES服务只依赖于JDK,推荐使用JDK1.7+。
(1)下载ES安装包:ES官方下载地址
(2)运行ES (双击bin目录下的elasticsearch.bat)
(3)验证是否运行成功,访问:http://localhost:9200/
如果看到如下信息,则说明ES集群已经启动并且正常运行。
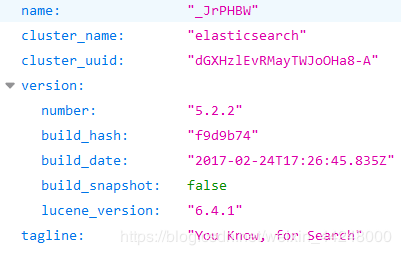
2.2 ES交互方式客户端
(1)基于RESTful API
ES和所有客户端的交互都是使用JSON格式的数据.
其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信,在开发测试阶段,你可以使用你喜欢的WEB客户端, curl命令以及火狐的POSTER插件方式和ES通信。
Curl命令方式:
默认windows下不支持curl命令,在资料中有curl的工具及简单使用说明。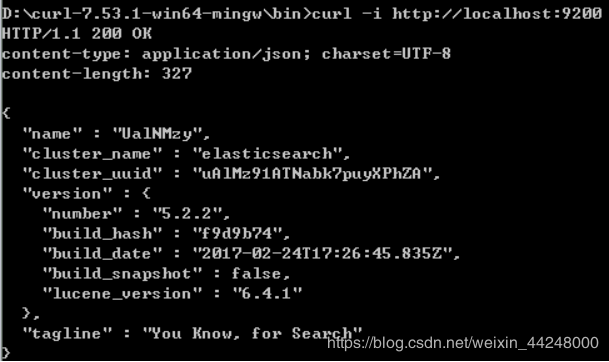
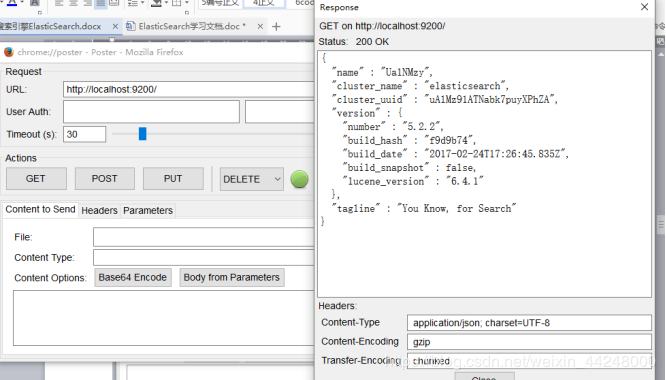
火狐的POSTER插件界面:
类似于Firebug,在火狐的“扩展”中搜索“POSTER”,并安装改扩展工具。

使用POSTER模拟请求的效果
(2)Java API
ES为Java用户提供了两种内置客户端:
节点客户端(node client):
节点客户端以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上。
传输客户端(Transport client):
这个更轻量的传输客户端能够发送请求到远程集群。它自己不加入集群,只是简单转发请求给集群中的节点。
两个Java客户端都通过9300端口与集群交互,使用ES传输协议(ES Transport Protocol)。集群中的节点
之间也通过9300端口进行通信。如果此端口未开放,你的节点将不能组成集群。
注意:
Java客户端所在的ES版本必须与集群中其他节点一致,否则,它们可能互相无法识别。
2.3 辅助管理工具Kibana5
(1)Kibana5.2.2下载地址:Kibana官方下载地址
(2)解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
(3)启动Kibana5 (在bin目录下双击kibana.bat)
(4)验证是否成功,默认访问地址:http://localhost:5601
2.4 head工具入门 + postman
(1)进入head文件中,输入cmd,打开控制台,输入npm install进行安装。
(2)安装完成,输入命令npm run start启动服务
(3)配置允许跨域访问,在elasticsearch/config/elasticsearch.yml文件末尾加上
http.cors.enabled: true
http.cors.allow-origin: “*”
(4)重启elasticsearch服务,访问http://localhost:9100
3 ES的基本操作
3.1 ES的CRUD
#新增
PUT crm/employee/1
{
"name":"xxxx",
"age":18
}
#查询
GET crm/employee/1 #修改
POST crm/employee/1
{
"name":"yyyy",
"age":28
} #删除
DELETE crm/employee/1 #没有指定id 字段生成id
POST crm/employee
{
"name":"yyyy",
"age":28
} # AW8iLW-mRN4d1HhhqMMJ
GET crm/employee/AW8iLW-mRN4d1HhhqMMJ GET _search
3.2 ES的特殊写法
# 查询所有
GET _search
#漂亮格式
GET crm/employee/AW8iLW-mRN4d1HhhqMMJ?pretty #指定返回的列
GET crm/employee/AW8iLW-mRN4d1HhhqMMJ?_source=name,age #不要元数据 只返回具体数据
GET crm/employee/AW8iLW-mRN4d1HhhqMMJ/_source
3.3 局部修改
#修改 --覆盖以前json
POST crm/employee/AW8iLW-mRN4d1HhhqMMJ
{
"name":"yyyy888"
} #局部更新
POST crm/employee/AW8iLW-mRN4d1HhhqMMJ/_update
{
"doc":{
"name":"baocheng"
}
}
3.4 批量操作
POST _bulk
{ "delete": { "_index": "xlj", "_type": "department", "_id": "123" }}
{ "create": { "_index": "xlj", "_type": "book", "_id": "123" }}
{ "title": "我发行的第一本书" }
{ "index": { "_index": "itsource", "_type": "book" }}
{ "title": "我发行的第二本书" } # 普通查询:
GET crm/department/id
# 批量查询:
GET xlj/book/_mget
{
"ids" : [ "123", "AH8ht-oSqTn8hjKcHo2i" ]
}
3.5 查询条件
# 从第0条开始查询3条student信息
GET crm/student/_search?size=3 # 从第2条开始查询2条student信息
GET crm/student/_search?from=2&size=2 # 表示查询age=15的人
GET crm/student/_search?q=age:15 # 查询3条student的信息,他们的age范围到10到20
GET crm/student/_search?size=3&q=age[10 TO 20]
如果上面的查询涉及条件比较多,就不适合使用
4 DSL查询与过滤
4.1 什么是DSL
由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
DSL分成两部分:
DSL查询
DSL过滤
4.2 DSL过滤与DSL查询在性能上的区别
(1)过滤结果可以缓存并应用到后续请求。
(2)查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
(3)过滤语句可有效地配合查询语句完成文档过滤。
总之在原则上,使用DSL查询做全文本搜索或其他需要进行相关性评分的场景,其它全用DSL过滤。
4.2.1 DSL查询
GET crm/student/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 3,
"_source": ["name", "age"],
"sort": [{"age": "asc"}]
}
4.2.2 DSL过滤
#DSL过滤 --> name = 'tangtang' --支持缓存
#select * from student where name=tangtang and age = 500
GET crm/student/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "tangtang"
}}
],
"filter": {
"term":{"age":500}
}
}
},
"from": 0,
"size": 3,
"_source": ["name", "age"],
"sort": [{"age": "asc"}]
}
#select * from student where age = 500 and name != 'tangtang' GET crm/student/_search
{
"query": {
"bool": {
"must_not": [
{"match": {
"name": "tangtang"
}}
],
"filter": {
"term":{"age":500}
}
}
},
"from": 0,
"size": 3,
"_source": ["name", "age"],
"sort": [{"age": "asc"}]
}
5 分词器
什么叫分词:把一段话按照一定规则拆分开
为什么要分词:便于检索
分词器放入ES:
解压ik分词器 -->在es 在plugins目录 -->创建一个IK文件夹 -->把ik插件拷贝到ik文件下面
测试ES怎么使用分词:
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
7 ES集群
7.1 为什么需要集群
- 解决单点故障问题
- 解决高并发问题
- 解决海量数据问题
7.2 ES集群的相关概念
分片::存储内容,主分片和从分片
node:节点,有很多类型的节点
节点属性的配置:
四种组合配置方式:
(1)node.master: true node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。
(2)node.master: false node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务。
(3)node.master: true node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。
(4)node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
7.3 ES集群理解
7.3.1 单node环境
- 单node环境下,创建一个index,有3个primary shard,3个replica shard
- 集群status是yellow
- 这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
- 集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
7.3.2 2个node环境
- replica shard分配:3个primary shard,3个replica shard,2 node
- primary —> replica同步
- 读请求:primary/replica
7.4 搭建ES集群
搭建三个节点的集群
(1) 拷贝三个ES 分别取名为node1 node2 node3
(2) 修改配置
修改内存配置 xms xmx
配置 elasticsearch.yml
# 统一的集群名
cluster.name: my-ealsticsearch
# 当前节点名
node.name: node-1
# 对外暴露端口使外网访问
network.host: 127.0.0.1
# 对外暴露端口
http.port: 9201
#集群间通讯端口号
transport.tcp.port: 9301
#集群的ip集合,可指定端口,默认为9300
discovery.zen.ping.unicast.hosts: [“127.0.0.1:9301”,”127.0.0.1:9302”,”127.0.0.1:9303”]
(3) 配置跨域
(4) 启动 node1 node2 node3
(5) 启动head
创建索引,指定分片(如果没有分配从分片,磁盘占用率太高,可以设置:cluster.routing.allocation.disk.threshold_enabled: false)
8 Java API
8.1 什么是JavaAPI
ES对Java提供一套操作索引库的工具包,即Java API。所有的ES操作都使用Client对象执行。
ES的Maven引入:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
8.2 测试代码
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexRequestBuilder;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test; import java.net.InetAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class EsTest { /**
* 连接es服务方法 嗅探方式
*/
private TransportClient getClient() throws Exception {
Settings settings = Settings.builder()
.put("client.transport.sniff", true).build();
TransportClient client = new PreBuiltTransportClient(settings).
addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
return client;
} /**
* 新增
*/
@Test
public void testAdd() throws Exception {
TransportClient client = getClient();
IndexRequestBuilder builder = client.prepareIndex("crm", "user", "1");
Map map = new HashMap();
map.put("name", "james");
map.put("age", 35);
System.out.println(builder.setSource(map).get());
client.close();
} /**
* 查询
*/
@Test
public void testGet() throws Exception {
TransportClient client = getClient();
System.out.println(client.prepareGet("crm", "user", "1").get().getSource());
client.close();
} /**
* 修改
*/
@Test
public void testUpdate() throws Exception {
TransportClient client = getClient();
IndexRequest indexRequest = new IndexRequest("crm", "user", "1");
Map map = new HashMap();
map.put("name", "kobe");
map.put("age", 18);
//不存在就新增,存在就更新
UpdateRequest upsert = new UpdateRequest("crm", "user", "1").doc(map).upsert(indexRequest);
client.update(upsert).get();
client.close();
} /**
* 删除
*/
@Test
public void testDelete() throws Exception {
TransportClient client = getClient();
client.prepareDelete("crm","user","1").get();
client.close();
} /**
* 批量操作
*/
@Test
public void testBulk() throws Exception {
TransportClient client = getClient();
BulkRequestBuilder bulk = client.prepareBulk();
for (int i = 1; i < 51; i++) {
Map map = new HashMap();
map.put("name", "xx" + i);
map.put("age", i);
bulk.add(client.prepareIndex("crm", "user", "" + i).setSource(map));
}
BulkResponse response = bulk.get();
if (response.hasFailures()) {
System.out.println("插入失败!");
}
client.close();
} /**
* DSL过滤(分页,过滤,排序)
*/
@Test
public void testDsl() throws Exception {
TransportClient client = getClient();
//得到builder
SearchRequestBuilder builder = client.prepareSearch("crm").setTypes("user");
//得到boolQuery对象
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//得到must
List<QueryBuilder> must = boolQuery.must();
must.add(QueryBuilders.matchAllQuery());
//添加filter过滤器
boolQuery.filter(QueryBuilders.rangeQuery("age").gte(18).lte(48));
builder.setQuery(boolQuery);
//添加分页
builder.setFrom(0);
builder.setSize(10);
//设置排序
builder.addSort("age", SortOrder.ASC);
//设置查询字段
builder.setFetchSource(new String[]{"name","age"}, null);
//取值
SearchResponse searchResponse = builder.get();
//得到查询内容
SearchHits hits = searchResponse.getHits();
//得到命中数据,返回数组
SearchHit[] hitsHits = hits.getHits();
//循环数组,打印获取值
for (SearchHit hitsHit : hitsHits) {
System.out.println(hitsHit.getSource());
}
client.close();
} }
分布式全文搜索引擎ElasticSearch—超详细的更多相关文章
- 3.高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建
高并发教程-基础篇-之分布式全文搜索引擎elasticsearch的搭建 如果大家看了我的上一篇<2.高并发教程-基础篇-之nginx+mysql实现负载均衡和读写分离>文章,如果能很好的 ...
- 分布式全文搜索引擎ElasticSearch
一 什么是 ElasticSearch Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elas ...
- 全文搜索引擎Elasticsearch入门实践
全文搜索引擎Elasticsearch入门实践 感谢阮一峰的网络日志全文搜索引擎 Elasticsearch 入门教程 安装 首先需要依赖Java环境.Elasticsearch官网https://w ...
- 全文搜索引擎 Elasticsearch 入门
1. 百科 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作 ...
- Spring Boot 全文搜索引擎 ElasticSearch
参考 全文搜索引擎ElasticSearch 还是Solr? - JaJian - 博客园
- 全文搜索引擎 Elasticsearch 安装
全文搜索引擎 Elasticsearch 安装 学习了:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html 拼音:https://www ...
- 全文搜索引擎Elasticsearch详细介绍
我们生活中的数据总体分为两种:结构化数据 和 非结构化数据. 结构化数据:也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理.指具有固 ...
- 全文搜索引擎 ElasticSearch 还是 Solr?
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索 Solr,但是该 Solr 搜索云项目不稳定,经常查询不出来数据,需要手动全量同步,而且是其他团队在维护,依赖性太强,导致 Solr 服务 ...
- 全文搜索引擎 Elasticsearch 入门教程
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选. 它可以快速地储存.搜索和分析海量数据.维基百科.Stack Overflow.Gi ...
随机推荐
- Linux下为知笔记和蚂蚁笔记测评,推荐蚂蚁笔记!(非广告)
本人由于学习Linux,需要一款可以在Linux平台下可以运行的一款软件,了解到为知笔记之笔记(下文以W代替)和蚂蚁笔记(下文以M代替)比较出名,由于某云和某象笔记在linux平台下没有对应的软件,所 ...
- html学习笔记--xdd
<!DOCTYPE html> <html> <head> <title>HTML学习笔记</title> <meta charset ...
- 迁移桌面程序到MS Store(13)——动态检查Win10 API是否可用
假设我们现有一个WPF程序,需要支持1903以前的Windows 10版本.同时在1903以后的版本上,额外多出一个Ink的功能.那么我们就可以通过ApiInformation.IsApiContra ...
- 搭建nextcloud私有云存储网盘
简介: 搭建个人云存储一般会想到ownCloud,堪称是自建云存储服务的经典.而Nextcloud是ownCloud原开发团队打造的号称是“下一代”存储. 真正试用过后就由衷地赞同这个Nextclou ...
- 关于JAVA,特点,历史,编译式的语言&解释式的语言,什么是java?JDK?DOS?一次编译到处运行原理。
1.java语言的特点: 简单的:面向对象的:跨平台(操作系统)的(一次编译,到处运行):高性能的: 2.类名的首字母大写,方法小写: 3.历史: java2(即java),为什么加个2呢?1998年 ...
- builtins内建模块
builtins模块 为啥我们没有导入任何模块就能使用len(),str(),print()...等这么多的函数? 其实在我们运行python解释器的时候,他会自动导入一些模块,这些函数就是从这些地方 ...
- 如何重置IE浏览器
1.退出所有程序,包括 Internet Explorer.单击“开始”.在“开始搜索”框中键入 inetcpl.cpl 命令,然后按回车键打开“Inetnet 选项”对话框. 2.单击“高级”选项卡 ...
- SwiftyUserDefaults-封装系统本地化的框架推荐
// // ViewController.swift // Test4SwiftyUserDefaults // Copyright © 2017年. All rights reserved. // ...
- .Net core-邮件发送(同步,异步)底层代码(欢迎留言讨论)
using MailKit.Net.Smtp;using MimeKit;using System;using System.Collections.Generic;using System.IO;u ...
- ios宏定义应该呆在恰当的地方
项目为了看起来整洁 并减少不必要的多次拼写 我们会把这样的方法 做成宏定义 那么问题来了 很多文件同时用到一个或多个宏定义 写完之后就会变成这个样子 看起来很乱 阅读性也不好 那么问题来了怎么解决嘞 ...