Spring Boot2 系列教程(二十四)Spring Boot 整合 Jpa
Spring Boot 中的数据持久化方案前面给大伙介绍了两种了,一个是 JdbcTemplate,还有一个 MyBatis,JdbcTemplate 配置简单,使用也简单,但是功能也非常有限,MyBatis 则比较灵活,功能也很强大,据我所知,公司采用 MyBatis 做数据持久化的相当多,但是 MyBatis 并不是唯一的解决方案,除了 MyBatis 之外,还有另外一个东西,那就是 Jpa,松哥也有一些朋友在公司里使用 Jpa 来做数据持久化,本文就和大伙来说说 Jpa 如何实现数据持久化。
Jpa 介绍
首先需要向大伙介绍一下 Jpa,Jpa(Java Persistence API)Java 持久化 API,它是一套 ORM 规范,而不是具体的实现,Jpa 的江湖地位类似于 JDBC,只提供规范,所有的数据库厂商提供实现(即具体的数据库驱动),Java 领域,小伙伴们熟知的 ORM 框架可能主要是 Hibernate,实际上,除了 Hibernate 之外,还有很多其他的 ORM 框架,例如:
- Batoo JPA
- DataNucleus (formerly JPOX)
- EclipseLink (formerly Oracle TopLink)
- IBM, for WebSphere Application Server
- JBoss with Hibernate
- Kundera
- ObjectDB
- OpenJPA
- OrientDB from Orient Technologies
- Versant Corporation JPA (not relational, object database)
Hibernate 只是 ORM 框架的一种,上面列出来的 ORM 框架都是支持 JPA2.0 规范的 ORM 框架。既然它是一个规范,不是具体的实现,那么必然就不能直接使用(类似于 JDBC 不能直接使用,必须要加了驱动才能用),我们使用的是具体的实现,在这里我们采用的实现实际上还是 Hibernate。
Spring Boot 中使用的 Jpa 实际上是 Spring Data Jpa,Spring Data 是 Spring 家族的一个子项目,用于简化 SQL、NoSQL 的访问,在 Spring Data 中,只要你的方法名称符合规范,它就知道你想干嘛,不需要自己再去写 SQL。
关于 Spring Data Jpa 的具体情况,大家可以参考一文读懂 Spring Data Jpa
工程创建
创建 Spring Boot 工程,添加 Web、Jpa 以及 MySQL 驱动依赖,如下:
工程创建好之后,添加 Druid 依赖,完整的依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.28</version>
<scope>runtime</scope>
</dependency>
如此,工程就算创建成功了。
基本配置
工程创建完成后,只需要在 application.properties 中进行数据库基本信息配置以及 Jpa 基本配置,如下:
# 数据库的基本配置
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.url=jdbc:mysql:///test01?useUnicode=true&characterEncoding=UTF-8
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# JPA配置
spring.jpa.database=mysql
# 在控制台打印SQL
spring.jpa.show-sql=true
# 数据库平台
spring.jpa.database-platform=mysql
# 每次启动项目时,数据库初始化策略
spring.jpa.hibernate.ddl-auto=update
# 指定默认的存储引擎为InnoDB
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
注意这里和 JdbcTemplate 以及 MyBatis 比起来,多了 Jpa 配置,Jpa 配置含义我都注释在代码中了,这里不再赘述,需要强调的是,最后一行配置,默认情况下,自动创建表的时候会使用 MyISAM 做表的引擎,如果配置了数据库方言为 MySQL57Dialect,则使用 InnoDB 做表的引擎。
好了,配置完成后,我们的 Jpa 差不多就可以开始用了。
基本用法
ORM(Object Relational Mapping) 框架表示对象关系映射,使用 ORM 框架我们不必再去创建表,框架会自动根据当前项目中的实体类创建相应的数据表。因此,我这里首先创建一个 User 对象,如下:
@Entity(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name")
private String username;
private String address;
//省略getter/setter
}
首先 @Entity 注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,@Entity 注解的 name 属性表示自定义生成的表名。@Id 注解表示这个字段是一个 id,@GeneratedValue 注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用 @Column 注解,去配置字段的名称,长度,是否为空等等。
做完这一切之后,启动 Spring Boot 项目,就会发现数据库中多了一个名为 t_user 的表了。
针对该表的操作,则需要我们提供一个 Repository,如下:
public interface UserDao extends JpaRepository<User,Integer> {
List<User> getUserByAddressEqualsAndIdLessThanEqual(String address, Integer id);
@Query(value = "select * from t_user where id=(select max(id) from t_user)",nativeQuery = true)
User maxIdUser();
}
这里,自定义 UserDao 接口继承自 JpaRepository,JpaRepository 提供了一些基本的数据操作方法,例如保存,更新,删除,分页查询等,开发者也可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在 Spring Data 中,只要按照既定的规范命名方法,Spring Data Jpa 就知道你想干嘛,这样就不用写 SQL 了,那么规范是什么呢?参考下图:
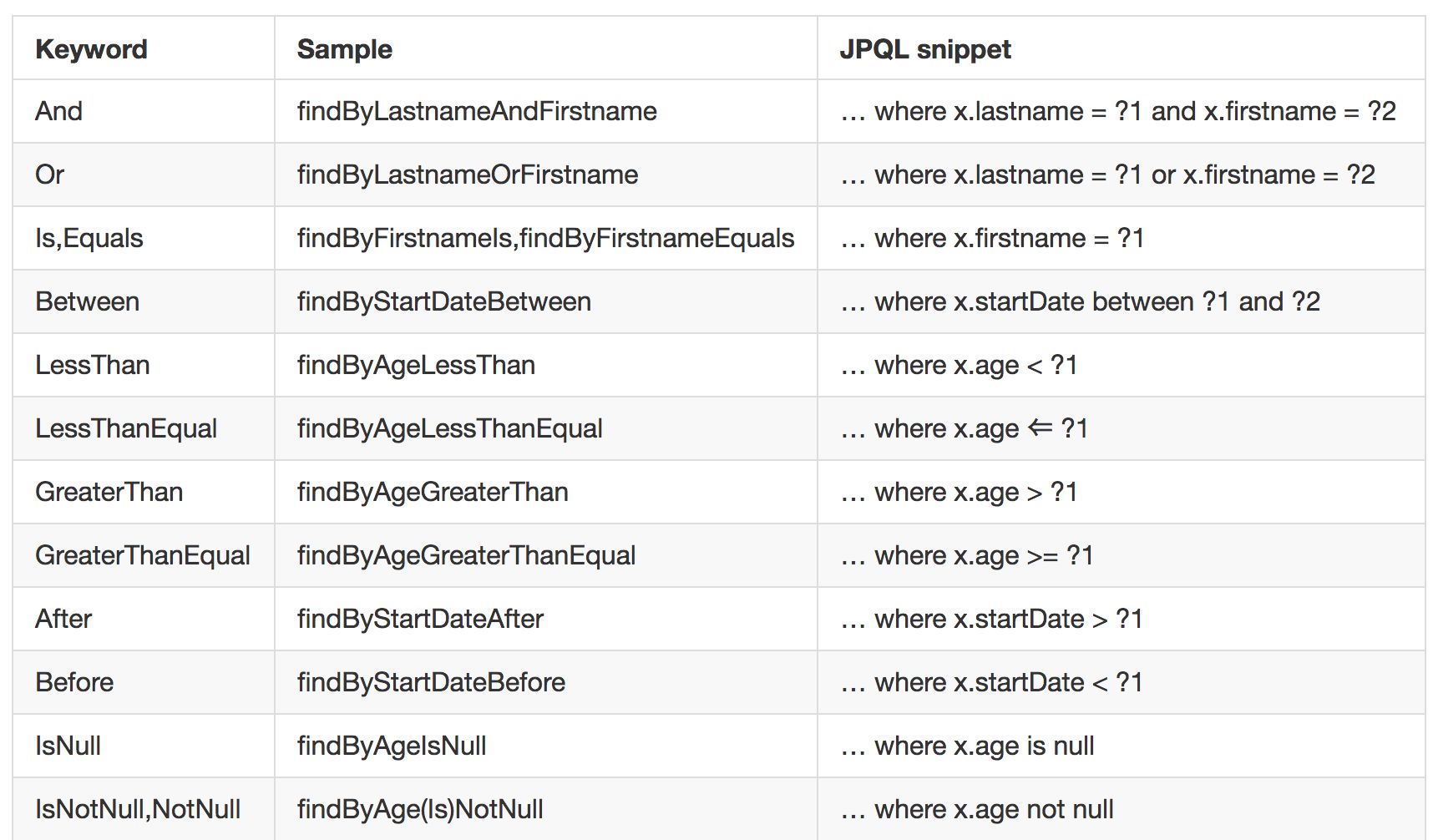
当然,这种方法命名主要是针对查询,但是一些特殊需求,可能并不能通过这种方式解决,例如想要查询 id 最大的用户,这时就需要开发者自定义查询 SQL 了。
如上代码所示,自定义查询 SQL,使用 @Query 注解,在注解中写自己的 SQL,默认使用的查询语言不是 SQL,而是 JPQL,这是一种数据库平台无关的面向对象的查询语言,有点定位类似于 Hibernate 中的 HQL,在 @Query 注解中设置 nativeQuery 属性为 true 则表示使用原生查询,即大伙所熟悉的 SQL。上面代码中的只是一个很简单的例子,还有其他一些点,例如如果这个方法中的 SQL 涉及到数据操作,则需要使用 @Modifying 注解。
好了,定义完 Dao 之后,接下来就可以将 UserDao 注入到 Controller 中进行测试了(这里为了省事,就没有提供 Service 了,直接将 UserDao 注入到 Controller 中)。
@RestController
public class UserController {
@Autowired
UserDao userDao;
@PostMapping("/")
public void addUser() {
User user = new User();
user.setId(1);
user.setUsername("张三");
user.setAddress("深圳");
userDao.save(user);
}
@DeleteMapping("/")
public void deleteById() {
userDao.deleteById(1);
}
@PutMapping("/")
public void updateUser() {
User user = userDao.getOne(1);
user.setUsername("李四");
userDao.flush();
}
@GetMapping("/test1")
public void test1() {
List<User> all = userDao.findAll();
System.out.println(all);
}
@GetMapping("/test2")
public void test2() {
List<User> list = userDao.getUserByAddressEqualsAndIdLessThanEqual("广州", 2);
System.out.println(list);
}
@GetMapping("/test3")
public void test3() {
User user = userDao.maxIdUser();
System.out.println(user);
}
}
如此之后,即可查询到需要的数据。
好了,本文的重点是 Spring Boot 和 Jpa 的整合,这个话题就先说到这里。
多说两句
在和 Spring 框架整合时,如果用到 ORM 框架,大部分人可能都是首选 Hibernate,实际上,在和 Spring+SpringMVC 整合时,也可以选择 Spring Data Jpa 做数据持久化方案,用法和本文所述基本是一样的,Spring Boot 只是将 Spring Data Jpa 的配置简化了,因此,很多初学者对 Spring Data Jpa 觉得很神奇,但是又觉得无从下手,其实,此时可以回到 Spring 框架,先去学习 Jpa,再去学习 Spring Data Jpa,这是给初学者的一点建议。
相关案例已经上传到 GitHub,欢迎小伙伴们们下载:https://github.com/lenve/javaboy-code-samples
扫码关注松哥,公众号后台回复 2TB,获取松哥独家 超2TB 学习资源

Spring Boot2 系列教程(二十四)Spring Boot 整合 Jpa的更多相关文章
- Spring Boot2 系列教程(二十五)Spring Boot 整合 Jpa 多数据源
本文是 Spring Boot 整合数据持久化方案的最后一篇,主要和大伙来聊聊 Spring Boot 整合 Jpa 多数据源问题.在 Spring Boot 整合JbdcTemplate 多数据源. ...
- Spring Boot2 系列教程(二十六)Spring Boot 整合 Redis
在 Redis 出现之前,我们的缓存框架各种各样,有了 Redis ,缓存方案基本上都统一了,关于 Redis,松哥之前有一个系列教程,尚不了解 Redis 的小伙伴可以参考这个教程: Redis 教 ...
- Spring Boot2 系列教程(二十八)Spring Boot 整合 Session 共享
这篇文章是松哥的原创,但是在第一次发布的时候,忘了标记原创,结果被好多号转发,导致我后来整理的时候自己没法标记原创了.写了几百篇原创技术干货了,有一两篇忘记标记原创进而造成的一点点小小损失也能接受,不 ...
- Spring Boot2 系列教程(二十九)Spring Boot 整合 Redis
经过 Spring Boot 的整合封装与自动化配置,在 Spring Boot 中整合Redis 已经变得非常容易了,开发者只需要引入 Spring Data Redis 依赖,然后简单配下 red ...
- Spring Boot2 系列教程(二十)Spring Boot 整合JdbcTemplate 多数据源
多数据源配置也算是一个常见的开发需求,Spring 和 SpringBoot 中,对此都有相应的解决方案,不过一般来说,如果有多数据源的需求,我还是建议首选分布式数据库中间件 MyCat 去解决相关问 ...
- Spring Boot2 系列教程(二十三)理解 Spring Data Jpa
有很多读者留言希望松哥能好好聊聊 Spring Data Jpa! 其实这个话题松哥以前零零散散的介绍过,在我的书里也有介绍过,但是在公众号中还没和大伙聊过,因此本文就和大家来仔细聊聊 Spring ...
- Spring Boot2 系列教程(二十二)整合 MyBatis 多数据源
关于多数据源的配置,前面和大伙介绍过 JdbcTemplate 多数据源配置,那个比较简单,本文来和大伙说说 MyBatis 多数据源的配置. 其实关于多数据源,我的态度还是和之前一样,复杂的就直接上 ...
- Spring Boot2 系列教程(三十)Spring Boot 整合 Ehcache
用惯了 Redis ,很多人已经忘记了还有另一个缓存方案 Ehcache ,是的,在 Redis 一统江湖的时代,Ehcache 渐渐有点没落了,不过,我们还是有必要了解下 Ehcache ,在有的场 ...
- Spring cloud系列教程第十篇- Spring cloud整合Eureka总结篇
Spring cloud系列教程第十篇- Spring cloud整合Eureka总结篇 本文主要内容: 1:spring cloud整合Eureka总结 本文是由凯哥(凯哥Java:kagejava ...
随机推荐
- Unix 线程改变创建进程中变量的值(2)
执行环境:Linux ubuntu 4.4.0-31-generic #50-Ubuntu SMP Wed Jul 13 00:07:12 UTC 2016 x86_64 x86_64 x86_64 ...
- 【Cocos2d-x】学习笔记目录
从2019年7月开始学习游戏引擎Cocos2dx,版本3.17. 学习笔记尽量以白话的形式表达自己对源码的理解,而不是大篇幅复制粘贴源码. 本人水平有限,欢迎批评指正! Cocos2d-x 学习笔记 ...
- idea迁移到其他电脑,省去重新安装破解及配置
idea迁移到其他电脑,省去重新安装破解及配置,要求路径与之前的电脑保持相同. 1. 将idea的配置目录文件夹整个复制过去,默认路径 C:\Users\Administrator\.IntelliJ ...
- linux-scp命令及如何设置免密登录
部署测试环境时经常在两台服务器间copy文件,那么如何设置免密登录? 场景:源服务器A(如172) -> 目标服务器B(如71) 实现将服务器A的文件copy到服务器B 实现方式有两种: 在源 ...
- Redis真集群安装
Redis真集群安装 命令文档:http://redisdoc.com/index.html 下载:https://code.google.com/archive/p/redis/downloads ...
- Arduino学习笔记⑧ 红外通信
1.前言 红外通信是一种利用红外光编码进行数据传输的无线通信方式,在目前来说是使用非常广泛的.生活中常见电视遥控器,空调遥控器,DVD遥控器(现在估计是老古董了),均使用红外线遥控.使用红外线 ...
- Nginx在Window上简单的使用
先上Nginx在Window上的基本常用指令: IP_hase也可以解决Session共享的问题:不过不推荐这样使用,建议使用 Memcache/redis来处理 session共享的问题 轮询还是权 ...
- day2------运算符和编码
运算符和编码 一. 格式化输出 现在有以下需求,让用户输入name, age, job,Gender 然后输出如下所示: ------------ info of Yong Jie --------- ...
- fenby C语言 P27使用指针
使用指针 p代表地址 *p代表这个地址存放的内容 #include <stdio.h> int main(){ int x=100,y=200,*p1=&x,*p2=&y; ...
- Emacs 学习之旅
**Emacs 的使用过程,就像是程序员的生涯一样--路漫漫其修远兮,吾将上下而求索.** ## 万物始于 Emacs 最早知道 _Emacs_ 是从编辑器的圣战开始的,即编辑器之神--Vi,和神的编 ...