C#+Selenium抓取百度搜索结果前100网址
需求
爬取百度搜索某个关键字对应的前一百个网址。
实现方式
VS2017 + Chrome
.NET Framework + C# + Selenium(浏览器自动化测试框架)
环境准备
创建控制台应用程序,通过NuGet添加对Selenium的引用
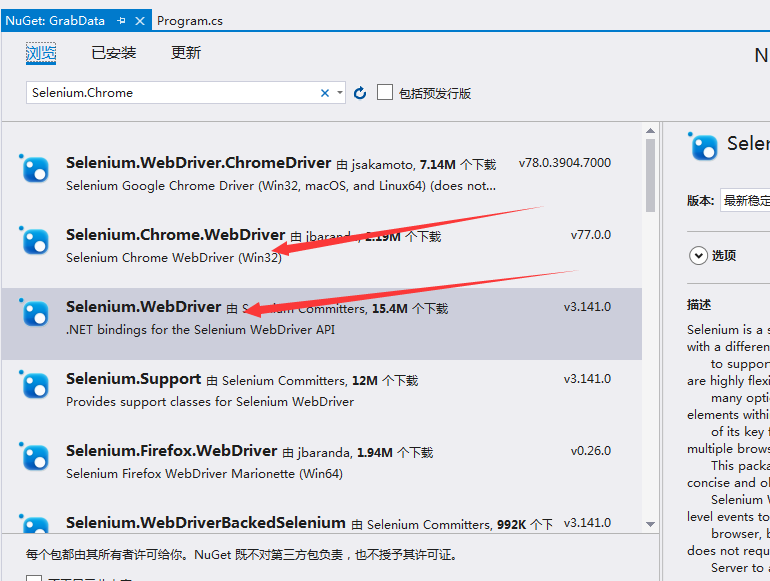
这里因为我用的Google浏览器,所以添加这两个的引用。
代码输出
static void GrabUrlByKeyWord(string keyWord)
{
//创建chrome驱动程序
IWebDriver webDriver = new ChromeDriver();
//跳至百度
webDriver.Navigate().GoToUrl("https://www.baidu.com");
//找到页面上的搜索框 输入关键字
webDriver.FindElement(By.Id("kw")).SendKeys(keyWord);
//点击搜索按钮
webDriver.FindElement(By.Id("su")).Click();
}
运行看一下效果先
static void Main(string[] args)
{
GrabUrlByKeyWord("香香瓜子");
}
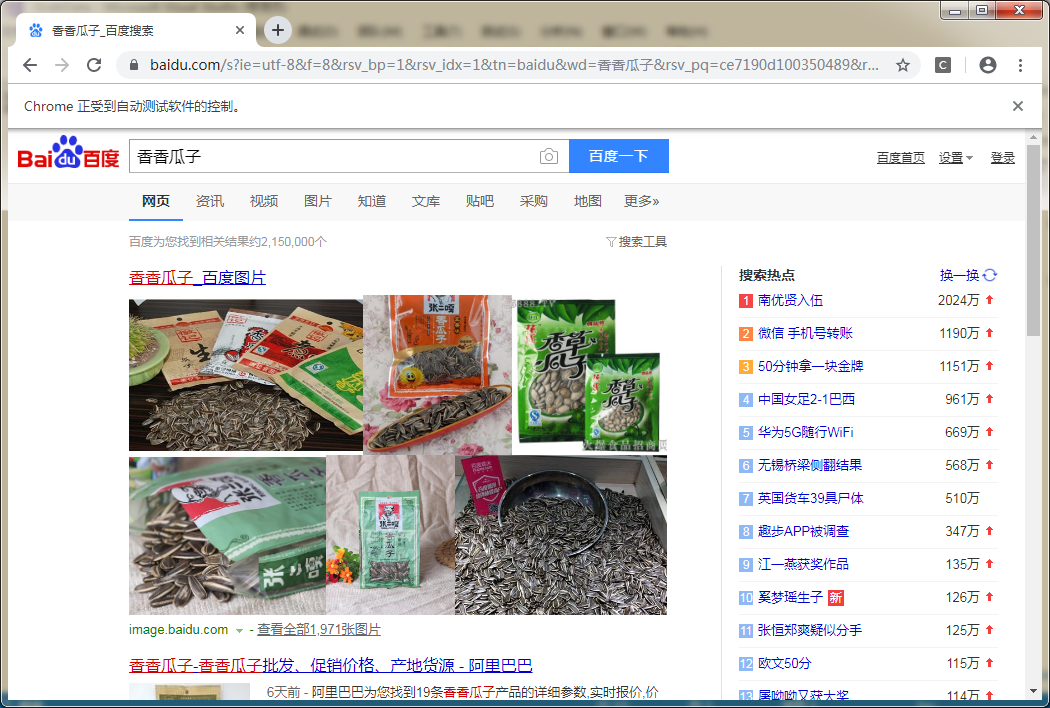
是不是感觉太简单了,这么快就来到目标页面了(这么想就太天真了。。)
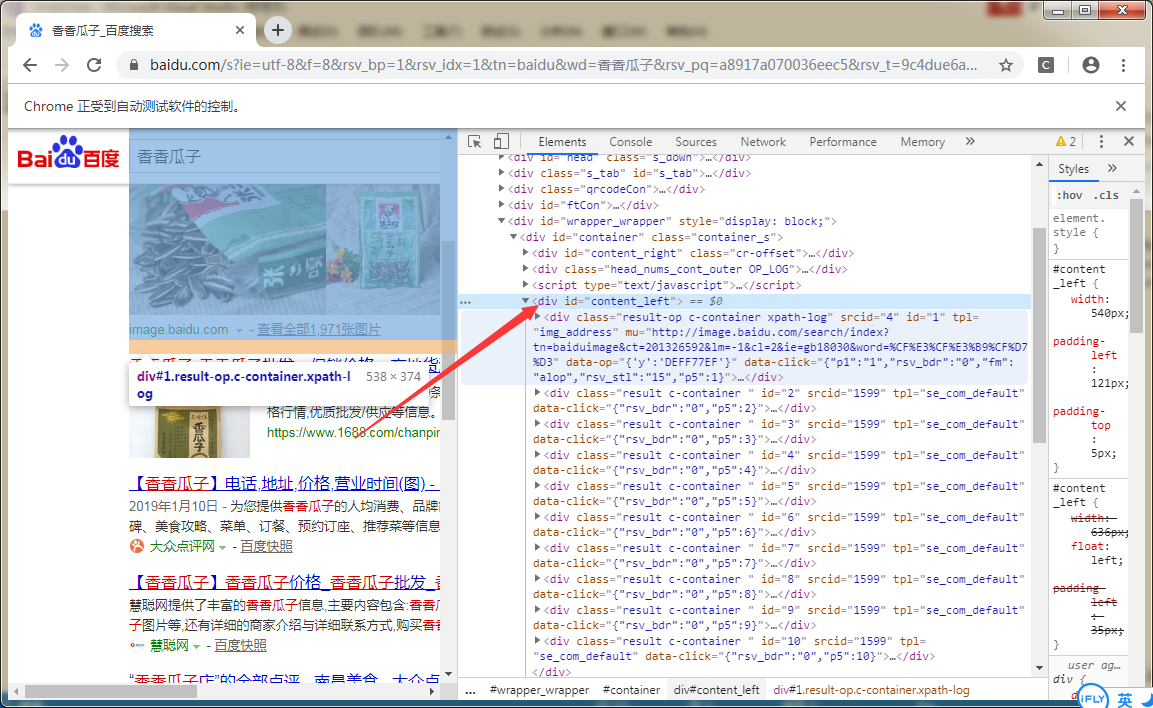
F12,观察发现搜索结果都在一个id为content_left的div中,进一步解刨
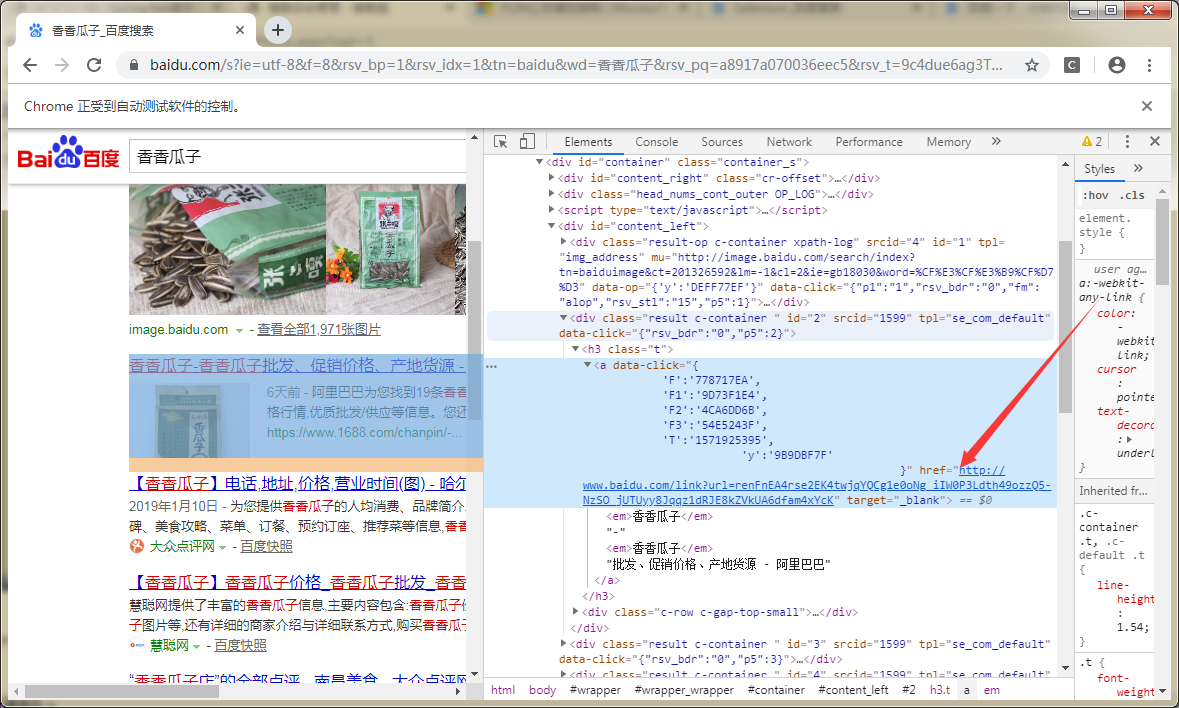
百度对目标做了中转,最关键的是它对目标url做了加密。。。
那么?问题来了,我们怎么获取到目标真实的网址呢?
当然,方法有很多:
①可以通过Selenium模拟真实操作,每个结果都点进去,获取地址栏的网址;(这样效率是不是太低了。。。)
②解密;(目前我还没有找到解密方法。。。)
③后台通过HttpClient发送请求,获取url;
......
......
......
把想说的思想总结一下:
使用HttpClient一个一个去请求的地址来获取真实地址的话,这样效率很低,
使用PLINQ并行查询 或 多线程 的话,效率变高了,但是它的执行顺序是不定的,
我们需要的结果又是排名的顺序,这时候可以把操作对象封装成不依赖顺序的model,
例如给model加一个rank排名属性,后期可以根据该属性进行处理。
贴一段来自Microsoft的文本:
虽然可以指示 PLINQ 暂留任何源序列的顺序,但这会对性能产生不利影响。 最佳做法是,尽量将查询的结构设计为不依赖顺序暂留。
C#+Selenium抓取百度搜索结果前100网址的更多相关文章
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
随机推荐
- 让tomcat使用指定JDK
一,前言 我们都知道,tomcat启动前需要配置JDK环境变量,如果没有配置JDK的环境变量,那么tomcat启动的时候就会报错,也就是无法启动. 但是在我们的工作或者学习过程中,有的时候会出现tom ...
- linux环境下Nginx的安装
因为工作环境大多数都是windows server服务器,仅有的linux服务器同事们都在抢着用,所以特意买了一台阿里云服务器,感兴趣的小伙伴可以了解一下,一年只要293: https://promo ...
- springboot集成Spring Data JPA数据查询
1.JPA介绍 JPA(Java Persistence API)是Sun官方提出的Java持久化规范.它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据.它的出现主要是为 ...
- freemarker模版引擎技术总结
FreeMarker语言概述 FreeMarker是一个模板引擎,一个基于模板生成文本输出的通用工具,使用纯Java编写. FreeMarker被设计用来生成HTML Web页面,特别是基于MVC模式 ...
- VS2010连接Oracle配置
直接看上图.EZ连接和TNS连接.TNS连接要修改tnsnames.tns文件内部的host为服务器地址
- git 查看日志记录
1.git log 如果日志特别多的话,在git bash中,按向下键来查看更多,按q键退出查看日志. 2.git show 查看最近一次commit内容,也可以后面加commit号,单独查看此次版本 ...
- MongoDB 学习笔记之 分析器和explain
MongoDB分析器: 检测MongoDB分析器是否打开: db.getProfilingLevel() 0表示没有打开 1表示打开了,并且如果查询的执行时间超过了第二个参数毫秒(ms)为单位的最大查 ...
- 人生,还没困难到"非死不可"
最近半个月,美国著名的Facebook公司,出了好几件大事.第一件事,2019年9月19日,一名陈姓中国软件工程师在Facebook加州总部跳楼自杀.第二件事,2019年10月4日,一名软件工程师在座 ...
- pycharm导入自己写的包的时候,不能识别模块的解决办法
今天用写selenium脚本的时候导入自己统计目录下的模块时,出错,明明存在但是报错说模块不存在,找了半天终于找到解决方案,顺便记录一下吧 pycharm不会将当前文件目录自动加入自己的sourse_ ...
- 超链接target属性的取值和作用?
<a>标签的target属性规定在何处打开连接文档 属性值 _black:点击一次打开一个新窗口 _new:始终在同一个新窗口中打开 _self:默认,在当前窗口打开 _parent:在父 ...