NLP(一)语料库和WordNet
原文链接:http://www.one2know.cn/nlp1/
- 访问语料库
NLTK数据库的安装:http://www.nltk.org/data.html
NLTK语料库列表:http://www.nltk.org/nltk_data/
内部访问(以Reuters corpus为例):
import nltk
from nltk.corpus import reuters
# 下载路透社语料库
nltk.download('reuters')
# 查看语料库的内容
files = reuters.fileids()
print(files)
# 访问其中一个文件的内容
words14826 = reuters.words(['test/14826'])
print(words14826[:20])
# 输出主题(一共90个)
reutersGenres = reuters.categories()
print(reutersGenres)
# 访问一个主题,一句话一行输出
for w in reuters.words(categories=['tea']):
print(w + ' ',end='')
if w is '.':
print()
- 下载外部语料库并访问(以影评数据集为例)
下载数据集:http://www.cs.cornell.edu/people/pabo/movie-review-data/
本例下载了1000积极和1000消极的影评
from nltk.corpus import CategorizedPlaintextCorpusReader
# 读取语料库
reader = CategorizedPlaintextCorpusReader(r'D:\PyCharm 5.0.3\WorkSpace\2.NLP\语料库\1.movie_review_data_1000\txt_sentoken',r'.*\.txt',cat_pattern=r'(\w+)/*')
print(reader.categories())
print(reader.fileids())
# 语料库分成两类
posFiles = reader.fileids(categories='pos')
negFiles = reader.fileids(categories='neg')
# 从posFiles或negFiles随机选择一个文件
from random import randint
fileP = posFiles[randint(0,len(posFiles)-1)]
fileN = negFiles[randint(0,len(negFiles)-1)]
# 逐句打印随机的选择文件
for w in reader.words(fileP):
print(w + ' ',end='')
if w is '.':
print()
for w in reader.words(fileN):
print(w + ' ',end='')
if w is '.':
print()
CategorizedPlaintextCorpusReader类通过参数的设置,从内部将样本加载到合适的位置
- 语料库中的词频计算和计数分布分析
以布朗语料库为例:布朗大学 500个文本 15个类
import nltk
from nltk.corpus import brown
nltk.download('brown')
# 查看brown中的类别
print(brown.categories())
# 挑选出三种类别,并获取其中的疑问词
genres = ['fiction','humor','romance']
whwords = ['what','which','how','why','when','where','who']
# 迭代器分别分析3种类
for i in range(0,len(genres)):
genre = genres[i]
print()
print("Analysing '"+ genre + "' wh words")
genre_text = brown.words(categories = genre)
print(genre_text)
# 返回输入单词对象的wh类及对应的频率
fdist = nltk.FreqDist(genre_text)
for wh in whwords:
print(wh + ':',fdist[wh],end=' ')
print()
输出:
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
Analysing 'fiction' wh words
['Thirty-three', 'Scotty', 'did', 'not', 'go', 'back', ...]
what: 128 which: 123 how: 54 why: 18 when: 133 where: 76 who: 103
Analysing 'humor' wh words
['It', 'was', 'among', 'these', 'that', 'Hinkle', ...]
what: 36 which: 62 how: 18 why: 9 when: 52 where: 15 who: 48
Analysing 'romance' wh words
['They', 'neither', 'liked', 'nor', 'disliked', 'the', ...]
what: 121 which: 104 how: 60 why: 34 when: 126 where: 54 who: 89
- 网络文本和聊天文本的词频分布
import nltk
from nltk.corpus import webtext
# nltk.download('webtext')
print(webtext.fileids())
# 选择一个数据文件,并计算频率分布,获得FreqDist的对象fdist
fileid = 'singles.txt' # 个人广告
wbt_words = webtext.words(fileid)
fdist = nltk.FreqDist(wbt_words)
# 获取高频单词及其计数
print('最多出现的词 "' , fdist.max() , '" :' , fdist[fdist.max()])
# 获取所有单词的计数
print(fdist.N())
# 找出最常见的10个词
print(fdist.most_common(10))
# 将单词和频率制成表格
print(fdist.tabulate(5))
# 将单词和频率制成分布图
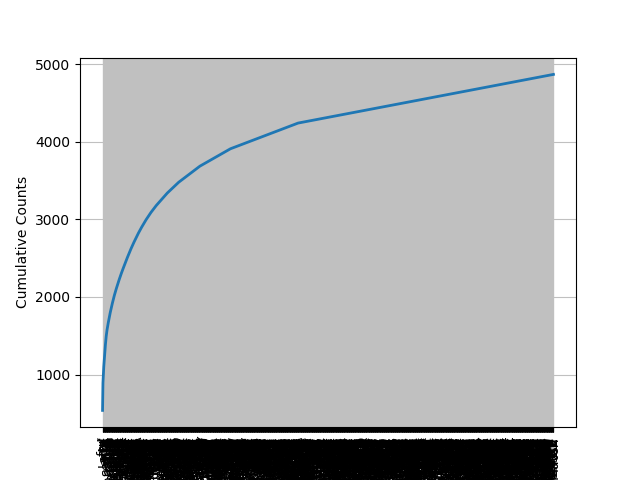
fdist.plot(cumulative=True) # 计数显示,cumulative=percents为百分比显示
输出:
['firefox.txt', 'grail.txt', 'overheard.txt', 'pirates.txt', 'singles.txt', 'wine.txt']
最多出现的词 " , " : 539
4867
[(',', 539), ('.', 353), ('/', 110), ('for', 99), ('and', 74), ('to', 74), ('lady', 68), ('-', 66), ('seeks', 60), ('a', 52)]
, . / for and
539 353 110 99 74
None
累计计数分布图:
- 使用WordNet获取一个词的不同含义
# import nltk
# nltk.download('wordnet')
from nltk.corpus import wordnet as wn
chair = 'chair'
# 输出chair的各种含义
chair_synsets = wn.synsets(chair)
print('Chair的意思:',chair_synsets,'\n\n')
# 迭代输出 含义,含义的定义,同义词条,例句
for synset in chair_synsets:
print(synset,': ')
print('Definition: ',synset.definition())
print('Lemmas/Synonymous words: ',synset.lemma_names())
print('Example: ',synset.examples(),'\n')
输出:
Chair的意思: [Synset('chair.n.01'), Synset('professorship.n.01'), Synset('president.n.04'), Synset('electric_chair.n.01'), Synset('chair.n.05'), Synset('chair.v.01'), Synset('moderate.v.01')]
Synset('chair.n.01') :
Definition: a seat for one person, with a support for the back
Lemmas/Synonymous words: ['chair']
Example: ['he put his coat over the back of the chair and sat down']
Synset('professorship.n.01') :
Definition: the position of professor
Lemmas/Synonymous words: ['professorship', 'chair']
Example: ['he was awarded an endowed chair in economics']
Synset('president.n.04') :
Definition: the officer who presides at the meetings of an organization
Lemmas/Synonymous words: ['president', 'chairman', 'chairwoman', 'chair', 'chairperson']
Example: ['address your remarks to the chairperson']
Synset('electric_chair.n.01') :
Definition: an instrument of execution by electrocution; resembles an ordinary seat for one person
Lemmas/Synonymous words: ['electric_chair', 'chair', 'death_chair', 'hot_seat']
Example: ['the murderer was sentenced to die in the chair']
Synset('chair.n.05') :
Definition: a particular seat in an orchestra
Lemmas/Synonymous words: ['chair']
Example: ['he is second chair violin']
Synset('chair.v.01') :
Definition: act or preside as chair, as of an academic department in a university
Lemmas/Synonymous words: ['chair', 'chairman']
Example: ['She chaired the department for many years']
Synset('moderate.v.01') :
Definition: preside over
Lemmas/Synonymous words: ['moderate', 'chair', 'lead']
Example: ['John moderated the discussion']
- 上位词和下位词
下位词更具体,上位词更一般(泛化)
以bed.n.01和woman.n.01为例:
from nltk.corpus import wordnet as wn
woman = wn.synset('woman.n.01')
bed = wn.synset('bed.n.01')
# 返回据有直系关系的同义词集,上位词!
print(woman.hypernyms())
woman_paths = woman.hypernym_paths()
# 打印从根节点到woman.n.01的所有路径
for idx,path in enumerate(woman_paths):
print('\n\nHypernym Path :',idx+1)
for synset in path:
print(synset.name(),',',end='')
# 更具体的术语,下位词!
types_of_bed = bed.hyponyms()
print('\n\nTypes of beds(Hyponyms): ',types_of_bed)
# 打印出更有意义的lemma(词条)
print('\n',sorted(set(lemma.name() for synset in types_of_bed for lemma in synset.lemmas())))
输出:
[Synset('adult.n.01'), Synset('female.n.02')]
Hypernym Path : 1
entity.n.01 ,physical_entity.n.01 ,causal_agent.n.01 ,person.n.01 ,adult.n.01 ,woman.n.01 ,
Hypernym Path : 2
entity.n.01 ,physical_entity.n.01 ,object.n.01 ,whole.n.02 ,living_thing.n.01 ,organism.n.01 ,person.n.01 ,adult.n.01 ,woman.n.01 ,
Hypernym Path : 3
entity.n.01 ,physical_entity.n.01 ,causal_agent.n.01 ,person.n.01 ,female.n.02 ,woman.n.01 ,
Hypernym Path : 4
entity.n.01 ,physical_entity.n.01 ,object.n.01 ,whole.n.02 ,living_thing.n.01 ,organism.n.01 ,person.n.01 ,female.n.02 ,woman.n.01 ,
Types of beds(Hyponyms): [Synset('berth.n.03'), Synset('built-in_bed.n.01'), Synset('bunk.n.03'), Synset('bunk_bed.n.01'), Synset('cot.n.03'), Synset('couch.n.03'), Synset('deathbed.n.02'), Synset('double_bed.n.01'), Synset('four-poster.n.01'), Synset('hammock.n.02'), Synset('marriage_bed.n.01'), Synset('murphy_bed.n.01'), Synset('plank-bed.n.01'), Synset('platform_bed.n.01'), Synset('sickbed.n.01'), Synset('single_bed.n.01'), Synset('sleigh_bed.n.01'), Synset('trundle_bed.n.01'), Synset('twin_bed.n.01'), Synset('water_bed.n.01')]
['Murphy_bed', 'berth', 'built-in_bed', 'built_in_bed', 'bunk', 'bunk_bed', 'camp_bed', 'cot', 'couch', 'deathbed', 'double_bed', 'four-poster', 'hammock', 'marriage_bed', 'plank-bed', 'platform_bed', 'sack', 'sickbed', 'single_bed', 'sleigh_bed', 'truckle', 'truckle_bed', 'trundle', 'trundle_bed', 'twin_bed', 'water_bed']
- 基于WordNet计算某种词性的多义性
以名词n为例:
from nltk.corpus import wordnet as wn
type = 'n' #动词v,副词r,形容词a
# 返回WordNet中所有type类型的同义词集
sysnets = wn.all_synsets(type)
# 将所有词条合并成一个大list
lemmas = []
for sysnet in sysnets:
for lemma in sysnet.lemmas():
lemmas.append(lemma.name())
# 删除重复词条,list=>set
lemmas = set(lemmas)
# 计算每个词条type类型的含义数并加到一起
count = 0
for lemma in lemmas:
count = count + len(wn.synsets(lemma,type)) # lemma在type类型下的所有含义
# 打印所有数值
print('%s总词条数: '%(type),len(lemmas))
print('%s总含义数: '%(type),count)
print('%s平均多义性: '%(type),count/len(lemmas))
输出:
n总词条数: 119034
n总含义数: 152763
n平均多义性: 1.2833560159282222
NLP(一)语料库和WordNet的更多相关文章
- nltk安装及wordnet使用详解
环境:python2.7.10 首先安装pip 在https://pip.pypa.io/en/stable/installing/ 下载get-pip.py 然后执行 python get-pip. ...
- 自然语言处理--nltk安装及wordnet使用详解
环境:python2.7.10 首先安装pip 在https://pip.pypa.io/en/stable/installing/ 下载get-pip.py 然后执行 python get-pip. ...
- 【NLP】大数据之行,始于足下:谈谈语料库知多少
大数据之行,始于足下:谈谈语料库知多少 作者:白宁超 2016年7月20日13:47:51 摘要:大数据发展的基石就是数据量的指数增加,无论是数据挖掘.文本处理.自然语言处理还是机器模型的构建,大多都 ...
- NLP语料库
文本语料库是一个大型结构化文本的集合 NLTK包含了许多语料库: (1)古滕堡语料库 (2)网络和聊天文本 (3)布朗语料库 (4)路透社语料库 (5)就职演讲语料库 (6)标注文本语料库 词汇列表 ...
- NLP—WordNet——词与词之间的最小距离
WordNet,是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典.它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”.我们这次的 ...
- lecture1-Word2vec实战班-七月在线nlp
nltk的全称是natural language toolkit,是一套基于python的自然语言处理工具集.自带语料库.词性分类库.自带分类分词等功能.强大社区支持.很多简单版wrapper 文本处 ...
- (Stanford CS224d) Deep Learning and NLP课程笔记(二):word2vec
本节课将开始学习Deep NLP的基础--词向量模型. 背景 word vector是一种在计算机中表达word meaning的方式.在Webster词典中,关于meaning有三种定义: the ...
- NLP十大里程碑
NLP十大里程碑 2.1 里程碑一:1985复杂特征集 复杂特征集(complex feature set)又叫做多重属性(multiple features)描写.语言学里,这种描写方法最早出现在语 ...
- 利用Tensorflow进行自然语言处理(NLP)系列之一Word2Vec
同步笔者CSDN博客(https://blog.csdn.net/qq_37608890/article/details/81513882). 一.概述 本文将要讨论NLP的一个重要话题:Word2V ...
随机推荐
- Android的简述4
NoteEditor深入分析 首先来弄清楚“日志编辑“的状态转换,通过上篇文章的方法来做下面这样一个实验,首先进入“日志编辑“时会触发onCreate和onResume,然后用户通过Option Me ...
- php的中文字符
在使用substr截取字符窜的时候出现乱码的问题 一直任认为字符串是2个字节,直到多次才尝试才总算知道问题所在 php的utf-8字符是每个字符3个字节 而gbk字符是每个字节2个字符 单个字母和符号 ...
- bootstrap开发响应式网页的常用的一些 类的说明
1.navbar-导航条 1.navbar-fixed-top,让导航条固定显示在页面上部(注意:固定的导航条会遮住代码,解决方案,给body设置padding-top的值[大于或等于]为我们导航条的 ...
- ES6--变量
声明变量 首先我们来回顾一下 es6 之前声明变量的方法:通常情况下,在 JavaScript 中,我们只有一种声明变量的关键字--var,我们使用 var 声明变量,使用 = 给变量赋值.在es6中 ...
- npm 一些有用的提示和技巧
生成 package.json 我们通常执行 npm init,然后开始添加 npm 请求的信息. 但是,如果我们不关心所有这些信息,并且希望保留默认值,那么对于 npm 请求的每一条数据,我们都按 ...
- pipreqs 生成requirements.txt文件时编码错误问题
1,首先安装pipreqs --> pip install pipreqs 2.生成相应项目的路径 --> pipreqs e:\a\b 在此时可能会遇见 UnicodeDecodeE ...
- ZDog:简单便捷好玩的的3D设计和动画制作库
各位老铁,我灰太狼又又又回来了,嘿嘿!!!!最近在忙所以有日子没写博客了,今天带大家看个好玩的东西 这个东西是今天偶尔看到的,是啥呢,难道是漂亮的小姐姐吗?当然是......不可能的了,这个东西其实就 ...
- java并发编程(十九)----(JUC集合)总体框架介绍
本节我们将继续学习JUC包中的集合类,我们知道jdk中本身自带了一套非线程安全的集合类,我们先温习一下java集合包里面的集合类,然后系统的看一下JUC包里面的集合类到底有什么不同. java集合类 ...
- GitHub项目:jkrasnay/sqlbuilder的使用
http://www.jianshu.com/p/7f099b8cf5f0 技术选型: 在报表查询时,通常需要做可以动态添加的条件 在老项目中使用的是一种Tcondition的对象分装sql impo ...
- ImageLoader_显示图片
public class MainActivity extends AppCompatActivity { private ListView lv; private List<Bean.Resu ...