hive on spark 释放session资源
背景

启动hive时,可以看到2.0以后的版本,将要弃用mr引擎,官方建议使用spark,tez等引擎。
spark同时支持批式流式处理,可以减少学习成本。所以选用了spark作为执行引擎。
hive on spark
- SET hive.execution.engine = spark;
参数优化
使用hive on spark 默认只用2个container。任务处理时间过长,或者报oom,或code2可以尝试修改如下的参数。
如下:
- set mapreduce.map.memory.mb = 8192;
- set mapreduce.reduce.memory.mb = 8192;
释放session资源
默认使用spark引擎,session资源是不会释放的。
1. 使用hive -f 执行sql文件
需要在sql文件的最后一行,添加
- quit
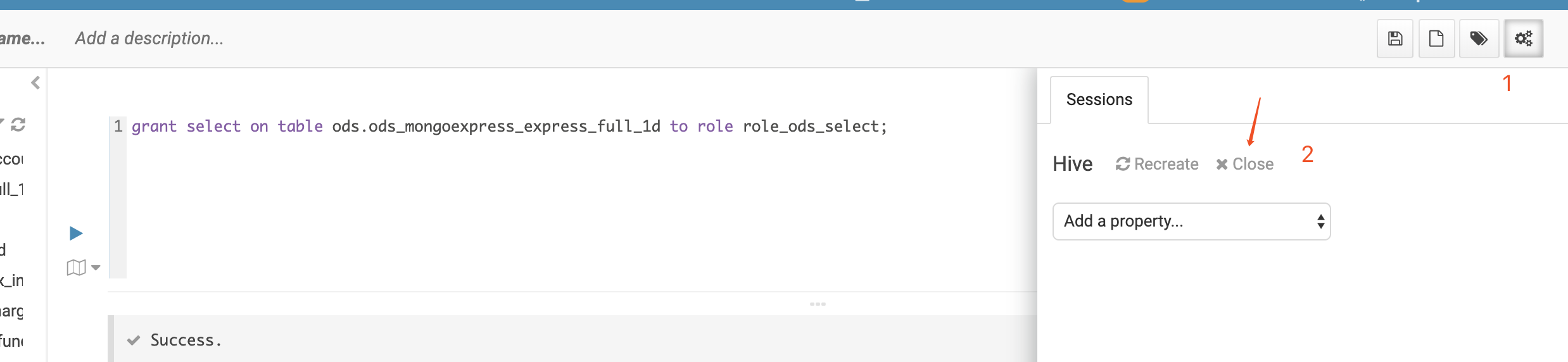
2. 在hue界面
点击会话右面的设置,可以close资源
hive on spark 释放session资源的更多相关文章
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- Hive On Spark概述
Hive现有支持的执行引擎有mr和tez,默认的执行引擎是mr,Hive On Spark的目的是添加一个spark的执行引擎,让hive能跑在spark之上: 在执行hive ql脚本之前指定执行引 ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- 基于CDH 5.9.1 搭建 Hive on Spark 及相关配置和调优
Hive默认使用的计算框架是MapReduce,在我们使用Hive的时候通过写SQL语句,Hive会自动将SQL语句转化成MapReduce作业去执行,但是MapReduce的执行速度远差与Spark ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 【原创】大数据基础之Hive(5)hive on spark
hive 2.3.4 on spark 2.4.0 Hive on Spark provides Hive with the ability to utilize Apache Spark as it ...
- hive on spark的坑
原文地址:http://www.cnblogs.com/breg/p/5552342.html 装了一个多星期的hive on spark 遇到了许多坑.还是写一篇随笔,免得以后自己忘记了.同事也给我 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
随机推荐
- 黄聪:mysql的SQL_CALC_FOUND_ROWS 使用 类似count(*) 使用性能更高
mysql的SQL_CALC_FOUND_ROWS 使用 类似count(*) 使用性能更高 在很多分页的程序中都这样写: SELECT COUNT(*) from `table` WHERE ... ...
- solr集群Server refused connection at: http://127.0.0.1:6060/solr/ego 注册zookeepr自动使用内网ip
引导:适用于各种注册服务,zookeeper和被注册的服务器不在同一ip上,产生的注册了127.0.0.1本地ip地址 在使用solr集群操作的时候,报了如下的错误 org.apache.solr.c ...
- toUpperCase(),toLowerCase()将字符串中的英文转换为全大写或全小写
package seday01;/** * String toUpperCase() * String toLowerCase() * 将字符串中的英文转换为全大写或全小写 * @author xin ...
- uni-app自定义Modal弹窗组件|仿ios、微信弹窗效果
介绍 uniapp自定义弹窗组件uniPop,基于uni-app开发的自定义模态弹窗|msg信息框|alert对话框|confirm确认框|toast弱提示框 支持多种动画效果.多弹窗类型ios/an ...
- 关于MySQL的一些骚操作——提升正确性,抠点性能
概要 回顾以前写的项目,发现在规范的时候,还是可以做点骚操作的. 假使以后还有新的项目用到了MySQL,那么肯定是要实践一番的. 为了准备,创建测试数据表(建表语句中默认使用utf8mb4以及utf8 ...
- [转]JVM系列二:GC策略&内存申请、对象衰老
原文地址:http://www.cnblogs.com/redcreen/archive/2011/05/04/2037056.html JVM里的GC(Garbage Collection)的算法有 ...
- 源码包安装转换rpm包
目录 纯净版虚拟机 1. 先安装个虚拟机,登陆nginx官网 http://nginx.org/选择一个稳定的版本 2. 右键复制地址,到新克隆的纯净虚拟机wget 下载 3.源码包 4.解压 tar ...
- 五分钟搞懂什么是B-树(全程图解)【转】
前戏 我们大家都知道动态查找树能够提高查找效率,比如:二叉查找树,平衡二叉查找树,红黑树.他们查找效率的时间复杂度O(log2n),跟树的深度有关系,那么怎么样才能提高效率呢?当然最快捷的方式就是减少 ...
- python爬虫(2)——urllib、get和post请求、异常处理、浏览器伪装
urllib基础 urlretrieve() urlretrieve(网址,本地文件存储地址) 直接下载网页到本地 import urllib.request #urlretrieve(网址,本地文件 ...
- mean shift聚类算法的MATLAB程序
mean shift聚类算法的MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. mean shift 简介 mean shift, 写的 ...