为什么Python 3.6以后字典有序并且效率更高?
在Python 3.5(含)以前,字典是不能保证顺序的,键值对A先插入字典,键值对B后插入字典,但是当你打印字典的Keys列表时,你会发现B可能在A的前面。
但是从Python 3.6开始,字典是变成有顺序的了。你先插入键值对A,后插入键值对B,那么当你打印Keys列表的时候,你就会发现B在A的后面。
不仅如此,从Python 3.6开始,下面的三种遍历操作,效率要高于Python 3.5之前:
for key in 字典
for value in 字典.values()
for key, value in 字典.items()
从Python 3.6开始,字典占用内存空间的大小,视字典里面键值对的个数,只有原来的30%~95%。
Python 3.6到底对字典做了什么优化呢?为了说明这个问题,我们需要先来说一说,在Python 3.5(含)之前,字典的底层原理。
当我们初始化一个空字典的时候,CPython的底层会初始化一个二维数组,这个数组有8行,3列,如下面的示意图所示:
my_dict = {}
'''
此时的内存示意图
[[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---]]
'''
现在,我们往字典里面添加一个数据:
my_dict['name'] = 'kingname'
'''
此时的内存示意图
[[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向kingname的指针],
[---, ---, ---],
[---, ---, ---]]
'''
这里解释一下,为什么添加了一个键值对以后,内存变成了这个样子:
首先我们调用Python 的hash函数,计算name这个字符串在当前运行时的hash值:
>>> hash('name')
1278649844881305901
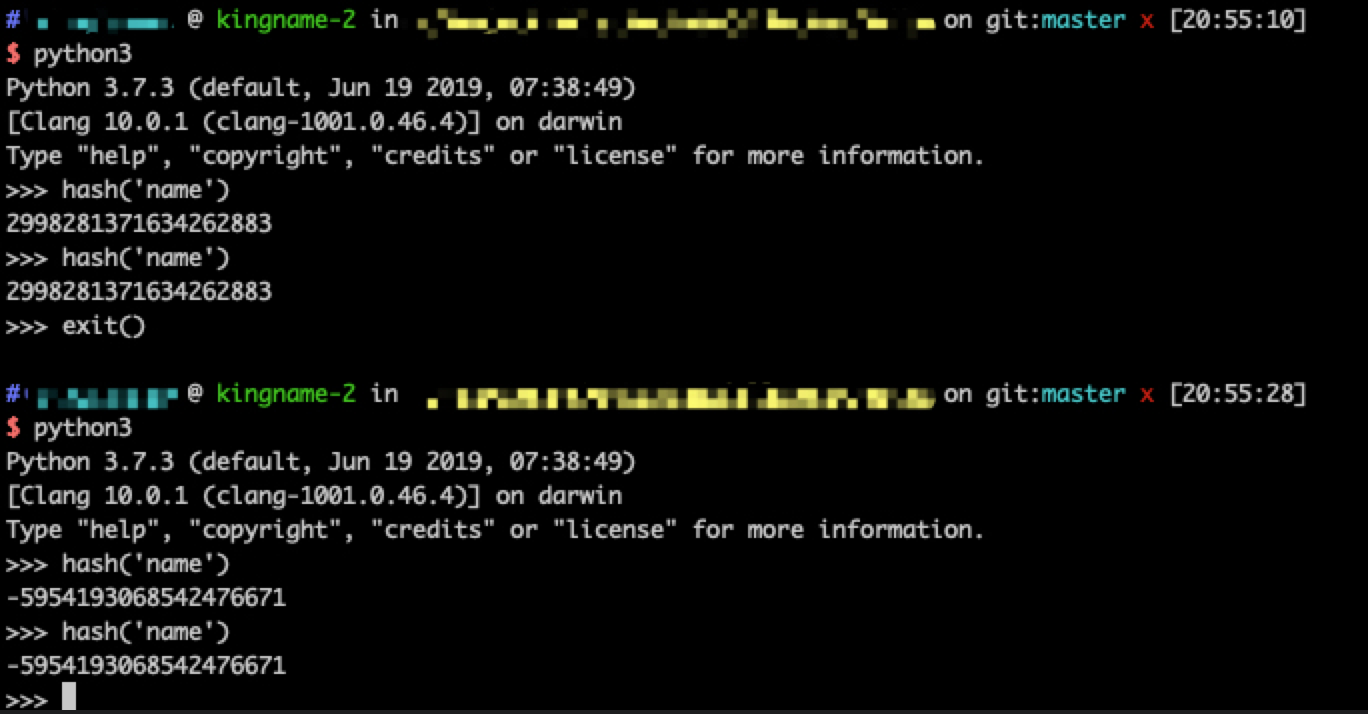
特别注意,我这里强调了『当前运行时』,这是因为,Python自带的这个hash函数,和我们传统上认为的Hash函数是不一样的。Python自带的这个hash函数计算出来的值,只能保证在每一个运行时的时候不变,但是当你关闭Python再重新打开,那么它的值就可能会改变,如下图所示:
假设在某一个运行时里面,hash('name')的值为1278649844881305901。现在我们要把这个数对8取余数:
>>> 1278649844881305901 % 8
5
余数为5,那么就把它放在刚刚初始化的二维数组中,下标为5的这一行。由于name和kingname是两个字符串,所以底层C语言会使用两个字符串变量存放这两个值,然后得到他们对应的指针。于是,我们这个二维数组下标为5的这一行,第一个值为name的hash值,第二个值为name这个字符串所在的内存的地址(指针就是内存地址),第三个值为kingname这个字符串所在的内存的地址。
现在,我们再来插入两个键值对:
my_dict['age'] = 26
my_dict['salary'] = 999999
'''
此时的内存示意图
[[-4234469173262486640, 指向salary的指针, 指向999999的指针],
[1545085610920597121, 执行age的指针, 指向26的指针],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向kingname的指针],
[---, ---, ---],
[---, ---, ---]]
'''
那么字典怎么读取数据呢?首先假设我们要读取age对应的值。
此时,Python先计算在当前运行时下面,age对应的Hash值是多少:
>>> hash('age')
1545085610920597121
现在这个hash值对8取余数:
>>> 1545085610920597121 % 8
1
余数为1,那么二维数组里面,下标为1的这一行就是需要的键值对。直接返回这一行第三个指针对应的内存中的值,就是age对应的值26。
当你要循环遍历字典的Key的时候,Python底层会遍历这个二维数组,如果当前行有数据,那么就返回Key指针对应的内存里面的值。如果当前行没有数据,那么就跳过。所以总是会遍历整个二位数组的每一行。
每一行有三列,每一列占用8byte的内存空间,所以每一行会占用24byte的内存空间。
由于Hash值取余数以后,余数可大可小,所以字典的Key并不是按照插入的顺序存放的。
注意,这里我省略了与本文没有太大关系的两个点:
- 开放寻址,当两个不同的Key,经过Hash以后,再对8取余数,可能余数会相同。此时Python为了不覆盖之前已有的值,就会使用
开放寻址技术重新寻找一个新的位置存放这个新的键值对。- 当字典的键值对数量超过当前数组长度的2/3时,数组会进行扩容,8行变成16行,16行变成32行。长度变了以后,原来的余数位置也会发生变化,此时就需要移动原来位置的数据,导致插入效率变低。
在Python 3.6以后,字典的底层数据结构发生了变化,现在当你初始化一个空的字典以后,它在底层是这样的:
my_dict = {}
'''
此时的内存示意图
indices = [None, None, None, None, None, None, None, None]
entries = []
'''
当你初始化一个字典以后,Python单独生成了一个长度为8的一维数组。然后又生成了一个空的二维数组。
现在,我们往字典里面添加一个键值对:
my_dict['name'] = 'kingname'
'''
此时的内存示意图
indices = [None, 0, None, None, None, None, None, None]
entries = [[-5954193068542476671, 指向name的指针, 执行kingname的指针]]
'''
为什么内存会变成这个样子呢?我们来一步一步地看:
在当前运行时,name这个字符串的hash值为-5954193068542476671,这个值对8取余数是1:
>>> hash('name')
-5954193068542476671
>>> hash('name') % 8
1
所以,我们把indices这个一维数组里面,下标为1的位置修改为0。
这里的0是什么意思呢?0是二位数组entries的索引。现在entries里面只有一行,就是我们刚刚添加的这个键值对的三个数据:name的hash值、指向name的指针和指向kinganme的指针。所以indices里面填写的数字0,就是刚刚我们插入的这个键值对的数据在二位数组里面的行索引。
好,现在我们再来插入两条数据:
my_dict['address'] = 'xxx'
my_dict['salary'] = 999999
'''
此时的内存示意图
indices = [1, 0, None, None, None, None, 2, None]
entries = [[-5954193068542476671, 指向name的指针, 执行kingname的指针],
[9043074951938101872, 指向address的指针,指向xxx的指针],
[7324055671294268046, 指向salary的指针, 指向999999的指针]
]
'''
现在如果我要读取数据怎么办呢?假如我要读取salary的值,那么首先计算salary的hash值,以及这个值对8的余数:
>>> hash('salary')
7324055671294268046
>>> hash('salary') % 8
6
那么我就去读indices下标为6的这个值。这个值为2.
然后再去读entries里面,下标为2的这一行的数据,也就是salary对应的数据了。
新的这种方式,当我要插入新的数据的时候,始终只是往entries的后面添加数据,这样就能保证插入的顺序。当我们要遍历字典的Keys和Values的时候,直接遍历entries即可,里面每一行都是有用的数据,不存在跳过的情况,减少了遍历的个数。
老的方式,当二维数组有8行的时候,即使有效数据只有3行,但它占用的内存空间还是 8 * 24 = 192 byte。但使用新的方式,如果只有三行有效数据,那么entries也就只有3行,占用的空间为3 * 24 =72 byte,而indices由于只是一个一维的数组,只占用8 byte,所以一共占用 80 byte。内存占用只有原来的41%。
为什么Python 3.6以后字典有序并且效率更高?的更多相关文章
- python数据结构-如何让字典有序
如何让字典有序 问题举例: 统计学生的成绩和名次,让其在字典中按排名顺序有序显示,具体格式如下 {'tom':(1, 99), 'lily':(2, 98), 'david':(3, 95)} 说明 ...
- Python窗口学习之使窗口变得更高清
初学tkinter发现窗口并不像成熟软件那么清楚 在实例化window后加这一行代码 #使窗口更加高清 # 告诉操作系统使用程序自身的dpi适配 ctypes.windll.shcore.SetPro ...
- .Net程序员之Python基础教程学习----字典的使用 [Third Day]
今天学习了字典的使用, 所谓的字典其实就是键值对数据, 一个字典里面有唯一的Key对应一个value,Key是唯一的,Value不唯一. 在.net添加相同的Key会报错,在Python,若出现相 ...
- 零基础入门学习Python(26)--字典:当索引不好用时2
知识点 删除字典元素 能删单一的元素也能清空字典,清空只需一项操作. 显示删除一个字典用del命令,如下: >>> dict1 = {'a':1,'b':2,'c':3} >& ...
- 流畅的python第三章字典和集合学习记录
什么是可散列的数据类型 如果一个对象是可散列的,那么在这个对象的生命周期中,他的散列值是不变的,而且这个对象需要实现__hash__()方法.另外可散列对象还要有__qe__()方法.这样才能跟其他键 ...
- python内置数据类型-字典和列表的排序 python BIT sort——dict and list
python中字典按键或键值排序(我转!) 一.字典排序 在程序中使用字典进行数据信息统计时,由于字典是无序的所以打印字典时内容也是无序的.因此,为了使统计得到的结果更方便查看需要进行排序. Py ...
- python基本数据类型之字典
python基本数据类型之字典 python中的字典是以键(key)值(value)对的形式储存数据,基本形式如下: d = {'Bart': 95, 'Michael': 34, 'Lisa': 5 ...
- 6 - Python内置结构 - 字典
目录 1 字典介绍 2 字典的基本操作 2.1 字典的定义 2.2 字典元素的访问 2.3 字典的增删改 3 字典遍历 3.1 遍历字典的key 3.2 遍历字典的value 3.3 变量字典的键值对 ...
- Python - 基础数据类型 dict 字典
字典简介 字典在 Python 里面是非常重要的数据类型,而且很常用 字典是以关键字(键)为索引,关键字(键)可以是任意不可变类型 字典由键和对应值成对组成,字典中所有的键值对放在 { } 中间,每一 ...
随机推荐
- CSS,让100%的宽度,自动减10,让100%的高度,自动减10,可以加减乘除
CSS,让100%的宽度,自动减10,让100%的高度,自动减10,可以加减乘除 实例: .add{ width: calc(100% - 10px); height: calc(100% - 10p ...
- C#图片保存与读取,以及图片另存
照片的保存与读取 /// <summary> /// 图片转二进制 /// </summary> /// <param name="imgPhoto" ...
- 用C#修改系统区域和语言设置
原文:用C#修改系统区域和语言设置 这几天做项目,因为客户机的系统不同,发现客户机的区域和语言设置也不尽相同,导致程序运行时根据时间判断的很多属性和方法都出现各种各样的千奇百怪的问题. 修改程序太费时 ...
- Windows下获取高精度时间注意事项 [转贴 AdamWu]
花了很长时间才得到的经验,与大家分享. 1. RDTSC - 粒度: 纳秒级 不推荐优势: 几乎是能够获得最细粒度的计数器抛弃理由: A) 定义模糊 - 曾经据说是处理器的cycle counter, ...
- Excel求值表达式——太好用了
这个需要通过宏表函数EVALUATE来实现,首先需要自定义名称.如果数据在A列,那么在B列自定义名称,按Ctrl+F3键,在“定义名称框”中选择“新建”,然后输入名称为“结果”,数据来源输入=EVAL ...
- Microsoft.Ace.OleDb.12.0 操作excel
在用c#操作excel的时候,碰到了一下的问题: 1.Microsoft.Ace.OleDb.12.0未安装,可以到下载2007 Office system 驱动程序AccessDatabaseEng ...
- Codility----PassingCars
Task description A non-empty zero-indexed array A consisting of N integers is given. The consecutive ...
- windows 消息列表
private const UInt32 WM_ACTIVATE = 0x0006; private const UInt32 WM_ACTIVATEAPP = 0x001C; private con ...
- 判断本地系统目录下是否存在XML文件,如果不存在就创建一个XMl文件,若存在就在里面执行添加数据
这是我为项目中写的一个测试的例子, 假如,您需要这样一个xml文件, <?xml version="1.0" encoding="utf-8"?> ...
- 30442数据操纵语言DML
5.5 SQL的数据操纵功能 5.5.1 数据插入 使用CREATE语句创建的数据表还只是一个“空壳”,表中没有任何数据.利用SQL语言提供的INSERT语句可以完成向数据表插入数据的任务. INSE ...