Scrapy爬取豆瓣图书数据并写入MySQL
项目地址 BookSpider
介绍
本篇涉及的内容主要是获取分类下的所有图书数据,并写入MySQL
准备
Python3.6、Scrapy、Twisted、MySQLdb等
演示
代码
一、创建项目
scrapy startproject BookSpider #创建项目
scrapy genspider douban book.douban.com #创建豆瓣爬虫
二、创建测试类(main.py)
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'douban'])
三、修改配置(spiders/settings.py)
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36' #浏览器
ROBOTSTXT_OBEY = False #不遵循豆瓣网站的爬虫协议
四、设置爬取的分类(spiders/douban.py)
start_urls = ['https://book.douban.com/tag/神经网络'] # 只测试爬取神经网络
五、获取分类列表页图书数据

from scrapy.http import Request
from urllib.parse import urljoin
def parse(self, response):
get_nodes = response.xpath('//div[@id="subject_list"]/ul/li/div[@class="pic"]/a')
for node in get_nodes:
url = node.xpath("@href").get()
img_url = node.xpath('img/@src').get()
yield Request(url=url, meta={"img_url": img_url}, callback=self.parse_book) # 传递img_url值 放在meta里面, parse_book回调函数,获取的详情再分析
next_url = response.xpath('//div[@class="paginator"]/span[@class="next"]/a/@href').get() # 获取下一页地址
if(next_url):
yield Request(url=urljoin(response.url, next_url), callback=self.parse) # 获取下一页内容
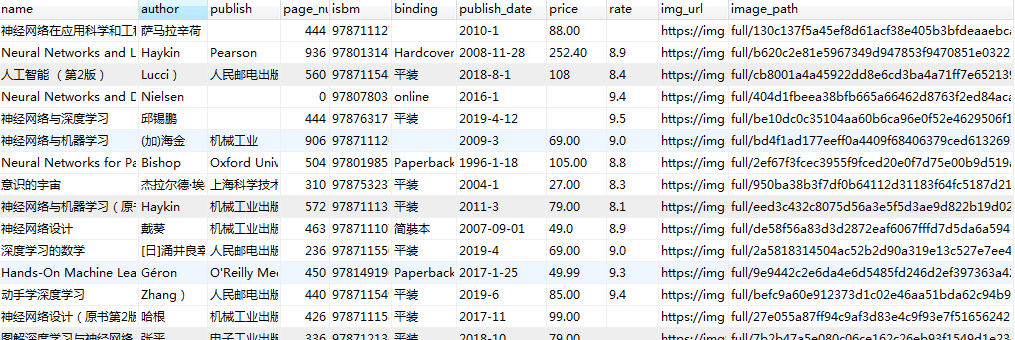
六、定义数据模型(spiders/items.py)
class BookspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
author = scrapy.Field()
publish = scrapy.Field()
page_num = scrapy.Field()
isbm = scrapy.Field()
binding = scrapy.Field()
publish_date = scrapy.Field()
price = scrapy.Field()
rate = scrapy.Field()
img_url = scrapy.Field()
image_path = scrapy.Field()
七、获取图书详情数据
import re
from BookSpider.items import BookspiderItem
def parse_book(self, response):
BookItem = BookspiderItem()
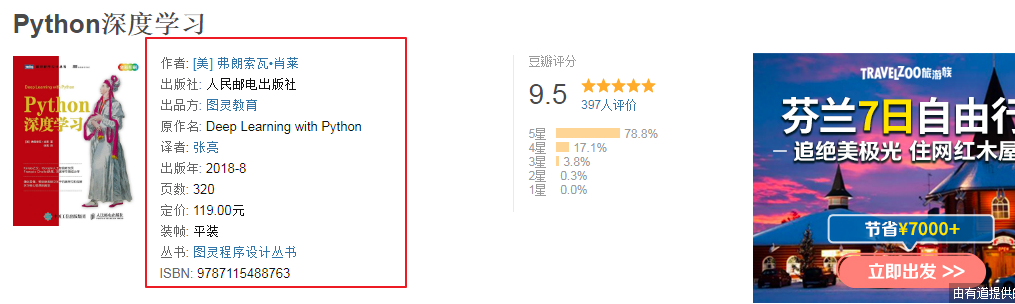
BookItem['name'] = response.xpath('//span[@property="v:itemreviewed"]/text()').get("").strip()
BookItem['author'] = response.xpath('//span[contains(text(), "作者")]/following-sibling::a[1]/text()').get("").split()[-1]
BookItem['publish'] = response.xpath('//span[contains(text(), "出版社")]/following-sibling::text()').get("").strip()
page_num = response.xpath('//span[contains(text(), "页数")]/following-sibling::text()').get("").strip()
BookItem['page_num'] = 0 if(page_num == '') else page_num
BookItem['isbm'] = response.xpath('//span[contains(text(), "ISBN")]/following-sibling::text()').get("").strip()
BookItem['binding'] = response.xpath('//span[contains(text(), "装帧")]/following-sibling::text()').get("").strip()
BookItem['publish_date'] = response.xpath('//span[contains(text(), "出版年")]/following-sibling::text()').get("").strip()
price = response.xpath('//span[contains(text(), "定价")]/following-sibling::text()').get("").strip()
BookItem['price'] = '' if(len(price) == 0) else re.findall(r'\d+\.?\d*', price)[0]
BookItem['rate'] = response.xpath('//div[contains(@class, "rating_self ")]/strong/text()').get("").strip()
BookItem['img_url'] = [response.meta.get('img_url')] #图片是列表
yield BookItem
八、下载图片
1、创建images文件加
2、配置spiders/settings.py
ITEM_PIPELINES = {
'BookSpider.pipelines.ImageStorePipeline': 1, #后面的数据是优先级
}
IMAGES_URLS_FIELD = "image_url"
IMAGES_STORE = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'images')
3、创建ImageStorePipeline类(spiders/pipelines.py)
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
class ImageStorePipeline(ImagesPipeline):
default_headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', #这个一定要
}
def get_media_requests(self, item, info):
for image_url in item['img_url']:
self.default_headers['referer'] = image_url
yield Request(image_url, headers=self.default_headers)
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem("Item contains no images")
item['image_path'] = image_path
return item
八、写入数据库
1、配置spiders/settings.py
#设置数据库
MYSQL_HOST = ""
MYSQL_DBNAME = ""
MYSQL_USER = ""
MYSQL_PASSWORD = ""
ITEM_PIPELINES = {
'BookSpider.pipelines.ImageStorePipeline': 1,
'BookSpider.pipelines.MysqlTwistedPipeline': 30,
}
2、创建MysqlTwistedPipeline类(spiders/pipelines.py)
import MySQLdb.cursors
from twisted.enterprise import adbapi
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod #静态方法,会优先执行from_settings, 这样self.dbpool就有值了
def from_settings(cls, settings):
dbpool = adbapi.ConnectionPool("MySQLdb", host=settings['MYSQL_HOST'], db = settings['MYSQL_DBNAME'], user = settings['MYSQL_USER'], passwd = settings['MYSQL_PASSWORD'], charset = 'utf8', cursorclass = MySQLdb.cursors.DictCursor, use_unicode = True)
return cls(dbpool)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error,item,spider)
def do_insert(self, cursor, item):
insert_sql = """
insert into douban(name, author, publish, page_num, isbm, binding, publish_date, price, rate, img_url, image_path)
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(insert_sql, (item['name'], item['author'], item['publish'], item['page_num'], item['isbm'], item['binding'], item['publish_date'], item['price'], item['rate'], item['img_url'], item['image_path']))
def handle_error(self, failure, item, spider):
print(failure)
九、测试
1、执行main.py文件
Scrapy爬取豆瓣图书数据并写入MySQL的更多相关文章
- python系列之(3)爬取豆瓣图书数据
上次介绍了beautifulsoup的使用,那就来进行运用下吧.本篇将主要介绍通过爬取豆瓣图书的信息,存储到sqlite数据库进行分析. 1.sqlite SQLite是一个进程内的库,实现了自给自足 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- requests+正则爬取豆瓣图书
#requests+正则爬取豆瓣图书 import requests import re def get_html(url): headers = {'User-Agent':'Mozilla/5.0 ...
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- 爬虫之爬取豆瓣图书名字及ID
from urllib import request from bs4 import BeautifulSoup as bs #爬取豆瓣最受关注图书榜 resp = request.urlopen(' ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
随机推荐
- Rust到底值不值得学--Rust对比、特色和理念
前言 其实我一直弄不明白一点,那就是计算机技术的发展,是让这个世界变得简单了,还是变得更复杂了. 当然这只是一个玩笑,可别把这个问题当真. 然而对于IT从业者来说,这可不是一个玩笑.几乎每一次的技术发 ...
- Inkscape 旋转并复制
画一个图形,点击图标. 然后图标中心有个十字叉, 然后把这个十字叉拖到你想要旋转的地方. 然后shift+ctrl+m打开变换菜单. 选择旋转选项卡,然后设置角度,点击应用.就可以旋转了,如果配合ct ...
- .NET斗鱼直播弹幕客户端(下)
.NET斗鱼直播弹幕客户端(下) 在上篇文章中,我们提到了如何使用.NET连接斗鱼TV直播弹幕的基本操作.然而想要做得好,做得容易扩展,就需要做进一步的代码整理. 本文将涉及以下内容: 介绍如何使用R ...
- java中的Collection和Collections
Collection是集合类的上级接口,继承他的接口主要有Set和List. Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索.排序.线程安全化等操作.
- python编程基础之三十四
面向对象:三大特征:封装,继承,多态 封装:隐藏对象的实现过程,对外仅仅公开接口,控制在程序中的读取和修改的访问级别 类,函数都是一种封装 属性私有化:当类里面的属性不想被外部访问,可以将这些属性设置 ...
- windows下使用Jenkins+Gitea持续集成
关于Jenkins持续集成: 一.Gitea 1)https://git-scm.com/download/win下载Git并安装 https://gitea.io/zh-cn/ 下载Gitea私人仓 ...
- hihoCode 1075 : 开锁魔法III
时间限制:6000ms 单点时限:1000ms 内存限制:256MB 描述 一日,崔克茜来到小马镇表演魔法. 其中有一个节目是开锁咒:舞台上有 n 个盒子,每个盒子中有一把钥匙,对于每个盒子而言有且仅 ...
- TensorFlow2.0(7):激活函数
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Lombok中关于@Data的使用
当你在使用 Lombok 的 @Data 注解时,其实会有一些坑需要关注,今天就让我们来见识一下. Lombok 先来简单介绍一下 Lombok ,其官方介绍如下: Project Lombok ma ...
- 渗透测试-基于白名单执行payload--Forfiles
0x01 Forfiles简介: Forfiles为Windows默认安装的文件操作搜索工具之一,可根据日期,后缀名,修改日期为条件.常与批处理配合使用. 微软官方文档:https://docs.mi ...