百万年薪python之路 -- 并发编程之 多进程二
1. 僵尸进程和孤儿进程
基于unix的环境(linux,macOS)
主进程需要等待子进程结束之后,主进程才结束
主进程时刻检测子进程的运行状态,当子进程结束之后,一段时间之内,将子进程进行回收.
为什么主进程不在子进程结束后马上对其回收呢?
- 主进程与子进程是异步关系,主进程无法马上捕获子进程什么时候结束
- 如果子进程结束之后马上在内存中释放资源,主进程就没有办法检测子进程的状态.
Unix针对于上面的问题提供了一个机制
- 所有的子进程结束之后,立马会释放掉文件的操作链接和内存的大部分数据,但是会保留一些内容: 进程号,结束时间,运行状态,等待主进程检测和回收.
僵尸进程: 在父进程生命周期之内,所有的子进程结束之后,被主进程回收之前,都会进入僵尸进程状态
僵尸进程有无危害???
- 如果父进程不对僵尸进程进行回收(wait/waitpid),产生大量的僵尸进程,这样就会占用内容,占用进程pid号
孤儿进程
- 父进程由于某种原因结束了,但是子进程还在运行中,这样这些进程就变成了孤儿进程. 当父进程结束了,init进程接管后就变成了孤儿进程的父进程,所有的孤儿进程都会被init进程(进程号为1)回收.
僵尸进程如何解决???
- 父进程产生了大量子进程,但是不回收,这样就会形成大量的僵尸进程,解决方式就是直接杀死父进程,将所有的僵尸进程变成孤儿进程,由init进行回收.
2. 互斥锁(保证数据安全, 自己加锁容易出现死锁.)
(以下进程是一个统称概念,可以指进程或线程)
互斥锁: 指散布在不同进程之间的若干程序片断,当某个进程运行其中一个程序片段时,其它进程就不能运行它们之中的任一程序片段,只能等到该进程运行完这个程序片段后才可以运行的一种类似于"锁"的机制互斥锁的作用:就是在保证子进程串行的同时,也保证了子进程执行顺序的随机性,以及数据的安全性
假设有三个同事,同时用于一个打印机打印内容
# 三个进程模拟三个同事,输出平台模拟打印机
# 版本一
from multiprocessing import Process
from multiprocessing import Lock
import time
import random
import os
def task():
print(f"{os.getpid()}开始打印了")
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}打印结束了")
if __name__ == '__main__':
p1 = Process(target=task)
p2 = Process(target=task)
p3 = Process(target=task)
p1.start()
p2.start()
p3.start()
# 结果是打印混乱
# 现在是所有的进程都并发的抢占打印机,
# 并发是以效率优先的,但是目前我们的需求: 顺序优先.
# 多个进程共强一个资源时, 要保证顺序优先: 串行,一个一个来.# 版本二
from multiprocessing import Process
from multiprocessing import Lock
import time
import random
import os
def task():
print(f"{os.getpid()}开始打印了")
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}打印结束了")
if __name__ == '__main__':
p1 = Process(target=task)
p2 = Process(target=task)
p3 = Process(target=task)
p1.start()
p1.join()
p2.start()
p1.join()
p3.start()
p3.join()
# 我们利用join 解决串行的问题,保证了顺序优先,但是这个谁先谁后是固定的.
# 这样不合理. 你在争抢同一个资源的时候,应该是先到先得,保证公平.# 版本三
from multiprocessing import Process
from multiprocessing import Lock
import time
import random
import os
def task(p,lock):
'''
一把锁不能连续锁两次
lock.acquire()
lock.acquire()
lock.release()
lock.release()
'''
lock.acquire()
print(f"{p}开始打印了")
time.sleep(random.randint(1, 3))
print(f"{p}打印结束了")
lock.release()
if __name__ == '__main__':
lock = Lock()
p1 = Process(target=task,args=("p1",lock))
p2 = Process(target=task,args=("p2",lock))
p3 = Process(target=task,args=("p3",lock))
p1.start()
p2.start()
p3.start()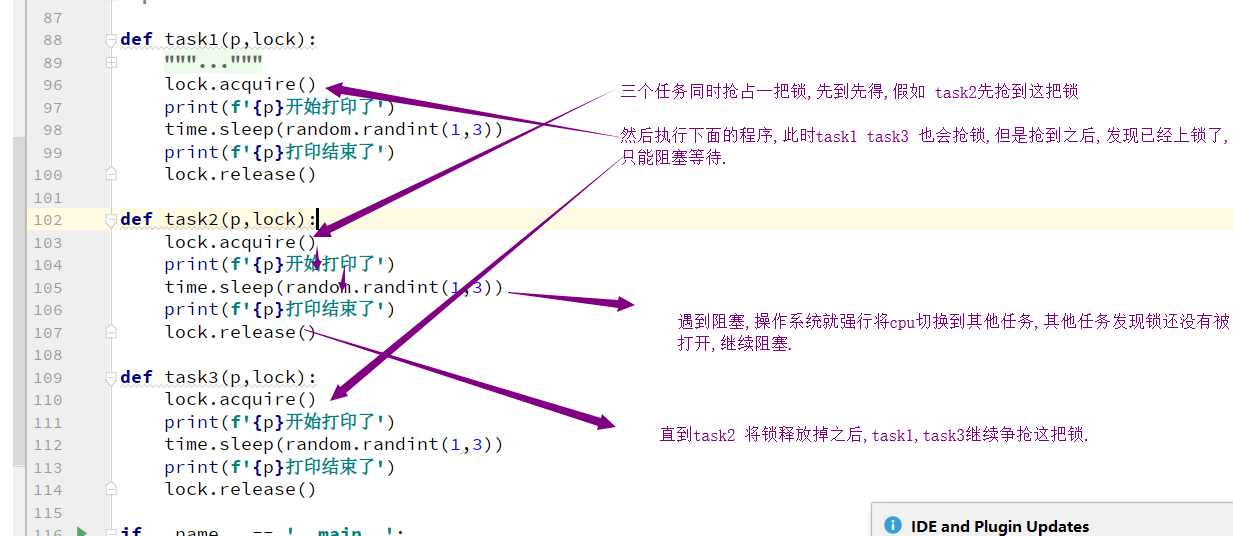
lock和join的区别.
共同点: 都可以把并发变成串行,保证了顺序.
不同点: join人为的设定顺序,lock让其争抢顺序,保证了公平性.
3. 进程之间的通信
进程在内存级别是隔离的,但是文件在磁盘上.
1. 基于文件通信.
# 抢票系统.
# 1. 先可以查票.查询余票数. 并发
# 2. 进行购买,向服务端发送请求,服务端接收请求,在后端将票数-1,返回到前端. 串行.
from multiprocessing import Process
from multiprocessing import Lock
import json
import time
import random
import os
def search():
time.sleep(random.randint(1,3)) # 模仿网络延迟(查询环节)
with open("db",encoding="utf-8") as f:
dic = json.load(f)
print(f"{os.getpid()} 查看了票数,剩余{dic['count']}")
def paid():
with open("db","r",encoding="utf-8") as f:
dic = json.load(f)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) # 模拟网络延迟(购买环节)
with open("db","w",encoding="utf-8") as f:
json.dump(dic,f)
print(f"{os.getpid()} 购买成功!")
def task(lock):
search()
paid()
if __name__ == '__main__':
mutex = Lock()
for i in range(10):
p = Process(target=task,args=(mutex,))
p.start()
# 当多个进程共抢一个数据时,如果要保证数据的安全,必须要串行.
# 要想让购买环节进行串行,我们必须要加锁处理.
# 抢票系统.
# 1. 先可以查票.查询余票数. 并发
# 2. 进行购买,向服务端发送请求,服务端接收请求,在后端将票数-1,返回到前端. 串行.
from multiprocessing import Process
from multiprocessing import Lock
import json
import time
import random
import os
def search():
time.sleep(random.randint(1,3)) # 模仿网络延迟(查询环节)
with open("db",encoding="utf-8") as f:
dic = json.load(f)
print(f"{os.getpid()} 查看了票数,剩余{dic['count']}")
def paid():
with open("db","r",encoding="utf-8") as f:
dic = json.load(f)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) # 模拟网络延迟(购买环节)
with open("db","w",encoding="utf-8") as f:
json.dump(dic,f)
print(f"{os.getpid()} 购买成功!")
def task(lock):
search()
lock.acquire()
paid()
lock.release()
if __name__ == '__main__':
mutex = Lock()
for i in range(10):
p = Process(target=task,args=(mutex,))
p.start()
# 当很多进程共强一个资源(数据)时, 你要保证顺序(数据的安全),一定要串行.
# 互斥锁: 可以公平性的保证顺序以及数据的安全.
# 基于文件的进程之间的通信:
# 效率低.
# 自己加锁麻烦而且很容易出现死锁.2. 基于队列通信. (真正会用到)
进程彼此之间互相隔离,要实现进程间通信(IPC)(inter-Process Communication),multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的
创建队列的类(底层就是以管道和绑定的方式实现):
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。参数介绍
maxsize是队列中允许最大项数,省略则无大小限制方法介绍:
主要方法:
1 q.put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
2 q.get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常.
3
4 q.get_nowait():同q.get(False)
5 q.put_nowait():同q.put(False)
6
7 q.empty():调用此方法时q为空则返回True,该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。
8 q.full():调用此方法时q已满则返回True,该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。
9 q.qsize():返回队列中目前项目的正确数量,结果也不可靠,理由同q.empty()和q.full()一样其他方法(了解):
1 q.cancel_join_thread():不会在进程退出时自动连接后台线程。可以防止join_thread()方法阻塞
2 q.close():关闭队列,防止队列中加入更多数据。调用此方法,后台线程将继续写入那些已经入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将调用此方法。关闭队列不会在队列使用者中产生任何类型的数据结束信号或异常。例如,如果某个使用者正在被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
3 q.join_thread():连接队列的后台线程。此方法用于在调用q.close()方法之后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread方法可以禁止这种行为
应用:
from multiprocessing import Process
import time
q = Queue(3)
q.put(3)
q.put(3)
q.put(3)
print(q.full()) # 满了
print(q.get())
print(q.get())
print(q.get())
print(q.empty()) # 空了
q.put(3)
q.put(3)
q.put(3)
q.put(3) # 在这阻塞住了,下面的方法不会执行
q.get(3)
3. 基于管道的通信
介绍:
#创建管道的类:
Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
#参数介绍:
dumplex:默认管道是全双工的,如果将duplex射成False,conn1只能用于接收,conn2只能用于发送。
#主要方法:
conn1.recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
conn1.send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
#其他方法:
conn1.close():关闭连接。如果conn1被垃圾回收,将自动调用此方法
conn1.fileno():返回连接使用的整数文件描述符
conn1.poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout射成None,操作将无限期地等待数据到达。
conn1.recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
conn.send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收
conn1.recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
from multiprocessing import Process,Pipe
import time,os
def consumer(p,name):
left,right=p
left.close()
while True:
try:
baozi=right.recv()
print('%s 收到包子:%s' %(name,baozi))
except EOFError:
right.close()
break
def producer(seq,p):
left,right=p
right.close()
for i in seq:
left.send(i)
# time.sleep(1)
else:
left.close()
if __name__ == '__main__':
left,right=Pipe()
c1=Process(target=consumer,args=((left,right),'c1'))
c1.start()
seq=(i for i in range(10))
producer(seq,(left,right))
right.close()
left.close()
c1.join()
print('主进程')
基于管道实现进程间通信(与队列的方式是类似的,队列就是管道加锁实现的)
但是,管道是有问题的,管道会造成数据的不安全,官方给予的解释是管道有可能会造成数据损坏。
百万年薪python之路 -- 并发编程之 多进程二的更多相关文章
- 百万年薪python之路 -- 并发编程之 多进程 一
并发编程之 多进程 一. multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大 ...
- 百万年薪python之路 -- 并发编程之 多线程 二
1. 死锁现象与递归锁 进程也有死锁与递归锁,进程的死锁和递归锁与线程的死锁递归锁同理. 所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因为争夺资源而造成的一种互相等待的现象,在无外力的作用 ...
- 百万年薪python之路 -- 并发编程之 协程
协程 一. 协程的引入 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两 ...
- 百万年薪python之路 -- 并发编程之 多线程 三
1. 阻塞,非阻塞,同步,异步 进程运行的三个状态: 运行,就绪,阻塞. 从执行的角度: 阻塞: 进程运行时,遇到IO了,进程挂起,CPU被切走. 非阻塞: 进程没有遇到IO 当进程遇到IO, ...
- 百万年薪python之路 -- 并发编程之 多线程 一
多线程 1.进程: 生产者消费者模型 一种编程思想,模型,设计模式,理论等等,都是交给你一种编程的方法,以后遇到类似的情况,套用即可 生产者与消费者模型的三要素: 生产者:产生数据的 消费者:接收数据 ...
- python并发编程之多进程二
一,multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程.P ...
- python并发编程之多进程(二):互斥锁(同步锁)&进程其他属性&进程间通信(queue)&生产者消费者模型
一,互斥锁,同步锁 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的, 竞争带来的结果就是错乱,如何控制,就是加锁处理 part1:多个进程共享同一打印终 ...
- 百万年薪python之路 -- 数据库初始
一. 数据库初始 1. 为什么要有数据库? 先来一个场景: 假设现在你已经是某大型互联网公司的高级程序员,让你写一个火车票购票系统,来hold住十一期间全国的购票需求,你怎么写? 由于在同一时 ...
- 百万年薪python之路 -- Socket
Socket 1. 为什么学习socket 你自己现在完全可以写一些小程序了,但是前面的学习和练习,我们写的代码都是在自己的电脑上运行的,虽然我们学过了模块引入,文件引入import等等,我可以在程序 ...
随机推荐
- python接口测试(post,get)-传参(data和json之间的区别)
python接口测试如何正确传参: POST 传data:data是python字典格式:传参data=json.dumps(data)是字符串类型传参 #!/usr/bin/env python3 ...
- nginx如何配置负载均衡
自己学习用 面试回答如下: 在nginx里面配置一个upstream,然后把相关的服务器ip都配置进去.然后采用轮询的方案,然后在nginx里面的配置项里,proxy-pass指向这个upstream ...
- Java网络编程--Netty中的责任链
Netty中的责任链 设计模式 - 责任链模式 责任链模式(Chain of Responsibility Pattern)是一种是行为型设计模式,它为请求创建了一个处理对象的链.其链中每一个节点都看 ...
- 使用mkfs.ext4格式化大容量磁盘
使用mkfs.ext4默认参数格式化磁盘后,发现格式化时间特别长,并且格式化会占用磁盘很大的空间.例如2TB的磁盘格式化会占用10分钟左右时间,并占用30G左右的磁盘空间.究其原因,原来inode会占 ...
- jenkins自动化部署项目1--下载安装启动(windows)
年初以来断断续续研究jenkins自动化部署项目,前些天终于搞定了,接下来一点点把做的时候遇到的坑以及自己的心得写下来,方便以后复用. 我的jenkins服务是是部署在windows上的 一.下载安装 ...
- 暑期——第九周总结(1,林子雨老师关于hdfs eclipse案例报错问题【已解决】)
所花时间:7天 代码行:1000(Java)+500(Python)+300(C++) 博客量:1篇 了解到知识点 : 一: 解决"Class org.apache.hadoop.hdfs. ...
- 网关鉴权后下游统一filter获取用户信息
1. 场景描述 最近有点忙,在弄微服务nacos+springcloud gateway这块工作,以前只是简单应用,这次因为要对接10几个系统或者平台,还的鉴权,等后续稍微闲点了,把这块东西总结下. ...
- spring后台重定向方式
1.直接返回值中加重定向:"redirect:要访问的网址"; public String updateOrAddProject() { return "redirect ...
- Python常用端口扫描
from socket import * import sys host=sys.argv[1] service={':'HTTP', ':'SQL_Server', ':'Remote_Destop ...
- ELK 学习笔记之 Logstash基本语法
Logstash基本语法: 处理输入的input 处理过滤的filter 处理输出的output 区域 数据类型 条件判断 字段引用 区域: Logstash中,是用{}来定义区域 区域内,可以定义插 ...