elastic search(es)安装
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
一、安装
Elastic 需要 Java 8 环境。如果你的机器还没安装 Java,可以参考这篇文章,注意要保证环境变量JAVA_HOME正确设置。
java7 应该也能使用。
》》》在linux中进行安装:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.1.zip
$ unzip elasticsearch-5.5.1.zip
$ cd elasticsearch-5.5.1/
接着,进入解压后的目录,运行下面的命令,启动 Elastic。
$ ./bin/elasticsearch
如果这时报错"max virtual memory areas vm.maxmapcount [65530] is too low",要运行下面的命令。
$ sudo sysctl -w vm.max_map_count=262144
如果一切正常,Elastic 就会在默认的9200端口运行。这时,打开另一个命令行窗口,请求该端口,会得到说明信息。
$ curl localhost:9200 {
"name" : "atntrTf",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "tf9250XhQ6ee4h7YI11anA",
"version" : {
"number" : "5.5.1",
"build_hash" : "19c13d0",
"build_date" : "2017-07-18T20:44:24.823Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
按下 Ctrl + C,Elastic 就会停止运行。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
》》》》在windows中进行安装:
修改配置文件
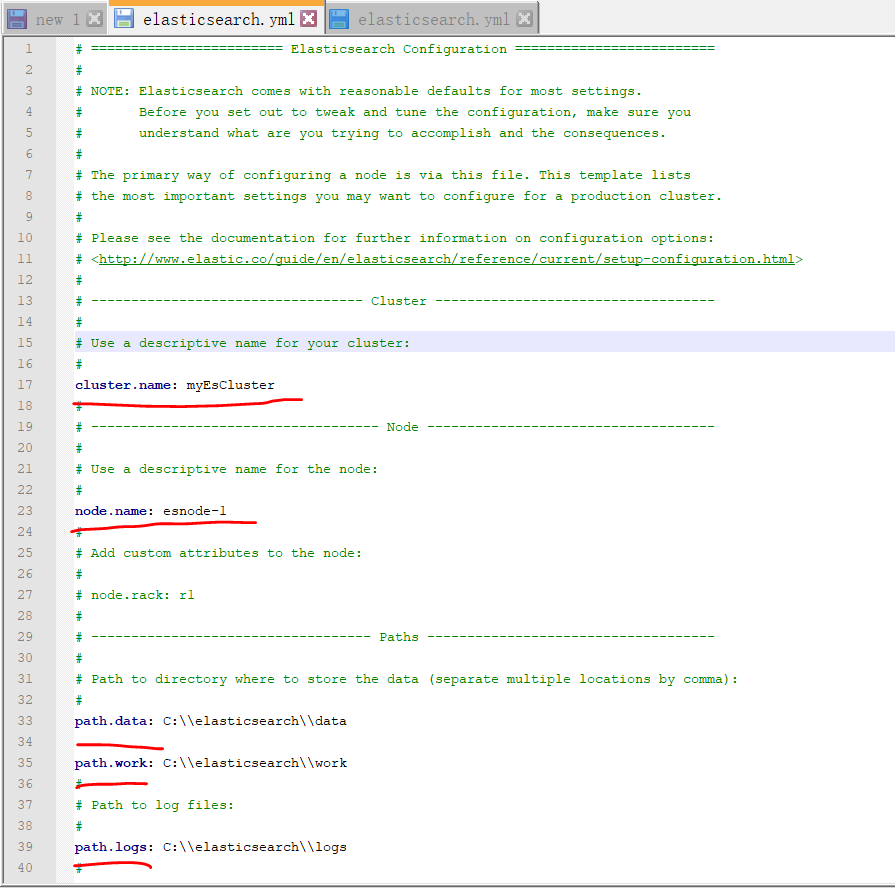
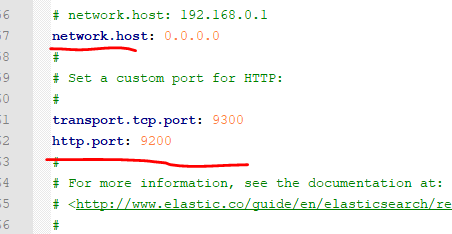
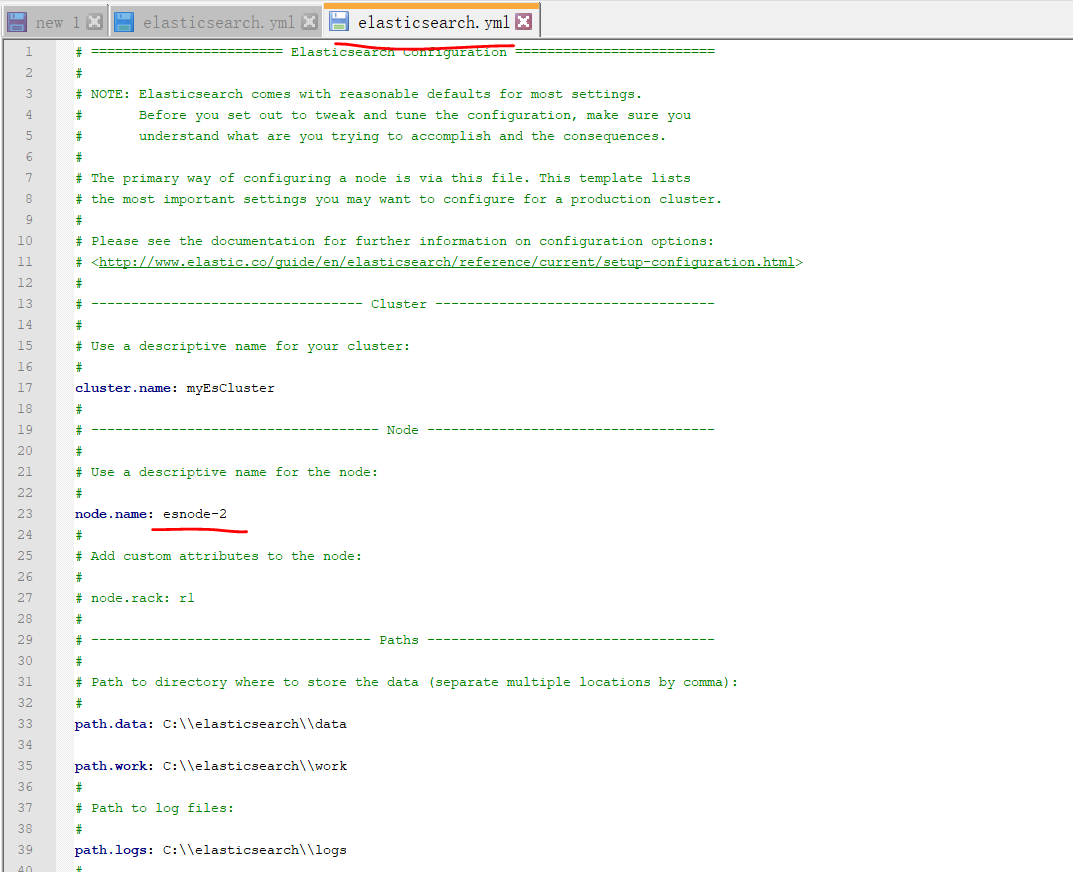
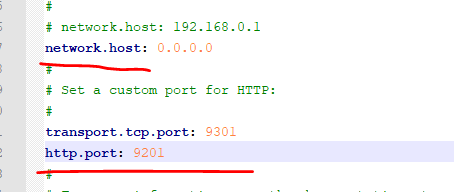
然后到bin下执行elasticsearch.bat (elasticsearch1 跟 elasticsearch2 都执行)
启动后:
二、基本概念
2.1 Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
2.2 Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
$ curl -X GET 'http://localhost:9200/_cat/indices?v'
2.3 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
2.4 Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
下面的命令可以列出每个 Index 所包含的 Type。
$ curl 'localhost:9200/_mapping?pretty=true'
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
三、新建和删除 Index
新建 Index,可以直接向 Elastic 服务器发出 PUT 请求。下面的例子是新建一个名叫weather的 Index。
$ curl -X PUT 'localhost:9200/weather'
服务器返回一个 JSON 对象,里面的acknowledged字段表示操作成功。
{
"acknowledged":true,
"shards_acknowledged":true
}
然后,我们发出 DELETE 请求,删除这个 Index。
$ curl -X DELETE 'localhost:9200/weather'
elastic search(es)安装的更多相关文章
- Elastic Search 安装和配置
目标 部署一个单节点的ElasticSearch集群 依赖 java环境 $java -version java version "1.8.0_161" Java(TM) SE R ...
- ELASTIC SEARCH 安装
elastic search 2017年3月18日 安装&使用 环境 表 1 环境信息 Centos cat /etc/issue CentOS release 6.8 (Final) cat ...
- elastic search安装与本地测试
elastic search安装与本地测试 elastic search是一个全文搜索引擎 教程: 综合:http://www.ruanyifeng.com/blog/2017/08/elastics ...
- Elastic Search快速上手(2):将数据存入ES
前言 在上手使用前,需要先了解一些基本的概念. 推荐 可以到 https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.htm ...
- Elastic Search快速上手(1):简介及安装配置
前言 最近开始尝试学习Elastic Search,因此决定做一些简单的整理,以供后续参考,快速上手使用ES. 简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多 ...
- elastic search&logstash&kibana 学习历程(一)es基础环境的搭建
elastic search 6.1.x 常用框架: 1.Lucene Apache下面的一个开源项目,高性能的.可扩展的工具库,提供搜索的基本架构: 如果开发人员需用使用的话,需用自己进行开发,成本 ...
- elastic search book [ ElasticSearch book es book]
谁在使用ELK 维基百科, github都使用 ELK (ElasticSearch es book) ElasticSearch入门 Elasticsearch入门,这一篇就够了==>http ...
- aws ec2 安装Elastic search 7.2.0 kibana 并配置 hanlp 分词插件
文章大纲 Elastic search & kibana & 分词器 安装 版本控制 下载地址 Elastic search安装 kibana 安装 分词器配置 Elastic sea ...
- docker安装elastic search和kibana
安装目标 使用docker安装elastic search和kibana,版本均为7.17.1 安装es 1. docker pull 去dockerhub看具体版本,这里用7.17.1 docker ...
随机推荐
- linux 编译引用动态库时,报GLIBC_2,14 not found的处理方法
这种错误一般是其引用的libc.so,其中含有版本较高的函数导致. 查看及解决办法: objdump -p ./libdmapi.so 显示: version References: ... requ ...
- git 命令归纳版
1.克隆: 单纯的克隆名字: git clone [url] 自定义新建项目名称: git clone [url] [项目名字] 2.跟踪文件: git add [文件名] 3.添加忽略文件 ...
- [考试反思]1026csp-s模拟测试88:发展
不用你们说,我自己来:我颓闪存我没脸. 昨天的想法, 今天的回答. 生存, 发展. 总分榜应该稍有回升,但是和上面的差距肯定还是很大. 继续. 为昨天的谬误,承担代价. T2和T3都值得张记性. T2 ...
- OI 经典诗歌
键盘行 学校机房夜送客,枫叶蒟蒻秋瑟瑟.主人下马客在船,代码欲写无键盘.夜不AC惨将别,别时茫茫屏幕亮. 忽闻楼上键盘声,主人忘归客不发.寻声暗问敲者谁,键盘声停欲语迟.上楼相近邀相见,添酒回灯重开宴 ...
- python入门递归之阶乘
def recurursion(n): if n == 1: return 1 else: return n * recurursion(n-1) number = int(input("请 ...
- 如何提高web应用的吞吐量
这篇博文所列举的优化手段是针对比较传统项目,但是想提高系统的吞吐量现在时髦的技术还是那些前后端未分离, 使用nginx当成静态资源服务器去代理我们的静态资源 是谁限制了Throughput? 当我们对 ...
- .NET进阶篇06-async异步、thread多线程2
知识需要不断积累.总结和沉淀,思考和写作是成长的催化剂 内容目录 一.线程Thread1.生命周期2.后台线程3.静态方法1.线程本地存储2.内存栅栏4.返回值二.线程池ThreadPool1.工作队 ...
- 第五天、vim,重定向,用户和组管理
第五天.vim,重定向,用户和组管理 vim vi:Visual editor,文本编辑器 行编辑器:sed 全屏编辑器:vim,vi,nano 其他编辑器gedit,gvim 定义别名让vi等于vi ...
- JavaScript中BOM与DOM的使用
BOM: 概念:Browser Object Model 浏览器对象模型 将浏览器的各个组成部分封装成对象. 组成: Window:窗口对象 Navigator:浏览器对象 Screen:显示器屏幕对 ...
- 《计算机网络 自顶向下方法》 第2章 应用层 Part2
域名.主机名? 从范围上看: 域名的范围比主机名大 一个域名下通常有多个主机名 从组成上看: 主机名 = 服务器名(或计算机名) + 域名 举例说明: baidu.com 是百度的域名 www.b ...