[DE] How to learn Big Data
打开一瞧:50G的文件!
- emptystacks
- jobstacks
- jobtickets
- stackrequests
- worker
大数据加数据分析,需要以python+scikit,sql作为基础,大数据框架作为载体。
大数据的存放:S3 Browser
一、大数据存放
Please note that Worker (worker parquet files) has one or more job tickets (jobticket parquet files) associated with it.
Using these parquet files:
1. Is there a co-relation between jobticket.jobTicketState, jobticket.clickedCalloff and jobticket.assignedBySwipeJobs values across workers.
2. Looking at Worker.profileLastUpdatedDate values, calculate an estimation for workers who will update their profile in the next two weeks.
二、大数据文件
Sol: Spark2.0入门:读写Parquet(DataFrame)
Parquet files
part-00178-88b459d7-0c3a-4b84-bb5c-dd099c0494f2.c000.snappy.parquet
如何操作:
Sol: Spark2.0入门:读写Parquet(DataFrame)
Ref: Spark SQL 官方文档-中文翻译 【有读取文件的例子】
什么原理:
Ref: Parquet
Ref: [翻译] Dremel made simple with Parquet
Ref: 深入分析Parquet列式存储格式
结论:
Hive集群搭建,然后生成Parquet文件,之后才谈得上分析。
典型案例
让我们再瞧一个实际的“不得不大数据"的例子。
市场需求:
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+,
用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群信息。
举个例子:
集合A: ( 购买过“牙膏“的人交易金额在10-500元并且交易次数在5次的客户并且平均订单价在20 -200元) 。
集合B: (购买过“牙刷”的人交易金额在5-50 并且交易次数在3次的客户并且平均订单价在10-30元)。
求:<1> 获取集合A 交 集合B 客户数 和 客户的具体信息,希望时间最好不要超过15s。
上面这种问题如果你用mysql做的话,基本上是算不出来的,时间上更无法满足项目需求。
方案选择:
分布式的Elasticsearch集群?
查询中相关的Nick,AvgPrice,TradeCount,TradeAmont字段可以用keyword模式存储,避免出现fieldData字段无法查询的问题:
- 虽然ES大体上可以解决这个问题,但是熟悉ES的朋友应该知道,它的各种查询都是我们通过json的格式去定制,虽然可以使用少量的script脚本,但是灵活度相比spark来说的话太弱基了,用scala函数式语言定制那是多么的方便,
- 第二个是es在group by的桶分页特别不好实现,也很麻烦,社区里面有一些 sql on elasticsearch 的框架,大家可以看看:https://github.com/NLPchina/elasticsearch-sql,只支持一些简单的sql查询,不过像having这样的关键词是不支持的,跟sparksql是没法比。
基于以上原因,决定用spark试试看。
环境搭建:
搭建spark集群,需要hadoop + spark + java + scala,搭建之前一定要注意各自版本的对应关系!!!
采用的组合是:
- hadoop-2.7.6.tar.gz
- jdk-8u144-linux-x64.tar.gz
- scala-2.11.0.tgz
- spark-2.2.1-bin-hadoop2.7.tgz
- jdk-8u144-linux-x64.tar.gz
- mysql-connector-java-5.1.46.jar
- sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
使用3台虚拟机:
一台【namenode +resourceManager + spark master node】
二台 【datanode + nodeManager + spark work data】
192.168.2.227 hadoop-spark-master
192.168.2.119 hadoop-spark-salve1
192.168.2.232 hadoop-spark-salve2
使用python对spark进行操作:
之前使用scala对spark进行操作,使用maven进行打包,用起来不大方便;
采用python还是很方便的,大家先要下载一个pyspark 的安装包,一定要和spark的版本对应起来。 pypy官网:https://pypi.org/project/pyspark/2.2.1/
/* 可以考虑一下 */
Amas大数据监控平台
有没有什么全栈的解决方案呢?
基于大数据平台技术开发的统一监控平台Amas开源项目核心开发者。
GitHub: https://github.com/amas-eye/amas
技术栈
编程语言:
(Backend)Python
(Web)Javascript
Web服务:
Vue, ECharts, Webpack
Express(NodeJS)
后台服务:
HBase, OpenTSDB, MongoDB, Redis
Spark, Kafka...
Jagger, Tornado
Pandas, Scikit-learn
Docker, Swarm
大数据的处理:Data Pipeline
一、公司示例
相关公司:https://matrix.ai/consulting/
Big Data Infrastructure
Matrix AI doesn't just build the machine learning models, we also build the underlying big data cloud infrastructure!
We use Docker to encapsulate software components called microservices. These microservices are composed together into a data processing pipeline which feeds data from production systems to our machine learning training and inference architecture. This data processing pipeline gets orchestrated via distributed cluster computing systems like Dask and Kubernetes. Tensorflow is used to train our neural network models. The entire architecture is then deployed onto cloud platforms like AWS.

二、Data Pipeline
具体详情,参见:[DE] Pipeline for Data Engineering
大数据的学习套路
看过以上的例子,自然便引出一个问题,如何系统地掌握数据分析的技能?

一、常见问题
Link: 大数据学习路线图
至于另一个问题,data science and machine learning什么区别?
个人的一个感觉,前者更加注重实践性,后者偏重理论。
学习python
在数据量不大的情况下(几个G),单机上就可以很好跑机器学习的程序。
这时,Python的用途就很大,不仅有已经实现好的算法,也可以实现爬虫,从网上获取数据。
学习Scala和函数式编程
对于大数据处理来说,尤其是几十个G的数据,Spark和Scala结合是现在的大趋势。
二、IBM资源
Ref: 大数据分析基础博文
4. 使用 Spark MLlib 做 K-means 聚类分析
从官方文档来看,Spark ML Pipeline 虽然是被推荐的机器学习方式,
但是并不会在短期内替代原始的 MLlib 库,
因为 MLlib 已经包含了丰富稳定的算法实现,并且部分 ML Pipeline 实现基于 MLlib。
看到这里,还是厦门大学的这个资料比较全,学习系统,所以,走起!
三、厦门大学资源
入门学习
课程:大数据技术原理与应用
教材:《大数据技术原理与应用》
进阶学习
1.受众对象
具备一定的大数据基础知识,比如,已经学习过林子雨编著的《大数据技术原理与应用》教材;
2.资源列表
(1)纸质教材:《Spark编程基础》(官网)
(2)在线教程:《Spark入门教程(Scala版)》(访问)
(3)在线教程:《Spark入门教程(Python版)》(访问)
(4)视频:《Spark编程基础》MOOC视频(2018年2月和纸质教材同步发布)
(5)案例1:淘宝双11数据分析与预测(访问)
(6)案例2: Spark+Kafka构建实时分析Dashboard(访问)
3.学习路线
(1)步骤一:参照《Spark编程基础》纸质教材(官网),或者参照《Spark入门教程(Scala版)》在线教程(访问),并观看《Spark编程基础》MOO视频(2018年2月发布),完成Spark技术原理与编程方法的学习。
(2)步骤二:完成《Spark编程基础》全书内容学习以后,可以练习Spark课程实验“案例1:淘宝双11数据分析与预测”(访问)和“案例2: Spark+Kafka构建实时分析Dashboard”(访问),对所学知识进行体统“串联”,融会贯通。
4.其他说明
(1)如果读者是教师,可以访问《Spark编程基础》教材官网(访问),里面提供了讲义PPT、实验题目答案、教学大纲等资源的下载。
(2)《Spark编程基础》教材官网(访问)里面提供了很多纸质教材上没有的上机实验指导内容。
四、Material Dashboard
数据可视化(远程):在PyTorch中使用 Visdom 可视化工具
北美大数据面试资源
阅读笔记
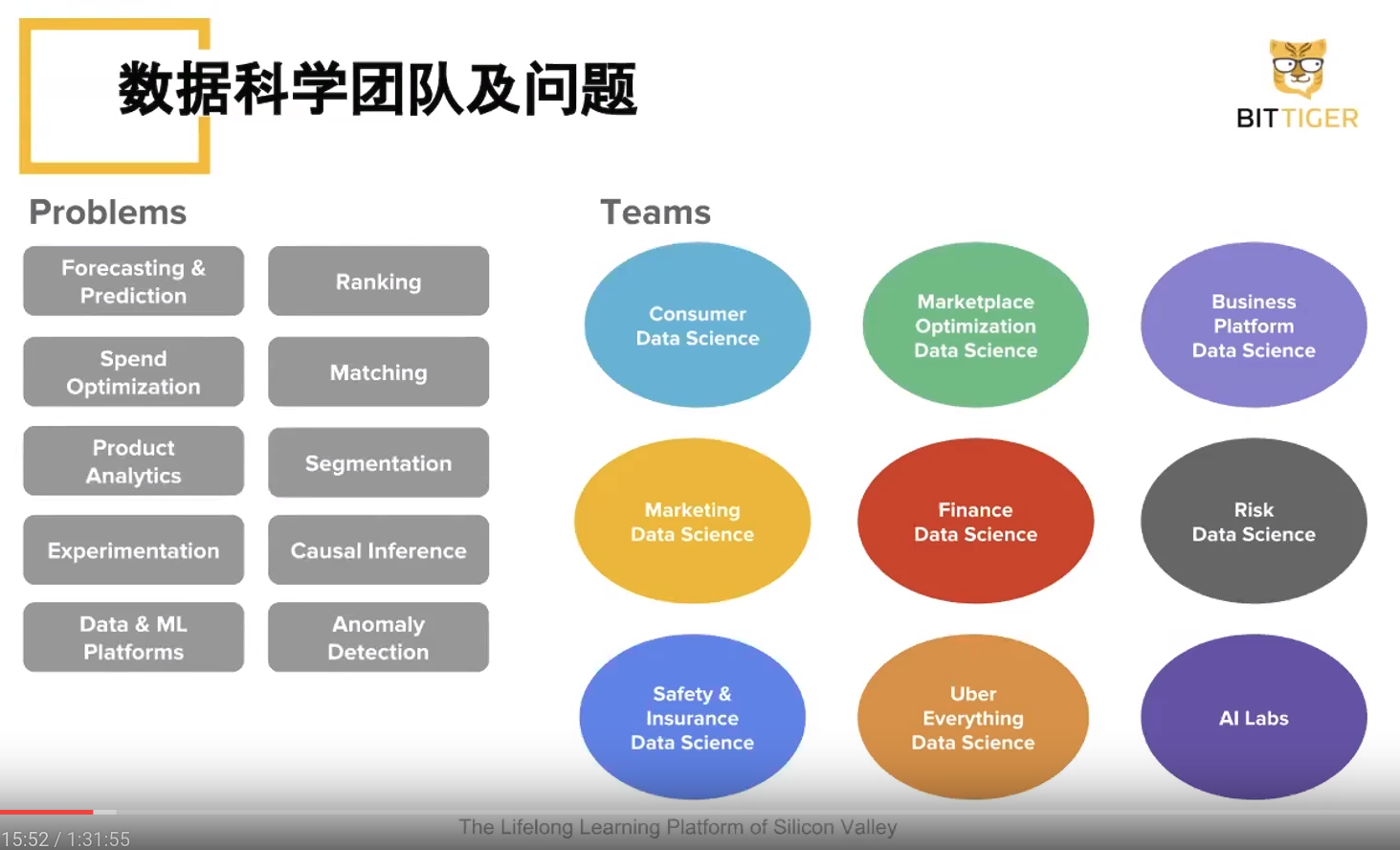
数据科学家类型
- Comunication 理解和表达
- Intuition 找到数学表达, feature engineering, 新问题
- Reasoning 算法实现强

实践资源:kaggle, LeetCode, HackerRank, ProjectEuler, Sciket-learn.
二、职位技能要求
Spark 大数据开发工程师(上海)
Software Data Engineer – Big Data
My client wants to reward a high performing Software Data Engineer proficient on Spark and Scala and Hadoop with experience coding on R or Python or Java. You will be working in a fast paced environment. You will be joining and existing team environment as a project kicks off.
Your Benefits:
Immediate full time contract role
Melbourne CBD location close to public transport
3 months + 3 month extension
Your Role:
Data modelling, analysis and machine learning.
Relate data to analytical questions and frame the data engineering work to solve those business problems
Experience with at least 1 of the following for transforming data in scala, python or R
Experience with source control, automated testing and continuous integration/deployment
Designing and building relational and non-relational data stores (such as HDFS or Cassandra)
You will need to have:
Demonstrated experience working on big data tools such as Spark is essential.
Other ideal experience in SQL, Hadoop, HBase, Cassandra, Kafka, Nifi
Proven experience programming in Scala using RDDs, Dataframe and API’s for building the spark application
Experience manipulating and analysing complex, high-volume, high dimensionality data from varying sources
Excellent communication and stakeholder management skills
Proven experience managing a team and holding leadership roles.
Proven experience across data warehousing and reporting platforms
Hadoop or Spark certification (preferred but not essential)
Proven experience working in an agile environment
Current full Australian working rights (no sponsorship)
Must be available immediately
You will need to draw on your strong coding skills in this professional, intelligent data-driven environment.
[DE] How to learn Big Data的更多相关文章
- DeepDB:Learn From Data,not from Queries!
ABSTRACT DBMS典型学习方法的弊端:手机数据集的成本过高;工作方向或数据库发生改变时,必须重新收集数据.--------------解决:提出了一种新的数据驱动方式,直接支持工作负载和数据库 ...
- [AI] 深度数据 - Data
Data Engineering Data Pipeline Outline [DE] How to learn Big Data[了解大数据] [DE] Pipeline for Data Eng ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- Toward Scalable Systems for Big Data Analytics: A Technology Tutorial (I - III)
ABSTRACT Recent technological advancement have led to a deluge of data from distinctive domains (e.g ...
- Learning Core Data 1
What is Core Data? If you want to build anything beyond the most simplistic apps for iOS, you’ll nee ...
- TF.Learn
TF.Learn 手写文字识别 转载请注明作者:梦里风林Google Machine Learning Recipes 7官方中文博客 - 视频地址Github工程地址 https://githu ...
- Google机器学习笔记(七)TF.Learn 手写文字识别
转载请注明作者:梦里风林 Google Machine Learning Recipes 7 官方中文博客 - 视频地址 Github工程地址 https://github.com/ahangchen ...
- How to use data analysis for machine learning (example, part 1)
In my last article, I stated that for practitioners (as opposed to theorists), the real prerequisite ...
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
随机推荐
- Servlet Cookie、Session
HTTP不能保持连接,可使用会话保存用户信息. 常用的会话技术有2种:Cookie.Session. Cookie 1.原理 当用户第一次访问某个网站时,服务器设置Cookie,存储用户信息,放在响应 ...
- Istio 太复杂?KubeSphere基于Ingress-Nginx实现灰度发布
在 Bookinfo 微服务的灰度发布示例 中,KubeSphere 基于 Istio 对 Bookinfo 微服务示例应用实现了灰度发布.有用户表示自己的项目还没有上 Istio,要如何实现灰度发布 ...
- 你不知道的JavaScript之作用域
什么是作用域 编译原理 分词/词法分析 这个过程会将由字符组成的字符串分解成(对编程语言来说)有意义的代码块,这些代 码块被称为词法单元(token) 解析/语法分析 这个过程是将词法单元流(数组)转 ...
- PicGo+GitHub:你的最佳免费图床选择!
# PicGo介绍 这是一款图片上传的工具,目前支持SM.MS图床,微博图床,七牛图床,腾讯云COS,阿里云OSS,Imgur,又拍云,GitHub等图床,未来将支持更多图床. 所以解决问题的思路就是 ...
- 使用VS Code 开发.NET CORE 程序指南
1. 前言 近两年来,很多前端的同学都开始将 VSCode 作为前端主力开发工具,其丰富的扩展给程序开发尤其是前端开发带来了很多便利,但是作为微软主力语言的 .NET,却由于有宇宙第一编辑器 Visu ...
- 游戏客户端面试(Egret)
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 一.朋友面的一家公司 1.说下let,var,const. var定义的变量,没有块的概念,可以跨块访问, 不能跨函 ...
- lua&C#学习整理
1.Lua中有8个基本类型分别为:nil.boolean.number.string.userdata.function.thread和table. 2.pairs 和 ipairs区别 pairs: ...
- Django 项目创建到启动(最全最详细的第一个项目)
一.前言 (一).概述 Python下有许多款不同的 Web 框架.Django是重量级选手中最有代表性的一位.许多成功的网站和APP都基于Django. Django是一个开放源代码的Web应用框架 ...
- Nginx总结(五)如何配置nginx和tomcat实现反向代理
前面讲了如何配置Nginx虚拟主机,大家可以去这里看看nginx系列文章:https://www.cnblogs.com/zhangweizhong/category/1529997.html 今天要 ...
- 文档打印 js print调用打印dom内容
1.首先按目前研究 print可以打印dom 2.被设置overflow:hidden 的模块,打印时会被截掉. 3.被设置成 display:none 的dom 打印不会有样式 边框等. 4.如果需 ...