Elastic Stack 笔记(五)Elasticsearch5.6 Mappings 映射
一、前言
关系型数据库对我们来说都很熟悉,Elasticsearch 也可以看成是一种数据库,所以我们经常将关系型数据库中的概念和 Elasticsearch 中的概念进行对比,如下:
Relational DB(关系型数据库) -> Databases(数据库) -> Tables(表) -> Rows(行) -> Columns(列)
Elasticsearch -> Indices(索引) -> Types(类型) -> Documents(文档) -> Fields(域/字段)
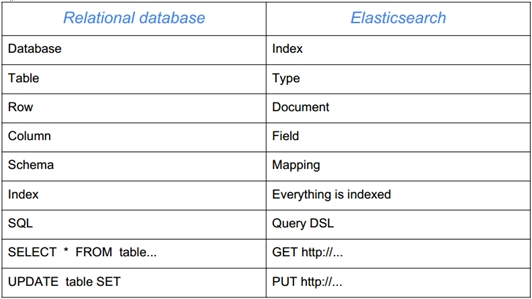
如上所示,Elasticsearch 中的 index(索引)就相当于数据库,type(类型)相当于表,mapping(映射)相当于表结构,document(文档)相当于行等等。
但是 Elasticsearch 也有自己的特点:
Elasticsearch 没有典型意义的事务;
Elasticsearch 是一种面向文档的数据库;
Elasticsearch 没有提供授权和认证特性。
二、映射
为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成全文本(Full-text)或精确(Exact-value)的字符串值,Elasticsearch 需要知道每个字段里面都包含什么数据类型。这些类型和字段的信息存储在映射中。创建索引的时候,可以预先定义字段的类型以及相关属性,相当于定义数据库字段的属性。以下参考文档地址均来自官方最新版本 6.2。
Elasticsearch 官网文档地址:Elasticsearch Reference
2.1 字段数据类型
字段数据类型文档地址:Field datatypes
核心类型 Core datatypes
字符串类型
string
text and keyword
text:全文检索需要分词的类型。
keyword:精确值。合适分组排序。不进行分词,只能通过精确值搜索到,支持模糊、精确查询,支持聚合等。
Elasticsearch 1.x 和 2.x 中是 string 类型,5.x 之后,分解为 text 和 keyword。
数字类型
long, integer, short, byte, double, float, half_float, scaled_float
日期类型
date
JSON 中没有日期类型,所以在 ELasticsearch 中,日期类型可以是以下几种:
日期格式的字符串:e.g. "2015-01-01" or "2015/01/01 12:10:30".
long类型的毫秒数( milliseconds-since-the-epoch)
integer的秒数(seconds-since-the-epoch)
日期格式可以自定义,如果没有自定义,默认格式如下:
"strict_date_optional_time||epoch_millis"
布尔类型
boolean
true 和 false
二进制类型
binary
范围类型
integer_range, float_range, long_range, double_range, date_range
复杂数据类型 Complex datatypes
数组类型
Array support does not require a dedicated type
数组支持不需要专用类型
对象类型
object for single JSON objects
单个JSON对象的对象
嵌套类型
nested for arrays of JSON objects
嵌套用于JSON对象数组
地理数据类型 Geo datatypes
地理坐标点类型
geo_point for lat/lon points
用于经纬度坐标点
地理形状类型
geo_shape for complex shapes like polygons
用于复杂的形状,比如多边形
专业数据类型 specialised datatypes
IP 地址数据类型
ip for IPv4 and IPv6 addresses
完成数据类型
completion to provide auto-complete suggestions
completion 提供自动补全建议。
令牌计数数据类型
token_count to count the number of tokens in a string
murmur3 插件类型
murmur3 to compute hashes of values at index-time and store them in the index
通过插件,可以通过 murmur3 来计算 index 的 hash 值。
过滤器类型
Accepts queries from the query-dsl
连接数据类型
Defines parent/child relation for documents within the same index
多字段类型
It is often useful to index the same field in different ways for different purposes. For instance, a string field could be mapped as a text field for full-text search, and as a keyword field for sorting or aggregations. Alternatively, you could index a text field with the standard analyzer, the english analyzer, and the french analyzer.
This is the purpose of multi-fields. Most datatypes support multi-fields via the fields parameter.
2.2 元字段
元字段是映射中描述文档本身的字段,从大的分类上来看,主要有文档属性的元字段、源文档的元字段、索引的元字段、路由的元字段和自定义元字段。
元字段文档地址:Meta-Fields
元字段用于定制文档的相关元数据。元字段的示例包括文档的_index,_type,_id 和 _source 字段。
文档属性的元字段 identity_meta_fields
The index to which the document belongs.
索引标识。
A composite field consisting of the _type and the _id.
由_type和_id组成的复合字段。
The document’s mapping type.
文档的类型。
The document’s ID.
文档的id。
源文档的元字段 Document source meta-fields
The original JSON representing the body of the document.
文档的原始 JSON 字符串。
The size of the _source field in bytes, provided by the mapper-size plugin.
_source 字段的大小。
索引的元字段 Indexing meta-fieldsedit
A catch-all field that indexes the values of all other fields. Disabled by default.
包含索引全部字段的超级字段。
_all 字段是把其他字段拼接在一起的超级字段,所有的字段内容用空格分开,_all 字段会被解析和索引,但是不存储。
All fields in the document which contain non-null values.
文档中包含非空值的所有字段。
路由元字段 Routing meta-fieldedit
A custom routing value which routes a document to a particular shard.
将文档路由到特定分片的自定义路由值。
其他元字段 Other meta-fieldedit
Application specific metadata.
应用程序特定的元字段,通常用于自定义元字段。
2.3 映射参数
Elasticsearch 提供了足够多的映射参数对字段的映射进行参数设置,一些常用功能的实现,比如字段的分词器,字段的权重、日期格式、检索模型的选择等都是通过映射参数来配置完成的。
映射参数文档地址:Mapping parameters
analyzernormalizerboostcoercecopy_todoc_valuesdynamicenabledfielddataeager_global_ordinalsformatignore_aboveignore_malformedindex_optionsindexfieldsnormsnull_valueposition_increment_gappropertiessearch_analyzersimilaritystoreterm_vector
以映射参数 analyzer 为例,在创建索引时指定分词器,如下:
PUT forum
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "text"
},
"title": {
"type": "text"
},
"postdate": {
"type": "date"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
analyzer 指定文本字段的分词器,对索引和分词都有效,默认使用标准分词器,可以指定第三方分词器,比如 IK 分词器,如 ik_smart 将使用智能分词,属于粗粒度分词,ik_max_word 是最细粒度分词。
以映射参数 index 为例,index 属性指定字段是否参与索引,不索引也就不可搜索,取值可以为 true 或者 false。
Elasticsearch 1.x 和 2.x 之前版本 "index":"not_analyzed",表示不分词,在版本 5.x 中提示已经废弃了 "not_analyzed",只能是 true 或 false。5.x 中 string 分为两种类型 keyword,text。如果不想分词,用 keyword 即可,"the keyword field for not_analyzed exact string values"。
使用如下 API 查询分词结果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国人"
}
返回结果如下:
{
"tokens": [
{
"token": "中国人",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "中国",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "国人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 2
},
{
"token": "人",
"start_offset": 2,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
}
]
}
Elastic Stack 笔记(五)Elasticsearch5.6 Mappings 映射的更多相关文章
- Elastic Stack 笔记(四)Elasticsearch5.6 索引及文档管理
博客地址:http://www.moonxy.com 一.前言 在 Elasticsearch 中,对文档进行索引等操作时,既可以通过 RESTful 接口进行操作,也可以通过 Java 也可以通过 ...
- Elastic Stack 笔记(一)CentOS7.5 搭建 Elasticsearch5.6 集群
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 是一个基于 Lucene 的分布式搜索引擎服务,采用 Java 语言编写,使用 Lucene 构建索引.提供 ...
- Elastic Stack 笔记(八)Elasticsearch5.6 Java API
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTf ...
- Elastic Stack 笔记(三)Kibana5.6 安装
博客地址:http://www.moonxy.com 一.前言 Kibana 是 Elastic Stack 公司推出的一个针对 Elasticsearch 的开源分析及可视化平台,可以搜索.查看存放 ...
- Elastic Stack 笔记(十)Elasticsearch5.6 For Hadoop
博客地址:http://www.moonxy.com 一.前言 ES-Hadoop 是连接快速查询和大数据分析的桥梁,它能够无间隙的在 Hadoop 和 ElasticSearch 上移动数据.ES ...
- Elastic Stack 笔记(六)Elasticsearch5.6 搜索详解
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 主要包含索引过程和搜索过程. 索引过程:一条文档被索引到 Elasticsearch 之后,默认情况下 ES ...
- Elastic Stack 笔记(九)Elasticsearch5.6 集群管理
博客地址:http://www.moonxy.com 一.前言 集群搭建好以后,在日常中就要对集群的使用情况进行监控,对于一个多节点集群,由于网络连接问题,出现宕机.脑裂等异常情况都是有可能发生的.E ...
- Elastic Stack 笔记(二)Elasticsearch5.6 安装 IK 分词器和 Head 插件
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 作为开源搜索引擎服务器,其核心功能在于索引和搜索数据.索引是把文档写入 Elasticsearch 的过程, ...
- Elastic Stack 笔记(七)Elasticsearch5.6 聚合分析
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 是一个分布式的全文搜索引擎,索引和搜索是 Elasticsarch 的基本功能.同时,Elasticsear ...
随机推荐
- React单页面应用使用antd的锚点跳转失效
首先在react项目中引用antd的锚点 import {Anchor} from 'antd';const { Link } = Anchor; <Anchor> <Link hr ...
- RDIFramework.NET敏捷开发框架通过SignalR技术整合即时通讯(IM)
1.引言 即时通讯(IM)是RDIFramework.NET敏捷开发框架全新提供的一个基于Web的即时通讯.内部聊天沟通的工具.界面美观大方对于框架内部进行消息的沟通非常方便.基于RDIFramewo ...
- 利用递归,反射,注解等,手写Spring Ioc和Di 底层(分分钟喷倒面试官)了解一下
再我们现在项目中Spring框架是目前各大公司必不可少的技术,而大家都知道去怎么使用Spring ,但是有很多人都不知道SpringIoc底层是如何工作的,而一个开发人员知道他的源码,底层工作原理,对 ...
- Cat应用告警实战
1. Cat应用告警实战 1.1. 前言 好像是中间件设计者的通病,文档写的都是面向有一定使用各种中间件经验的人,告警模块中每个参数其实都可以详细解释一下,要不然我们理解起来真的很吃力还容易采坑 1. ...
- Hugo
快速开始 安装Hugo 1.二进制安装(推荐:简单.快速) 到 Hugo Releases 下载对应的操作系统版本的Hugo二进制文件(hugo或者hugo.exe) Mac下直接使用 ==Homeb ...
- Fire Balls 04——砖塔的创建,动态上升以及旋转
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- three.js实现球体地球城市模拟迁徙
概况如下:1.SphereGeometry实现自转的地球:2.THREE.ImageUtils.loadTexture加载地图贴图材质:3.THREE.Math.degToRad,Math.sin,M ...
- JavaScript 数据结构与算法之美 - 你可能真的不懂递归
1. 前言 算法为王. 排序算法博大精深,前辈们用了数年甚至一辈子的心血研究出来的算法,更值得我们学习与推敲. 因为之后要讲有内容和算法,其代码的实现都要用到递归,所以,搞懂递归非常重要. 2. 定义 ...
- CodeForces 758 D Ability To Convert
Ability To Convert 题意:给你一个n进制的60位的数,但是由于Alexander只会写0->9,所以他就会用10来表示十而不是A(假设进制>10); 题解:模拟就好了,先 ...
- Storm 系列(一)—— Storm和流处理简介
一.Storm 1.1 简介 Storm 是一个开源的分布式实时计算框架,可以以简单.可靠的方式进行大数据流的处理.通常用于实时分析,在线机器学习.持续计算.分布式 RPC.ETL 等场景.Storm ...