Netty源码分析 (十二)----- 心跳服务之 IdleStateHandler 源码分析
什么是心跳机制?
心跳说的是在客户端和服务端在互相建立ESTABLISH状态的时候,如何通过发送一个最简单的包来保持连接的存活,还有监控另一边服务的可用性等。
心跳包的作用
保活
Q:为什么说心跳机制能保持连接的存活,它是集群中或长连接中最为有效避免网络中断的一个重要的保障措施?
A:之所以说是“避免网络中断的一个重要保障措施”,原因是:我们得知公网IP是一个宝贵的资源,一旦某一连接长时间的占用并且不发数据,这怎能对得起网络给此连接分配公网IP,这简直是对网络资源最大的浪费,所以基本上所有的NAT路由器都会定时的清除那些长时间没有数据传输的映射表项。一是回收IP资源,二是释放NAT路由器本身内存的资源,这样问题就来了,连接被从中间断开了,双发还都不晓得对方已经连通不了了,还会继续发数据,这样会有两个结果:a) 发方会收到NAT路由器的RST包,导致发方知道连接已中断;b) 发方没有收到任何NAT的回执,NAT只是简单的drop相应的数据包
通常我们测试得出的是第二种情况会多些,就是客户端是不知道自己应经连接断开了,所以这时候心跳就可以和NAT建立关联了,只要我们在NAT认为合理连接的时间内发送心跳数据包,这样NAT会继续keep连接的IP映射表项不被移除,达到了连接不会被中断的目的。检测另一端服务是否可用
TCP的断开可能有时候是不能瞬时探知的,甚至是不能探知的,也可能有很长时间的延迟,如果前端没有正常的断开TCP连接,四次握手没有发起,服务端无从得知客户端的掉线,这个时候我们就需要心跳包来检测另一端服务是否还存活可用。
基于TCP的keepalive机制实现
基于TCP的keepalive机制,由具体的TCP协议栈来实现长连接的维持。如在netty中可以在创建channel的时候,指定SO_KEEPALIVE参数来实现:
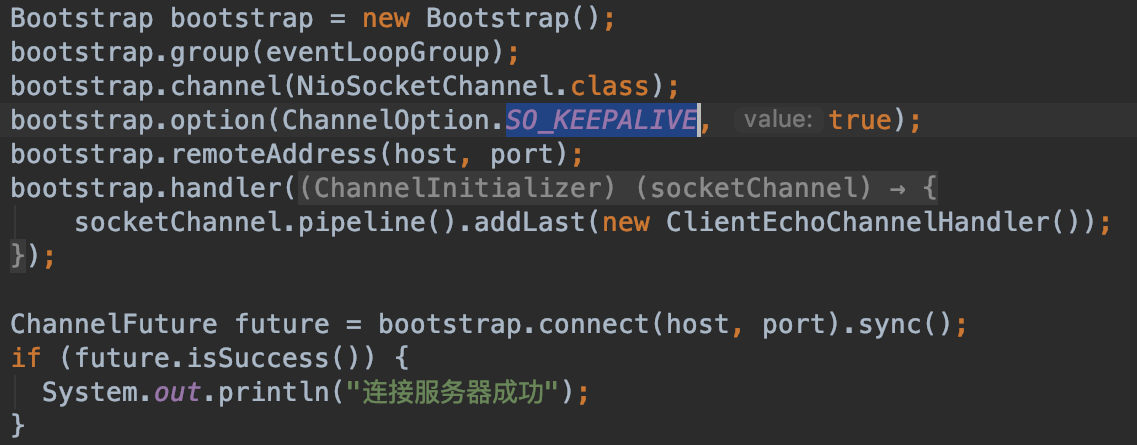
存在的问题:Netty只能控制SO_KEEPALIVE这个参数,其他参数,则需要从系统的sysctl中读取,其中比较关键的是tcp_keepalive_time,发送心跳包检测的时间间隔,默认为7200s,即空闲后,每2小时检测一次。如果客户端在这2小时内断开了,那么服务端也要维护这个连接2小时,浪费服务端资源;另外就是对于需要实时传输数据的场景,客户端断开了,服务端也要2小时后才能发现。服务端发送心跳检测,具体可能出现的情况如下:
(1)连接正常:客户端仍然存在,网络连接状况良好。此时客户端会返回一个 ACK 。 服务端接收到ACK后重置计时器,在2小时后再发送探测。如果2小时内连接上有数据传输,那么在该时间基础上向后推延2个小时;
(2)连接断开:客户端异常关闭,或是网络断开。在这两种情况下,客户端都不会响应。服务器没有收到对其发出探测的响应,并且在一定时间(系统默认为 1000 ms )后重复发送 keep-alive packet ,并且重复发送一定次数。
(3)客户端曾经崩溃,但已经重启:这种情况下,服务器将会收到对其存活探测的响应,但该响应是一个复位,从而引起服务器对连接的终止。
基于Netty的IdleStateHandler实现
什么是 IdleStateHandler
当连接的空闲时间(读或者写)太长时,将会触发一个 IdleStateEvent 事件。然后,你可以通过你的 ChannelInboundHandler 中重写 userEventTrigged 方法来处理该事件。
如何使用?
IdleStateHandler 既是出站处理器也是入站处理器,继承了 ChannelDuplexHandler 。通常在 initChannel 方法中将 IdleStateHandler 添加到 pipeline 中。然后在自己的 handler 中重写 userEventTriggered 方法,当发生空闲事件(读或者写),就会触发这个方法,并传入具体事件。
这时,你可以通过 Context 对象尝试向目标 Socekt 写入数据,并设置一个 监听器,如果发送失败就关闭 Socket (Netty 准备了一个 ChannelFutureListener.CLOSE_ON_FAILURE 监听器用来实现关闭 Socket 逻辑)。
这样,就实现了一个简单的心跳服务。
源码分析
构造方法
该类有 3 个构造方法,主要对一下 4 个属性赋值:
private final boolean observeOutput;// 是否考虑出站时较慢的情况。默认值是false(不考虑)。
private final long readerIdleTimeNanos; // 读事件空闲时间,0 则禁用事件
private final long writerIdleTimeNanos;// 写事件空闲时间,0 则禁用事件
private final long allIdleTimeNanos; //读或写空闲时间,0 则禁用事件
可以分别控制读,写,读写超时的时间,单位为秒,如果是0表示不检测,所以如果全是0,则相当于没添加这个IdleStateHandler,连接是个普通的短连接。
handlerAdded 方法
IdleStateHandler是在创建IdleStateHandler实例并添加到ChannelPipeline时添加定时任务来进行定时检测的,具体在initialize(ctx)方法实现;同时在从ChannelPipeline移除或Channel关闭时,移除这个定时检测,具体在destroy()实现
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
if (ctx.channel().isActive() && ctx.channel().isRegistered()) {
this.initialize(ctx);
}
}
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
this.destroy();
}
initialize
private void initialize(ChannelHandlerContext ctx) {
switch (state) {
case 1:
case 2:
return;
}
state = 1;
initOutputChanged(ctx);
lastReadTime = lastWriteTime = ticksInNanos();
if (readerIdleTimeNanos > 0) {
// 这里的 schedule 方法会调用 eventLoop 的 schedule 方法,将定时任务添加进队列中
readerIdleTimeout = schedule(ctx, new ReaderIdleTimeoutTask(ctx),
readerIdleTimeNanos, TimeUnit.NANOSECONDS);
}
if (writerIdleTimeNanos > 0) {
writerIdleTimeout = schedule(ctx, new WriterIdleTimeoutTask(ctx),
writerIdleTimeNanos, TimeUnit.NANOSECONDS);
}
if (allIdleTimeNanos > 0) {
allIdleTimeout = schedule(ctx, new AllIdleTimeoutTask(ctx),
allIdleTimeNanos, TimeUnit.NANOSECONDS);
}
}
只要给定的参数大于0,就创建一个定时任务,每个事件都创建。同时,将 state 状态设置为 1,防止重复初始化。调用 initOutputChanged 方法,初始化 “监控出站数据属性”,代码如下:
private void initOutputChanged(ChannelHandlerContext ctx) {
if (observeOutput) {
Channel channel = ctx.channel();
Unsafe unsafe = channel.unsafe();
ChannelOutboundBuffer buf = unsafe.outboundBuffer();
// 记录了出站缓冲区相关的数据,buf 对象的 hash 码,和 buf 的剩余缓冲字节数
if (buf != null) {
lastMessageHashCode = System.identityHashCode(buf.current());
lastPendingWriteBytes = buf.totalPendingWriteBytes();
}
}
}
读事件的 run 方法
代码如下:
protected void run(ChannelHandlerContext ctx) {
long nextDelay = readerIdleTimeNanos;
if (!reading) {
nextDelay -= ticksInNanos() - lastReadTime;
}
if (nextDelay <= 0) {
// Reader is idle - set a new timeout and notify the callback.
// 用于取消任务 promise
readerIdleTimeout = schedule(ctx, this, readerIdleTimeNanos, TimeUnit.NANOSECONDS);
boolean first = firstReaderIdleEvent;
firstReaderIdleEvent = false;
try {
// 再次提交任务
IdleStateEvent event = newIdleStateEvent(IdleState.READER_IDLE, first);
// 触发用户 handler use
channelIdle(ctx, event);
} catch (Throwable t) {
ctx.fireExceptionCaught(t);
}
} else {
// Read occurred before the timeout - set a new timeout with shorter delay.
readerIdleTimeout = schedule(ctx, this, nextDelay, TimeUnit.NANOSECONDS);
}
}
nextDelay的初始化值为超时秒数readerIdleTimeNanos,如果检测的时候没有正在读,且计算多久没读了:nextDelay -= 当前时间 - 上次读取时间,如果小于0,说明左边的readerIdleTimeNanos小于空闲时间(当前时间 - 上次读取时间)了,则超时了
则创建IdleStateEvent事件,IdleState枚举值为READER_IDLE,然后调用channelIdle方法分发给下一个ChannelInboundHandler,通常由用户自定义一个ChannelInboundHandler来捕获并处理
总的来说,每次读取操作都会记录一个时间,定时任务时间到了,会计算当前时间和最后一次读的时间的间隔,如果间隔超过了设置的时间,就触发 UserEventTriggered 方法。就是这么简单。
写事件的 run 方法
写任务的逻辑基本和读任务的逻辑一样,唯一不同的就是有一个针对 出站较慢数据的判断。
if (hasOutputChanged(ctx, first)) {
return;
}
如果这个方法返回 true,就不执行触发事件操作了,即使时间到了。看看该方法实现:
private boolean hasOutputChanged(ChannelHandlerContext ctx, boolean first) {
if (observeOutput) {
// 如果最后一次写的时间和上一次记录的时间不一样,说明写操作进行过了,则更新此值
if (lastChangeCheckTimeStamp != lastWriteTime) {
lastChangeCheckTimeStamp = lastWriteTime;
// 但如果,在这个方法的调用间隙修改的,就仍然不触发事件
if (!first) { // #firstWriterIdleEvent or #firstAllIdleEvent
return true;
}
}
Channel channel = ctx.channel();
Unsafe unsafe = channel.unsafe();
ChannelOutboundBuffer buf = unsafe.outboundBuffer();
// 如果出站区有数据
if (buf != null) {
// 拿到出站缓冲区的 对象 hashcode
int messageHashCode = System.identityHashCode(buf.current());
// 拿到这个 缓冲区的 所有字节
long pendingWriteBytes = buf.totalPendingWriteBytes();
// 如果和之前的不相等,或者字节数不同,说明,输出有变化,将 "最后一个缓冲区引用" 和 “剩余字节数” 刷新
if (messageHashCode != lastMessageHashCode || pendingWriteBytes != lastPendingWriteBytes) {
lastMessageHashCode = messageHashCode;
lastPendingWriteBytes = pendingWriteBytes;
// 如果写操作没有进行过,则任务写的慢,不触发空闲事件
if (!first) {
return true;
}
}
}
}
return false;
}
- 如果用户没有设置了需要观察出站情况。就返回 false,继续执行事件。
- 反之,继续向下, 如果最后一次写的时间和上一次记录的时间不一样,说明写操作刚刚做过了,则更新此值,但仍然需要判断这个 first 的值,如果这个值还是 false,说明在这个写事件是在两个方法调用间隙完成的 / 或者是第一次访问这个方法,就仍然不触发事件。
- 如果不满足上面的条件,就取出缓冲区对象,如果缓冲区没对象了,说明没有发生写的很慢的事件,就触发空闲事件。反之,记录当前缓冲区对象的 hashcode 和 剩余字节数,再和之前的比较,如果任意一个不相等,说明数据在变化,或者说数据在慢慢的写出去。那么就更新这两个值,留在下一次判断。
- 继续判断 first ,如果是 fasle,说明这是第二次调用,就不用触发空闲事件了。
所有事件的 run 方法
这个类叫做 AllIdleTimeoutTask ,表示这个监控着所有的事件。当读写事件发生时,都会记录。代码逻辑和写事件的的基本一致,除了这里:
long nextDelay = allIdleTimeNanos;
if (!reading) {
// 当前时间减去 最后一次写或读 的时间 ,若大于0,说明超时了
nextDelay -= ticksInNanos() - Math.max(lastReadTime, lastWriteTime);
}
这里的时间计算是取读写事件中的最大值来的。然后像写事件一样,判断是否发生了写的慢的情况。最后调用 ctx.fireUserEventTriggered(evt) 方法。
通常这个使用的是最多的。构造方法一般是:
pipeline.addLast(new IdleStateHandler(0, 0, 30, TimeUnit.SECONDS));
读写都是 0 表示禁用,30 表示 30 秒内没有任务读写事件发生,就触发事件。注意,当不是 0 的时候,这三个任务会重叠。
Netty源码分析 (十二)----- 心跳服务之 IdleStateHandler 源码分析的更多相关文章
- Netty 心跳服务之 IdleStateHandler 源码分析
前言:Netty 提供的心跳介绍 Netty 作为一个网络框架,提供了诸多功能,比如我们之前说的编解码,Netty 准备很多现成的编解码器,同时,Netty 还为我们准备了网络中,非常重要的一个服务- ...
- OpenJDK源码研究笔记(十二):JDBC中的元数据,数据库元数据(DatabaseMetaData),参数元数据(ParameterMetaData),结果集元数据(ResultSetMetaDa
元数据最本质.最抽象的定义为:data about data (关于数据的数据).它是一种广泛存在的现象,在许多领域有其具体的定义和应用. JDBC中的元数据,有数据库元数据(DatabaseMeta ...
- 庐山真面目之十二微服务架构基于Docker搭建Consul集群、Ocelot网关集群和IdentityServer版本实现
庐山真面目之十二微服务架构基于Docker搭建Consul集群.Ocelot网关集群和IdentityServer版本实现 一.简介 在第七篇文章<庐山真面目之七微服务架构Consul ...
- Netty源码分析 (三)----- 服务端启动源码分析
本文接着前两篇文章来讲,主要讲服务端类剩下的部分,我们还是来先看看服务端的代码 /** * Created by chenhao on 2019/9/4. */ public final class ...
- Android 7.0 存储系统—Vold与MountService分析(二)(转 Android 9.0 分析)
Android的存储系统(二) 回顾:前贴主要分析了Android存储系统的架构和原理图,简要的介绍了整个从Kernel-->Vold-->上层MountService之间的数据传输流程, ...
- Netty源码解读(二)-服务端源码讲解
简单Echo案例 注释版代码地址:netty 代码是netty的源码,我添加了自己理解的中文注释. 了解了Netty的线程模型和组件之后,我们先看看如何写一个简单的Echo案例,后续的源码讲解都基于此 ...
- ABP源码分析十二:本地化
本文逐个分析ABP中涉及到locaization的接口和类,以及相互之间的关系.本地化主要涉及两个方面:一个是语言(Language)的管理,这部分相对简单.另一个是语言对应得本地化资源(Locali ...
- [Abp 源码分析]十二、多租户体系与权限验证
0.简介 承接上篇文章我们会在这篇文章详细解说一下 Abp 是如何结合 IPermissionChecker 与 IFeatureChecker 来实现一个完整的多租户系统的权限校验的. 1.多租户的 ...
- jQuery 源码分析(十二) 数据操作模块 html特性 详解
jQuery的属性操作模块总共有4个部分,本篇说一下第1个部分:HTML特性部分,html特性部分是对原生方法getAttribute()和setAttribute()的封装,用于修改DOM元素的特性 ...
随机推荐
- freemarker导出复杂样式的Excel
freemarker导出复杂样式的Excel 代码地址: gitee https://gitee.com/suveng/demo/tree/master/chapter.002 代码存放于demo下面 ...
- Hibernate对象状态之间的神奇转换
状态分类 在Hibernate框架中,为了管理持久化类,Hibernate将其分为了三个状态: 瞬时态(Transient Object) 持久态(Persistent Object) 脱管态(Det ...
- (四十七)c#Winform自定义控件-树表格(treeGrid)
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kwwwvagaa/NetWinformControl 码云:ht ...
- Jmeter发送post请求报错Content type 'application/x-www-form-urlencoded;charset=UTF-8' not supported
常识普及: Content-type,在Request Headers里面,告诉服务器,我们发送的请求信息格式,在JMeter中,信息头存储在信息头管理器中,所以在做接口测试的时候,我们维护Conte ...
- 跨库数据迁移利器 —— Sqoop
一.Sqoop 基本命令 1. 查看所有命令 # sqoop help 2. 查看某条命令的具体使用方法 # sqoop help 命令名 二.Sqoop 与 MySQL 1. 查询MySQL所有数据 ...
- JSP学习笔记(1)——Jsp指令、动作元素和内置对象
简单来说,javaweb技术就是让服务器端能够执行Java代码,之后返回数据给客户端(浏览器)让客户端显示数据 jsp页面中可以嵌套java代码(java小脚本)和嵌套Web前端(html,css,j ...
- nginx有哪些作用
Nginx应该是现在最火的web和反向代理服务器,没有之一.她是一款诞生于俄罗斯的高性能web服务器,尤其在高并发情况下,相较Apache,有优异的表现. 那除了负载均衡,她还有什么其他的用途呢,下面 ...
- 洛谷P1273 有线电视网 树上分组背包DP
P1273 有线电视网 )逼着自己写DP 题意:在一棵树上选出最多的叶子节点,使得叶子节点的值 减去 各个叶子节点到根节点的消耗 >= 0: 思路: 树上分组背包DP,设dp[u][k] 表示 ...
- cogs 1199选课(树形dp 背包或多叉转二叉
http://cogs.pro:8080/cogs/problem/problem.php?pid=vQyiJkkPP 题意:给m门课,每门课在上完其先修课后才能上,要你从中选n门课使得总学分尽可能大 ...
- codeforces 876 D. Sorting the Coins(线段树(不用线段树写也行线段树写比较装逼))
题目链接:http://codeforces.com/contest/876/problem/D 题解:一道简单的类似模拟的题目.其实就是看右边连出来有多少连续不需要换的假设位置为pos只要找pos- ...