五、Doris数据分布
在 Doris 中,数据都以表(Table)的形式进行逻辑上的描述
名词解释
- 数据分布:数据分布是将数据划分为子集, 按一定规则, 均衡地分布在不同节点上,以期最大限度地利用集群的并发性能
- 短查询:short-scan query,指扫描数据量不大,单机就能完成扫描的查询
- 长查询:long-scan query,指扫描数据量大,多机并行扫描能显著提升性能的查询
数据分布概览
常见的四种数据分布方式有:(a) Round-Robin、(b) Range、(c) List和(d) Hash (DeWitt and Gray, 1992)。如下图所示:
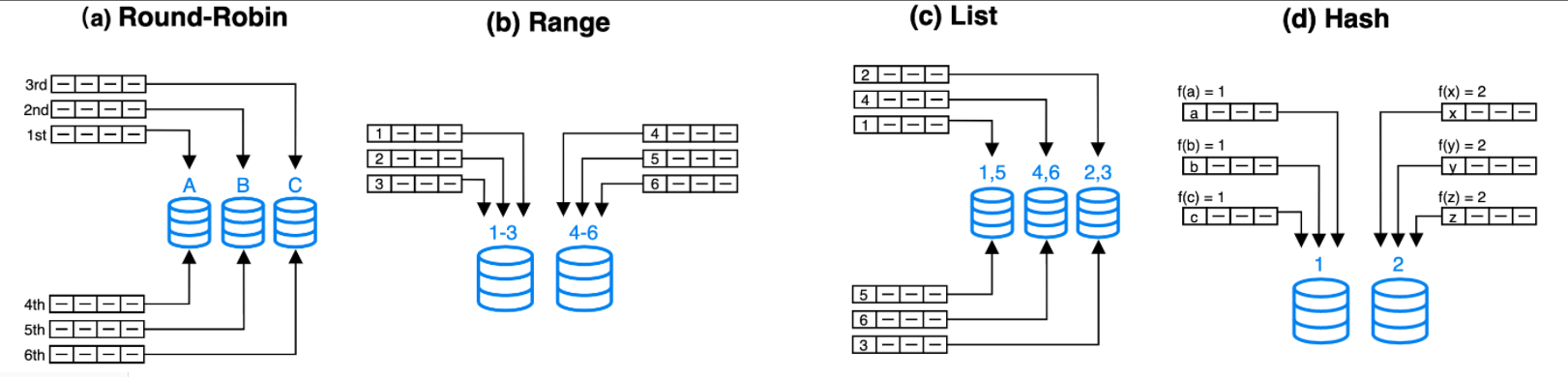
其中:
- Round-Robin: 以轮转的方式把数据逐个放置在相邻节点上。
- Range: 按区间进行数据分布,图中区间[1-3],[4-6]分别对应不同Range。
- List: 直接基于离散的各个取值做数据分布,性别、省份等数据就满足这种离散的特性。每个离散值会映射到一个节点上,不同的多个取值可能也会映射到相同节点上。
- Hash: 按哈希函数把数据映射到不同节点上。
为了更灵活地划分数据,现代分布式数据库除了单独采用上述四种数据分布方式之外,也会视情况采用组合数据分布。常见的组合方式有Hash-Hash、Range-Hash、Hash-List。
分区(Partition)与分桶(Bucket)
在 Doris 的存储引擎规则:
- 用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。
- 而在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
- Tablet直接的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
DorisDB数据分布
DorisDB使用先分区后分桶的方式, 可灵活地支持支持二种分布方式:
- Hash分布: 不采用分区方式, 整个table作为一个分区, 指定分桶的数量.
- Range-Hash的组合数据分布: 即指定分区数量, 指定每个分区的分桶数量.
采用Hash分布的建表语句:

采用Range-Hash组合分布的建表语句

DorisDB中Range分布,被称之为分区,用于分布的列也被称之为分区列,上图中的event_day就是分区列。Hash分布,则被称之为分桶,用于分布的列也被称之为分桶列,如上图中分桶列都是site_id.
Range分区可动态添加和删减,上图中如果新来了隶属于新月份的数据,就可以添加新分区。Hash分桶一旦确定,分桶数也就随之固定,不能再进行调整。

分区列如何选择
分区的主要作用是将整个分区作为管理单位, 选择存储策略, 比如副本数, 冷热策略和存储介质等等。
- 大多数情况下,近期的数据被查询的可能性更大。将最近的数据放在一个分区之内,这样可以通过DorisDB的分区裁剪功能,最大限度地减少扫描数据量,从而提高查询性能。
- 同时,DorisDB支持在一个集群内使用多种存储介质(SATA/SSD)。用户可以将最新数据所在的分区放在SSD上,利用SSD的随机读写性能来提高查询性能。而老的数据可以放在SATA盘上,以节省数据存储的成本。
- 在实际应用中,用户一般选取时间列作为分区键,具体划分的粒度视数据量而定,单个分区原始数据量建议维持在100G以内。
分桶列如何选择
DorisDB采用Hash算法作为分桶算法:
- 同一分区内, 分桶键的哈希值相同的数据形成(Tablet)子表, 子表多副本冗余存储,
- 子表副本在物理上由一个单独的本地存储引擎管理, 数据导入和查询最终都下沉到所涉及的子表副本上, 同时子表也是数据均衡和恢复的基本单位.
上图中,site_access采用site_id作为分桶键, 这里选用site_id字段作为分桶键的原因在于,针对site_access表的查询请求,基本上都以站点作为查询过滤条件。采用site_id作为分桶键,可以在查询时裁剪掉大量无关分桶。
如下图中的查询,可以裁剪掉10个bucket中的9个,只需要扫描site_access表的1/10的数据。

但是存在这样一种情况,假设site_id分布十分不均匀,大量的访问数据是关于少数网站的(幂律分布, 二八规则)。如果用户依然采用上述分桶方式,数据分布会出现严重的数据倾斜, 导致系统局部的性能瓶颈。这个时候,用户需要适当调整分桶的字段,以将数据打散,避免性能问题。如下图5中,可以采用site_id、city_code组合作为分桶键,将数据划分得更加均匀。
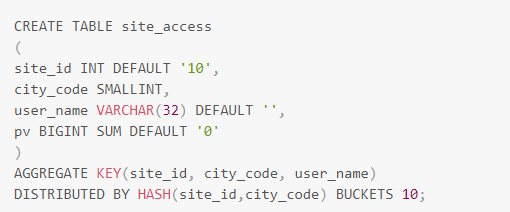
上面两种模式的选取是建表过程中经常需要面对的问题,采用site_id的分桶方式对于短查询十分有利,能够减少节点之间的数据交换,提供集群整体性能;采用site_id、city_code组合做分桶键的模式对于长查询有利,能够利用分布式集群的整体并发性能,提高吞吐。用户在实际使用中,可以依据自身的业务特点进行相应模式的选择。
分桶数如何确定
在DorisDB系统中,分桶是实际物理文件组织的单元。数据在写入磁盘后,就会涉及磁盘文件的管理。一般而言,我们不建议分桶数据过大或过小,尽量适中会比较妥当。
- 根据经验而言,一般每个分桶的数据不建议超过10G,此处的10G指代的是原始数据。考虑到压缩比,压缩后磁盘上每个分桶数据文件大小在4~5G左右。这种模式在多数情况下足以满足业务需求。
- 建议用户根据集群规模的变化,建表时调整分桶的数量。集群规模变化,主要指节点数目的变化。假设现有100G原始数据,依照上述标准,可以建10个分桶。但是如果用户有20台机器,那么可以缩小每个分桶的数据量,加大分桶数。
最佳实践
对于DorisDB而言,分区和分桶的选择是非常关键的。在建表时选择好的分区分桶列,可以有效提高集群整体性能。当然,在使用过程中,也需考虑业务情况,根据业务情况进行调整。以下是针对特殊应用场景下,对分区和分桶选择的一些建议:
- 数据倾斜:业务方如果确定数据有很大程度的倾斜,那么建议采用多列组合的方式进行数据分桶,而不是只单独采用倾斜度大的列做分桶。
- 高并发:分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
- 高吞吐:尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
动态分区管理
在很多实际应用场景中,数据的时效性很重要,需要为新达到数据创建新分区, 删除过期. DorisDB的动态分区机制可以实现分区rollover: 对分区实现进行生命周期管理(TTL),自动增删分区,减少用户的使用心智负担。
创建支持动态分区的表
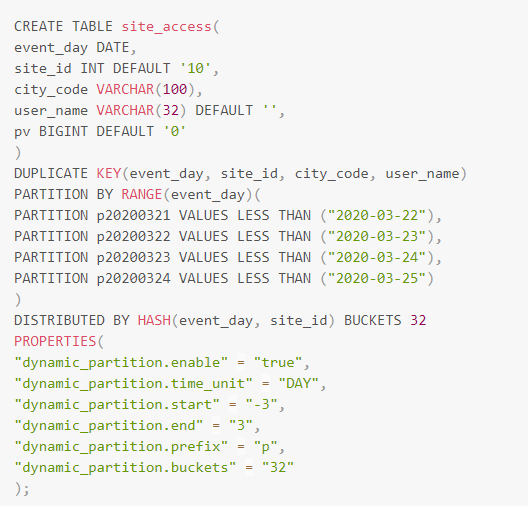
图中建表语句中通过指定PEROPERTIES来完成动态分区策略的配置。配置项可以描述如下:
- dynamic_partition.enable : 是否开启动态分区特性,可指定为 TRUE 或 FALSE。如果不填写,默认为 TRUE。
- dynamic_partition.time_unit : 动态分区调度的粒度,可指定为 DAY/WEEK/MONTH。
- dynamic_partition.start: 动态分区的开始时间。以当天为基准,超过该时间范围的分区将会被删除。如果不填写,则默认为Integer.MIN_VALUE 即 -2147483648
- 指定为 DAY 时,分区名后缀需为yyyyMMdd,例如20200325。上图 就是一个按天分区的例子,分区名的后缀满足yyyyMMdd
- 指定为 WEEK 时,分区名后缀需为yyyy_ww,例如2020_13代表2020年第13周
- 指定为 MONTH 时,动态创建的分区名后缀格式为 yyyyMM,例如 202003
- dynamic_partition.end: 动态分区的结束时间。 以当天为基准,会提前创建N个单位的分区范围
- dynamic_partition.prefix: 动态创建的分区名前缀
- dynamic_partition.buckets: 动态创建的分区所对应的分桶数量
上图中创建了一张表,并同步开启动态分区特性。图中分区的区间为当前时间的前后3天,总共6天。假设当前时间为2020-03-25为例,在每次调度时,会删除分区上界小于 2020-03-22 的分区,同时在调度时会创建今后3天的分区。调度完成之后,新的分区会是下列列表
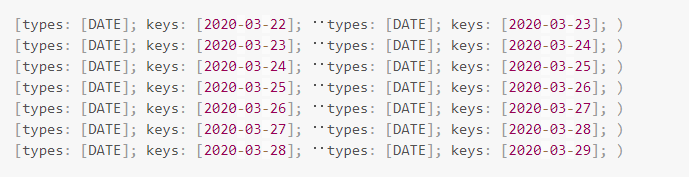
调度的时机依赖于FE的配置,FE的常驻线程会根据 dynamic_partition_enable 和 dynamic_partition_check_interval_seconds 两个参数来控制。每次调度时,读取动态分区表的属性,以此判断是否增加/删除分区。
语法:
1、查看表当前的分区:动态分区表运行过程中,会不断地自动增减分区,可以通过下列命令查看当前的分区情况
- SHOW PARTITIONS FROM site_access;
2、修改表的分区属性:态分区的属性可以修改,例如需要起/停动态分区的功能,可以通过ALTER TABLE来完成。
- ALTER TABLE site_access SET("dynamic_partition.enable"="false");
- 注意:依照相同语句,也可以相应的修改其他属性。
批量创建和修改分区
该功能在1.16版本中添加
1、建表时批量创建日期分区:用户可以通过给出一个START值、一个END值以及一个定义分区增量值的EVERY子句批量产生分区。其中START值将被包括在内而END值将排除在外。
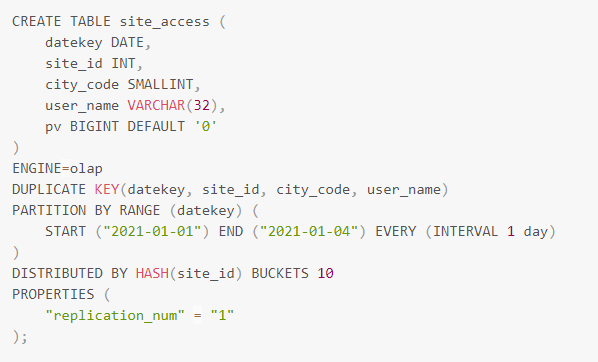
这样DorisDB便会自动创建如下等价的分区

当前分区键仅支持日期类型和整数类型,分区类型需要与EVERY里的表达式匹配。
当分区键为日期类型的时候需要指定INTERVAL关键字来表示日期间隔,目前日期仅支持day、week、month、year,分区的命名规则同动态分区一样。
2、建表时批量创建数字分区
当分区键为整数类型时直接使用数字进行分区,注意分区值需要使用引号引用,而EVERY则不用引号,如下
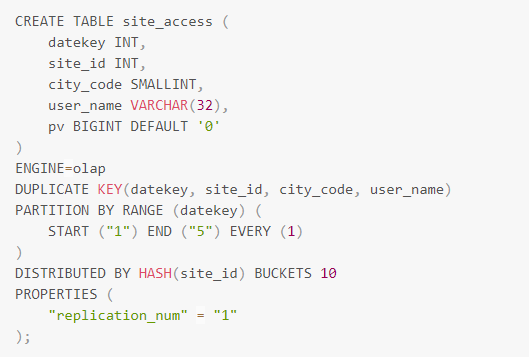
上面的语句将产生如下分区:

3、建表后批量创建分区
与建表时批量创建分区类似,DorisDB也支持通过ALTER语句批量创建分区。通过指定ADD PARITIONS关键字,配合START和END以及EVERY的值来创建分区。

小结:
1、Table: 在 Doris 中,数据都以表(Table)的形式进行逻辑上的描述
2、DorisDB的数据分布:使用先分区后分桶
- 分区:主要作用是将整个分区作为管理单位, 选择存储策略, 比如副本数, 冷热策略和存储介质。仅支持日期类型和整数类型。可动态调整
- 分桶:分桶是实际物理文件组织的单元。主要作用让数据均匀分布,防止出现数据热点。 不可动态调整。同一分区内, 分桶键的哈希值相同的数据形成(Tablet)子表。
3、Table (逻辑描述) -- > Partition(分区:管理单元) --> Bucket(分桶:存储,每个分桶就是一个数据分片:Tablet,数据划分的最小逻辑单元。岂称为子表) ,如下图:

4、RANGE分区(partition): RANGE分区用于将数据划分成不同区间, 逻辑上可以理解为将原始表划分成了多个子表。 业务上,多数用户会选择采用按时间进行partition, 让时间进行partition有以下好处:
- 可区分冷热数据
- 可用上DorisDB分级存储(SSD + SATA)的功能
- 按分区删除数据时,更加迅速
5、HASH分桶(bucket): 根据hash值将数据划分成不同的bucket
- 建议采用区分度大的列做分桶, 避免出现数据倾斜
- 为方便数据恢复, 建议单个bucket的size不要太大, 保持在10GB左右, 所以建表或增加partition时请合理考虑buckets数目, 其中不同partition可指定不同的buckets数。
- random分桶的方式不建议采用,建表时请指定明确的hash分桶列。
参考资料
- https://www.kancloud.cn/dorisdb/dorisdb/2142135
- https://www.jianshu.com/p/d3742af8ecce
- https://www.yuque.com/zailushang-j5dyp/wn32ln/btgzby
- https://blog.csdn.net/kaede1209/article/details/112243447
- http://doris.apache.org/master/zh-CN/getting-started/data-partition.html
- https://blog.bcmeng.com/post/doris-colocate-join.html
五、Doris数据分布的更多相关文章
- MySql学习(五) —— 数据库优化理论篇(一)
一.数据库管理系统 数据库管理系统(Database Management System, DBMS) 衡量是否是数据库的标准: ACID:是指在数据库管理系统(DBMS)中事务所具有的四个特性: 1 ...
- 《BI那点儿事》三国数据分析系列——蜀汉五虎上将与魏五子良将武力分析,绝对的经典分析
献给广大的三国爱好者们,希望喜欢三国的朋友一起讨论,加深对传奇三国时代的了解 数据分析基础概念:集中趋势分析是指在大量测评数据分布中,测评数据向某点集中的情况.总体(population)是指客观存在 ...
- Sql Server之旅——第五站 确实不得不说的DBCC命令
原文:Sql Server之旅--第五站 确实不得不说的DBCC命令 今天研发中心办年会,晚上就是各自部门聚餐了,我个人喜欢喝干红,在干红中你可以体味到那种酸甜苦辣...人生何尝不是这样呢???正好 ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- Doris
Doris 基本概念 Doris 是基于 MPP 架构的交互式 SQL 数据仓库,主要用于解决近实时的报表和多维分析. Doris 分成两部分 FE 和 BE ,FE 负责存储以及维护集群元数据.接收 ...
- GAN实战笔记——第五章训练与普遍挑战:为成功而GAN
训练与普遍挑战:为成功而GAN 一.评估 回顾一下第1章中伪造达・芬奇画作的类比.假设一个伪造者(生成器)正在试图模仿达・芬奇,想使这幅伪造的画被展览接收.伪造者要与艺术评论家(判别器)竞争,后者试图 ...
- Apache Doris 单节点(可多节点)Docker集群制作教程
集群制作Author:苏奕嘉脚本研发Author:种益调研测试Author:杨春东 前言 Apache Doris是当下非常火热和流行的MPP架构OLAP数据库,很多同学想自学/测试Doris的使用和 ...
- 新型MPP的Doris数据库:数据模型和数据分区使用详解
Apache Doris是一个现代化的MPP分析性数据库产品.是一个由百度开源,在2018年贡献给Apache基金会,成为有顶级开源项目.仅需要亚秒级响应时间即可获得查询结果,可以有效地支持实时数据分 ...
- 系统评价——理想点TOPSIS法的R语言实现(五)
TOPSIS 法是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距.TOPSIS全称Technique for Order Preference by Simi ...
随机推荐
- C# 使用AForge调用摄像头
AForge官网地址:http://www.aforgenet.com/framework/ using System; using System.Collections.Generic; using ...
- @Value static静态变量注入
@Component public class Config { @Value("${config1}") private static String config1; } 使用上 ...
- #K-D Tree#BZOJ 4303 数列
题目传送门 分析 将 \((i,p_i)\) 视为一个点,那么相当于对横坐标或纵坐标对应的点区间乘.区间加或者区间求和, 把这些点丢到 K-D Tree 上,维护最小/大横/纵坐标,如果当前区间点在范 ...
- DOM 节点遍历:掌握遍历 XML文档结构和内容的技巧
遍历是指通过或遍历节点树 遍历节点树 通常,您想要循环一个 XML 文档,例如:当您想要提取每个元素的值时. 这被称为"遍历节点树". 下面的示例循环遍历所有 <book&g ...
- js实现电子白板
功能:使用画笔绘制笔迹(线条).橡皮檫 <!DOCTYPE html> <html lang="en"> <head> <meta cha ...
- nginx重新整理——————http请求的11个阶段中的find_config[十三]
前言 简单介绍一下find_config 与 preaccess 阶段. 正文 find_config 很大一部分工作是进行location的匹配. 来一张图看下location指令和merge_sl ...
- redis 简单整理——内存的优化[二十七]
前言 简单介绍一下内存的优化. 正文 Redis所有的数据都在内存中,而内存又是非常宝贵的资源.如何优化内存的使用一直是Redis用户非常关注的问题.本节深入到Redis细节中,探索内存优化的技巧. ...
- js es6 Proxy
传统的get,set ES6 中引入Proxies,让你可以自定义Object的基本操作.例如,get就是Object的基础操作方法. const obj = { val: 10 }; console ...
- Flink 自定义 ClickHouse Table Connector 的简单实现
本次实现基于 Flink 1.18 版本,具体的对象之间的关系可以先参考官网的图: 先拿官网上的 Socket 示例来说一下实现过程: 首先编写 SocketDynamicTableFactory 实 ...
- eclipse tomcat的一些错误
eclipse tomcat运行错误 错误提示: Server Tomcat v7.0 Server at localhost was unable to start within 45 second ...