同策略强化学习算法可以使用经验缓存池(experience buffer)吗 ??? 设计一个基于缓存池的改进reinforce算法,给出初步的尝试 ---------- (reinforce + experience buffer)
本文使用代码地址:
https://gitee.com/devilmaycry812839668/reinforce_with_-experience-buffer
==============================================
前面有几篇博客分析了以reinforce算法为原型的多环境并行强化学习算法,这里是在之前的算法基础上加入了经验池回放机制。经验池回放机制一直被看做是off-policy才可以使用的方法,而on-policy算法是一直被认为无法使用这一机制的,而这一笼统观点并不完全准确。从对训练数据生成的时刻距离训练时刻的时间距离来看,off-policy 是依据old data 来进行训练的,因此只有off-policy的强化学习算法才可以使用experience replay buffer机制,而on-policy算法由于需要新鲜的fresh data 来进行训练,所以一直被认为是无法使用experience replay buffer机制的。
其实,on-policy 和 off-policy 对训练数据的差别主要是体现在是否fresh,而是否fresh就一定和experience buffer相关吗???
对于 on-policy 算法,我们可以想象这样一种场景,那就是我们可以快速的、大量的获取到新鲜的fresh data ,那么及时我们那这些数据放入一定大小的experience buffer中,只要我们保证experience buffer 的大小,新鲜数据fresh data 进入 buffer的速度足够快,足以是buffer中的数据一直保持较新的状态,那么即使我们是从experience buffer中抽取数据也是可以保证抽取到的数据是比较fresh 的, 这样就可以保证这些fresh data 可以用来训练on-policy的强化学习算法,也正是基于这个思路给出了下面的算法设计。
共11种设计,运行结果如下:
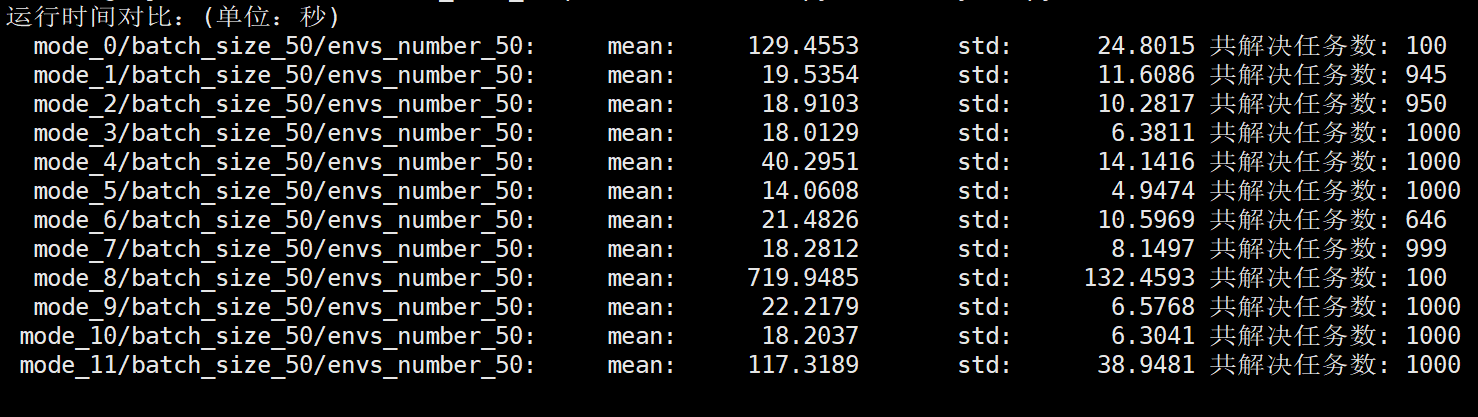
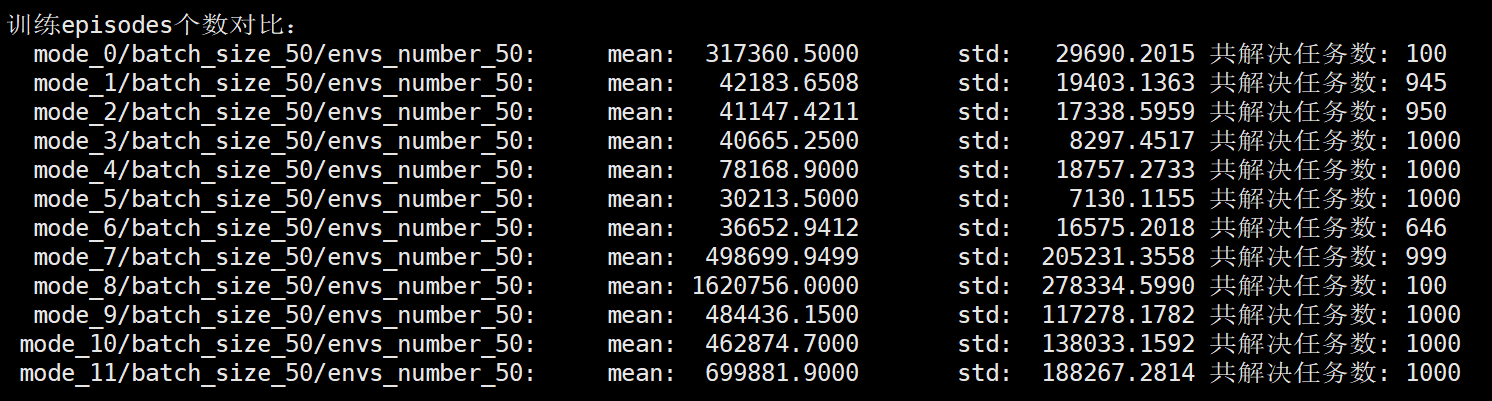
特别说明的是上面的mode=0 和 mode=8 这两种模式下均是进行了100次试验,其他的设置下均进行了1000次试验。
试验中 batch_size=50, 单进程下并行环境数envs_number=50
并行进程数设置为8
============================================
Agent_0 为最原始的并行reinforce算法,没有加入exprience buffer 机制, 这里是作为对比算法出现。
Agent_1 # experience buffer, size=50
在训练数据时依然优先出actor进程中获取训练数据,如果训练进程在请求actor进程中数据后没有获得数据(还没有数据生成)那么便从exprience buffer中抽取数据进行训练。每次训练进程在获得actor进程中的数据后都会将其加入到exprience buffer中。
Agent_2 # experience buffer, size=10
和Agent_1 算法基本完全一致,唯一不同的是experience buffer中存放的数据为Agent_1的五分之一。
Agent_3 # experience buffer中连续抽取次数设有上限15
为了解决Agent_1 和 Agent_2中有部分试验没有正确的获得结果(有部分试验没有收敛到目标结果),分析后是没有控制好buffer中数据的新鲜程度,也就是buffer中的数据更新的慢了,也可以说是actor进程生成的数据慢了,导致buffer中在没有新鲜数据进入的同时还被训练进程持续抽取数据。为了改进这一点Agent_3这里对连续抽取buffer的次数设置上限为15,也就是说在没有新的actor数据进入buffer中那么只能连续进行15次的数据抽取。
Agent_4 # experience buffer中连续抽取次数设为5
和 Agent_3 算法基本完全一致,区别为对连续抽取次数的上限设置为 5 。
Agent_5 # experience buffer中连续抽取次数设为15
与前面的1,2,3,4算法不同,Agent_5每次训练数据都是从buffer中抽取的,不会直接对actor进程传来的数据进行训练,或者说每次获得actor数据后都是先将其存入buffer中然后再从buffer抽取数据。在没有新鲜actor数据加入到buffer的情况下,连续从buffer中抽取数据的次数上限设置为15。
Agent_6 # experience buffer中连续抽取次数设为25
于Agent_5 基本相同,唯一不同的是从buffer连续抽取的次数上限设置为25。
Agent_7 # 完全从experience buffer里面抽取(每次抽取数据时不限制新数据的添加)
每次都需要从buffer中抽取,但是不和5,6那样对连续抽取次数做限制,但是每次进行网络迭代更新计算的时候都强制性的试着进行一定次数的对buffer添加数据的操作。
Agent_8 # 完全从experience buffer里面抽取(每次抽取数据时至少一次新数据的添加)
基本和Agent_7一样,唯一不同的是每次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_9 # 完全从experience buffer里面抽取(15次抽取数据时至少一次新数据的添加)
基本和Agent_7, Agent_8一样,唯一不同的是每15次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_10 # 完全从experience buffer里面抽取(25次抽取数据时至少一次新数据的添加)
基本和Agent_7, Agent_8,Agent_9一样,唯一不同的是每25次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_11 # x: loss+( 完全从experience buffer里面抽取(25次抽取数据时至少一次新数据>的添加))
基本和Agent_10一样,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer,唯一不同的是每25次从buffer中抽取时都至少保证有一个新数据加入到buffer中,并且需要同时保证在这25次抽取数据之内上一次抽取的训练过程所得结果要优之前100次所得结果的平均值,否则需要等待新的数据加入到buffer中才可以进行数据抽取。或者说和Agent_10唯一不同的是在不需要等待新数据加入到buffer中的条件不仅是在没有新数据加入buffer中最多不能连续抽取25次数据,同时还需要保证上一次的运行结果要优于之前100次的平均值, 否则必须需要新数据加入buffer后才可以抽取数据。通过运行结果(上图)可以发现加入第二个限制条件后优化效果没有比Agent_10好,反而变得更差了,这说明通过上次结果与前100次结果均值做比较难以判断buffer中数据是否足够fresh,该设置反而导致优化效果下降。
经过试验可以发现on-policy的强化学习在特定情况下也是可以使用experience buffer的。on-policy算法多环境并行化时在使用experience buffer机制后,对没有新数据加入buffer中情况下连续抽取buffer数据的次数做一定限制(次数上限)可以很好的提升算法性能。
===============================================
同策略强化学习算法可以使用经验缓存池(experience buffer)吗 ??? 设计一个基于缓存池的改进reinforce算法,给出初步的尝试 ---------- (reinforce + experience buffer)的更多相关文章
- 强化学习 CartPole实验的一些启发 有没有可能设计一个新的实验呢?(杆子可以向360度方向倾倒,可行吗?)
最近在看强化学习方面的东西,突然想到了这么一个事情,那就是经典的CartPole游戏我们改变一下,或者说升级一下,那么使用强化学习是否能得到不错的效果呢? 原始游戏如图: 一点个人的想法: ===== ...
- DQN 处理 CartPole 问题——使用强化学习,本质上是训练MLP,预测每一个动作的得分
代码: # -*- coding: utf-8 -*- import random import gym import numpy as np from collections import dequ ...
- 一个基于特征向量的近似网页去重算法——term用SVM人工提取训练,基于term的特征向量,倒排索引查询相似文档,同时利用cos计算相似度
摘 要 在搜索引擎的检索结果页面中,用户经常会得到内容相似的重复页面,它们中大多是由于网站之间转载造成的.为提高检索效率和用户满意度,提出一种基于特征向量的大规模中文近似网页检测算法DDW(Det ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 【转载】 强化学习(三)用动态规划(DP)求解
原文地址: https://www.cnblogs.com/pinard/p/9463815.html ------------------------------------------------ ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
随机推荐
- ABC337
E 其实就是构造出最小的方案. 我们把二进制第 \(i\) 为 \(1\) 的所有数放到一起查询. 所以如果第 \(i\) 次询问的回答是 \(1\) 那么有问题的饮料二进制下的第 \(i\) 为就是 ...
- ABC317题解报告
我直接从第三题开始讲了. T3 把数组 \(A\) 从大到小排序. 然后从前往后把前 \(q\) 个数加起来,然后判断这 \(q\) 个数的和与 \(d\) 的大小关系,如果大了就变成 \(d\). ...
- INFINI Labs 产品更新 | Easysearch 1.7.1发布
INFINI Labs 产品又更新啦~,包括 Console,Gateway,Agent 1.23.0 和 Easysearch 1.7.1.此次版本重点修复历史遗留 Bug .网友们提的一些需求等. ...
- Grafana 开源了一款 eBPF 采集器 Beyla
eBPF 的发展如火如荼,在可观测性领域大放异彩,Grafana 近期也发布了一款 eBPF 采集器,可以采集服务的 RED 指标,本文做一个尝鲜介绍,让读者有个大概了解. eBPF 基础介绍可以参考 ...
- zabbix---监控Oracle12c数据库
使用插件:orabbix用于监控oracle实例的zabbix插件 orabbix插件下载地址:http://www.smartmarmot.com/product/orabbix/download/ ...
- 09-CentOS软件包管理
简介 CentOS7使用rpm和yum来管理软件包. CentOS 8附带YUM包管理器v4.0.4版本,该版本现在使用DNF (Dandified YUM)技术作为后端.DNF是新一代的YUM,新的 ...
- 浅谈k8s中cni0和docker0的关系和区别
最近在复习k8s网络方面的知识,查看之前学习时整理的笔记和文档还有过往自己总结的博客之后发现一个问题,就是在有关flannel和calico这两个k8s网络插件的文章和博客中,会涉及到cni0和doc ...
- 【资料分享】全志科技T507-H工业核心板规格书
1 核心板简介 创龙科技SOM-TLT507是一款基于全志科技T507-H处理器设计的4核ARM Cortex-A53全国产工业核心板,主频高达1.416GHz.核心板CPU.ROM.RAM.电源.晶 ...
- mermaid语法画图
mermaid 脚本语言 graph TB 从上到下 graph BT 从下到上 graph RL 从右到左 graph LR 从左到右 graph LR; A001-->B001; graph ...
- 使用urllib3实现http请求
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3. 1.发送请求 import urllib3 # 创建实例 http ...