【论文阅读】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal
论文题目:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
参考与前言
arXiv 地址:
github代码地址(还没开,六月开):https://github.com/zhiqi-li/BEVFormer
整篇文章方法挺清晰的 理解起来不费劲
1. Motivation
做的任务是:3D detection,主要是提出使用BEV的表达方式去做感知类任务
问题场景
Perception in 3D space
因为整篇是拿相机在做表达和任务,所以先是说明相机优势:identify vision-based road elements (e.g., traffic lights, stoplines);指出BEV优势:清晰的表述了物体的位置和大小,比较适合自动驾驶里感知和规划的任务,同时连接了 temporal 和 spatial space,时空两个空间
同时指出现有的BEV方案:1. 2D plane,2. 从深度信息获取特征,对深度值和深度分布太敏感
因为基于BEV方法的detection performance 会受 compounding error和BEV特征的影响,所以我们提出了一种 不受深度信息,同时无需严格依靠3d prior 学习BEV的方法
Contribution
- 提出一种 以多相机和时间作为输入的,时空transformer encoder
We propose BEVFormer, a spatiotemporal transformer encoder that projects multi-camera and/or timestamp input to BEV representations. - 设计了通过在空间上的cross-attention,和时间上的self-attention,设计 learnable BEV queries 去做时域上的结合,然后加到Unified BEV 特征中
- 做nuScenes和Waymo的detection任务重取得了不错的效果
相关工作中介绍了 基于transformer-based 2D perception,和基于相机的 3D Perception
问题区:
cross-camera post-processing
是指将相机进行坐标转换 把数据对其嘛?还是啥? → 好像就是多相机的处理
3d prior是指不同相机之间的外参嘛?所以是指的是减弱外参在整个框架中的先验?
2. Method
2.1 框架
框架图挺清晰,从输入是六个角度的相机,通过一个可选的backbone(比如resnet101)
- 每张照片都得到一个 feature \(F_t^i\) 其中 i 指代第 i 个相机,合起来就是得到一个 \(F_t=\{F_t^i\}_{i=1}^{N_{\text{view}}}\)
- BEV Queries Q 是 gird-shaped learnable parameter \(Q \in \R^{H\times W \times C}\) H, W就是空间下BEV平面的大小,在 点\(p=(x, y)\) 下的 \(Q_p \in \R^{1 \times C}\) 和其对应的BEV plane grid cell region有关,每个格都代表现实世界中s米的范围长度(s分辨率
对 queries Q里同样加入learnable的positional embedding

2.2 Spatial Cross-Attention 空间域
过程可以用该公式概括:
\]
对于每个 \(Q_p\) 我们都有一个project function \(\mathcal P(p,i,j)\) 以获取 i-th相机下的 j-th 参考点
从现实坐标 \((x',y')\) 中 找到对应的query p=(x,y) 下 \(Q_p\) :
\]
同时因为在(x’,y’)上的物体也会有z上的高度,所以对于每个query \(Q_p\) 我们会得到 a pillar of 3D 参考点 \(\left(x^{\prime}, y^{\prime}, z_{j}^{\prime}\right)_{j=1}^{N_{\mathrm{ref}}}\) 然后通过projection matrix投到对应的相机下
\]
其中\(T_i \in \R^{3\times 4}\) 就是第i个相机的projection matrix
2.3 Temporal Self-Attention 时间域
主要是要拿上一个输出的 BEV \(B_t\) 作为输入
\]
不同于vanilla deformable attention,这个offsets \(\Delta p\) 是从此处 concate \(\{Q, B’_{t-1}\}\) 预测而出
问题区:
R-101 DCN 没找到... 搜了一下 相关Github: https://github.com/open-mmlab/mmdetection/blob/master/configs/dcn/README.md
是resnet 101 卷积核可变吗?【15, 12】 实验中 用了两个backbone进行对比
projection matrix是到车中心?
只要是一个中心就行..
开始咋处理? 上一帧输入 BEV \(B_t\)
重复 Q,
3. 实验及结果
实现细节上:
- 选择t时,是从相邻2s时间内随机采样而来,减少ego-motion的diversity,比如四个采样:\(t-3,t-2,t-1, t\),由此可得到:\(\left\{B_{t-3}, B_{t-2}, B_{t-1}\right\}\)
- 因为 \(B_t\) 是基于多相机and \(B_{t-1}\)的,所以\(B_t\) 包含four samples的时空域clues
Loss function是根据 任务定义而来的,比如detection、segmentation等
结果表

nuScenes 数据集

waymo数据集
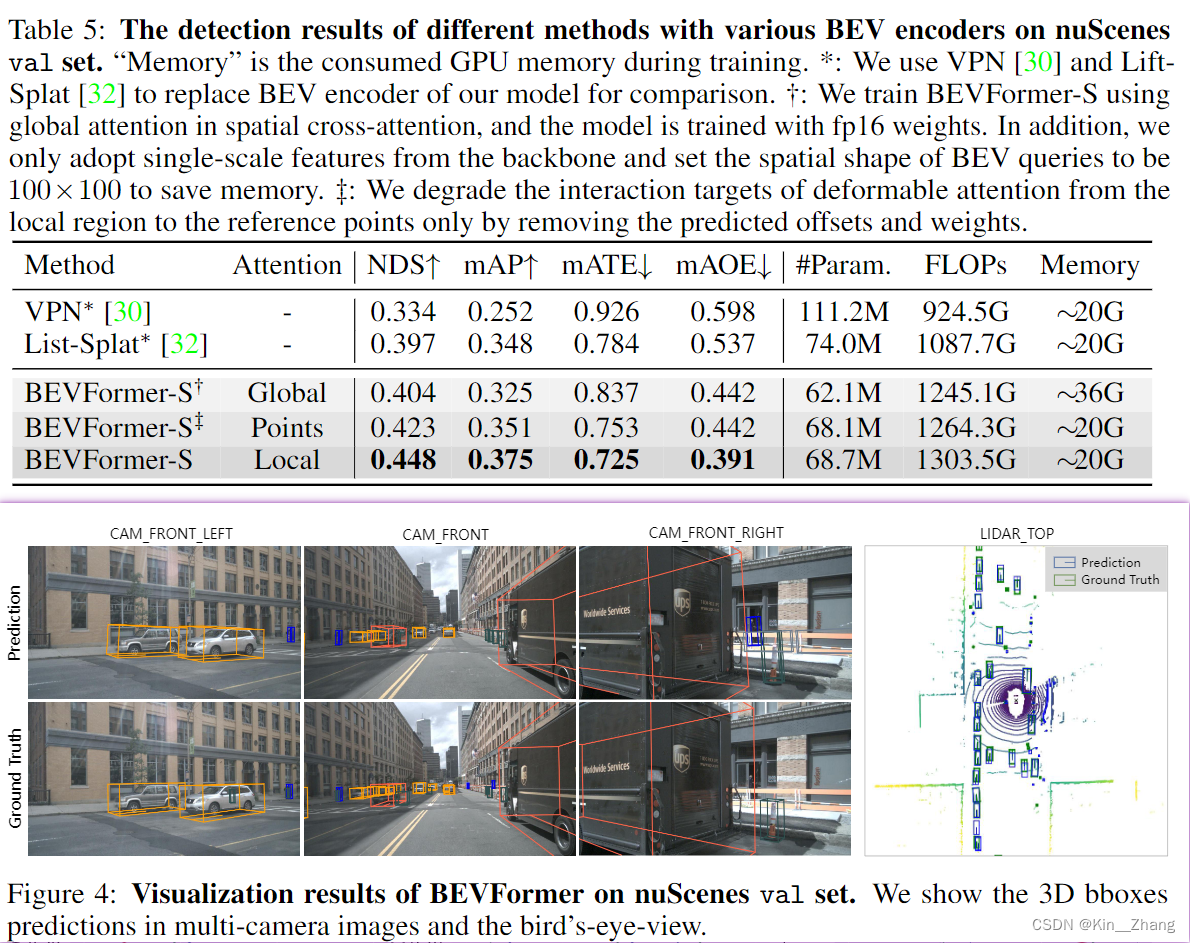
4. Conclusion
提出BEVFormer,验证其效果不错
limitation中提到了 和LiDAR-based还是有gap的,主要在effect和efficiency上(但是其实在本文表1 pointpaiting也并没有 ... effect上比BEVFormer好?可能只是这种指标下

碎碎念
代码还没开,可以等一波,但是好像知乎有人讨论说 也不一定会按时开。先就大概看看,网络方法输入输出都挺清晰的,就是感觉 emmm 效果意外的好 hhh
- 有些细节有点迷,比如x’,y’获取是内参+外参直接pixel到全局坐标系下吗?
- 估计后面跑跑 debug一下理解更深点
不同的方法对时间域数据上的处理方式各不相同,感觉时间域上的玩法还挺多的,比如上次MP3里面是optical flow, interesting;这种在视频领域更多一点 上次看沐神b站上有讲过I3D 3D-conv
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal的更多相关文章
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 论文阅读 DyREP:Learning Representations Over Dynamic Graphs
5 DyREP:Learning Representations Over Dynamic Graphs link:https://scholar.google.com/scholar_url?url ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- 【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1702.05891 Caffe-code:https:// ...
- 论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测 论文地址 Abstract 关于知识库完成的研究(也称为关系预测)的任务越来越受关注.多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达 ...
- Learning under Concept Drift: A Review 概念漂移综述论文阅读
首先这是2018年一篇关于概念漂移综述的论文[1]. 最新的研究内容包括 (1)在非结构化和噪声数据集中怎么准确的检测概念漂移.how to accurately detect concept dri ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
随机推荐
- 大营销抽奖系统,DDD开发要如何建模?
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 大家好,我是技术UP主小傅哥. 经过5.1假期的一顿框框输出,终于完成了<大营销项目 ...
- 自定义的基于System.Net.Http.HttpClient的WebClient,可以作为微信支付宝的发起请求时的基础请求类
个人编写的,自己用于自己的微信api的请求的实现当中,源码公开,大家可以查看反编译源码.以下是使用方法: 第一步 搜索和安装zmjtool 第二步 发起请求 1 /**引入命名空间*/ 2 using ...
- cesium教程2-加载显示地形地图
上面地形数据,是调用cesium官方的地图服务,需要先注册cesium账户,配置cesium的账户token才行 1.在线地形服务的示例代码如下 <!DOCTYPE html> <h ...
- Splashtop获5000万美元新投资 成为远程桌面行业独角兽
加利福尼亚州圣何塞,2021 年 1 月 27 日 - 下一代远程访问和远程支持领域的新兴领导者 Splashtop Inc. 完成了新一轮的 5000 万美元融资,其估值已超过了 10 亿美元的独角 ...
- Idefics2 简介: 为社区而生的强大 8B 视觉语言模型
我们很高兴在此发布 Idefics2,这是一个通用的多模态模型,接受任意文本序列和图像序列作为输入,并据此生成文本.它可用于回答图像相关的问题.描述视觉内容.基于多幅图像创作故事.从文档中提取信息以及 ...
- 薄书的Gitee 码云使用教程学习纪录
git 使用帮助 参考: https://www.liaoxuefeng.com/wiki/896043488029600/1163625339727712 https://blog.csdn.net ...
- 使用Docker安装Odoo 17(非Docker Compose)
使用Docker安装Odoo 17(非Docker Compose) 前言 最近在学习Odoo,先是windows 安装企业版,多年不用windows的服务器操作系统,一看windows的ECS那么贵 ...
- gRPC入门学习之旅(九)
gRPC入门学习之旅目录 gRPC入门学习之旅(一) gRPC入门学习之旅(二) gRPC入门学习之旅(三) gRPC入门学习之旅(四) gRPC入门学习之旅(七) 3.10.客户端编译生成GRP ...
- Linux和Windows时间不一致问题
问题描述 装过双系统或者虚拟机装Linux的人都知道,Linux的时间和Windows往往是不同步的,在编写跨平台程序的时候特别是对时间敏感的代码就带来很大的困扰 解决办法 这个问题可以在Linux下 ...
- uview 滑动切换
```html <template> <view class="content"> <!-- <u-row justify="spac ...