第 9章 数据分析案例:Python 岗位行情
第 9章 数据分析案例:Python 岗位行情
9.1 数据爬取
(1)打开某招聘网站首页 https://www.lagou.com,选择“全国站”,在搜索栏输入 Python,单击“搜索”。
(2)滚动到底部可以看到只有 30 页。
(3)多次单击“下一页”,发现页面并没有全部刷新,猜测是 Ajax 动态加载数据,在Chrome 浏览器中打开开发者工具进行抓包分析,使用 XHR 过滤,刷新网页。找到positionAjax.json文件。
知道获取哪里的数据,接下来就是模拟请求了,单击 Headers 选项卡。
没有登录也能访问,说明 Cookies 请求可以不用设置,其他请求不变,接着是 POST提交的表单数据:
data = {
'first': 'true',
'pn': page,
'kd': '数据分析师'
}
first 表示是不是第一次加载,pn 是页码,kd 是搜索关键词,爬取时只修改页码,其他两个参数不变。
接着运行程序把数据写入 CSV 文件。
import requests
import json
import csv
import time
url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
# 请求网页
headers = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88/p-city_0?',
"Cookie": "user_trace_token=20240109144522-22a864fb-165d-40a5-9106-c8c4dc0833be; _ga=GA1.2.714090013.1704782724; LGUID=20240109144524-b4c91de5-c00e-44ad-980e-8b390e6ce3cb; JSESSIONID=ABAABJAACEEACDC491607BADD16CFBD16DE05AEF3F65DE9; WEBTJ-ID=20240216172151-18db138e28a13c5-04d07b79f5d239-26001851-1327104-18db138e28b18fb; RECOMMEND_TIP=true; sensorsdata2015session=%7B%7D; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1708075312; _gid=GA1.2.1801299287.1708075312; privacyPolicyPopup=false; index_location_city=%E5%85%A8%E5%9B%BD; __lg_stoken__=8d209f0da8117a7f227ff5bcf85d5aee81ec638f51b321ab2499d1a1e55477b18a018cdb186c91a2755690b0a0d079fa17a47b5da95e94296d5b65e2fba66056f85d7d5c25a5; X_HTTP_TOKEN=eabfd70a31a2b04619267080711fa44a831f8c5fff; X_MIDDLE_TOKEN=b85d819be2e6990415429d15f75d4bb5; PRE_UTM=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; _gat=1; LGSID=20240216185902-8375e3ec-6a8d-4188-9d25-b1197100f1b1; PRE_HOST=link.zhihu.com; PRE_SITE=https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fwww.lagou.com%2F; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1708081146; _ga_DDLTLJDLHH=GS1.2.1708080415.3.1.1708081145.60.0.0; LGRID=20240216185906-2a43cf92-b853-4adc-8867-683bfabe304d; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218cecf7fb5136f-0d4d5589a6224f-26001951-1327104-18cecf7fb5283d%22%2C%22%24device_id%22%3A%2218cecf7fb5136f-0d4d5589a6224f-26001951-1327104-18cecf7fb5283d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%A4%BE%E4%BA%A4%E7%BD%91%E7%AB%99%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fwww.lagou.com%2F%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%22121.0.0.0%22%7D%7D",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
}
with open('lagou_jobs.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['position_id', 'position_name', 'company_size', 'finance_stage', 'city', 'salary', 'work_year', 'education', 'job_nature']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
count = 1 # 计数器
for page in range(1, 10):
data = {
'first': 'true',
'pn': page,
'kd': '数据分析师'
}
response = requests.post(url=url, headers=headers, data=data, timeout=3)
response = json.loads(response.content)
# 获取数据
result_data = response['content']['positionResult']['result']
# 写入CSV文件
for i in result_data:
position_id = i['positionId'] # 职位Id
position_name = i['positionName'] # 职位名称
company_size = i['companySize'] # 公司规模
finance_stage = i['financeStage'] # 融资阶段
city = i['city'] # 城市
salary = i['salary'] # 薪水
work_year = i['workYear'] # 工作年限
education = i['education'] # 教育背景
job_nature = i['jobNature'] # 工作性质
writer.writerow({
'position_id': position_id,
'position_name': position_name,
'company_size': company_size,
'finance_stage': finance_stage,
'city': city,
'salary': salary,
'work_year': work_year,
'education': education,
'job_nature': job_nature
})
print("已经完成第{}页数据爬取".format(count))
count += 1
# 暂停一段时间,避免请求过于频繁
time.sleep(1)
部分数据如表

打开 CSV 文件可以看到爬取的数据。数据有了,接下来就是准备开始数据可视化分析。在此之前,我们先要来了解数据分析的两个常用库 NumPy 与 pandas。
9.2 NumPy 库和 pandas 库
NumPy 库是科学计算的基础库,提供了一个多维数组对象(ndarray)和各种派生对象(如 Masked、arrays 和矩阵),以及各种加速数组操作的例程,包括数学、逻辑、图形变换、排序、选择、io、离散傅里叶变换、基础线性代数、基础统计、随机模拟等。
概念看上去很复杂,目前我们只了解 ndarray 常用的基本函数就够了,安装 NumPy 库可以通过 pip 命令(pip install numpy)或 Anaconda 库(conda install numpy)完成。
9.2.1 ndarray 数组
ndarray 是一个多维的数组对象,和 Python 自带的列表、元组等元素最大的区别就是后者元素的数据类型可以是不一样的,比如一个列表里可能存放着整型、字符串,而 ndarray中元素的数据类型必须是相同的。可以通过 NumPy 库提供的 array 函数来生成一个 ndarray数组,传入一个列表或元组即可创建。下面演示生成 ndarray 的多种方法,以及几个常用属性。
import numpy as np
print("1.生成一个一维数组:\n %s" % np.array([1, 2]))
print("2.生成一个二维数组:\n %s" % np.array([[1, 2], [3, 4]]))
print("3.生成一个元素初始值都为0的4行3列矩阵:\n %s" % np.zeros((4, 3)))
print("4.生成一个元素初始值都为1的3行4列矩阵:\n %s" % np.ones((3, 4)))
print("5.创建一个空数组,元素为随机值:\n %s" % np.empty([2, 3], dtype=int))
a1 = np.arange(0, 30, 2)
print("6.生成一个等间隔数字的数组:\n %s" % a1)
a2 = a1.reshape(3, 5)
print("7.转换数组的维度,比如把一维的转换为3行5列的数组:\n %s" % a2)
# ndarray常用属性
print("8.a1的维度: %d \t a2的维度:%d" % (a1.ndim, a2.ndim))
print("9.a1的行列数:%s \t a2的行列数:%s" % (a1.shape, a2.shape))
print("10.a1的元素个数:%d \t a2的元素个数:%d" % (a1.size, a2.size))
print("11.a1的元素数据类型:%s 数据类型大小:%s" % (a1.dtype, a1.itemsize))
运行代码,结果如下:
1.生成一个一维数组:
[1 2]
2.生成一个二维数组:
[[1 2]
[3 4]]
3.生成一个元素初始值都为0的4行3列矩阵:
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
4.生成一个元素初始值都为1的3行4列矩阵:
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
5.创建一个空数组,元素为随机值:
[[ 809116279 1885413932 -2124452662]
[-2147455881 1701061164 1702259052]]
6.生成一个等间隔数字的数组:
[ 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28]
7.转换数组的维度,比如把一维的转换为3行5列的数组:
[[ 0 2 4 6 8]
[10 12 14 16 18]
[20 22 24 26 28]]
8.a1的维度: 1 a2的维度:2
9.a1的行列数:(15,) a2的行列数:(3, 5)
10.a1的元素个数:15 a2的元素个数:15
11.a1的元素数据类型:int32 数据类型大小:4
9.2.2 ndarray 数组的常用操作
下面介绍 ndarray 的常用操作,和 Python 中的列表类似,方法较多不用去记,使用时查询即可。
import numpy as np
# 1.访问数组
a1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("访问第一行: %s" % a1[0])
a1[0] = 2 # 修改数组中元素的值
print("访问第一列: %s" % a1[:, 0])
print("访问前两行:\n {}".format(a1[:2]))
print("访问前两列:\n {}".format(a1[:, :2]))
print("访问第二行第三列:{}".format(a1[1][9]))
# 2.通过take函数访问数组(axis参数代表轴),put函数快速修改元素值
a2 = np.array([1, 2, 3, 4, 5])
print("take函数访问第二个元素:%s" % a2.take(1))
a3 = np.array([0, 2, 4])
print("take函数参数列表索引元素:%s" % a2.take(a3))
print("take函数访问某个轴的元素:%s" % a1.take(1, axis=1))
a4 = np.array([6, 8, 9])
a2.put([0, 2, 4], a4)
print("put函数快速修改特定索引元素的值:%s" % a2)
# 3.通过比较符访问元素
print("通过比较符索引满足条件的元素:%s" % a1[a1 > 3])
# 4.遍历数组
print("一维数组遍历:")
for i in a2:
print(i, end=" ")
print("\n二维数组遍历:")
for i in a1:
print(i, end=" ")
print("\n还可以这样遍历:")
for (i, j, k) in a1:
print("%s - %s - %s" % (i, j, k))
# 5.insert插入元素(参数依次为数组,插入轴的标号,插入值,axis=0插入行,=1插入列)
a5 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a5 = np.insert(a5, 0, [6, 6, 6], axis=0)
print("insert函数插入元素到第一行:\n %s " % a5)
# 6.delete删除元素(参数依次为数组,删除轴的标号,axis同上)
a5 = np.delete(a5, 0, axis=1)
print("delete函数删除第一列元素:\n %s" % a5)
# 7.copy深拷贝一个数组,直接赋值是浅拷贝
a6 = a5.copy()
a7 = a5
print("copy后的数组是否与原数组指向同一对象:%s" % (a6 is a5))
print("赋值的数组是否与原数组指向同一对象:%s" % (a7 is a5))
# 8.二维数组转一维数组,二维数组间数组合并
a8 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("二维数组 => 一维数组:%s" % a8.flatten())
a9 = np.array([[1, 2, 3], [4, 5, 6]])
a10 = np.array([[7, 8], [9, 10]])
print("两个二维数组合并 => 一个二维数组:\n{}".format(np.concatenate((a9, a10), axis=1)))
# 9.数学计算(乘法是对应元素相乘,叉乘用.dot()函数)
a11 = np.array([[1, 2], [3, 4]])
a12 = np.array([[5, 6], [7, 8]])
print("数组相加:\n%s" % (a11 + a12))
print("数组相减:\n%s" % (a11 - a12))
print("数组相乘:\n%s" % (a11 * a12))
print("数组相除:\n%s" % (a11 / a12))
print("数组叉乘:\n%s" % (a11.dot(a12)))
# 10.其他
a12 = np.array([1, 2, 3, 4])
print("newaxis增加维度:\n %s" % a12[:, np.newaxis])
print("tile函数重复数组(重复列数,重复次数):\n %s" % np.tile(a12, [2, 2]))
print("vstack函数按列堆叠:\n %s" % np.vstack([a12, a12]))
print("hstack函数按行堆叠:\n %s" % np.hstack([a12, a12]))
a13 = np.array([1, 4, 8, 2, 44, 77, -2, 1, 4])
a13.sort()
print("sort函数排序:\n %s" % a13)
print("unique函数去重:\n {}".format(np.unique(a13)))
运行结果如下:
访问第一行: [1 2 3]
访问第一列: [2 4 7]
访问前两行:
[[2 2 2]
[4 5 6]]
访问前两列:
[[2 2]
[4 5]
[7 8]]
访问第二行第三列:6
take函数访问第二个元素:2
take函数参数列表索引元素:[1 3 5]
take函数访问某个轴的元素:[2 5 8]
put函数快速修改特定索引元素的值:[6 2 8 4 9]
通过比较符索引满足条件的元素:[4 5 6 7 8 9]
一维数组遍历:
6 2 8 4 9
二维数组遍历:
[2 2 2] [4 5 6] [7 8 9]
还可以这样遍历:
2 - 2 - 2
4 - 5 - 6
7 - 8 - 9
insert函数插入元素到第一行:
[[6 6 6]
[1 2 3]
[4 5 6]
[7 8 9]]
delete函数删除第一列元素:
[[6 6]
[2 3]
[5 6]
[8 9]]
copy后的数组是否与原数组指向同一对象:False
赋值的数组是否与原数组指向同一对象:True
二维数组 => 一维数组:[1 2 3 4 5 6 7 8 9]
两个二维数组合并 => 一个二维数组:
[[ 1 2 3 7 8]
[ 4 5 6 9 10]]
数组相加:
[[ 6 8]
[10 12]]
数组相减:
[[-4 -4]
[-4 -4]]
数组相乘:
[[ 5 12]
[21 32]]
数组相除:
[[0.2 0.33333333]
[0.42857143 0.5 ]]
数组叉乘:
[[19 22]
[43 50]]
newaxis增加维度:
[[1]
[2]
[3]
[4]]
tile函数重复数组(重复列数,重复次数):
[[1 2 3 4 1 2 3 4]
[1 2 3 4 1 2 3 4]]
vstack函数按列堆叠:
[[1 2 3 4]
[1 2 3 4]]
hstack函数按行堆叠:
[1 2 3 4 1 2 3 4]
sort函数排序:
[-2 1 1 2 4 4 8 44 77]
unique函数去重:
[-2 1 2 4 8 44 77]
9.2.3 pandas 库
pandas 库提供了快速处理结构化数据的大量数据结构和函数,有两种常见的数据结构,分别为 Series(一维的标签化数组对象)和 DataFrame(面向列的二维表结构)。
pandas 库安装:
pip install pandas
Series 是一维的标签化数组对象,和Python 自带的列表类似,每个元素由索引与值构成,数组中的值为相同的数据类型。
注意:np.nan 用来标识空缺数据。
Series 代码如下:
import pandas as pd
import numpy as np
s1 = pd.Series([1, 2, 3, np.nan, 5])
print("1.通过列表创建Series对象:\n%s" % s1)
s2 = pd.Series([1, 2, 3, np.nan, 5], index=['a', 'b', 'c', 'd', 'e'])
print("2.通过列表创建Series对象(自定义索引):\n%s" % s2)
print("3.通过索引获取元素:%s" % s2['a'])
print("4.获得索引:%s" % s2.index)
print("5.获得值:%s" % s2.values)
print("6.和列表一样只支持分片的:\n{}".format(s2[0:2]))
s3 = pd.Series(pd.date_range('2014.1.17', periods=6))
print("7.利用date_range生成日期列表:\n%s" % s3)
代码运行结果如下:
1.通过列表创建Series对象:
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
dtype: float64
2.通过列表创建Series对象(自定义索引):
a 1.0
b 2.0
c 3.0
d NaN
e 5.0
dtype: float64
3.通过索引获取元素:1.0
4.获得索引:Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
5.获得值:[ 1. 2. 3. nan 5.]
6.和列表一样只支持分片的:
a 1.0
b 2.0
dtype: float64
7.利用date_range生成日期列表:
0 2014-01-17
1 2014-01-18
2 2014-01-19
3 2014-01-20
4 2014-01-21
5 2014-01-22
dtype: datetime64[ns]
DataFrame 具有面向列的二维表结构,类似于 Excel 表格,由行标签、列表索引与值三
部分组成,代码如下:
import pandas as pd
# 1.创建DataFrame对象
dict1 = {
'学生': ["小红", "小绿", "小蓝", "小黄", "小黑", "小灰"],
'性别': ["女", "男", "女", "男", "男", "女"],
'年龄': np.random.randint(low=10, high=15, size=6),
}
d1 = pd.DataFrame(dict1)
print("1.用相等长度的列表组成的字典对象生成:\n %s" % d1)
d2 = pd.DataFrame(np.random.randint(low=60, high=100, size=(6, 3)),
index=["小红", "小绿", "小蓝", "小黄", "小黑", "小灰"],
columns=["语文", "数学", "英语"])
print("2.通过二维数组生成DataFrame: \n %s" % d2)
# 2.数据查看
print("3.head函数查看顶部多行(默认5行):\n%s" % d2.head(3))
print("4.tail函数查看底部多行(默认5行):\n%s" % d2.tail(2))
print("5.index查看所有索引:%s" % d2.index)
print("6.columns查看所有行标签:%s" % d2.columns)
print("7.values查看所有值:\n%s" % d2.values)
# 3.数据排序
print("8.按索引排序(axis=0行索引,=1列索引排序,ascending=False降序排列):\n%s"
% (d2.sort_index(axis=0, ascending=False)))
print("9.按值进行排序:\n%s" % d2.sort_values(by="语文", ascending=False))
# 4.数据选择
print("9.选择一列或多列:\n{} {} ".format(d2['语文'], d2[['数学', '英语']]))
print("10.数据切片:\n{}".format(d2[0:1]))
print("11.条件过滤(过滤语文分数高于90的数据):\n{}".format(d2[d2.语文 > 90]))
print("12.loc函数行索引切片获得指定列数据:\n{}".format(d2.loc['小红':'小蓝', ['数学', '英语']]))
print("13.iloc函数行号切片获得指定列数据:\n{}".format(d2.iloc[4:6, 1:2]))
# 5.求和,最大/小值,平均值,分组
print("14.语文总分:{}".format(d2['语文'].sum()))
print("15.语文平均分:{}".format(d2['语文'].mean()))
print("16.数学最高分:{}".format(d2['数学'].max()))
print("17.英语最低分:{}".format(d2['英语'].min()))
# 6.数据输入输出(可以把数据保存到CSV或Excel中,也可以读取文件)
d1.to_csv('student_1.csv')
d3 = pd.read_csv('student_1.csv')
print("18.读取CSV文件中的数据:\n{}".format(d3))
d2.to_excel('student_2.xlsx', sheet_name="Sheet1")
d4 = pd.read_excel('student_2.xlsx', sheet_name="Sheet1")
print(("19.读取Excel文件中的数据:\n{}".format(d4)))
运行代码,结果如下:
1.用相等长度的列表组成的字典对象生成:
学生 性别 年龄
0 小红 女 10
1 小绿 男 10
2 小蓝 女 10
3 小黄 男 12
4 小黑 男 14
5 小灰 女 13
2.通过二维数组生成DataFrame:
语文 数学 英语
小红 60 83 74
小绿 97 83 80
小蓝 92 63 65
小黄 69 66 60
小黑 90 62 76
小灰 94 75 97
3.head函数查看顶部多行(默认5行):
语文 数学 英语
小红 60 83 74
小绿 97 83 80
小蓝 92 63 65
4.tail函数查看底部多行(默认5行):
语文 数学 英语
小黑 90 62 76
小灰 94 75 97
5.index查看所有索引:Index(['小红', '小绿', '小蓝', '小黄', '小黑', '小灰'], dtype='object')
6.columns查看所有行标签:Index(['语文', '数学', '英语'], dtype='object')
7.values查看所有值:
[[60 83 74]
[97 83 80]
[92 63 65]
[69 66 60]
[90 62 76]
[94 75 97]]
8.按索引排序(axis=0行索引,=1列索引排序,ascending=False降序排列):
语文 数学 英语
小黑 90 62 76
小黄 69 66 60
小蓝 92 63 65
小绿 97 83 80
小红 60 83 74
小灰 94 75 97
9.按值进行排序:
语文 数学 英语
小绿 97 83 80
小灰 94 75 97
小蓝 92 63 65
小黑 90 62 76
小黄 69 66 60
小红 60 83 74
9.选择一列或多列:
小红 60
小绿 97
小蓝 92
小黄 69
小黑 90
小灰 94
Name: 语文, dtype: int32 数学 英语
小红 83 74
小绿 83 80
小蓝 63 65
小黄 66 60
小黑 62 76
小灰 75 97
10.数据切片:
语文 数学 英语
小红 60 83 74
11.条件过滤(过滤语文分数高于90的数据):
语文 数学 英语
小绿 97 83 80
小蓝 92 63 65
小灰 94 75 97
12.loc函数行索引切片获得指定列数据:
数学 英语
小红 83 74
小绿 83 80
小蓝 63 65
13.iloc函数行号切片获得指定列数据:
数学
小黑 62
小灰 75
14.语文总分:502
15.语文平均分:83.66666666666667
16.数学最高分:83
17.英语最低分:60
18.读取CSV文件中的数据:
Unnamed: 0 学生 性别 年龄
0 0 小红 女 10
1 1 小绿 男 10
2 2 小蓝 女 10
3 3 小黄 男 12
4 4 小黑 男 14
5 5 小灰 女 13
19.读取Excel文件中的数据:
Unnamed: 0 语文 数学 英语
0 小红 60 83 74
1 小绿 97 83 80
2 小蓝 92 63 65
3 小黄 69 66 60
4 小黑 90 62 76
5 小灰 94 75 97
9.3 用 Matplotlib 实现数据可视化
Matplotlib 是一个用于 2D 图表绘制的Python 库,用法也很简单,可以轻易地绘制出各种图表。
推荐通过 pip 命令行进行安装:
pip install matplotlib
9.3.1 Matplotlib 中文乱码问题
使用 Matplotlib 进行图表绘制,第一个遇到的问题就是中文乱码问题
解决方法如下:
解决方案一:重载配置文件
import matplotlib as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
解决方案二:指定字体文件:在绘图时,可以指定支持中文的字体文件
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"/usr/share/fonts/truetype/arphic/uming.ttc") # 指定字体文件路径
plt.xlabel(u'时间', fontproperties=font) # 使用指定的字体绘制x轴标签
解决方案三:设置图形backend
import matplotlib.pyplot as plt
plt.switch_backend('agg') # 切换到agg backend,该backend支持中文显示
解决方案四:使用Seaborn
Seaborn是一个基于Matplotlib的高级数据可视化库,它默认支持中文,因此使用Seaborn也是解决中文乱码问题的一种简单方法。
import seaborn as sns
import matplotlib.pyplot as plt
sns.lineplot([1, 2, 3], [4, 5, 6])
plt.title("中文标题")
plt.xlabel("横轴")
plt.ylabel("纵轴")
plt.show()
9.3.2 Matplotlib 绘制显示不全
如图所示,在绘制时可能会出现显示不全的情况,需要进行设置。
9.3.3 用 Matplotlib 生成图表并进行分析
先调用 pd.read_csv()函数读取存放爬取数据的 CSV 文件,接着针对不同的列进行数据分析。
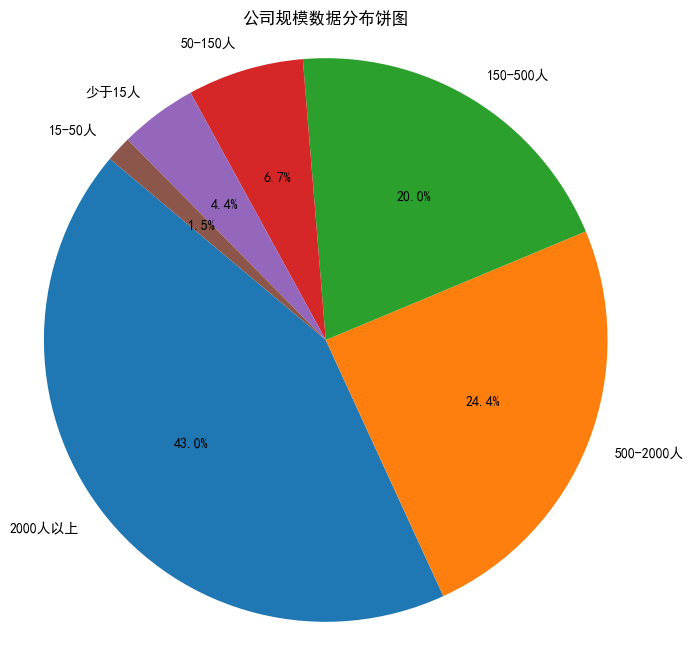
- 公司规模
获取 data 里的公司规模数据,调用value_counts()函数统计频次,接着绘制饼图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
data =pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 统计频次
company_size_counts = df['company_size'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(company_size_counts, labels=company_size_counts.index, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('公司规模数据分布饼图')
plt.show()
2. 公司融资状态
获取 data 里的融资状态数据,调用
value_counts()函数统计频次,接着绘制饼图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
data =pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 统计频次
company_size_counts = df['finance_stage'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(company_size_counts, labels=company_size_counts.index, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('公司融资数据分布饼图')
plt.show()
![image]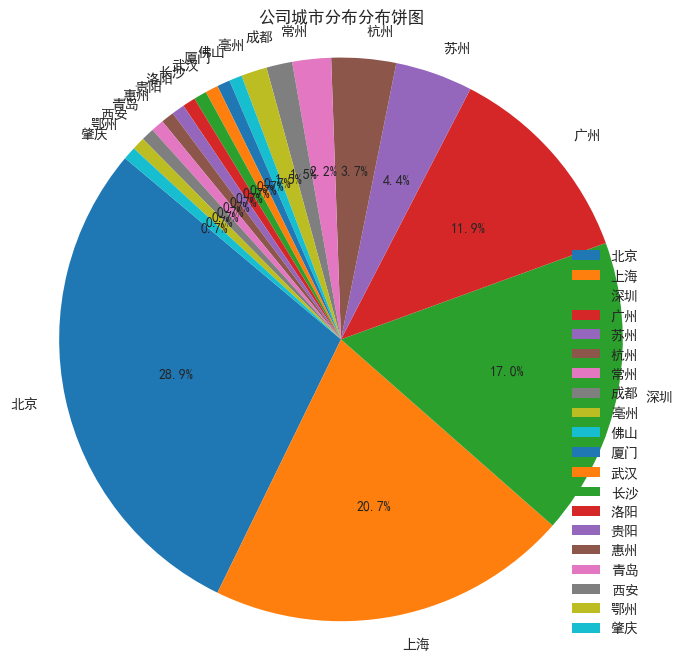
- 公司城市分布
获取 data 里的城市数据,调用value_counts()函数统计频次,接着绘制饼图。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 统计频次
company_size_counts = df['city'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(company_size_counts, labels=company_size_counts.index, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('公司城市分布分布饼图')
# 重新设置标签方向
plt.legend(loc='best')
plt.show()
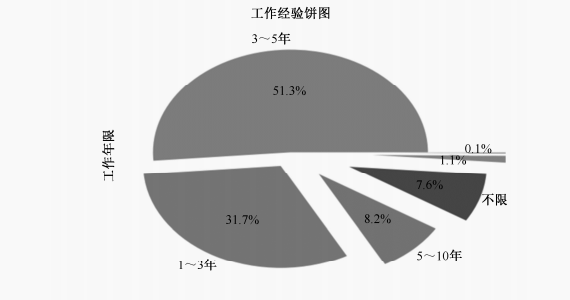
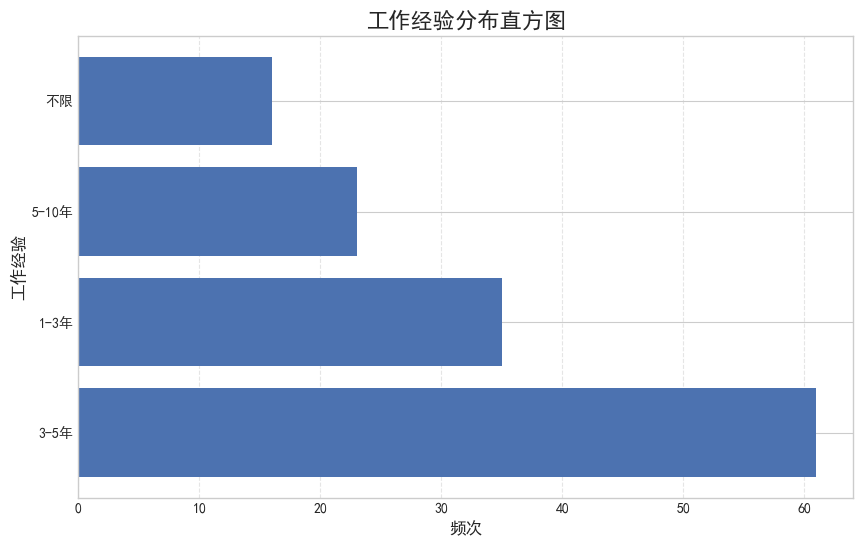
4. 工作经验
获取 data 里的工作经验数据,调用value_counts()函数统计频次,接着分别绘制直方图和饼图。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
mpl.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 获取工作经验数据并统计频次
experience_counts = df['work_year'].value_counts()
# 设置绘图参数
plt.figure(figsize=(10, 6))
bar_color = '#4c72b0'
# 绘制横向直方图
plt.barh(experience_counts.index, experience_counts, color=bar_color)
# 添加标题和标签
plt.title('工作经验分布直方图', fontsize=16)
plt.xlabel('频次', fontsize=12)
plt.ylabel('工作经验', fontsize=12)
# 添加网格线
plt.grid(axis='x', linestyle='--', alpha=0.5)
plt.show()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(experience_counts, labels=experience_counts.index, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('工作经验数据分布饼图')
plt.legend(loc='best')
plt.show()

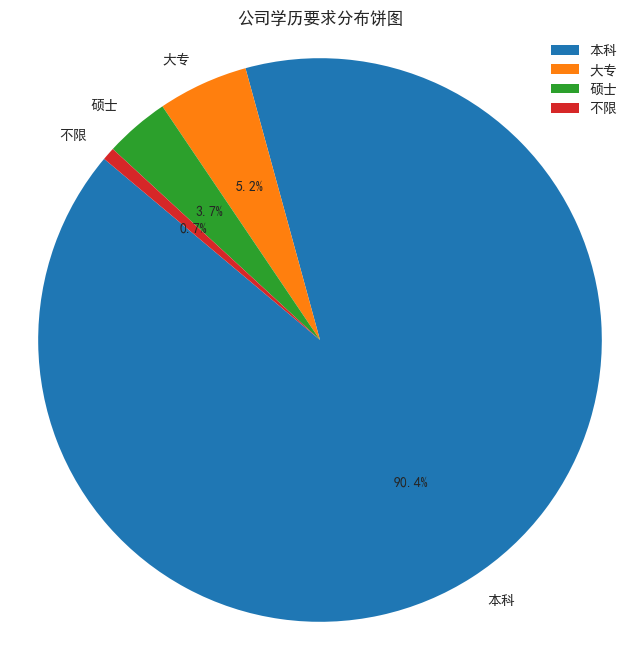
- 学历要求
获取 data 里的学历数据,调用value_counts()函数统计频次,接着绘制饼图。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 统计频次
company_size_counts = df['education'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(company_size_counts, labels=company_size_counts.index, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('公司学历要求分布饼图')
# 重新设置标签方向
plt.legend(loc='best')
plt.show()
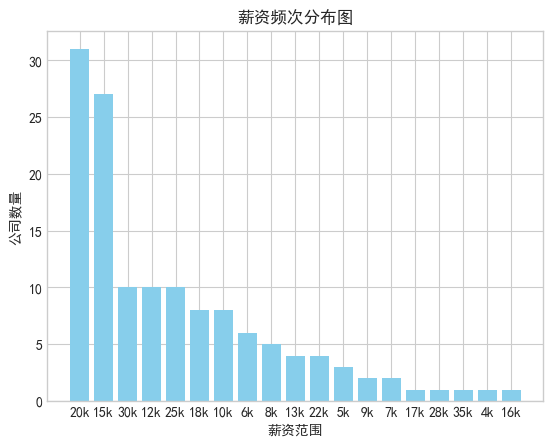
- 薪资
获取 data 里的薪资数据,调用value_counts()函数统计频次,接着绘制条形图。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('lagou_jobs.csv')
df = pd.DataFrame(data)
# 提取最低薪资数据
salaries = df['salary'].str.split('-', expand=True)[0]
# 统计频次
salary_counts = salaries.value_counts()
# 提取薪资范围和对应的公司数量
salary_ranges = salary_counts.index
company_counts = salary_counts.values
# 绘制条形图
plt.bar(salary_ranges, company_counts, color='skyblue')
plt.xlabel('薪资范围')
plt.ylabel('公司数量')
plt.title('薪资频次分布图')
plt.show()
9.4 用 Wordcloud 库进行词云绘制
词云以词语为基本单位,用于更直观和艺术地展示文本,在 Python 中我们可以使用Wordcloud 库来实现精美的词云图。
9.4.1 Wordcloud 简介
我们可以进行词频统计,即统计每个词语出现的次数,然后按照比例生成词云。而生成词云可以利用 Wordcloud 库。
推荐通过 pip 命令进行安装:
pip install wordcloud
9.4.2 Wordcloud 构造函数与常用方法
- 构造函数
def __init__(self, font_path=None, width=400, height=200, margin=2,
ranks_only=None, prefer_horizontal=.9, mask=None, scale=1,
color_func=None, max_words=200, min_font_size=4,
stopwords=None, random_state=None, background_color='black',
max_font_size=None, font_step=1, mode="RGB",
relative_scaling=.5, regexp=None, collocations=True,
colormap=None, normalize_plurals=True):
- 参数详解
- font_path:字体路径,就是绘制词云用的字体,如 monaco.ttf。
- width:输出的画布宽度,默认为 400 像素。
- height:输出的画布高度,默认为 200 像素。
- margin:画布偏移,默认为 2 像素。
- prefer_horizontal:词语水平方向排版出现的概率,默认为 0.9,垂直方向出现的概
- 率为 0.1。
- mask:如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高
- 值将被忽略,遮罩形状被 mask,全白(#FFFFFF)的部分将不会绘制,其余部分
- 会用于绘制词云。比如 bg_pic = imread('读取一张图片.png'),背景图片的画布一定
- 要设置为白色(#FFFFFF),图片形状显示为其他颜色。可以用绘图工具将要显示
- 的形状复制到一个纯白色的画布上再保存。
- scale:按照比例放大画布,比如设置为 1.5,则长和宽都是原画布的 1.5 倍。
- color_func:生成新颜色的函数,如果为空,则使用 self.color_func。
- max_words:显示的词的最大个数。
- min_font_size:显示的最小字体的大小。
- stopwords:需要屏蔽的词(字符串集合),为空则使用内置 stopwords。
- random_state:如果给出了一个随机对象,则生成一个随机数。
- background_color:背景颜色,默认为黑色。
- max_font_size:显示的最大字体的大小。
- font_step:字体步长,如果步长大于 1,会加快运算,但是可能导致结果出现较大的误差。
- mode:当参数为"RGBA",并且 background_color 不为空时,背景为透明,默认为RGB。
- relative_scaling:词频和字体大小的关联性,默认为 5。
- regexp:使用正则表达式分隔输入的文本。
- collocations:是否包括两个词的搭配。
- colormap:给每个单词随机分配颜色,若指定 color_func,则忽略该方法。
- normalize_plurals:是否删除尾随的词语。
- 常见的几个函数
- fit_words(frequencies):根据词频生成词云。
- generate(text):根据文本生成词云。
- generate_from_frequencies(frequencies[, ...]):根据词频生成词云。
- generate_from_text(text):根据文本生成词云。
- process_text(text):将长文本分词并去除屏蔽词(此处指英语,中文分词还需要用
- 其他库先实现,如fit_words(frequencies))。
- recolor([random_state, color_func, colormap]):对现有输出重新上色。重新上色会比重新生成整个词云快很多。
- to_array():转化为 numpy array。
- to_file(filename):输出到文件。
9.4.3 一个简单的词云
我们生成一个简单词云 并用image绘出来
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
wcd = wordcloud.WordCloud(background_color='white')
text = 'hello world python windows css html javascript'
# 生成词云
wcd.generate(text) # Generate wordcloud from text.
wcd.to_image()

从中可以看见单词很散,很少, 我们对 词云对象 添加两个属性, repeat = true(重复)max_words (最大词数)
# 设置背景为白色,单词重复,词数限制,放大长宽
wcd1 = wordcloud.WordCloud(background_color='white',repeat=True,max_words=100,width=800,height=600,max_font_size=100)
wcd1.generate(text)
wcd1.to_image()

9.4.4 中文版词云
zh_hans_text = "自由、平等、公正、法治。自由、平等、公正、法治"
wcd_zh_hans = wordcloud.WordCloud(background_color='white',repeat=True,max_words=100,width=800,height=600,max_font_size=100)
wcd_zh_hans.generate(zh_hans_text)
wcd_zh_hans.to_image()
可以发现 编码问题出现了

解决方案: 修改 font path 为中文字体路径
中文字体路径在哪里找呢,在C:\Windows\Fonts
zh_hans_text = "自由、平等、公正、法治。自由、平等、公正、法治"
wcd_zh_hans = wordcloud.WordCloud(font_path='C:/Windows/Fonts/SimHei.ttf',background_color='white',repeat=True,max_words=100,width=800,height=600,max_font_size=100)
wcd_zh_hans.generate(zh_hans_text)
wcd_zh_hans.to_image()

自定义轮廓(根据图片)
import PIL
import wordcloud
import numpy as np
mask = np.array(PIL.Image.open('q.jpg'))
text = 'hello world python windows css html javascript'
# 设置背景为白色,单词重复,词数限制,放大长宽
wcd1 = wordcloud.WordCloud(background_color='white',mask=mask,repeat=True,max_words=100,width=800,height=600,max_font_size=100)
wcd1.generate(text)
wcd1.to_image()

使用此类脚本下载网站内容时应遵守网站的使用条款,以及相关的法律法规。
本系列文章皆做为学习使用,勿商用。
第 9章 数据分析案例:Python 岗位行情的更多相关文章
- 向大家介绍我的新书:《基于股票大数据分析的Python入门实战》
我在公司里做了一段时间Python数据分析和机器学习的工作后,就尝试着写一本Python数据分析方面的书.正好去年有段时间股票题材比较火,就在清华出版社夏老师指导下构思了这本书.在这段特殊时期内,夏老 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的精彩插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
- [转帖]Speed-BI数据分析案例:2016年8月汽车销量排行榜
[转帖]Speed-BI数据分析案例:2016年8月汽车销量排行榜 据中国汽车工业协会统计分析,2016年8月,乘用车市场表现较好,当月销量环比和同比均呈较快增长.1-8月,乘用车销量总体呈稳定增长, ...
- Python爬虫——Python 岗位分析报告
前两篇我们分别爬取了糗事百科和妹子图网站,学习了 Requests, Beautiful Soup 的基本使用.不过前两篇都是从静态 HTML 页面中来筛选出我们需要的信息.这一篇我们来学习下如何来获 ...
- 小白年薪26万,为什么Python岗位薪资越来越高?
人工智能和大数据概念的兴起,带动了Python的快速增长——Python语言逻辑简洁.入门简单.生态丰富,几乎成为几个新兴领域的不二选择.而除了这两个领域,Python还有更多的适用领域:爬虫.web ...
- javascript进阶教程第二章对象案例实战
javascript进阶教程第二章对象案例实战 一.学习任务 通过几个案例练习回顾学过的知识 通过案例练习补充几个之前没有见到或者虽然讲过单是讲的不仔细的知识点. 二.具体实例 温馨提示 面向对象的知 ...
- python 教程 第二十一章、 扩展Python
第二十一章. 扩展Python /* D:\Python27\Lib\Extest-1.0\Extest2.c */ #include <stdio.h> #include <std ...
- matlab第六章数据分析与多项式计算
MATLAB练习 第六章数据分析与多项式计算 1.max和min 1.分别求矩阵A中各列和各行元素中的最大值.max和min的用法一样 % [例6.1]分别求矩阵中各列和各行元素中的最大值. A=[5 ...
- (转载)一篇文章详解python的字符编码问题
一篇文章详解python的字符编码问题 一:什么是编码 将明文转换为计算机可以识别的编码文本称为"编码".反之从计算机可识别的编码文本转回为明文为"解码". ...
- 【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
一.爬取老番茄B站数据 前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含: 视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕 ...
随机推荐
- k8s标签的增删改查和选择器
在 Kubernetes(K8s)中,标签(Label)是与资源对象相关联的键值对,用于实现多维度的资源分组管理功能.下面是关于 Kubernetes 标签的增删改查操作的简要说明: 查询标签 (查) ...
- 基于ads1299生物电信号采集研发总结之参考信号的接法
一 概念 ads1299的电极端有两种采集方式,单端和差分.两种的使用方式又有很大的区别,怎么高质量的采集信号,这个是一个比较难的问题. 二 解析 参考信号SRB1的接法,决定了采集到数据的精确度和信 ...
- 基于ads1299的可穿戴脑电信号采集之性能调试总结
一 前言 问题背景: 最近做项目,遇到了一个问题,就是采集的信号有噪声,在这里做了很多尝试. 二 测试步骤 A 内部方波信号质量,通过测试发现内部方波信号质量特别好.这个说明了软件和存储这块,没啥 ...
- IDEA/Android Studio的gradle控制台输出中文乱码问题解决
原文地址: IDEA/Android Studio的gradle控制台输出中文乱码问题解决 - Stars-One的杂货小窝 在项目中,有使用到Gradle自定义脚本,会有些输出日志,但是输出中文就变 ...
- Spring Boot命令指定环境启动jar包
原文地址:Spring Boot命令指定环境启动jar包 - Stars-One的杂货小窝 记下通过命令行的方式去改变spring boot项目中的环境配置信息 命令 项目中有以下配置 applica ...
- [Linux] 使用du命令查看文件夹空间使用情况
一.摘要 本文介绍了在linux下使用du命令查看文件夹所占空间大小的命令,包括查看当磁盘中所有文件占空间大小.前目录的所占空间大小.当前目录下一级子目录各自所占空间大小等等操作. 二.du命令示例 ...
- NJUPT第二次积分赛小结与视觉部分开源
NJUPT第二次积分赛小结与视觉部分开源 跟队友连肝一周多积分赛,写了一堆屎山,总算是今天完赛了.结果也还行,80分到手.其实题目是全做完了的,但验收时我nt了没操作好导致丢了不少分,而且整个控制流程 ...
- Java面试题【1】
Java面试题总结 2022-05-20 1)Java有没有goto? goto是C语言中的,通常与条件语句配合使用,可用来实现条件转移, 构成循环,跳出循环体等功能.Java保留了这个关键字但是没有 ...
- ET介绍——数值组件设计
类似魔兽世界,moba这种技能极其复杂,灵活性要求极高的技能系统,必须需要一套及其灵活的数值结构来搭配.数值结构设计好了,实现技能系统就会非常简单,否则就是一场灾难.比如魔兽世界,一个人物的数值属性非 ...
- 前端问题整理 Vite+Vue3+Ts 创建项目及配置 持续更新
前端问题整理 持续更新 目录 前端问题整理 持续更新 前端 Vue 篇 @项目配置 1.node 版本过高问题 安装nvm 管理node版本 2.镜像证书无效问题 3.npm 版本问题 4.npm i ...