AI/机器学习(计算机视觉/NLP)方向面试复习1
1. 判断满二叉树
所有节点的度要么为0,要么为2,且所有的叶子节点都在最后一层。
#include <iostream>
using namespace std;
class TreeNode {
public:
int val;
TreeNode* left;
TreeNode* right;
//创建的时候输入参数x,会把x给val,nullptr给left和right
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {};
TreeNode(int x, TreeNode* l, TreeNode* r) : val(x), left(l), right(r) {};
};
bool isfull(TreeNode* cur) {
if (cur == nullptr) return true;
if (cur->left == nullptr && cur->right != nullptr || cur->left != nullptr && cur->right == nullptr) return false;
if (cur->left != nullptr) {
isfull(cur->left);
isfull(cur->right);
}
else {
return true;
}
}
int main() {
int x = 1;
TreeNode* left = new TreeNode(1);
TreeNode* right = new TreeNode(1);
TreeNode* root = new TreeNode(1, left, nullptr);
cout << isfull(root) << endl;
}
重点在于创建一个TreeNode类,并且写出构造函数,调用构造函数创建节点。
2. 给定一个数,求该数的平方根,不用内置函数
二分法求解。递归。
float n;
float e = 0.001;
float findsquare(float left, float right) {
float mid = (left + right) / 2;
if (mid * mid - n >= 0 && mid * mid - n < e || mid * mid - n <= 0 && mid * mid - n >= -e) {
return mid;
}
else {
if (mid * mid > n) {
findsquare(left, mid);
}
else {
findsquare(mid, right);
}
}
}
int main() {
cin >> n;
cout<< findsquare(0, n)<<endl;
}
3. GAN model 内容
图像生成模型。图像生成模型比较了解的两种是GAN和diffusion。
GAN的基本流程:生成器可以用任何输出二维图片的网络,例如DNN或者CNN。
Discriminator一般输入为图片,输出为real或者fake。
每一轮,将reference输入到discriminator里判别为real,Generator输出的输入到discriminator里判别为假。
Generator的损失函数和Discriminator的损失函数都是二元交叉熵,也就是评估真实数据的概率,Generator的目标是最大化二元交叉熵,也就是让假结果都为正,而Discriminator是最小化二元交叉熵,让假结果都为假。
4. Diffusion model 内容
首先是数学知识:
条件概率公式
基于马尔科夫假设:当前概率仅与上一刻概率有关,与其他时刻无关。可以把条件概率其他项约掉。
高斯分布的KL散度公式:
参数重整化:整理出z作为网络输入,其他两个作为网络参数,可求梯度的。
多元VAE目标函数,都是根据x推理出z,用z预测x。多元VAE的z有多个。
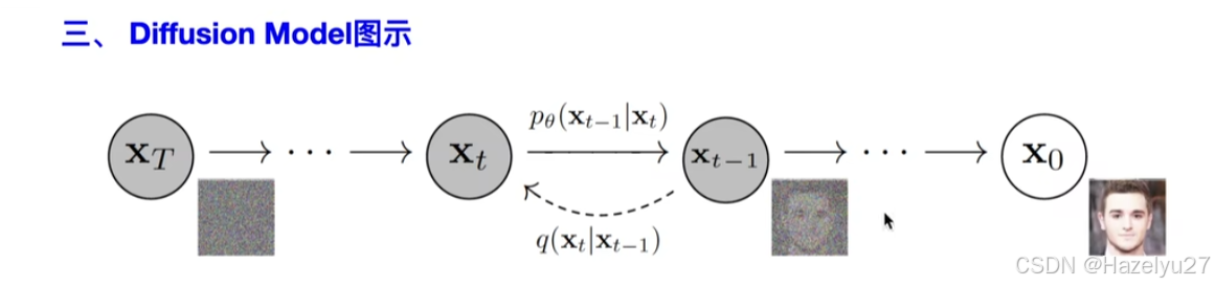
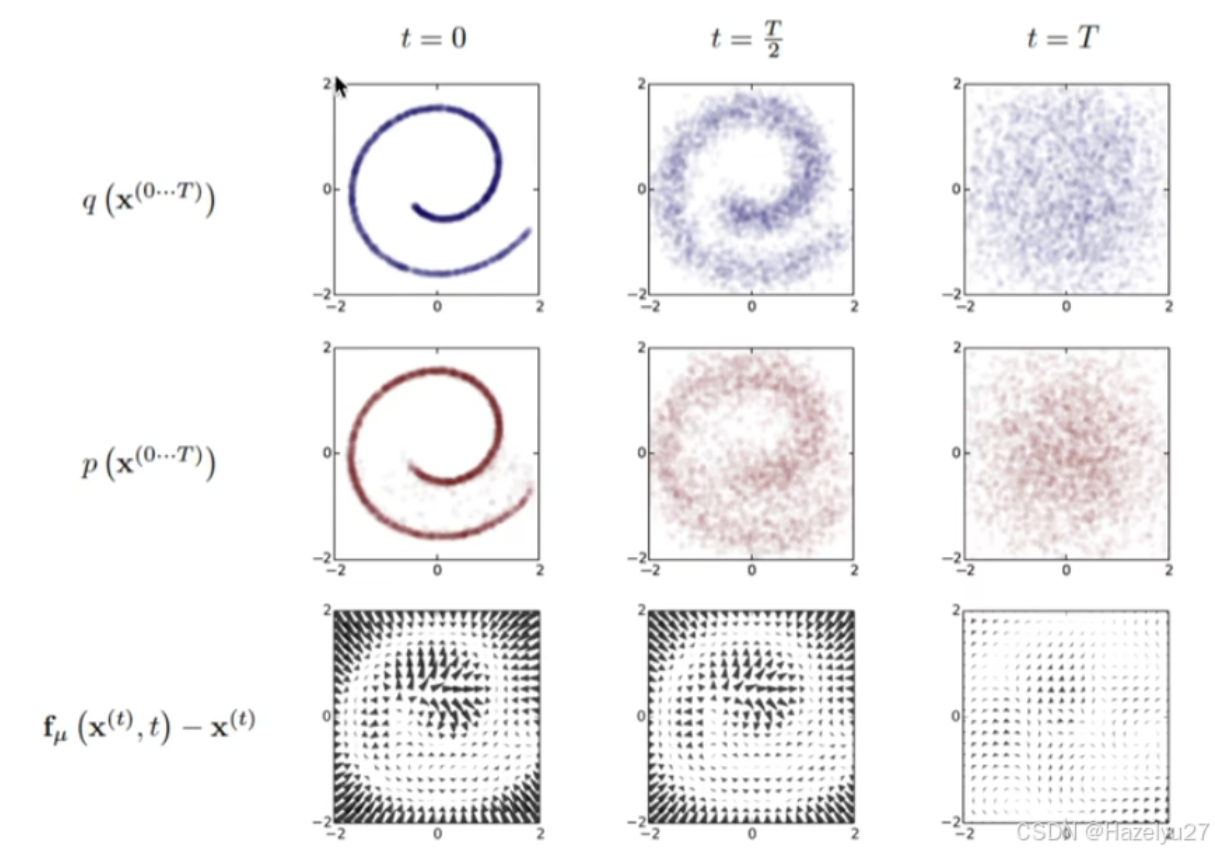
Diffusion Model 主要是两个过程,先从目标分布中扩散,得到噪声分布,是熵增的过程;
然后是从噪声分布中预测出目标分布。训练过程就是训练好这个x,这样就能在随机生成(例如高斯分布 )的噪声中获得想要的目标分布。
扩散过程是p,逆扩散过程是q。漂移量是两者之间的差。
5. 二叉树的创建,插入和删除
这里应该是搜索二叉树,左节点小于自己,右节点大于自己。
删除先不写了不会
#include<iostream>
using namespace std;
class TreeNode {
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) :val(x), left(nullptr), right(nullptr) {};
TreeNode(int x, TreeNode* l, TreeNode* r) : val(x), left(l), right(r) {};
};
TreeNode* insert(TreeNode* cur, int x) {
if (cur == nullptr) {
return new TreeNode(x);
}
if (x < cur->val) {
cur->left = insert(cur->left, x);
}
else if (x > cur->val) {
cur->right = insert(cur->right, x);
}
return cur;
}
//有点复杂,先不写了
TreeNode* deleteNode(TreeNode* cur, int val) {
if (cur == nullptr) {
return cur;
}
}
int main() {
int x = 1;
TreeNode* root = new TreeNode(x);
insert(root, 2);
}
6. Linux相关命令:
top 查看进程信息
df -h 查看硬盘使用情况
ps aux 查看所有进程
kill -9 pid 杀死编号为pid的进程
chmod 修改权限
grep 从文件名中找到包含某个字符串的数据
wc -l 统计行数
cut 分割一行内容
echo $PATH | cut -d ':' -f 3,5:输出PATH用:分割后第3、5列数据
find -name 查找文件
vim 浏览
head -3 显示前三行内容
docker:
docker ps -a 查看容器
docker attach 恢复容器
docker exec 挂起容器
docker run 跑容器
vim :n 到第n行 dd 删除当前行 :q!直接退出 :wq保存退出 gg=G格式化
ssh 登录服务器 scp -r传文件
7. 快速排序
#include <bits/stdc++.h>
using namespace std;
const int N = 100001;
void quicksort(int * arr, int l, int r){
if(l >= r) return;
int i = l-1, j = r+1;
int mid = (l+r) / 2;
int x = arr[mid];
while(i<j){
do i++; while(arr[i] < x) ;
do j--; while(arr[j] > x) ;
if(i<j) swap(arr[i],arr[j]);
}
quicksort(arr, l,j);
quicksort(arr, j+1, r);
}
int main(){
int n;
cin>>n;
int arr[N];
for(int i =0;i<n;i++){
cin>>arr[i];
}
quicksort(arr,0,n-1);
for(int i =0;i<n;i++){
cout<<arr[i]<<" ";
}cout<<endl;
}
总是会忘记的点:先do后while,i和j初始化为l-1和r+1,因为进入dowhile循环后会自增or自减。
quicksort(arr, l,j); 这里不能用i代替j,因为i是一定大于x的,j是小于等于x的。要保证左边的段是小于等于x,右边的段是大于等于x。
8. xgboost和deepfm的性能。
(1)xgboost的结构:由多个回归决策树的模型构成。每一步都加入一个新的树。(前向分布算法,用贪心的策略)逐步优化基学习器。
优化第t棵树时,前面t-1颗树的参数是确定的。每轮的目标函数是n个样本的最小损失+正则项
正则项是前t颗树的复杂度。它由叶子结点的个数和每个节点值w的平方和决定,正则项是为了防止过拟合的。叶子节点越多,越容易过拟合。节点值大,就会导致这棵树占比比较多,也容易过拟合。
在机器学习中,一般通过梯度下降法优化参数。但是树模型是阶跃的,不连续的函数求不了梯度。所以xgboost是对每个叶节点求loss。 每个叶结点的loss可以用梯度来算,分别用了一阶导数和二阶导数也就是Hessian矩阵来找最优的分割点。
(2)xgboost如何用在推荐系统上?
将用户的上下文信息作为特征输入到xgboost中,预测用户的点击概率。所以xgboost是做回归的,放入到里面后
因为是回归任务,所以每轮迭代是选择叶节点的分裂点,然后根据分裂点得到一个值,这个值就是点击概率。多个数就是加权求平均。树的节点个数这些都是超参数。
(3)xgboost如何并行的?
并行时,在最优分裂点时用并行运算加快效率。它对特征进行分块,并行计算每个特征的增益,通过增益找到最佳分割点。再同步结果,选择最大的特征进行分割。
xgboost相对于梯度提升树(GBDT)有啥提升?
引入了二阶导数(Hessian),这在优化过程中比传统GBDT(只使用一阶导数信息)更为准确。
(4)Deepfm算法:
deep factorization machines 因子分解机。它对低阶特征做特征交互,另外一个DNN神经网络,做高阶特征交互。一般输出是两者的加权和。
因子分解机(FM)是什么?
FM是SVM的拓展,更适合用于处理稀疏特征。主要考虑到多维特征之间的交叉关系(就像SVM的核函数,用内积,但是却是用因子分解参数化的方式,而SVM中用的是稠密参数化的方式,这使得FM相比SVM的参数少了很多,更加容易计算)。其中参数的训练使用的矩阵分解的方法。
例如对于电影评分中的数据,用onehot向量建模,一个特征是非常稀疏的,非常长。因子分解机就是一种改进的二阶多项式模型,考虑到两个向量之间的相似性,例如喜欢这个类型电影的对另一个类型电影的喜欢。(推荐系统之FM(因子分解机)模型原理以及代码实践 - 简书)
本质上是用deepfm给召回阶段的候选集合排序。所以做的仅仅只是排序,不是召回。Loss用的是adam。
(5)为什么在大规模数据集上使用deepfm?
在处理用户行为数据和隐式反馈数据时,DeepFM通过其深度部分能够捕捉到复杂的非线性关系,表现较好。在大规模推荐系统中,如广告推荐、商品推荐等,DeepFM具有优势。
适合大规模数据和自动特征学习的场景,尤其在处理高维稀疏特征时表现出色。但需要大量数据和计算资源才能充分发挥其优势。
9. 判断链表里是否有环
可以用哈希法或者快慢指针法。快慢指针要注意:判断fast的next。不然会出界,并且初始化两个指针不能相同,不然当只有一个数据时返回就不对了。
bool hasCycle(ListNode *head) {
if (head == nullptr) return false;
ListNode* slow = head;
ListNode* fast = head->next;
while(slow != fast){
if(fast == nullptr || fast->next == nullptr) return false;
slow = slow->next;
fast = fast->next->next;
}
return true;
}
哈希表法:注意插入是insert
bool hasCycle(ListNode *head) {
unordered_set<ListNode*> sets;
ListNode * cur = head;
while(cur!=nullptr){
if(sets.count(cur)) return true;
sets.insert(cur);
cur = cur->next;
}
return false;
}
10. HDFS相关基础知识
对hadoop了解的不多,主要是使用了一些hadoop的命令进行数据读取。
HDFS是hadoop distribution file system。HDFS的文件分布在服务器集群上,提供副本和容错率保证。
适用于存储特别大的文件,采用流式数据进行访问。但不适合毫秒级别的访问,是有点延时的。
我是使用了一些命令行的命令,例如:
hadoop fs -copyFromLocal // copy file
hadoop fs mkdir
hadoop fs -ls
AI/机器学习(计算机视觉/NLP)方向面试复习1的更多相关文章
- 干货 | 请收下这份2018学习清单:150个最好的机器学习,NLP和Python教程
机器学习的发展可以追溯到1959年,有着丰富的历史.这个领域也正在以前所未有的速度进化.在之前的一篇文章中,我们讨论过为什么通用人工智能领域即将要爆发.有兴趣入坑ML的小伙伴不要拖延了,时不我待! 在 ...
- 机器学习、NLP、Python和Math最好的150余个教程(建议收藏)
编辑 | MingMing 尽管机器学习的历史可以追溯到1959年,但目前,这个领域正以前所未有的速度发展.最近,我一直在网上寻找关于机器学习和NLP各方面的好资源,为了帮助到和我有相同需求的人,我整 ...
- linux常用命令大全(linux基础命令入门到精通+命令备忘录+面试复习+实例)
作者:蓝藻(罗蓝国度) 创建时间:2018.7.3 编辑时间:2019.4.29 前言 本文特点 授之以渔:了解命令学习方法.用途:不再死记硬背,拒绝漫无目的: 准确无误:所有命令执行通过(环境为ce ...
- [转帖]linux常用命令大全(linux基础命令入门到精通+实例讲解+持续更新+命令备忘录+面试复习)
linux常用命令大全(linux基础命令入门到精通+实例讲解+持续更新+命令备忘录+面试复习) https://www.cnblogs.com/caozy/p/9261224.html 总结的挺好的 ...
- 超过 150 个最佳机器学习,NLP 和 Python教程
超过 150 个最佳机器学习,NLP 和 Python教程 微信号 & QQ:862251340微信公众号:coderpai简书地址:http://www.jianshu.com/p/2be3 ...
- 从 Quora 的 187 个问题中学习机器学习和NLP
从 Quora 的 187 个问题中学习机器学习和NLP 原创 2017年12月18日 20:41:19 作者:chen_h 微信号 & QQ:862251340 微信公众号:coderpai ...
- linux常用命令大全(linux基础命令+命令备忘录+面试复习)
linux常用命令大全(linux基础命令+命令备忘录+面试复习)-----https://www.cnblogs.com/caozy/p/9261224.html
- Java秋招面试复习大纲(二):Spring全家桶+MyBatis+MongDB+微服务
前言 对于那些想面试高级 Java 岗位的同学来说,除了算法属于比较「天方夜谭」的题目外,剩下针对实际工作的题目就属于真正的本事了,热门技术的细节和难点成为了面试时主要考察的内容. 这里说「天方夜谭」 ...
- 京东AI平台 春招实习生面试--NLP(offer)
给offer了 开心.春招第一个offer!!! 2018.4.11 update 1面: 只有1面, 面试官还是个老乡.. 1.自我介绍 如何学的AI相关的知识? 2.介绍百度的实习 3.拿到一个问 ...
- 认识:人工智能AI 机器学习 ML 深度学习DL
人工智能 人工智能(Artificial Intelligence),英文缩写为AI.它是研究.开发用于模拟.延伸和扩展人的智能的理论.方法.技术及应用系统的一门新的技术科学. 人工智能是对人的意识. ...
随机推荐
- 语义分割评价指标(Dice coefficient, IoU)
语义分割任务常用的评价指标为Dice coefficient和IoU.Dice和IoU都是用来衡量两个集合之间相似性的度量,对于语义分割任务而言即用来评估网络预测的分割结果与人为标注结果之间的相似度. ...
- 拼多多面试:Netty如何解决粘包问题?
粘包和拆包问题也叫做粘包和半包问题,它是指在数据传输时,接收方未能正常读取到一条完整数据的情况(只读取了部分数据,或多读取到了另一条数据的情况)就叫做粘包或拆包问题. 从严格意义上来说,粘包问题和拆包 ...
- react this指向问题
在JSX事件函数方法中的 this,默认不会绑定 this指向.如果你忘记绑定,当你调用这个函数的时候 this 的值为 undefined.所以使用时一定要绑定好this的指向. 构造方法中绑定 c ...
- div拖拽移动事件
<style> * { margin: 0; padding: 0; } body { ...
- ftl生成模板并从前台下载
1.生成模板的工具类 package com.jesims.busfundcallnew.util; import freemarker.template.Configuration; import ...
- JsonPath - 根据表达式路径解析Json
JsonPath 在xml的使用过程中,对于xml的解析我们知道可以使用xpath的方式,随意的获取到我们想要的属性值.那么在使用json时,我们能不能实现同样的操作呢? 答案就是 json-path ...
- 面试官:为什么重写equals方法必须要重新hashCode方法?
网络上解释的很全面但是很枯涩,也有些难懂,其实就是为了保证当该对象作为key时哈希表的检索效率.如HashMap的get方法是分两步获取的 第一步通过key的哈希值找到对应的哈希桶 第二步通过equa ...
- AnnotationTransactionAttributeSource is only available on Java 1.5 and higher和windows同时安装jdk7和jdk8
AnnotationTransactionAttributeSource is only available on Java 1.5 and higher和windows同时安装jdk7和jdk8 出 ...
- Windows10(or windows11) Hyper-V 创建虚拟交换机后宿主机上传速度变特别慢的问题解决
问题 我在我的win11上启用了Hyper-v,装了个虚拟机跑了个CentOS7.6,为了让centos和宿主机通信在同个网段搞了个桥接网络,网络环境如下 然后我测试一个文件上传功能的时候发现网络上传 ...
- spring数据验证
一般情况下,我们并不推荐在服务端做基础的数据校验,因为这有一个很主要的问题:它加重了服务器的负载,如果并发多,这种负载就更加明显. 如果我们跟踪一个简单的Controller方法执行过程,就会发现Sp ...