10 Self-Attention(自注意力机制)
注意力机制
看一个物体的时候,我们倾向于一些重点,把我们的焦点放到更重要的信息上
第一眼看到这个图,不会说把所有的信息全部看完

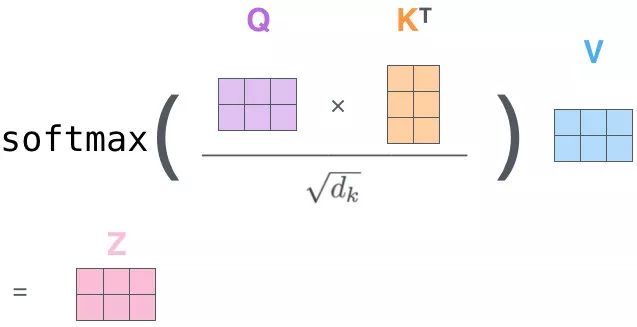
QK 相乘求相似度,做一个 scale(未来做 softmax 的时候避免出现极端情况)
然后做 Softmax 得到概率
新的向量表示了K 和 V(K==V),然后这种表示还暗含了 Q 的信息(于 Q 而言,K 里面重要的信息),也就是说,挑出了 K 里面的关键点
自-注意力机制(Self-Attention)(向量)
Self-Attention 的关键点再于,不仅仅是 K\(\approx\)V\(\approx\)Q 来源于同一个 X,这三者是同源的
通过 X 找到 X 里面的关键点
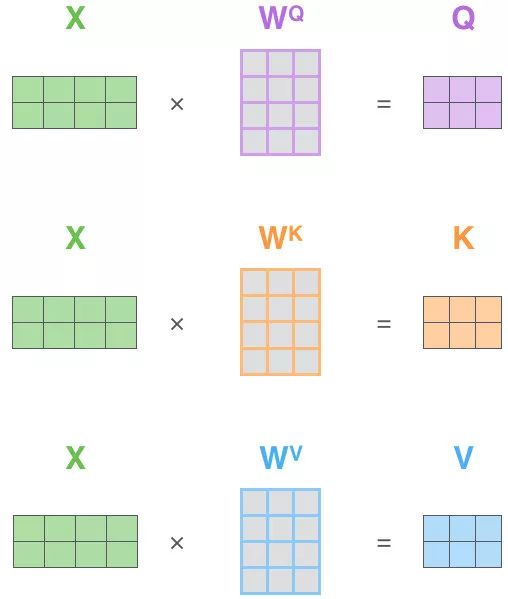
并不是 K=V=Q=X,而是通过三个参数 \(W_Q,W_K,W_V\)
接下来的步骤和注意力机制一模一样
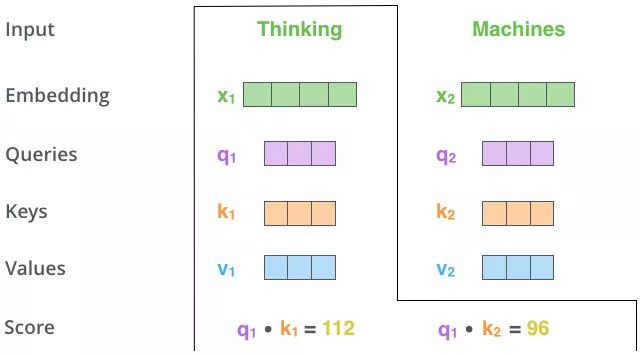
Q、K、V的获取
Matmul:
Scale+Softmax:
Matmul:



\(z_1\)表示的就是 thinking 的新的向量表示
对于 thinking,初始词向量为\(x_1\)
现在我通过 thinking machines 这句话去查询这句话里的每一个单词和 thinking 之间的相似度
新的\(z_1\)依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息
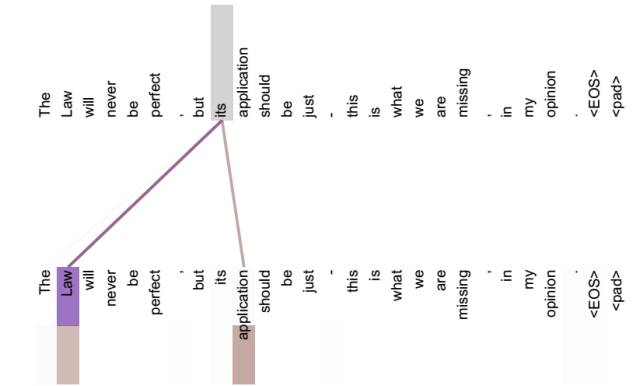
不做注意力,its 的词向量就是单纯的 its,没有任何附加信息
也就是说 its 有 law 这层意思,而通过自注意力机制得到新的 its 的词向量,则会包含一定的 laws 和 application 的信息
自注意力机制(矩阵)

10 Self-Attention(自注意力机制)的更多相关文章
- NLP之基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) @ 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 ...
- NLP之基于Bi-LSTM和注意力机制的文本情感分类
Bi-LSTM(Attention) @ 目录 Bi-LSTM(Attention) 1.理论 1.1 文本分类和预测(翻译) 1.2 注意力模型 1.2.1 Attention模型 1.2.2 Bi ...
- 基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 A ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- 注意力机制(Attention Mechanism)应用——自然语言处理(NLP)
近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了最近神经网络研究的一个热点,下面是一些基于attention机制的神经网络在 ...
- 【注意力机制】Attention Augmented Convolutional Networks
注意力机制之Attention Augmented Convolutional Networks 原始链接:https://www.yuque.com/lart/papers/aaconv 核心内容 ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- 关于注意力机制(《Attention is all you need》)
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列.(https://kexue.fm/archives/4765) 第一个思路是RNN层,递归进行,但是RNN无法很好地 ...
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
随机推荐
- 【MySQL】字符联合主键过长 Specified key was too long; max key length is 767 bytes
MySQL版本: 这个情况在 8.0.28版本没有出现 报错如图 建表SQL: DROP TABLE IF EXISTS `pt_dict_common`; CREATE TABLE `pt_dict ...
- 【MybatisPlus】 Field '主键' doesn't have a default value
使用MybatisPlus的 PoMapper执行Insert插入方法报错: 复原场景: 1.PO对象存在主键值(双主键) 2.表中数据为空 3.首次插入 这张表使用的是双主键,发现原因是因为PO设置 ...
- 【Vue】Re11 Vue 与 Webpack
一.案例环境前置准备: 创建一个空目录用于案例演示 mkdir vue-sample 初始化案例和安装webpack cd vue-sample npm install webpack@3.6.0 - ...
- jax框架的 Pallas 方式的GPU扩展不可用
说下深度学习框架的GPU扩展功能的部分,也就是使用个人定制化的GPU代码编写方式来为深度学习框架做扩展. 深度学习框架本身就是一种对GPU功能的一种封装和调用,但是由于太high-level,因此就会 ...
- 强化学习分布式经验回放框架(experience replay)reverb的安装
框架reverb的相关介绍: https://www.cnblogs.com/devilmaycry812839668/p/16260799.html ======================== ...
- vue之组件的简单使用
1.背景 2.组件的简单使用 <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- php curl访问https 域名接口一直报错的问题
这两天一直在对接一个https的接口 通过本地postman完美链接后再服务器一直报错 出现问题:linux 下 curl可以正常访问 但是PHP请求一直返回false 测试方法:var_dump(c ...
- 文件IO常用的函数接口
本文归纳整理了常用的文件IO常见的函数接口及其用法,以供读者查阅 目录 打开文件 fopen 关闭文件 fclose 数据读取 字符读取:fgetc.getc.getchar 按行读取:fgets.g ...
- Gradle 项目打开自动下载Zip问题及相关配置
原因 : 由于使用Eclipse开发,导入了SpringCloud 工程,SpringCloud 自从哪个版本忘了昂,选择了Gradle 作为工程管理工具,至于为啥,你去问问官方,我的了解是为了支持G ...
- Jenkins部署架构概述
1.Jenkins是什么 Jenkins是一个开源的.提供友好操作界面的持续集成(CI)工具,起源于Hudson,主要用于持续.自动的构建/测试软件项目.监控外部任务的运行. Jenkins用Java ...