CSR格式如何更新? GES图计算引擎HyG揭秘之数据更新
摘要:HyG图计算引擎采用CSR格式来存储图的拓扑信息,CSR格式可以将稀疏矩阵的存储空间压缩,进而大大降低图的存储开销,同时具备访问效率高、格式易转化等优点。
本文分享自华为云社区《CSR格式如何更新? GES图计算引擎HyG揭秘之数据更新》,作者: π 。
HyG图计算引擎采用CSR格式来存储图的拓扑信息,CSR格式可以将稀疏矩阵的存储空间压缩,进而大大降低图的存储开销,同时具备访问效率高、格式易转化等优点。利用CSR + 列存(parquet格式)的组合,HyG获得了很高的图访问性能。但是,对于数据需要增量更新的场景,CSR的更新非常困难,可能会导致大量的数据复制和移动,进而影响系统性能。HyG对传统CSR更新进行了一系列优化,实现了高效的数据更新。
什么是CSR格式?
CSR格式是一种常用的稀疏矩阵存储格式,它将稀疏矩阵以三个数组的形式存储。具体来说,CSR格式使用 values、column indices和row offsets三个数组来表示稀疏矩阵。
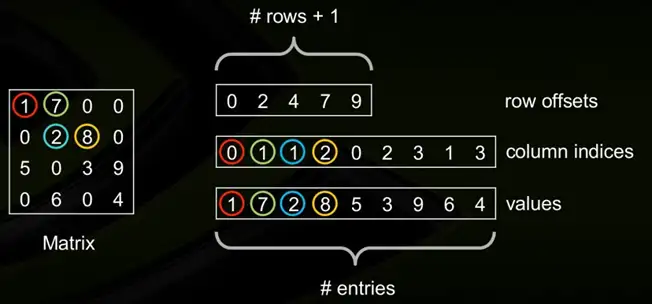
定义NNZ(Num-non-zero)为矩阵M中非0元素的个数。
第一个数组为values数组。其中,values数组的长度为NNZ,分别从左到右从上到下的非零元素的值。
第二个数组为column数组。其中,column数组的长度为NNZ,其对应于values数组中的元素的column_index(例如元素8排列在所在行的第3个位置,因此其column index为2)。
第三个数组为row offsets,其中row offsets的数组大小为m+1,其前m个元素分别代表这每一行中第一个非零元素在Values数组的下标。(例如元素2是第二行的第二个元素,其在values数组中的下标为2.)。
CSC和CSR类似,只不过和CSR行列互换。values数组里是按列存的数值,row offsets变成了col offsets,column数组变成了row数组。
CSR格式由于其紧凑的存储方式和高效的计算方式,已经成为了处理稀疏矩阵的标准格式之一。具体来说,CSR格式可以利用连续的内存块来存储非零元素,这使得计算机在处理稀疏矩阵时可以跳过大量的零元素,从而提高了计算效率。此外,CSR格式所需要的存储空间相对于其他格式,如COO格式(Coordinate)等,也更为紧凑,这在处理大型稀疏矩阵时非常有利。
如何更新CSR格式数据?
传统方案:
更新图数据需要对三个数组进行操作:values、columns和row offset。
更新
要更新矩阵中某个位置(i,j)的值,需要找到该位置在CSR格式中对应的行(第i行)在values和columns数组中的起始和结束索引。具体而言,该行的非零元素在values数组中的起始位置是row offset [i],结束位置是row offset [i+1]-1。然后,在columns数组中找到对应的列(第j列)的索引位置。
接下来,可以直接更新values数组中对应位置的值,即values[row offset[i]+k],其中k是columns数组中第j列的索引位置。
插入
如果要插入一个新的非零元素,可以按照以下步骤进行:
1、找到要插入的元素在CSR格式中对应的行(第i行)在values和columns数组中的起始和结束索引,方法同上。
2、在columns数组中找到新元素应该插入的位置,即找到插入元素后columns数组中第j列的索引位置。
3、将新元素的值插入到values数组中正确的位置,并将columns数组中对应位置以及后面的元素向后移动一个位置。
4、更新row offset数组中第i行及其后面所有行的元素起始位置,因为在第i行插入了一个新的非零元素。
删除
如果要删除一个非零元素,可以按照以下步骤进行:
1、找到要删除的元素在CSR格式中对应的行(第i行)在values和columns数组中的起始和结束索引,方法同上。
2、在columns数组中找到要删除的元素的位置。
3、从values和columns数组中删除该元素,并将后面的元素向前移动一个位置。
4、更新row offset数组中第i行及其后面所有行的元素起始位置,因为在第i行删除了一个非零元素。
需要注意的是,更新CSR格式中的元素可能会导致数组长度的变化,因此需要动态分配和释放内存空间。此外,在进行插入和删除操作时,可能需要对row offset数组中的元素进行更新,这可能会影响CSR格式的性能。
总之,CSR格式的更新操作相对复杂,需要对三个数组进行操作,并需要考虑内存分配和数组长度的变化等问题,这十分不利于实时分批式的增量更新。
HyG数据更新策略
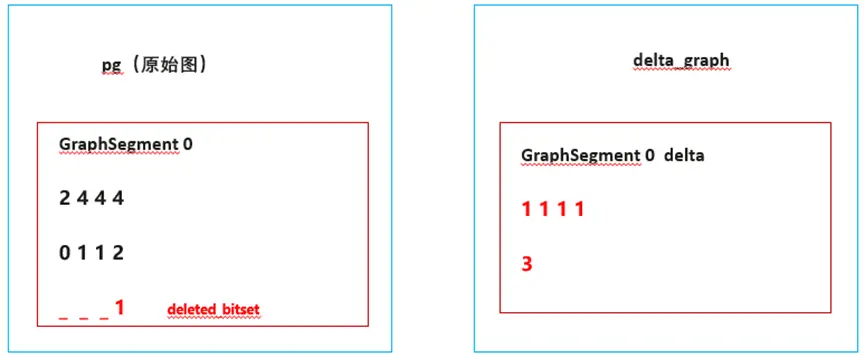
- 每次更新都会生成一个子图(delta_graph),这个子图是CSR格式,描述了增量信息。
- 引入deleted_biset数组,记录被删除的点、边信息。
- 按顺序加载 MergedPG = pg + [delta_graph]
- 对各点、边按照所属的pg/ delta_graph进行本地访问和增、删。
因为HyG考虑了分布式切分图的场景,我们将场景简化,接下来描述一下数据更新的流程。
图原始数据如下图所示,图中包含4个点,4条边,4条边上的值分别为1、7、2、8。
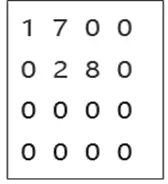
图对应的CSR格式如下图所示,这个是原始的拓扑数据。

我们对数据进行更新,基于原始图新增了边0(src)->3(dst),边的值为3。删除了边1(src)->2(dst),边的值为8。
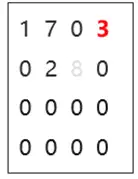
新增了1条边,边的src是0,dst是3,因此CSR的row offset为[1 1 1 1],column为[3],value为[3]。进而得到了右侧的delta graph。
删除了1条边,这条边是属于pg(原始图),所以,我们会对pg的deleted_bitset置位,因为删除是column数组的最后一个,因此,我们会将最后一个bit置为1,表示这个边已被删除。
到此,我们就完成了一次增、删操作,生成了一个新的delta graph,这个delta graph跟历史数据没有任何关系,它只表示了本次增量的数据,因此,对于超大规模的图,更新数据不再需要大量的数据拷贝和移动,只需要生成一个很小的delta graph就可以了。
图访问
经过增量更新,全量图的信息就会被分解为一个原始图和一个增量图。HyG设计了一种同时读取到两个图信息的访问迭代器(以下简称“二级迭代器”),这种迭代器会将这多个子图视为一个全量图访问,可以在不同的子图间游走。
HyG增量图迭代性能优化
HyG增量图会产生多个快照,每个快照是一个子图,对应着一次commit。算法读取增量图需要依赖HyG的二级迭代器,迭代器会在不同的快照间游走,校验点、边是否已被删除,最终返回给算法结果。因此,迭代器需要维护很多信息,远远大于pg(原始图)的轻量级迭代器,进而使增量图迭代的性能很低,快照数量越多性能下降越剧烈。
优化方案
HyG引入基于页的快照索引技术来缓解由于存在大量快照导致的性能下降问题。
为每个快照划分虚拟页,比如页的大小是4K,那么一个页对应着4K个点以及这4k点对应的边。
索引表记录了每个页最近被更新的快照,因此,如果这个页没有被更新,那么利用索引表可以直接跳过对应的快照。
索引表采用copy on write的方式更新,每生成一个新快照,会把上一个快照的全部索引信息copy一份,然后把修改信息更新到对应的索引上,得到最新快照的索引表。
同时,对于二级迭代器的构造,我们也进行了优化,尽量减少数据成员的数量,当迭代器在不同快照间切换时,去更新该快照的上下文信息,而不会维护所有快照的信息。
利用快照索引技术,我们可以快速的定位到点、边对应的最新修改的快照,进而可以跳过很多无效的访问。但是,随着快照数量的增多,图遍历的性能还是会不断下降,被删除的点、边不但浪费了大量的存储空间,还会增加无效的访问延时,因此,设计一套有效的自动化合并方案,当快照数量过多或者删除点、边过多时,触发合并,提升系统性能。如果大家感兴趣,我们后面会接着介绍HyG是如何实现快照合并的。
CSR格式如何更新? GES图计算引擎HyG揭秘之数据更新的更多相关文章
- 图计算引擎分析——Gemini
前言 Gemini 是目前 state-of-art 的分布式内存图计算引擎,由清华陈文光团队的朱晓伟博士于 2016 年发表的分布式静态数据分析引擎.Gemini 使用以计算为中心的共享内存图分布式 ...
- 图计算引擎分析--GridGraph
作者:京东科技 李永萍 GridGraph:Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Pa ...
- GraphX 图计算实践之模式匹配抽取特定子图
本文首发于 Nebula Graph Community 公众号 前言 Nebula Graph 本身提供了高性能的 OLTP 查询可以较好地实现各种实时的查询场景,同时它也提供了基于 Spark G ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 腾讯开源进入爆发期,Plato助推十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 使用开源计算引擎提升Excel格式文件处理效率
对Excel进行解析\生成\查询\计算等处理是Java下较常见的任务,但Excel的文件格式很复杂,自行编码读写太困难,有了POI\EasyExcel\JExcel等类库就方便多了,其中POI最为出色 ...
- 【Spark深入学习 -13】Spark计算引擎剖析
----本节内容------- 1.遗留问题解答 2.Spark核心概念 2.1 RDD及RDD操作 2.2 Transformation和Action 2.3 Spark程序架构 2.4 Spark ...
- MaxCompute 图计算用户手册(上)
概要 ODPS GRAPH是一套面向迭代的图计算处理框架.图计算作业使用图进行建模,图由点(Vertex)和边(Edge)组成,点和边包含权值(Value),ODPS GRAPH支持下述图编辑操作: ...
- 关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL)) 欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
随机推荐
- [数据库/Java SE]MySQL驱动包(mysql-connector-java.jar)问题[com.mysql.jdbc.Driver/org.gjt.mm.mysql.Driver/com.mysql.cj.jdbc.Driver]
MySQL的驱动JAR包----mysql-connector-java.jar,不同版本,其JBDC驱动类Driver的路径均有可能变化. 日后使用时,可根据本文的思路,有依据地进行检查(而不是随便 ...
- [Linux]CentOS7:创建OS用户+授予sudo权限
1 创建OS用户+授予sudo权限 Step1 下载安装Xshell.Xftp工具 Step2 通过Xshell,远程登陆服务器root用户 Step3 使用检查用户的命令查询当前linux环境是否存 ...
- day30:TCP&UDP:socket
目录 1.TCP协议和UDP协议 2.什么是socket? 3.socket正文 1.TCP基本语法 2.TCP循环发消息 3.UDP基本语法 4.UDP循环发消息 4.黏包 5.解决黏包问题 1.解 ...
- PHP读取XML文件的三种方式
一 用 simplexml_load_file 读取xml文件 <?php $xml_array=simplexml_load_file('person.xml'); //将XML中的数据, ...
- 信息论之从熵、惊奇到交叉熵、KL散度和互信息
一.熵(PRML) 考虑将A地观测的一个随机变量x,编码后传输到B地. 这个随机变量有8种可能的状态,每个状态都是等可能的.为了把x的值传给接收者,需要传输⼀个3⽐特的消息.注意,这个变量的熵由下式给 ...
- .NET快速开发框架-RDIFramework.NET 全新EasyUI版发布
RDIFramework.NET,基于.NET的快速信息化系统快速开发框架.10年专注.易上手.多组件.全源码.可灵活构建各类型系统. 1.RDIFramework.NET快速开发框架简介 RDIFr ...
- 关于Java中值传递和址传递
参数传递在Java中有两种类型 值和址 其实本质都是一份拷贝 在调用函数的时候 进行压栈 传进来的参数会被开辟一份新的空间 传基本类型是把值传过去 传引用数据类型是实例指向实参 void m(int ...
- Longformer详解——从Self-Attention说开去
1.Longformer的应用场景 为了理解Longformer的原理,我们最好首先从为何需要使用Longformer开始说起.(这里默认各位已经对Self Attention等基础知识有一定的了解) ...
- java处理集合工具
public static <K, V> Map<K, V> parseListToMap(Collection<V> list, Function<V, K ...
- linux高级编程之线程间的通信(pthread_cleanup_push和pthread_cleanup_pop)
linux高级编程之线程间的通信(pthread_cleanup_push和pthread_cleanup_pop) 线程可以安排他退出时需要调用的函数,这与进程可以用atexit函数安排进程退出时需 ...