NEMU PA 3-3 实验报告
一、实验目的
在上一章PA3-2中,我们实现了分段机制,将48位的虚拟地址vaddr转换成了laddr。为什么不是paddr呢?这就要说到这一章要完成的东西:**分页机制 **。
从80386开始,计算机又提供了一种全新的存储管理方式,那就是分页机制。在分页机制下,每一个进程都拥有独立的存储空间。同时,每一个进程独立的存储空间又具有相同的地址划分方式。此时,线性地址就需要通过进一步的转换,才能获得最终要访问的物理地址。PA3-3中我们将要实现对NEMU分页机制的模拟。
二、实验任务与步骤
老规矩,我们先来看为啥需要分页机制。分段机制的意义在于把混乱的内存管理划分出层次,把代码、数据、堆栈都划分好。到这里感觉对内存的管理已经很完善了——但实际上这还不够。主存太小了!当有多个进程需要运行的时候就显得十分吃力。
我们现在运行NEMU时,要运行在上面的“软件”就只有两个:kernel和一个testcase。我们知道Kernel占多少字节,通过修改testcase/Makefile设置-Ttext为0x100000来避免内存区域的冲突。但如果同时存在多个testcase要同时运行,且装载顺序在运行时动态确定,就没办法在编译时就确定各个进程内存起始地址,管理起来非常麻烦。到这里,我们可以总结分段机制现在面临的问题:
- 物理内存大小的限制
- 多进程并行
所以我们引入分页机制。我们来看看分页、Cache都有的一个逻辑如下:
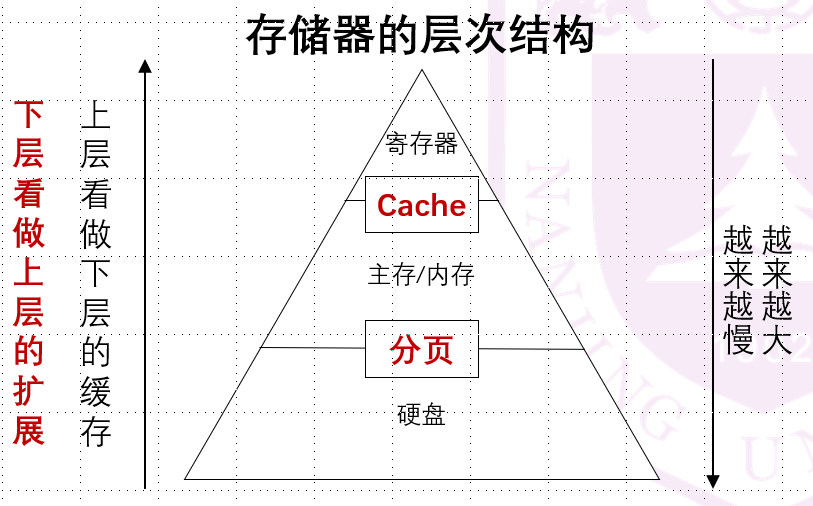
要解决上面的两个问题,我们需要解决几个要点:
- 寻址空间无法突破物理内存空间的限制?
- 上层和下层存储器按照同样的大小划分成一个个“单元”
- 解决上下层存储器“单元”之间的映射问题
- 多个进程并行运行,同时占用内存时如何分配?
- 各个进程在运行前不需要关心运行时的内存分配情况
- 各个进程运行时所占用的物理内存“单元”不要起冲突(除非指明要共享)
要点解释完了,我们来看看是具体流程:
首先,内存不是不足嘛,我们就想象每个进程的4GB空间在运行时都存储在硬盘上,硬盘够大了吧!
实际上我们并没有这样做(硬盘的读写太慢太慢)。我们要引入一个“虚拟地址空间”的概念:假想每一个进程都有4GB的空间,即每一个进程都以为自己是独享内存的。这样的话,程序员无需考虑运行时内存的分配情况,只需针对虚拟地址空间进行编译就可以了。
然后,对于一个个虚拟地址空间,我们要做的就是建立其虚拟地址空间和物理地址空间的映射:
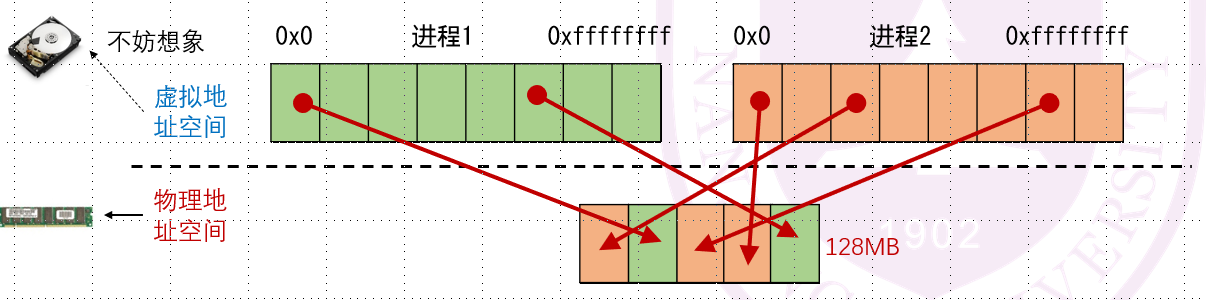
到了这一步,你可能会想:哎呀这一片那一片这不全乱套啦!这么多进程的页混杂在一起...没关系,我们如果访问到缺失的页,这时候再拿进来就行了:
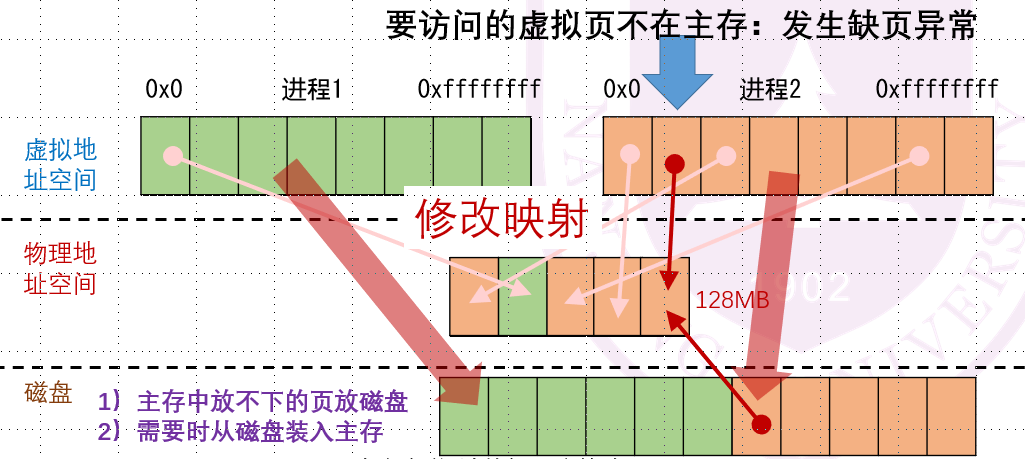
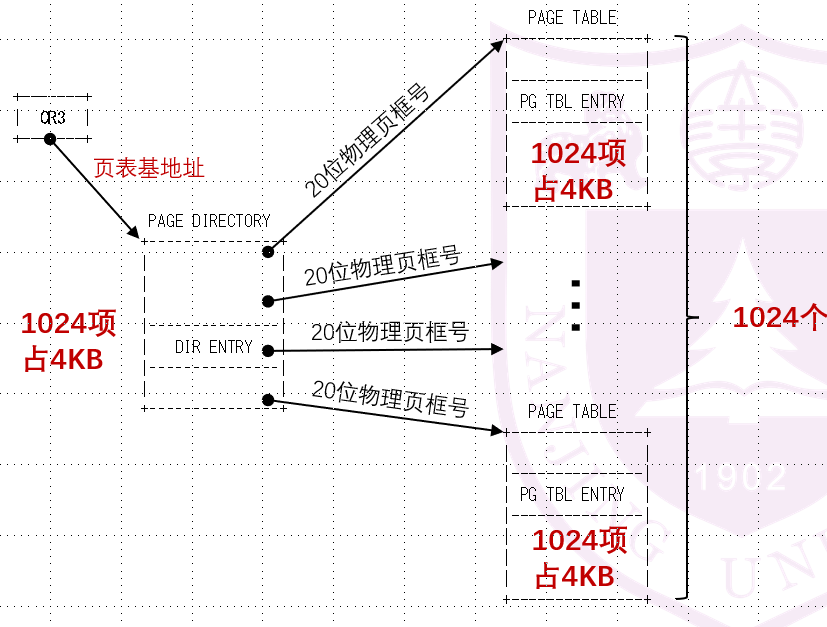
我们的操作系统维护各个进程的虚拟页和物理页之间的映射关系,每个进程都有一个它自己的页表:
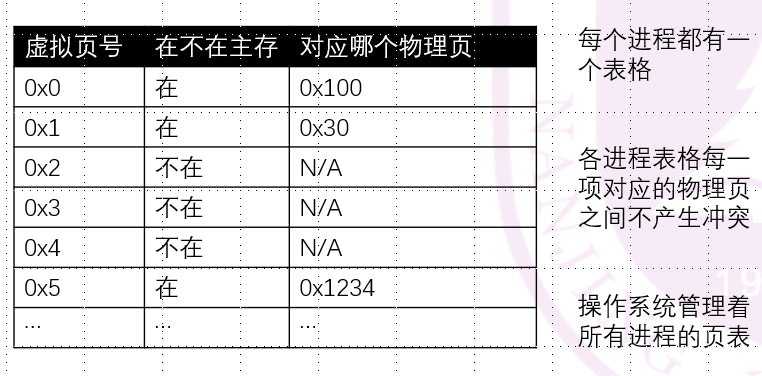
页表项的结构如下,页表在内存中存储为一个页表项的数组。
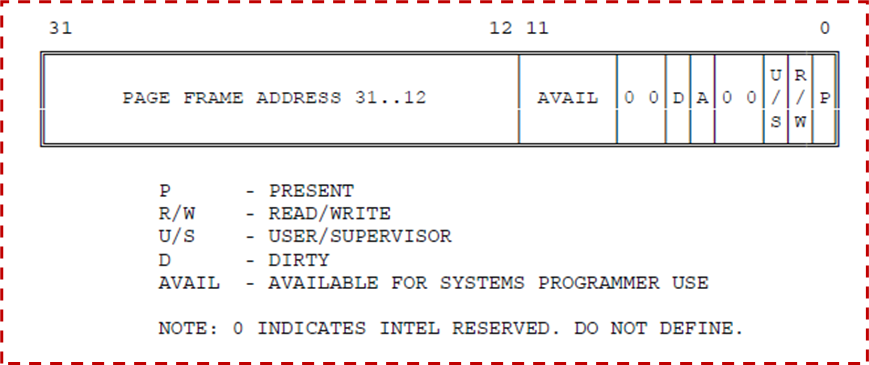
我们约定一个页为4KB = 212B,即32位线性地址中,前20bit是页索引,侯12bit是页内地址。那么我们足足有220个页表项!一个页表达到了4MB!在内存中遍历连续的4MB的数组空间很难,所以我们把它又划成了二级页表。简单说就是前面的20位页号被拆成了两个10位,前10bit是页目录索引,后10bit是页索引。
那么现在我们要做的地址转换操作如下:
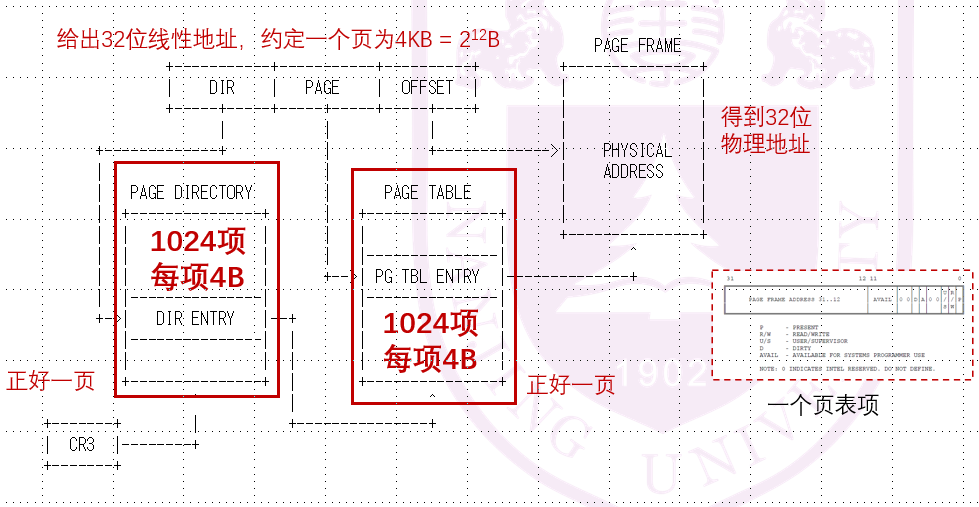
好,具体流程我们也搞懂了,现在来看看NEMU是如何具体实现的:
在
include/config.h头文件中定义宏IA32_PAGE并make clean;修改kernel和testcase中
Makefile的链接选项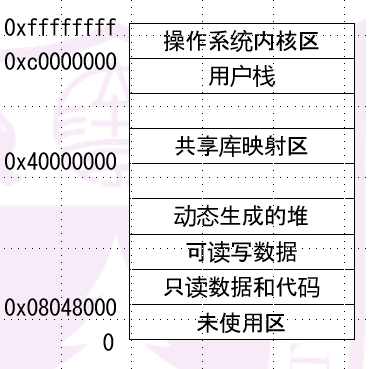
修改
kernel/Makefile中的链接选项:
这里给出我自己的理解:
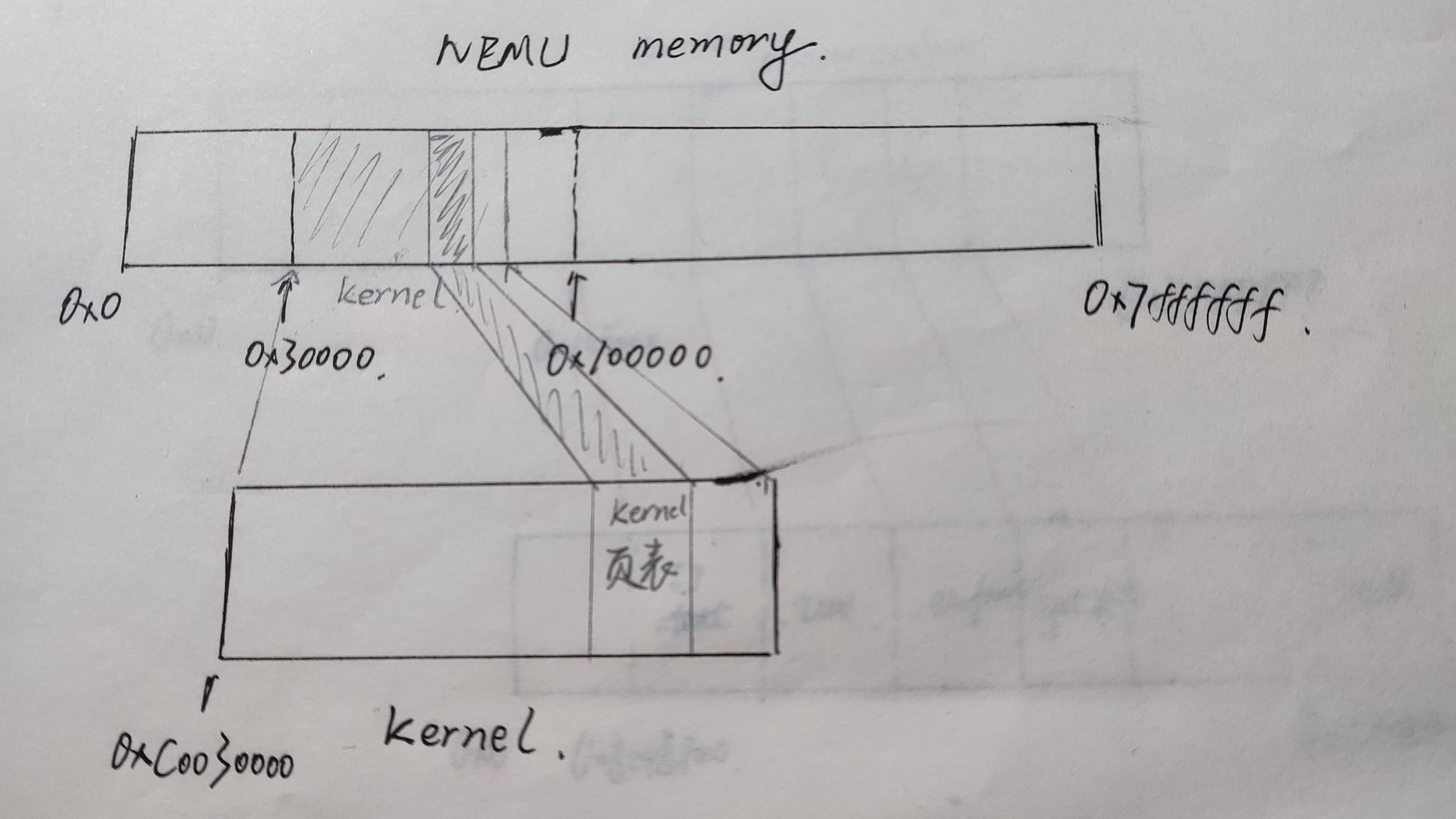
我们知道,kernel.img文件是依靠我们实际机器来转载到NEMU的内存中的。它的物理上的被装载位置还是处于hw_mem+0x30000的位置,但是,它的文件内容却因为链接选项的改变而改变了:
原本kernel代码的起始指令地址是0x30000,现在是0xc0030000。
kernel的指令从0xc0030000一路向下,0xc0030001,0xc0030002……
而kernel被我们实际机器装载进去NEMU的内存后,kernel的执行就靠NEMU的环境了。0xc0030000开始的指令取指、存取操作数都需要用到你自己实现的访存函数,它会经过分段机制转换成线性地址,再通过分页机制转成物理地址。
而
#define va_to_pa(x) (x - KOFFSET)这个宏的意义在于:我们知道kernel的指令段的地址是从0xc0030000开始(虽然装载在NEMU的0x30000),但我们要装载GDT的首地址到GDTR的话,虽然
gdtdesc在NEMU的位置实际上是处于hw_mem + 0x30000后面某处的,但根据链接给它排的序,它字面上是在0xc0030000的后面!如果我们直接就把gdtdesc的地址用lgdt装进GDTR,那么GDTR的值就变成一个大于0xc0030000的值。所以我们用这个宏耍一点小手段,把GDTR的值变成和实际上的地址相符,即处于hw_mem + 0x30000后面某处。(init_page()前没有kernel页表)修改
testcase/Makefile中的链接选项:
这个举动的意义在于让你的testcase的ELF格式更加符合Linux规定(即原版),就像上图。在NEMU环境下kernel对其装载还是用你实现的mov,但现在mov的访存已经有了分页操作,没改之前是直接根据程序头表的0x100000装载到0x100000,现在即使是从0x80488000开始,也能通过有了分页机制的访存函数来将它转换成正确的属于NEMU内存的装载地址中去。
在NEMU中添加分页相关器件支持
- 添加
CR3寄存器,实现对页表基地址(物理页框号)的存储 - 添加
CR0的PG位,实现开启/关闭分页机制
- 添加
实现从线性地址到物理地址的转换,修改
laddr_read()和laddr_write(),适时调用page_translate()函数进行地址翻译(page_translate()定义在nemu/src/memory/mmu/page.c);修改Kernel的
loader(),使用mm_malloc来完成对用户进程空间的分配;为了减轻大家的负担, 我们已经为大家准备了一个内存分配的接口函数
mm_malloc()其函数原型为:uint32_t mm_malloc(uint32_t va, int len);
它的功能是为用户进程分配一段以虚拟地址
va开始,长度为len的连续的物理内存区间,并填写为用户进程准备的页目录和页表,然后返回这一段物理内存区间的首地址。由于mm_malloc()的实现和操作系统实验有关,我们没有提供mm_malloc()函数的源代码,而是提供了相应的目标文件mm_malloc.o,Makefile中已经设置好相应的链接命令了, 你可以在loader()函数中直接调用它, 完成上述内存分配的功能。通过
make test_pa-3-3执行并通过各测试用例。
自己的一点小记:
首先,kernel的代码,用户程序是直接执行不了的。
其次,kernel的代码取指啥的会调用自己写的读写函数,会经过分页机制转换,页是取kernel页表。
还有,kernel页表在init_page()建立前,需要用到那个耍赖的宏定义,直接减去koffset。
三、思考题
1.Kernel的虚拟页和物理页的映射关系是什么?请画图说明;
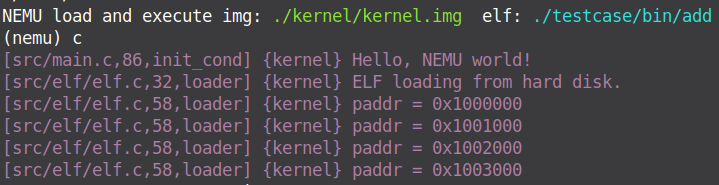
2.以某一个测试用例为例,画图说明用户进程的虚拟页和物理页间映射关系又是怎样的?Kernel映射为哪一段?你可以在loader()中通过Log()输出mm_malloc的结果来查看映射关系,并结合init_mm()中的代码绘出内核映射关系。


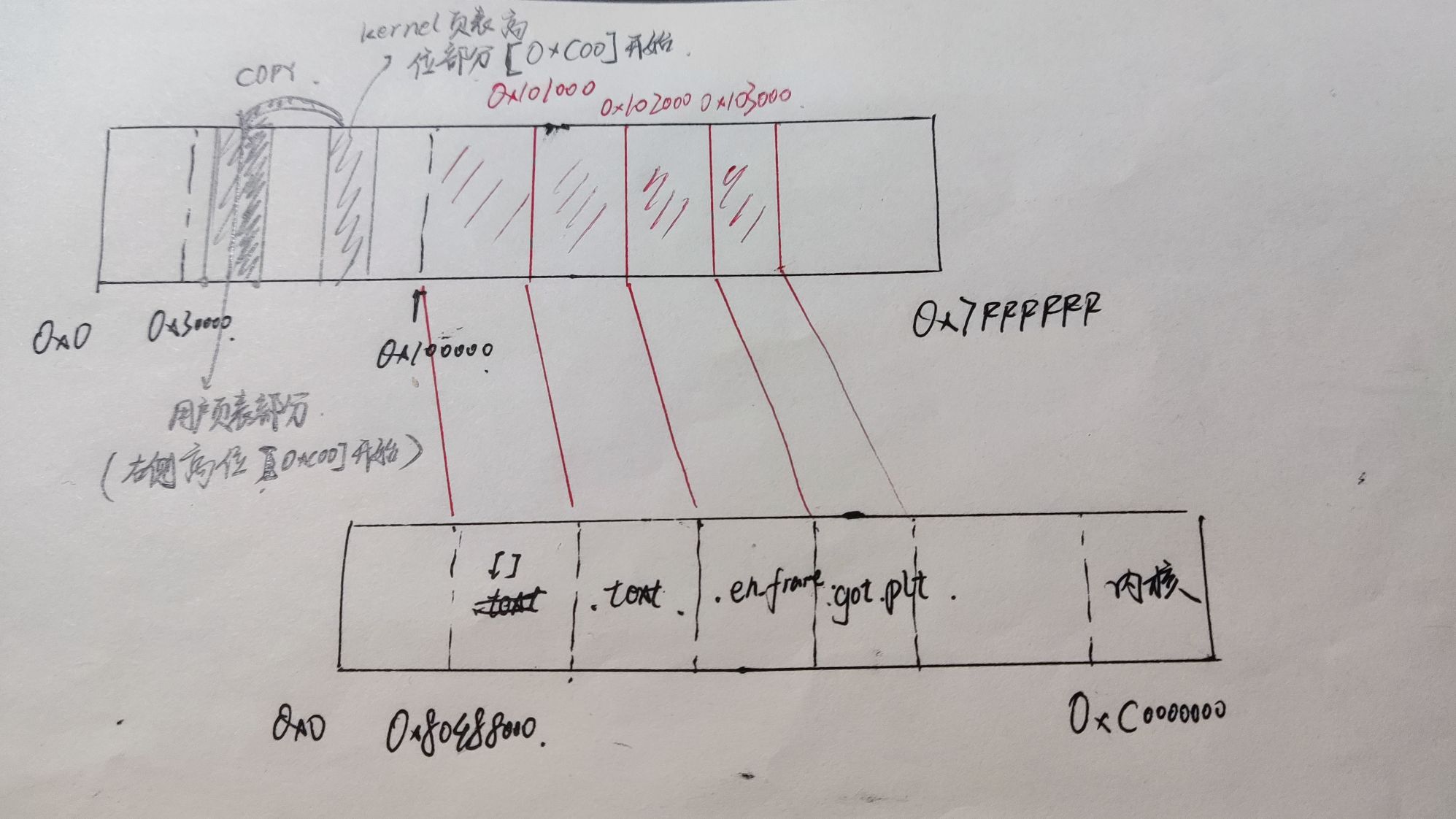
3.“在Kernel完成页表初始化前,程序无法访问全局变量”这一表述是否正确?在init_page()里面我们对全局变量进行了怎样的处理?
这句话是错误的。如果PE位和PG位没有开启,那么就是没有进入保护模式,kernel是可以直接通过逻辑地址访问全局变量。
我们在init_page()中对全局变量的处理是使用了align_to_page进行对齐。

NEMU PA 3-3 实验报告的更多相关文章
- ucoreOS_lab3 实验报告
所有的实验报告将会在 Github 同步更新,更多内容请移步至Github:https://github.com/AngelKitty/review_the_national_post-graduat ...
- ucoreOS_lab2 实验报告
所有的实验报告将会在 Github 同步更新,更多内容请移步至Github:https://github.com/AngelKitty/review_the_national_post-graduat ...
- JAVA实验报告及第七周总结
JAVA第六周作业 实验报告五 第一题 1.设计一个类层次,定义一个抽象类--形状,其中包括有求形状的面积的抽象方法. 继承该抽象类定义三角型.矩形.圆. 分别创建一个三角形.矩形.圆存对象,将各类图 ...
- 第五次java实验报告
Java实验报告 班级 计科二班 学号 20188437 姓名 何磊 完成时间2019/10/10 评分等级 实验四 类的继承 实验目的 理解抽象类与接口的使用: 了解包的作用,掌握包的设计方法. 实 ...
- 第七周总结&第五次实验报告
学习总结 这周我们加深了对抽象类与接口的学习,获得的知识点也比上周多了许多,抽象类与接口很相似,就比如别人还没有做完的是交给你来做,而他那些样式都做好了,你只需要完善即可 但也有不同点. 区别点 抽象 ...
- 第七周课程总结 & 实验报告(五)
第七周课程总结 一.抽象类与接口的应用 1.实例化 2.实际应用 ---模板设计(抽象类) ---制定标准(接口) 3.设计模式 ---工厂设计 ---代理设计 ---适配器设计 二.抽象类与接口之间 ...
- 第七周&实验报告五
实验四 类的继承 •实验目的 •理解抽象类与接口的使用: •了解包的作用,掌握包的设计方法. •实验要求 •掌握使用抽象类的方法. •掌握使用系统接口的技术和创建自定义接口的方法. •了解 Java ...
- 2019JAVA第五次实验报告
Java实验报告 班级 计科二班 学号 20188442 姓名 吴怡君 完成时间2019/10/11 评分等级 实验四 类的继承 实验目的 理解抽象类与接口的使用: 了解包的作用,掌握包的设计方法. ...
- 实验报告5&第七周课程总结
实验四 类的继承 实验目的 理解抽象类与接口的使用: 了解包的作用,掌握包的设计方法. 实验要求 掌握使用抽象类的方法. 掌握使用系统接口的技术和创建自定义接口的方法. 了解 Java 系统包的结构. ...
- 北京电子科技学院(BESTI)实验报告5
北京电子科技学院(BESTI)实验报告5 课程: 信息安全系统设计基础 班级:1452.1453 姓名:(按贡献大小排名) 郑凯杰.周恩德 学号:(按贡献大小排名) 20145314.20145217 ...
随机推荐
- mybatis plus 主键策略
博主原创,转载请注明出处: mybatis plus 对实体类映射表的主键做了注解支持,该注解为 @TableId ,如果不使用该注解,mybatis plus 默认主键生成的策略是内部封装的雪花算法 ...
- SV Interface and Program 2
Clocking:激励的时序 memory检测start信号,当start上升沿的时候,如果write信号拉高之后,将data存储到mem中 start\write\addr\data - 四个信号是 ...
- AHB-SRAMC Design-03
SRAMC SRAM CORE 8块memory进行广播信号,例化8片memory
- Cortex-M3 MCU的技术特点
1.Cortex-M3 MCU的技术特点 MCU简单来说就是一个可编程的中央处理器(CPU)加上一些必要的外设.不管是中央处理器还是整个MCU都是复杂的时序数字电路,根据程序或者指令来完成特定的任务. ...
- JMS微服务开发示例(七)使用 Serilog 作为日志提供者
nuget 引入: Serilog.Extensions.LoggingSerilog.Settings.ConfigurationSerilog.Sinks.ConsoleSerilog.Sinks ...
- Linux-文件权限-rwx-chmod
- PMC相关RAID卡信息查看方法
PMC相关RAID卡信息查看方法 摘要 昨天简单整理了LSI相关设备的信息 今天计划学习下PMC相关的RAID卡信息. 也就是偶昨天storcli 查看 controller为0 的情况. 感觉部分服 ...
- expres实现登录与修改密码
登录模块 如果登录的时候,昵称在数据库中查询的是不唯一值.需要提示用户登录失败. 即使用户密码输入正确. 然后将该消息通知相关人员,立即进行排查问题. var express = require('e ...
- 【记录一个问题】golang 中的 ecdsa(椭圆曲线加密) 算法很慢,因为用到了系统调用
代码中使用了椭圆曲线算法来签名,实际运行中发现不够快: func BenchmarkECDSA(b *testing.B) { privateKeyInst, err := parseSignatur ...
- python安装与python、pip的环境变量配置
进入官网 在你常用的搜索引擎中输入 python官网 然后进入. 可直接点击本链接 python官网进入: 也可在浏览器地址栏输入www.python.org回车进入官网. 下载 将鼠标放到菜单栏中的 ...