面试必问之redis
这里是我作为10年面试经验总结的面试中必问问题
问题一 简单介绍下redis
redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储。)。和Memcache类似,但很大程度补偿了Memcache的不足。和Memcache一样,Redis数据都是缓存在计算机内存中,不同的是,Memcache只能将数据缓存到内存中,无法自动定期写入硬盘,这就表示,一断电或重启,内存清空,数据丢失。所以Memcache的应用场景适用于缓存无需持久化的数据。而Redis不同的是它会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,实现数据的持久化
问题二 redis有哪几种数据结构
1、string是redis最基本的类型,可以理解成与memcached一模一样的类型,一个key对应一个value。value不仅是string,也可以是数字。string类型是二进制安全的,意思是redis的string类型可以包含任何数据,比如jpg图片或者序列化的对象。string类型的值最大能存储512M。
2、Hash是一个键值(key-value)的集合。redis的hash是一个string的key和value的映射表,Hash特别适合存储对象。常用命令:hget,hset,hgetall等。
3、list列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边) 常用命令:lpush、rpush、lpop、rpop、lrange(获取列表片段)等。应用场景:list应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表都可以用list结构来实现。数据结构:list就是链表,可以用来当消息队列用。redis提供了List的push和pop操作,还提供了操作某一段的api,可以直接查询或者删除某一段的元素。实现方式:redis list的是实现是一个双向链表,既可以支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
4、set是string类型的无序集合。集合是通过hashtable实现的。set中的元素是没有顺序的,而且是没有重复的。常用命令:sdd、spop、smembers、sunion等。应用场景:redis set对外提供的功能和list一样是一个列表,特殊之处在于set是自动去重的,而且set提供了判断某个成员是否在一个set集合中。
5、zset和set一样是string类型元素的集合,且不允许重复的元素。常用命令:zadd、zrange、zrem、zcard等。使用场景:sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set结构。和set相比,sorted set关联了一个double类型权重的参数score,使得集合中的元素能够按照score进行有序排列,redis正是通过分数来为集合中的成员进行从小到大的排序。实现方式:Redis sorted set的内部使用HashMap和跳跃表(skipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
问题三 redis雪崩、穿透、击穿分别是因为什么原因导致,你一般是怎么解决的
缓存穿透
原因
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿
原因
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题
方案一:使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
方案二:不设置失效时间,使用另外的定时任务去更新缓存数据
缓存雪崩
原因
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
解决方案
与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
问题四 为什么redis要用单线程
redis 核心数据全都在内存里,单线程的去操作 效率是最高的,为什么呢?
因为多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案。我们可以举个例子来比较下单线程与多线程的成本:
一次CPU上下文的切换大概在 1500ns 左右。
从内存中读取 1MB 的连续数据,耗时大约为 250us,假设1MB的数据由多个线程读取了1000次,那么就有1000次时间上下文的切换,
那么就有1500ns * 1000 = 1500us ,单线程的读完1MB数据才250us ,如果多线程光是上下文的切换就用了1500us了,这还不算每次读一点数据 的时间,
问题五 redis有哪几种持久化方式
Redis 提供了 RDB 和 AOF 两种持久化方式,RDB 是把内存中的数据集以快照形式写入磁盘,实际操作是通过 fork 子进程执行,采用二进制压缩存储;AOF 是以文本日志的形式记录 Redis 处理的每一个写入或删除操作。
RDB 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
AOF 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
问题六 redis有哪几种高可用部署方式
主从模式
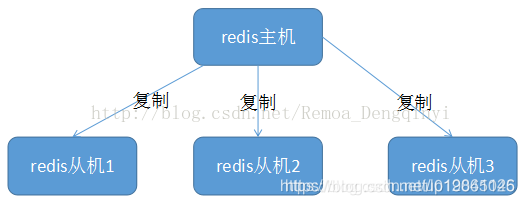
使用一个Redis实例作为主机,其余的作为备份机。主机和备份机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取。也就是说,客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机。主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
这种部署方案会存在主节点宕机后没办法进行写操作问题,需要人工干预或者keeplive+VIP来进行主节点漂移
哨兵
redis-Sentinel(哨兵模式)是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行切换
sentinel哨兵如下功能实现
(1)monitoring:监控redis是否正常运行
(2)notification:通知application错误信息
(3)failover:当某个master死掉,选择另外一个slave升级为master,更 新master-slave关系。
(4)configurationprovider:client通过sentinel获取redis地址,并在failover时更新地址
2.sentinels and slaves autodiscovery(redis2.8及以上)
配置文件中只配置master地址,slave地址和sentinel地址可以自动发现。
(1)sentinels——sentinel之间通过redis pub/sub交换信息获得。
(2)slaves——询问master获得。
3.sdown、odown、failover
故障检测一般都是通过ping-pong机制,sentinel引入sdown(主观下线)和odown(客观下线)机制,目的应该是在集群规模较大时,检测更客观
(1)sdwon——is-master-down-after-milliseconds(可配置)时间内ping-pong失败。sdown的slave不能升级为master。
(2)odown——超过一定数目(可配置)的sentinel认为sdown,odown只针对master。
(3)failover——多数sentinel认为odown。
redis集群模式
redis集群模式,同样可以实现redis高可用部署,Redis Sentinel集群模式中,随着业务量和数据量增,到性能达到redis单节点瓶颈,垂直扩容受机器限制,水平扩容涉及对应用的影响以及数据迁移中数据丢失风险。针对这些痛点
Redis3.0推出cluster分布式集群方案,当遇到单节点内存,并发,流量瓶颈是,采用cluster方案实现负载均衡,cluster方案主要解决分片问题,即把整个数据按照规则分成多个子集存储在多个不同几点上,每个节点负责自己整个数据的一部分。
Redis Cluster采用哈希分区规则中的虚拟槽分区。虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。Redis Cluster槽的范围是0 ~ 16383。槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,每个节点负责一定数量的槽。Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16383。每一个实节点负责维护一部分槽以及槽所映射的键值数据。下图展现一个五个节点构成的集群,每个节点平均大约负责3276个槽,以及通过计算公式映射到对应节点的对应槽的过程。
redis有哪几种淘汰策略
redis有六种淘汰策略
- noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。 大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL )。
- allkeys-lru: 所有key通用; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- volatile-lru: 只限于设置了 expire 的部分; 优先删除最近最少使用(less - recently used ,LRU) 的 key。
- allkeys-random: 所有key通用; 随机删除一部分 key。
- volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key。
- volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的key。
面试必问之redis的更多相关文章
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 【面试必问】python实例方法、类方法@classmethod、静态方法@staticmethod和属性方法@property区别
[面试必问]python实例方法.类方法@classmethod.静态方法@staticmethod和属性方法@property区别 1.#类方法@classmethod,只能访问类变量,不能访问实例 ...
- 面试必问:JVM类加载机制详细解析
前言 在Java面试中,简历上有写JVM(Java虚拟机)相关的东西,JVM的类加载机制基本是面试必问的知识点. 类的加载和卸载 JVM是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是cla ...
- 一线大厂Java面试必问的2大类Tomcat调优
一.前言 最近整理了 Tomcat 调优这块,基本上面试必问,于是就花了点时间去搜集一下 Tomcat 调优都调了些什么,先记录一下调优手段,更多详细的原理和实现以后用到时候再来补充记录,下面就来介绍 ...
- python笔记39-unittest框架如何将上个接口的返回结果给下个接口适用(面试必问)
前言 面试必问:如何将上个接口的返回结果,作为下个接口的请求入参?使用unittest框架写用例时,如何将用例a的结果,给用例b使用. unittest框架的每个用例都是独立的,测试数据共享的话,需设 ...
- 高级测试工程师面试必问面试基础整理——python基础(一)(首发公众号:子安之路)
现在深圳市场行情,高级测试工程师因为都需要对编程语言有较高的要求,但是大部分又没有python笔试机试题,所以面试必问python基础,这里我整理一下python基本概念,陆续收集到面试中python ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
随机推荐
- .NET Core 中生成验证码
在开发中,有时候生成验证码的场景目前还是存在的,本篇演示不依赖第三方组件,生成随机验证码图片. 先添加验证码接口 public interface ICaptcha { /// <summary ...
- QT学习:05 元对象系统
--- title: framework-cpp-qt-05-元对象系统 EntryName: framework-cpp-qt-05-mos date: 2020-04-09 17:11:44 ca ...
- bash shell基础命令
bash shell基础命令 很多Linux发行版的默认shell是GNU bash shell. 1. 启动shell GNU bash shell是一个程序,提供了对Linux系统的交互式访问.它 ...
- tcp_tw_reuse、tcp_tw_recycle、tcp_fin_timeout参数介绍
参数介绍 net.ipv4.tcp_tw_reuse = 1 表示开启重用.允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭: net.ipv4.tcp_tw_rec ...
- NXP i.MX 6ULL工业核心板硬件说明书( ARM Cortex-A7,主频792MHz)
1 硬件资源 创龙科技SOM-TLIMX6U是一款基于NXP i.MX 6ULL的ARM Cortex-A7高性能低功耗处理器设计的低成本工业级核心板,主频792MHz,通过邮票孔连 ...
- 基于NXP i.MX 8M Mini开发板规格书(四核ARM Cortex-A53 + 单核ARM Cortex-M4,主频1.6GHz)
1 评估板简介 创龙科技TLIMX8-EVM-B是一款基于NXP i.MX 8M Mini的四核ARM Cortex-A53 + 单核ARM Cortex-M4异构多核处理器设计的高性能评估板,由核 ...
- Vue2 整理(一):基础篇
前言 首先说明:要直接上手简单得很,看官网熟悉大概有哪些东西.怎么用的,然后简单练一下就可以做出程序来了,最多两天,无论Vue2还是Vue3,就都完全可以了,Vue3就是比Vue2多了一些东西而已,所 ...
- AT_joisc2019_j 题解
先考虑这个式子: \[\sum_{j=1}^{M} |C_{k_{j}} - C_{k_{j+1}}| \] 一定是在 \(C\) 有序时取到,具体证明很简单各位读者自己证明. 那么现在式子变成: \ ...
- Nuxt框架中内置组件详解及使用指南(五)
title: Nuxt框架中内置组件详解及使用指南(五) date: 2024/7/10 updated: 2024/7/10 author: cmdragon excerpt: 摘要:本文详细介绍了 ...
- css-渐变简约的登录设计
代码如下 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...