hive中一般取top n时,row_number(),rank,dense_ran()常用三个函数
一、 分区函数Partition By与row_number()、rank()、dense_rank()的用法(获取分组(分区)中前几条记录)
一、数据准备

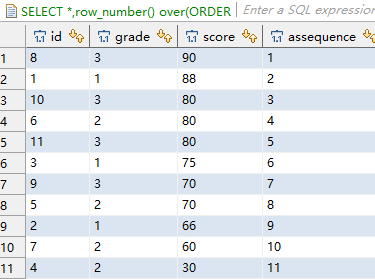
二、分区函数partition by与row_number()的用法
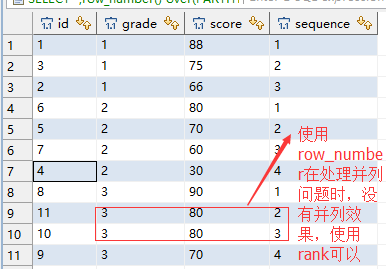
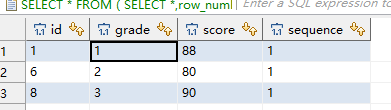
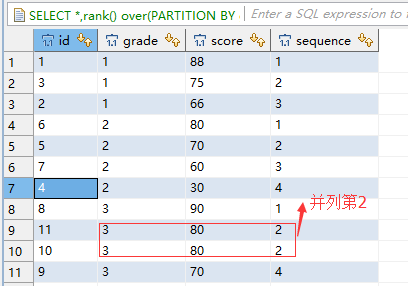
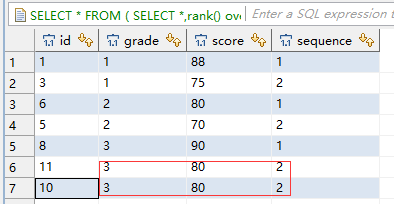
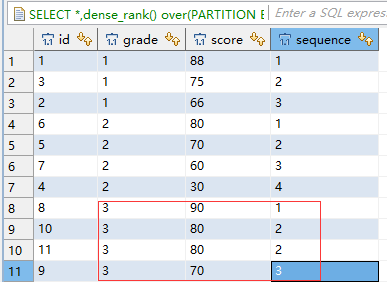
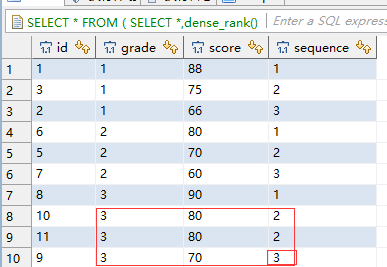
三、分区函数partition by与排序rank()的用法
hive中一般取top n时,row_number(),rank,dense_ran()常用三个函数的更多相关文章
- hive 中窗口函数row_number,rank,dense_ran,ntile分析函数的用法
hive中一般取top n时,row_number(),rank,dense_ran()这三个函数就派上用场了, 先简单说下这三函数都是排名的,不过呢还有点细微的区别. 通过代码运行结果一看就明白了. ...
- hive中分组取前N个值的实现
背景 假设有一个学生各门课的成绩的表单,应用hive取出每科成绩前100名的学生成绩. 这个就是典型在分组取Top N的需求. 解决思路 对于取出每科成绩前100名的学生成绩,针对学生成绩表,根据学科 ...
- hive分组排序 取top N
pig可以轻松获取TOP n.书上有例子 hive中比较麻烦,没有直接实现的函数,可以写udf实现.还有个比较简单的实现方法: 用row_number,生成排名序列号.然后外部分组后按这个序列号多虑, ...
- 在hive中查询导入数据表时FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
当我们出现这种情况时 FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least ...
- sqoop 从oracle导数据到hive中,date型数据时分秒截断问题
oracle数据库中Date类型倒入到hive中出现时分秒截断问题解决方案 1.问题描述: 用sqoop将oracle数据表倒入到hive中,oracle中Date型数据会出现时分秒截断问题,只保留了 ...
- 为什么在ucos向stm32f103移植时说os_cpu_c.c中有三个函数如OS_CPU_SysTickInit()需要注释掉
我在看os_cpu_c.c代码时对下面这段话困惑了半天总是在百度的帮助下找到了答案 /* 申明几个函数,这里要注意最后三个函数需要注释掉,为什么呢? OS_CPU_SysTickHandler ...
- Hive中使用Python实现Transform时遇到Broken pipe错误排查
Hive中有一表,列分隔符为冒号(:),有一列utime是Timestamp格式,需要转成Weekday存到新表. 利用Python写一个Pipeline的Transform,weekday.py的代 ...
- SQL Server 分组取 Top 笔记(row_number + over 实现)
先看SQL语句(注意:这是在SQL Server 2005+ [包括2005] 的版本才支持的哦,o(∩_∩)o 哈哈~) SELECT col1,col2,col3 FROM table1 AS a ...
- 从m个数中取top n
将题目具体一点,例如,从100个数中取出从大到小排前10的数 方法1:使用快速排序 因为快速排序一趟下来,小于K的数都在K的前面,大于K的数都在K的后面 如果,小于K的数有35个,大于K的数有64个 ...
随机推荐
- PyQt编程实战:画出QScrollArea的scrollAreaWidgetContents内容部署层的范围矩形
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 在<PyQt(Python+Qt)学习随笔:QScrollArea滚动区域详解> ...
- jarvisoj flag在管理员手上
jarvisoj flag在管理员手上 涉及知识点: (1)代码审计和cookie注入 (2)哈希长度拓展攻击 解析: 进入题目的界面.看到 那么就是想方设法的变成admin了.挂上御剑开始审计.发现 ...
- java.lang.UnsupportedOperationException: Unable to create instance of org.fisco.bcos.web3j.abi.datatypes.generated.Int256
Contract Address : 0x967f92adc229b77dda64b42af21ea1ff1b0702eb Unable to create instance of org.fisco ...
- 最详细Python批量字典暴力破解zip密码
工具破解 前两天在网上下来了一波项目案例,结果全是加密的压缩包,于是去网上找了一个压缩包破解的工具 苦于工具破解太慢,一个压缩包要好久,解压了三个之后就放弃了,准备另寻他法 密码字典 巧的是破解的三个 ...
- MySQL全备及备份文件删除脚本
1.数据库全备 #!/bin/shv_user="root"v_password="mysql"backup_date=`date +%Y%m%d%H%M` M ...
- 2020.12.16 模拟赛x+1
A. 接力比赛 跑两遍背包,再进行一些玄学的剪枝 代码 #include<cstdio> #include<algorithm> #define rg register inl ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 群晖DS218+部署Harbor(1.10.3)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Kali Linux破解wifi密码(无须外置网卡)
环境准备: 方式一(选择该方式):Kali Linux.笔记本一台.U盘(至少8G) 方式二:Kali Linux.外置网卡.笔记本一台.VM 特别说明,主要是使用方式一进行破解,如果有外置网 ...
- 如何修改openstack虚拟机密码
1.虚拟机创建时设置密码 计算节点安装以下软件包 yum install libguestfs python-libguestfs libguestfs-tools-c 配置计算节点nova配置文件/ ...