TSP旅行商问题
求解的问题,burma.tsp里面的内容
1 16.47 96.10
2 16.47 94.44
3 20.09 92.54
4 22.39 93.37
5 25.23 97.24
6 22.00 96.05
7 20.47 97.02
8 17.20 96.29
9 16.30 97.38
10 14.05 98.12
11 16.53 97.38
12 21.52 95.59
13 19.41 97.13
14 20.09 94.55
主程序
为方便调用,已经将所有的模块整合到一个程序内。
import random
import math
import matplotlib.pyplot as plt
import re
#本程序为老师布置的旅行商问题的程序练习作业#
#制作者-zqh 联系方式:博客园-克莱比 qq:962903415#
#-------参数部分--------#
generation=[]
fitvalue=[]
# dict={
# 1:[16.47,96.10],2:[16.47,94.44],3:[20.09,92.54],
# 4:[22.39,93.37],5:[25.23,97.24],6:[22.00,96.05],
# 7:[20.47,97.02],8:[17.20,96.29],9:[16.30,97.38],
# 10:[14.05,98.12],11:[16.53,97.38],12:[21.52,95.59],
# 13:[19.41,97.13],14:[20.09,94.55]
# }
#修改部位1。此部分的字典操作应该采用文件读写的方式来完成 crossrate=4
mutationrate=1
size=30
popgeneration=400 #——————————————这里是交叉的模块——————————#
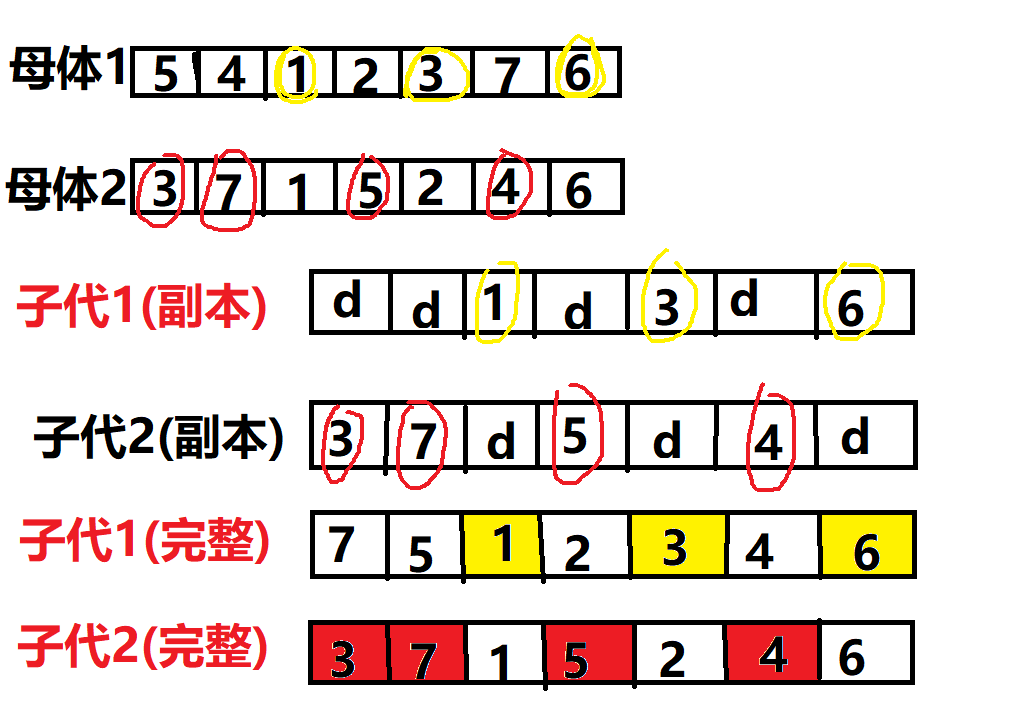
def crossOver(population):
ret = []
for i in range(0,int(len(population)/2)):
cplist1=[]
cplist2=[]
register1=[]
register2=[]
crossval1=[]
crossval2=[]
x1=random.choice(population)
target=0
while target!=1:
x2=random.choice(population)
if x2!=x1:
target=1
if x2==x1:
continue
# print('随机抽出两个不同的母体',(x1,x2))
while len(cplist1)<=crossrate: #随机抽crossrate条染色体位置传给子代
crossposition=random.randrange(0,13)
if crossposition not in cplist1: #保证随机取得交叉位置不重复
cplist1.append(crossposition)
crossval1.append(x1[crossposition])
# print('母体1传给子代的交叉位置%s,交叉位置值%s' %(cplist1,crossval1))
for i in range(0,14):
if i not in cplist1:
cplist2.append(i)
crossval2.append(x2[i])
# print('母体2传给子代的交叉位置%s,交叉位置值%s' %(cplist2,crossval2))
for i1 in range(0,14):
if i1 not in cplist1: #单体长度14,如果是交叉位置上的就传值,如果不是就传d
register1.append('d')
if i1 in cplist1:
register1.append(x1[i1])
# print('母体1交叉位置形成子代1副本',register1)
for i2 in x2:
if i2 not in crossval1: #给d更换的值不能与已经存在的值重复
for xp in range(0,len(register1)):
if register1[xp]=='d': #用于定位d的位置
register1[xp]=i2
break
# print('交叉后的子体1',register1)
for p1 in range(0,14):
if p1 not in cplist2:
register2.append('d')
if p1 in cplist2:
register2.append(x2[p1])
# print('母体2交叉位置形成子代1副本',register2)
for p2 in x1:
if p2 not in crossval2:
for xp1 in range(0,len(register2)):
if register2[xp1]=='d':
register2[xp1]=p2
break
# print('交叉后的子体2',register2)
ret.append(register1)
ret.append(register2)
print('交叉完成后的种群',ret)
return ret #——————————————这里是变异的模块——————————#
def mutation(population):
ret=[]
for i in population:
porbility=random.uniform(0,1)
if porbility<mutationrate:
a=random.randrange(0,14)
b=random.randrange(0,14)
trans=i[a]
trans1=i[b]
i[a]=trans1
i[b]=trans
ret.append(i)
else:
ret.append(i)
# print('变异完成后的种群',ret)
return ret #——————————————————这里是产生随机种群的模块——————————#
def creatPop(popsize):
ret1=[]
for i in range(0,popsize):
ret=[]
# while(len(ret)<=13):
# x=random.randrange(1,15)
# if x not in ret: #xulie
# ret.append(x)
# ret1.append(ret)
#根据上次说的改进,可以使用random乱序来生成
for i1 in range(0,14):
ret.append(i1+1)
random.shuffle(ret)
ret1.append(ret)
print('生成的初代种群',ret1)
return ret1
creatPop(2) #——————————————————这里是将文件内的数据读取出来并放入字典的程序——————————# dict={} fil=open('burma14.tsp','r',encoding='utf8') #r代表读操作,且打开时按utf8
for i in range(0,14):
readtext=fil.readline()
readline=re.split('[ ]',readtext)
for i in range(0,4):
readline.remove('')
dict.update({int(readline[0]):[float(readline[1]),float(readline[2])]})
print(dict) #————————————————这里是适应度函数值的计算模块——————
def fitNess(population):
ret=[]
for i in population:
# print(i)
distance = 0
s=0
for xp in range(0,len(i)-1):
# print(dict[i[s]])
# print(dict[i[s+1]])
distance=distance+((dict[i[s]][0]-dict[i[s+1]][0])**2+(dict[i[s]][1]-dict[i[s+1]][1])**2)**(1/2)
# print(distance) #每两个相邻的点位求距离
s=s+1
distance=distance+((dict[i[0]][0]-dict[i[13]][0])**2+(dict[i[0]][1]-dict[i[13]][1])**2)**(1/2) #最后再求终点到起点的距离
ret.append(distance)
print('计算并集内个体适应度',ret)
return ret def popChoice(population):
ret=[]
ret1=[]
dict1={}
unionpop=[]
for i in start:
unionpop.append(i)
for i1 in population:
unionpop.append(i1)
print('新老种群并集',unionpop)
fitlist=fitNess(unionpop)
for xp in range(0,len(fitlist)):
dict1.update({fitlist[xp]:unionpop[xp]})
print(dict1)
fitlist.sort()
print(fitlist)
for xp1 in fitlist:
ret.append(dict1[xp1])
print(ret)
for xp2 in range(0,size):
if ret[xp2] not in ret1:
ret1.append(ret[xp2])
print(ret1)
print('最优适应度值为',fitlist[0])
fitvalue.append(fitlist[0])
return ret1 a=creatPop(size)
start=a
for i in range(0,popgeneration):
b=crossOver(start)
c=mutation(b)
d=popChoice(c)
print('第%s世代,他的最优解为%s' %(i+1,d[0]))
start=d for i1 in range(0,popgeneration):
generation.append(i1) plt.plot(generation,fitvalue)
plt.ylabel('fitness value') #为y轴加注释
plt.xlabel('generation') #为x轴加注释
plt.show()
#本程序为老师布置的旅行商问题的程序练习作业#
#制作者-zqh 联系方式:博客园-克莱比 qq:962903415#
TSP旅行商问题的更多相关文章
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- 数学建模 TSP(旅行商问题) Lingo求解
model: sets: cities../:level; link(cities, cities): distance, x; !距离矩阵; endsets data: distance ; end ...
- ACS蚁群算法求解对称TSP旅行商问题的JavaScript实现
本来以为在了解蚁群算法的基础上实现这道奇怪的算法题并不难,结果实际上大相径庭啊.做了近三天时间,才改成现在这能勉强拿的出手的模样.由于公式都是图片,暂且以截图代替那部分内容吧,mark一记. 1 蚁群 ...
- Python动态展示遗传算法求解TSP旅行商问题(转载)
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/jiang425776024/articl ...
- 基于GA遗传算法的TSP旅行商问题求解
import random import math import matplotlib.pyplot as plt import city class no: #该类表示每个点的坐标 def __in ...
- TSP旅行商问题的Hopfield求解过程
连续型Hopfield在matlab中没有直接的工具箱,所以我们们根据Hopfield给出的连续行算法自行编写程序.本文中,以求解旅行商 问题来建立Hopfield网络,并得到解,但是该解不一定是 ...
- hdu5067Harry And Dig Machine(TSP旅行商问题)
题目链接: huangjing 题意:给出一幅图.图中有一些点,然后从第1个点出发,然后途径全部有石头的点.最后回到原点,然后求最小距离.当初作比赛的时候不知道这就是旅行商经典问题.回来学了一下. 思 ...
- TSP 旅行商问题(状态压缩dp)
题意:有n个城市,有p条单向路径,连通n个城市,旅行商从0城市开始旅行,那么旅行完所有城市再次回到城市0至少需要旅行多长的路程. 思路:n较小的情况下可以使用状态压缩dp,设集合S代表还未经过的城市的 ...
- HDU 5067 Harry And Dig Machine(状压DP)(TSP问题)
题目地址:pid=5067">HDU 5067 经典的TSP旅行商问题模型. 状压DP. 先分别预处理出来每两个石子堆的距离.然后将题目转化成10个城市每一个城市至少经过一次的最短时间 ...
随机推荐
- C# 队列Queue,ConcurrentQueue,BlockingCollection 并发控制lock,Monitor,信号量Semaphore
什么是队列? 队列Queues,是一种遵循先进先出的原则的集合,在.netCore中微软给我们提供了很多个类,就目前本人所知的有三种,分别是标题提到的:Queue.ConcurrentQueue.Bl ...
- C# List的并集、交集、差集
并集---Union 集合的并集是合并两个集合的所有项,去重,如下图所示: List<int> ls1 = new List<int>() { 1,2,3,5,7,9 }; ...
- 容器编排系统K8s之PV、PVC、SC资源
前文我们聊到了k8s中给Pod添加存储卷相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14180752.html:今天我们来聊一下持久存储卷相关话题 ...
- idea2020 没有 Autoscroll from Source
2018版本: 2020版本: 最后在官网的网站中找到了解决方案,原来是改名了: 网址:https://intellij-support.jetbrains.com/hc/en-us/communit ...
- IaaS、PaaS、SaaS、DaaS都是什么?现在怎么样了?终于有人讲明白了
导读:本文将详细科普云计算的概念.云服务的发展现状,并逐一介绍各种云服务模式(IaaS.PaaS.SaaS.DaaS),建议收藏! 作者:阿里云智能-全球技术服务部来源:大数据DT(ID:bigdat ...
- MRP物料需求计划
1.重订货点的采购计划. 计算方式:再订货点的库存数量 = 安全库存 + 采购提前期 * 每天消耗的数量 一旦库存数量触及再订货点的库存数量,需触发采购订单订购物料,理想的情况下 ,下次到采购订单收货 ...
- Tiny6410烧入uboot,linux内核,文件系统
好久没有玩tiny6410了,今天拿出来试试.之前学习一直是跟着视频学习的.今天自己动手来做一下. 首先我将光盘linux目录下的linux-2.6.38-20150708.tgz rootfs_r ...
- 这一次,彻底理解XSS攻击
希望读完本文大家彻底理解XSS攻击,如果读完本文还不清楚,我请你吃饭慢慢告诉你~ 话不多说,我们进入正题. 一.简述 跨站脚本(Cross-site scripting,简称为:CSS, 但这会与层叠 ...
- JVM 常用命令行工具
本文部分摘自<深入理解 Java 虚拟机第三版> 基础故障处理工具 Java 开发人员肯定都知道 JDK 的 bin 目录下有许多小工具,这些小工具除了用于编译和运行 Java 程序外,打 ...
- vue调起微信扫一扫
vue调起微信扫一扫,两个注意的点 1.url必须是不带参的地址栏,如果传了带参数的地址url有可能会出现安卓机能调,苹果机报错或者安卓和苹果都报错 2.this指代问题在vx.ready等等方法里面 ...