解Bug之路-dubbo流量上线时的非平滑问题
前言
笔者最近解决了一个困扰了业务系统很久的问题。这个问题只在发布时出现,每次只影响一两次调用,相较于其它的问题来说,这个问题有点不够受重视。由于种种原因,使得这个问题到了业务必须解决的程度,于是就到了笔者的手上。
问题现场
我们采用的是dubbo服务,这是个稳定成熟的RPC框架。但是我们在某些应用中会发现,只要这个应用一发布(或者重启),就会出现请求超时的问题,如下图所示:
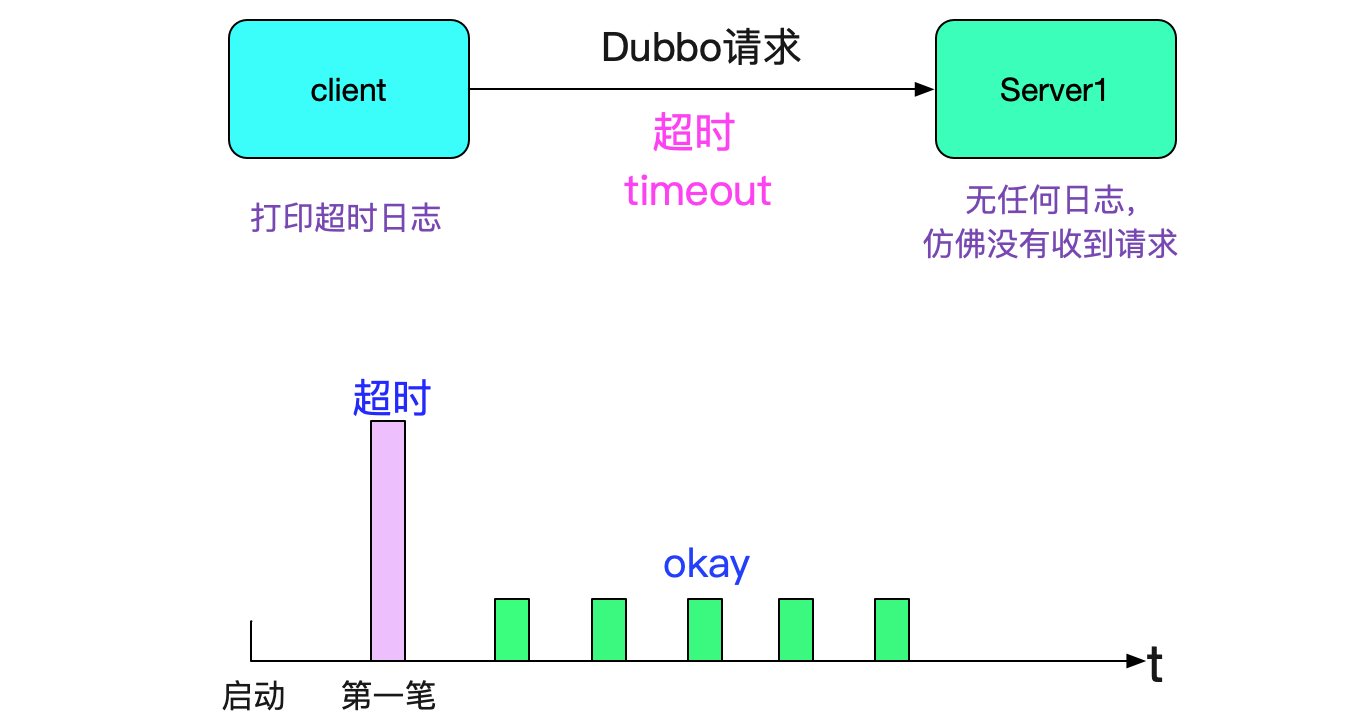
而且都是第一笔请求会报错,之后就再也没有问题了。
排查日志
好了,现象我们知道了,于是开始排查那个时间点的日志。Server端没有任何日志,而Client(App1)端报错超时。报错如下所示:
2019-08-22 20:33:50.798
com.alibaba.dubbo.rpc.RpcException:
Failed to invoke the method set in the servce XXXFacade,
tries 1 times
......
start time: 2019-08-22 20:32:50.474
end time: 2019-08-22 30:33:50.767
timeout=60000,channel:/1.1.1.1:44502->2.2.2.2:20880
看日志报错是这个tcp五元组(1.1.1.1:44502->2.2.2.2:20880)有问题。于是笔者netstat了一下,查看当前此连接的状态:
netstat -anp | grep 44502
1.1.1.1:44502 2.2.2.2:20880 ESTABLISHED
这个连接处于正常的ESTABLISHED状态,而且调用2.2.2.2这个server的连接只有这一个,那后续这台机器调用2.2.2.2这个server肯定只用到了这个连接,查看日志发现除了这一笔,其它调用一切正常。
思路1:Server端处理超时
按照上面的报错,肯定这个连接有问题,按照正常思路,是否是第一笔调用的时候各种初始化过程(以及jit)导致server处理请求过慢?如下图所示:
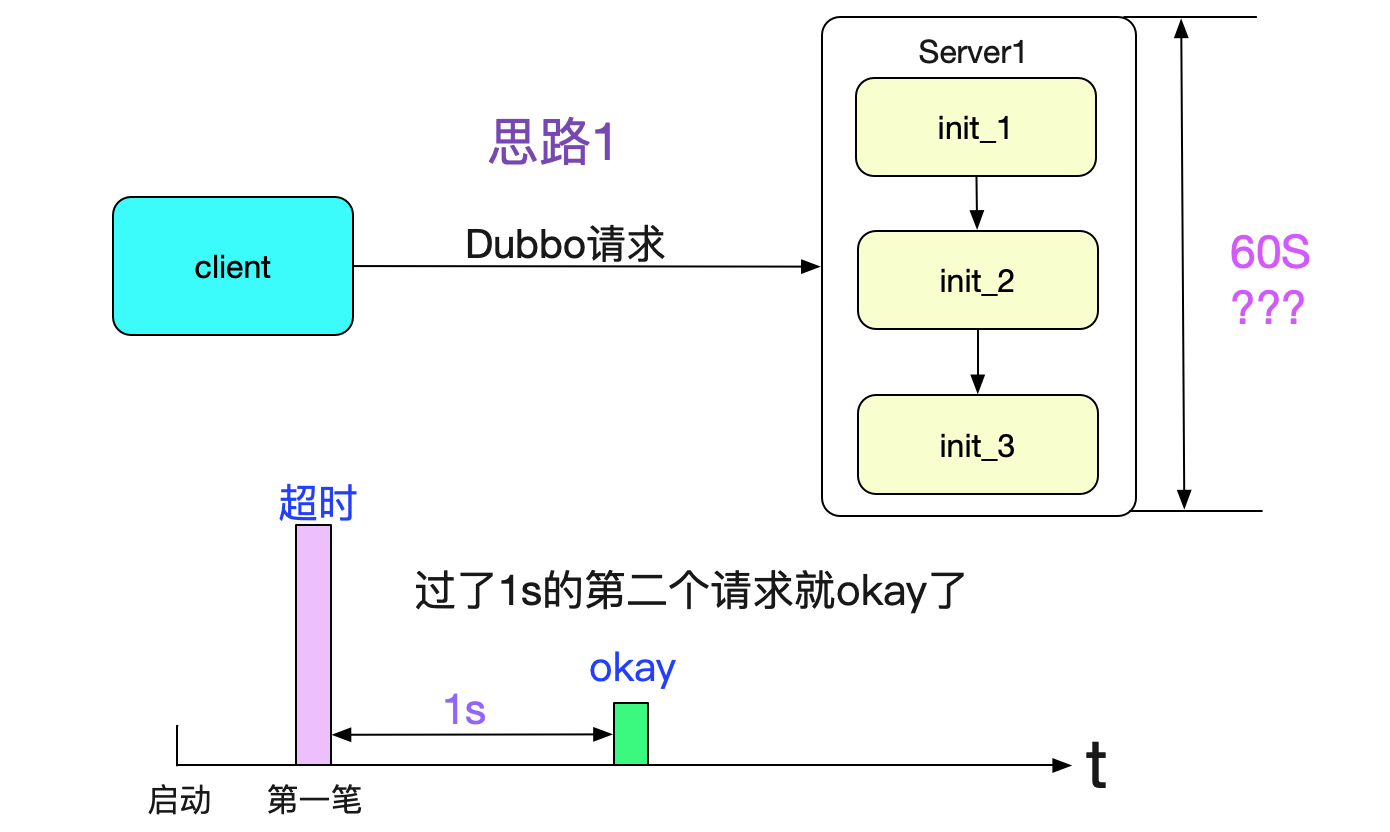
但这个问题很快被第二笔请求(和第一笔请求间隔只有一秒)给否决了。也就是说第一笔请求花了60s还超时,而第二笔请求在第一笔请求发出后的一秒后发出就成功了(而且耗时是毫秒级的)。如果按照上述思路,第二笔请求也应该等各种初始化完成之后再处理,也应该卡相当长的一段时间才对。再加上server端没有任何日志,就感觉好像没有收到请求。
思路2:Client端没有发送成功
于是我们开始了思路2,Client端没有发送成功。由于Dubbo是基于Netty的,其请求传输的处理过程是个NIO的异步化过程(只不过通过使用future机制对业务来说是同步的)。首先我们看下dubbo的超时检测机制,如下图所示:

当然,还有future的超时机制,这边我就不列举出来了。从这个机制可以看出,就算Client端发送的时候(因为写是写到socket的writebuffer里面,一般不会满,所以不会报错)没有发送出去,也不会在发的那一刻报出错误,而是要等定时扫描。为了验证这个猜想,笔者就开始着手排查连接的日志。
连接日志
因为规律是第一笔失败,那么笔者开始怀疑连接创建的有问题,但后面的请求成功又表明连接创建是没有问题的。那么,是否是连接还没有创建好就发送了第一笔请求呢?带着这样的疑问,笔者找到了如下的日志:
2019-08-22 20:32:51.876 (DubboClientReconnectTimer-thread-1) Successed connect to server /1.1.1.1:20880 ... channel is
NettyChannel /1.1.1.1:44502 => /2.2.2.2:20880
由日志所示,1.1.1.1:44502这个连接串是在2019-08-22 20:32:51.876连接成功的,而上面出错的日志起始时间为
请求发送时间:2019-08-22 20:32:50.474
连接开始建立时间:2019-08-22 20:32:51.876
连接成功建立时间:2019-08-22 20:32:51.876
请求在连接成功建立之前,感觉非常符合笔者上述的猜想。但细想又不对,上述日志表示的是在2019-08-22 20:32:51.876开始建立连接并在1ms内建立成功连接。而请求确是50s发出的,dubbo本身代码不可能在连接还没做出创建动作的时候就开始发送请求(因为44502是由kernel分配的,没到创建连接动作之前是不可能知道这个端口号的,但它却在日志里面打印出来了),如下图所示:

思考了一段时间,笔者觉得这种情况很有可能是日志是不准确的,它仅仅打印当前连接包装类中的信息,之前那个出错的连接已经被新建的连接掩盖了(在日志中)。我们看下dubbo中对应的打印日志代码:
private String getTimeoutMessage(boolean scan) {
long nowTimestamp = System.currentTimeMillis();
return (sent > 0 ? "Waiting server-side response timeout" : "Sending request timeout in client-side")
+ (scan ? " by scan timer" : "") + ". start time: "
+ (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date(start))) + ", end time: "
+ (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date())) + ","
+ (sent > 0 ? " client elapsed: " + (sent - start)
+ " ms, server elapsed: " + (nowTimestamp - sent)
: " elapsed: " + (nowTimestamp - start)) + " ms, timeout: "
+ timeout + " ms, request: " + request + ", channel: " + channel.getLocalAddress()
+ " -> " + channel.getRemoteAddress();
}
这个1.1.1.1:44502是由channel.getLocalAddress()得出的,我们看下调用链:
channel.getLocalAddress()
|->nettyClient.channel.getLocalAddress()
笔者看了下代码,dubbo在reconnect(重新连接的时候)会把nettyClient.channel换掉,从而可能打印出来和发送请求时不同的client端口信息。再加上日志里面打印出来的线程号DubboClientReconnectTimer-thread-1就几乎可以确定,之前还有一个连接,只不过这个连接失败了,新建的连接为1.1.1.1f
:44502。再仔细的找了下日志,发现了下面这条日志:
------------------日志分割线----------------
2019-08-22 20:32:51,876(DubboClientReconnectTimer-thread-1) Close old Netty channel /1.1.1.1:44471 :> 2.2.2.2:20880
on create new netty channel /1.1.1.1:44502 => /2.2.2.2:20880
------------------日志分割线----------------
2019-08-22 20:32:51.876 (DubboClientReconnectTimer-thread-1) Successed connect to server /1.1.1.1:20880 ... channel is
NettyChannel /1.1.1.1:44502 => /2.2.2.2:20880
即是说dubbo在把1.1.1.1:44471关闭后,立马创建了2.2.2.2:44502
那么整体过程如下图所示:
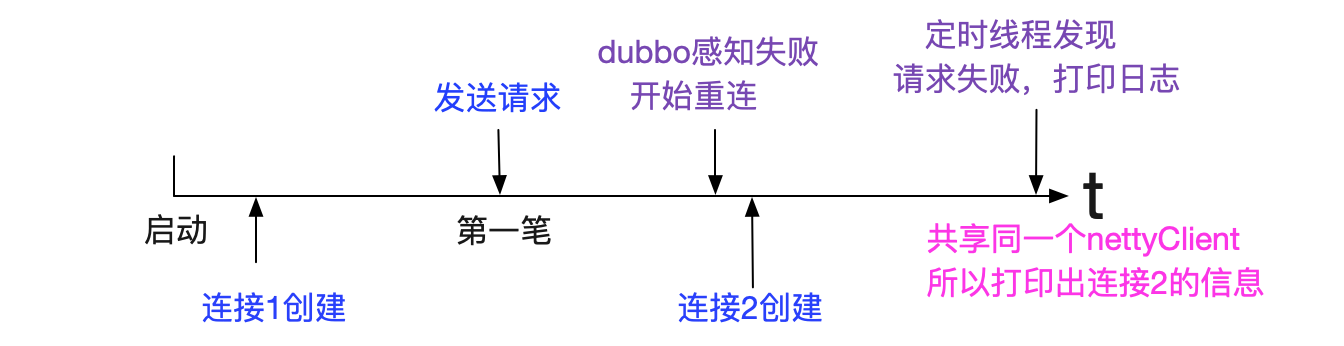
我们看下1.1.1.1:44471是什么时候创建的,继续搜寻日志:
zgrep '1.1.1.1:44471' dubbo.log.1.zip
2019-08-22 20:31:59.871 (ZkClient-EventThread-23) Successed connect to server /2.2.2.2:20880 ... channel is
NettyChannel /1.1.1.1: 44471 => /2.2.2.2:20880
------------------日志分割线----------------
2019-08-22 20:32:51,876(DubboClientReconnectTimer-thread-1) Close old Netty channel /1.1.1.1:44471 :> 2.2.2.2:20880
发现其在
连接1创建时间:2019-08-22 20:31:59.871
请求发送时间:2019-08-22 20:32:50.474
连接1关闭时间:2019-08-22 20:32:51,876
而且笔者翻看了业务日志,发现连接1在其生命周期内有且只有一笔请求,这笔请求就是报错的请求,由此可以看出这个连接1从建立成功开始就无法使用。
为什么连接建立成功确无法使用
首先由于dubbo是基于netty的,这种成熟的广泛应用的框架在创建连接这种问题上不应该会有问题。
而笔者仔细翻看netty翻看netty源码也确实遵守了NIO的编写套路。那么问题可能出现在环境上,既然应用(client/server)本身日志找不到更多的有用信息,那么看看操作系统能否有什么可以追寻的蛛丝马迹。于是笔者首先用dmesg查看下kernel打印的日志,client端没发现什么有用的信息,但server端的dmesg引起了笔者的注意
possible SYN flooding on port 20880. Sending cookies.
possible SYN flooding on port 20880. Sending cookies.
possible SYN flooding on port 20880. Sending cookies.
possible SYN flooding on port 20880. Sending cookies.
possible SYN flooding on port 20880. Sending cookies.
其字面意思为kenerl本身可能在20880端口遭到了SYN泛洪攻击,发送cookies。
这种日志会在并发连接过多的情况下由kernel打印出来。笔者netstat了下频繁出问题的机器,发现其特点都是连接特别多(达到了好几千甚至上万)。而dubbo的上线机制是只要注册到zookeeper后,zookeeper给所有的机器推送,所有的机器立马连接,这样就会造成比较高的并发连接,如下图所示:

既然怀疑到了高并发connect,那么笔者就立马用netstat看下kernel对于tcp的统计信息:
netstat -s
...
TcpExt:
...
1607 times the listen queue of a socket overflowed
...
果然有这种并发连接导致的统计信息,socket overflowed表示的是server端的tcp_backlog队列溢出了。到这里笔者有八成把握是这个tcp_backlog设置的过小的问题了。下面就是分析,tcp_backlog溢出为什么会导致上述连接虽然成功但是第一笔报错的现象,从而和日志相印证,来证明笔者的猜测。
tcp_backlog溢出分析
tcp的三次握手
先从tcp的三次握手进行着手分析,从tcp_v4_do_rcv函数进行入手,因为这个函数是tcp协议获取packet的地方,当三次握手的SYN第一次进来的时候,应该会走这个函数:
// 先考察一下三次握手的第一个SYN
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb){
if (sk->sk_state == TCP_LISTEN) {
......
// 由于现在连接处于第一个SYN,现在server端的socket处于LISTEN状态
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
......
}
}
// 我们继续看下tcp_v4_hnd_req代码,三次握手第一个SYN kernel走的分支
tcp_v4_do_rcv
/* 由于tcp_v4_hnd_req没有发现和此五元组对应的连接,所以do nothing */
|->tcp_v4_hnd_req
|->tcp_rcv_state_process
/** case TCP_LISTEN && th->syn */
|->conn_request(tcp_v4_conn_request)
我们继续分析conn_request函数,由于里面很多逻辑,所以我们滤掉了很多细节:
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) {
// 如果csk的reqsk queue满了,则设置want_cookie标识
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
if (sysctl_tcp_syncookies) {
want_cookie = 1;
}
......
if(want_cookie){
// 下面这行就是打印possible SYN flooding的地方
syn_flood_warning(skb);
......
}
// 发送synack,即三次握手的第二次握手
// 注意want_cookie的时候并不把对应的req加入到reqsk的hash列表中
if (__tcp_v4_send_synack(sk, req, dst) || want_cookie)
goto drop_and_free;
// 如果发送syack成功,则加到hash列表里面
inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT);
......
drop_and_free;
reqsk_free(req);
return 0;
}
}
上面就是三次握手的前两次握手,如下图所示:

现在让我们看下最关键的第三次握手(客户端发给server ack的过程),依旧从tcp_v4_do_rcv开始
tcp_v4_hnd_req
|->tcp_v4_hnd_req
// 这里面分两种情况
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb){
// 首先从inet_csk_search_req看是否有对应的五元组
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source,
iph->saddr, iph->daddr);
// 这边的req分支下的tcp_check_req是重点,我们下面再分析
if (req)
return tcp_check_req(sk, skb, req, prev);
// 处理established情况
// 如果inet_csk没找到,则可能是需要syn cookie,处理syn cookie
// 下面这条语句应该是在syn
sk = cookie_v4_check(sk, skb, &(IPCB(skb)->opt));
// 如果处理成功,则把其加入到inet_csk_reqsk_queue_add队列中
......
}
上面这些代码片段主要表明的就是如果三次握手成功,会在server端把新创建的server端sock放到inet_csk_reqsk里面,然后由后面的tcp_child_process去处理。
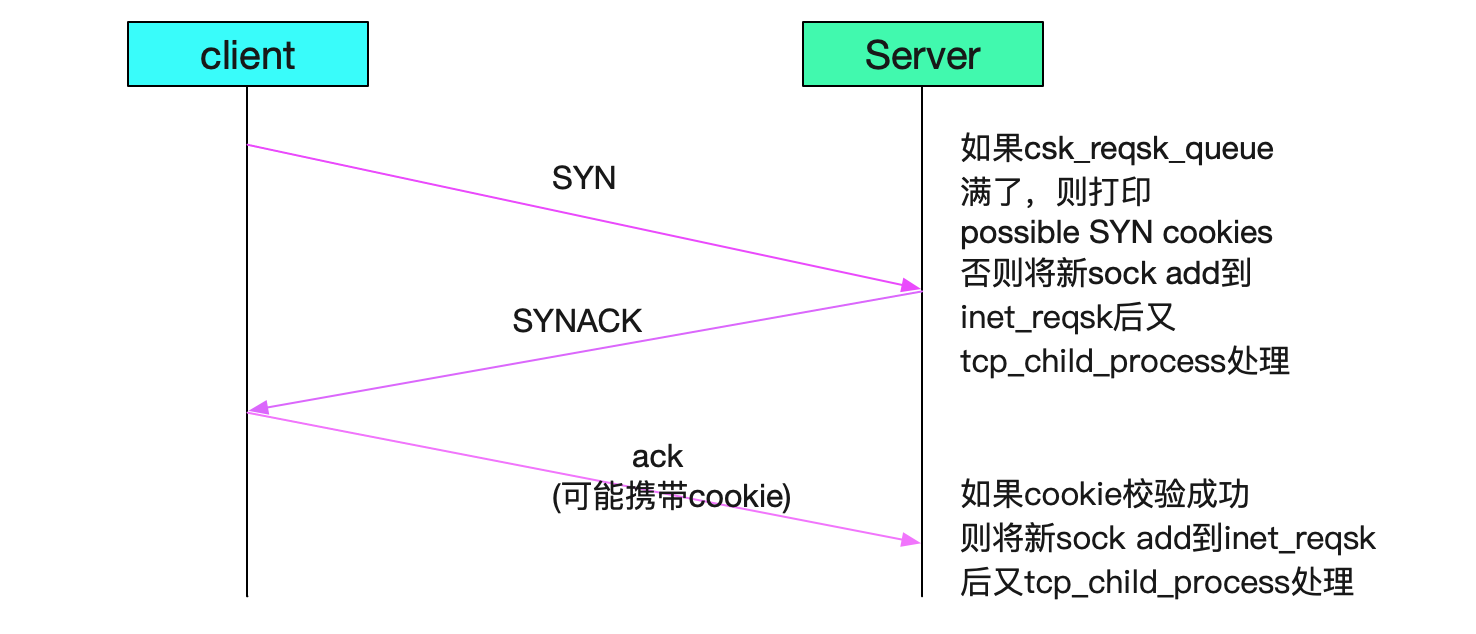
tcp_check_req
上面分析完大致的tcp三次握手代码逻辑之后,我们现在看看造成本文问题现象的核心分支tcp_check_req,这个是在对应的req被放到inet_csk_reqsk(即不需要cookie或者cookie校验成功)后才能执行到这一句,源码如下:
// 下边是client ack回来后的处理过程
// 笔者为了简单起见,我们省略cookie校验的逻辑
struct sock *tcp_check_req(......){
/* 各种处理,各种校验 */
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
// 如果syn_recv_sock返回空,则跳到listen_overflow
if (child == NULL)
goto listen_overflow;
......
listen_overflow:
// 如果没有设置tcp_abort_on_overflow则设置acked=1
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}}
// 增加内核统计参数
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_EMBRYONICRSTS);
// 如果设置了tcp_abort_on_overflow则发送reset报文
if (!(flg & TCP_FLAG_RST))
req->rsk_ops->send_reset(sk, skb);
// 同时将当前sock从csk_reqsk中删除,即当client端下次报文过来的时候,无法找到
// 对应的csk_reqsk
inet_csk_reqsk_queue_drop(sk, req, prev);
return NULL;
如果进了listen_overflow分支,server端会有两种现象,一个是直接将acked设置为1(仅设置标识不发送ack),另一个是发送ack。这两个分支都会把对应的req从reqsk_queue中删除。下图就是走了listen_overflow后不同分之,三次握手的情况:
不设置tcp_abort_on_overflow

设置tcp_abort_on_overflow
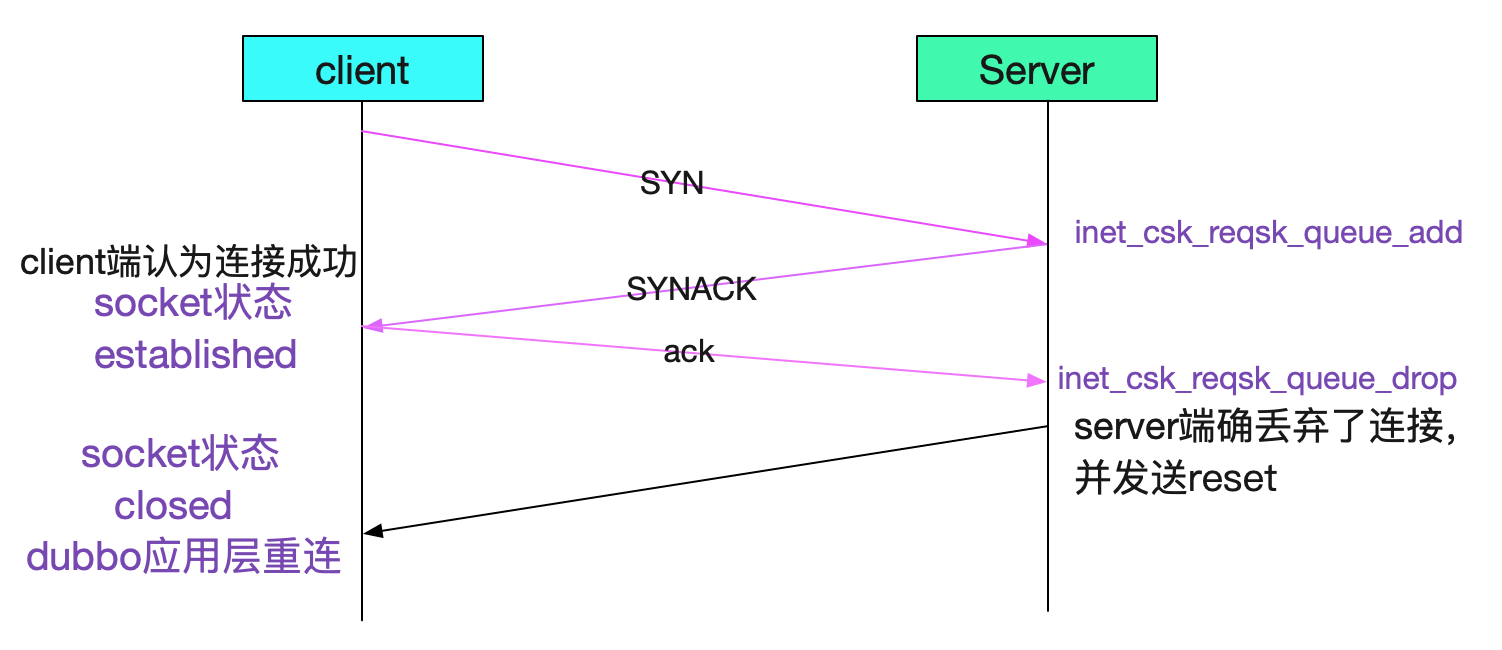
由上面看出设置了tcp_abort_on_overflow会在三次握手之后立马置为closed状态,二不设置tcp_abort_on_overflow会等第一个请求发出来的时候才会知道这个连接其实已经被server端丢弃了。
什么时候listen_overflow
看上面的代码,即在syn_recv_sock返回null的时候,会到listen_overflow,对应的tcp协议的函数为:
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst){
....
if (sk_acceptq_is_full(sk))
goto exit_overflow;
......
}
sk_acceptq_is_full里面判断full的队列长度是下面这三个参数中的最小值:
取三者中的最小值
/proc/sys/inet/ipv4/tcp_max_syn_backlog
/proc/sys/net/core/somaxconn
tcp listen函数调用时候传入的back_log
限于篇幅,就不给出这里判断队列是否为full的源码了。
修复方案
设置kernel参数
一开始笔者仅仅在server端设置了下面这三个参数(天真的以为dubbo考虑到了backlog,设置了一个较大的数值,其实其用了jdk默认的50)
注意,这边511是根据redis的建议值设置的
/proc/sys/inet/ipv4/tcp_max_syn_backlog 511
/proc/sys/net/core/somaxconn 511
/proc/sys/net/ipv4/tcp_abort_on_overflow 1
发现依旧有Close old netty client这样的错误日志,但是业务方确告诉笔者已经没有上线流量损失的情况了。笔者上去观察了一下情况,发现没有流量损失是由于如上图所述reset报文立马发回来,导致能够出错的时间窗口缩小为2s,而不是之前的第一笔必报错,2s内由于没有任何请求,所以大大减少了出错概率。如下图所示:

而创建连接和close old netty client日志的间隔都是小于等于两秒也证明了tcp_abort_on_overflow生效了
dubbo代码增加backlog的设置
由于dubbo用的是jdk默认的backlog(50),所以笔者在dubbo源码对应的部分做了调整,如下代码所示:
public class NettyServer extends AbstractServer implements Server {
......
protected void doOpen() throws Throwable {
...
// 可以从jvm参数中动态调整这个backlog
String backlog = System.getProperty(BACK_LOG_KEY);
if(StringUtils.isEmpty(backlog)){
// 默认为2048,这边调大点,反正改内核参数是即时生效的
backlog = DEFAULT_BACK_LOG;
}
bootstrap.setOption("backlog",backlog);
......
}
}
将这个修改过的dubbo版本给业务方(server端)用了以后,再也没有对应的报错日志了,dubbo上线也平滑了。
总结
事实上,从开始分析问题到猜测要调整backlog所花费的时间并不长。但是笔者喜欢把所有的细节和自己的猜想一一印证,通过源码分析出来的过程图景能够将所有的问题现象全部解释,是一件很爽快的事情。
公众号
关注笔者公众号,获取更多干货文章:

解Bug之路-dubbo流量上线时的非平滑问题的更多相关文章
- 解Bug之路-dubbo应用无法重连zookeeper
前言 dubbo是一个成熟且被广泛运用的框架.饶是如此,在某些极端条件下基于dubbo的应用还会出现无法重连zookeeper的问题.由于此问题容易导致比较大的故障,所以笔者费了一番功夫去定位,现将排 ...
- 解Bug之路-Nginx 502 Bad Gateway
解Bug之路-Nginx 502 Bad Gateway 前言 事实证明,读过Linux内核源码确实有很大的好处,尤其在处理问题的时刻.当你看到报错的那一瞬间,就能把现象/原因/以及解决方案一股脑的在 ...
- 解Bug之路-记一次线上请求偶尔变慢的排查
解Bug之路-记一次线上请求偶尔变慢的排查 前言 最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章. Bug现场 这是一个偶发的性能问题.在每天几百万比交易请求中,平均 ...
- 解Bug之路-ZooKeeper集群拒绝服务
解Bug之路-ZooKeeper集群拒绝服务 前言 ZooKeeper作为dubbo的注册中心,可谓是重中之重,线上ZK的任何风吹草动都会牵动心弦.最近笔者就碰到线上ZK Leader宕机后,选主无法 ...
- 解Bug之路-TCP粘包Bug
解Bug之路-TCP粘包Bug - 无毁的湖光-Al的个人空间 - 开源中国 https://my.oschina.net/alchemystar/blog/880659 解Bug之路-TCP粘包Bu ...
- 解Bug之路-记一次中间件导致的慢SQL排查过程
解Bug之路-记一次中间件导致的慢SQL排查过程 前言 最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,正好博客也好久不更新了,就以此为素材写出了本篇文章 ...
- 解Bug之路-记一次存储故障的排查过程
解Bug之路-记一次存储故障的排查过程 高可用真是一丝细节都不得马虎.平时跑的好好的系统,在相应硬件出现故障时就会引发出潜在的Bug.偏偏这些故障在应用层的表现稀奇古怪,很难让人联想到是硬件出了问题, ...
- 解Bug之路-串包Bug
解Bug之路-串包Bug 笔者很热衷于解决Bug,同时比较擅长(网络/协议)部分,所以经常被唤去解决一些网络IO方面的Bug.现在就挑一个案例出来,写出分析思路,以飨读者,希望读者在以后的工作中能够少 ...
- 解Bug之路-NAT引发的性能瓶颈
解Bug之路-NAT引发的性能瓶颈 笔者最近解决了一个非常曲折的问题,从抓包开始一路排查到不同内核版本间的细微差异,最后才完美解释了所有的现象.在这里将整个过程写成博文记录下来,希望能够对读者有所帮助 ...
随机推荐
- DEX文件解析--4、dex类的类型解析
一.前言 前几篇系列文章链接: DEX文件解析---1.dex文件头解析 DEX文件解析---2.Dex文件checksum(校验和)解析 DEX文件解析--3.dex文件 ...
- SpringBoot系列之Elasticsearch极速入门与实际教程
@ 目录 一.什么Elasticsearch? 二.Elasticsearch安装部署 2.1 Elasticsearch安装环境准备 2.2 Docker环境安装Elasticsearch 2.3 ...
- Python Ethical Hacking - VULNERABILITY SCANNER(1)
HTTP REQUESTS BASIC INFORMATION FLOW The user clicks on a link. HTML website generates a request(cli ...
- python-多任务编程03-迭代器(iterator)
迭代器是一个可以记住遍历的位置的对象.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 可迭代对象(Iterable) 能够被循环遍历(迭代)的对象称为可迭代 ...
- 【Logisim实验】构建立即数-随机存储器-寄存器的传送
关于Logisim Logisim在仿真软件行列中算是比较直观的软件了,它能做的事情有很多,唯一不足的是硬件描述语言的支持,总体上来说适合比较底层的仿真,依赖于Hex值,通过线路逻辑设计能够较好的 关 ...
- 风速风向 UV 相互转换
这里以c#为例将风的uv分量转成风向风速(别的语言类似) 风向是以y轴正方向为零度顺时针转 UV转风速风向 1 double v ;//v分量 2 double u;//u分量 3 double fx ...
- pandas_数据拆分与合并
import pandas as pd import numpy as np # 读取全部数据,使用默认索引 data = pd.read_excel(r'C:\Users\lenovo\Deskto ...
- 面试官你好,我已经掌握了MySQL主从配置和读写分离,你看我还有机会吗?
我是风筝,公众号「古时的风筝」,一个简单的程序员鼓励师. 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在里面. 面试官:我看你简历上写的你们公司数据库是 ...
- 12-21 Request庫
- PHP fileinode() 函数
定义和用法 fileinode() 函数返回指定文件的 inode 编号. 如果成功,该函数返回指定文件的 inode 编号.如果失败,则返回 FALSE. 语法 fileinode(filename ...