深入理解linux-free命令原理(2)
linux free 命令用法说明
free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。

如果加上 -h 选项,输出的结果会友好很多:

有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数:
$ free -h -s 3
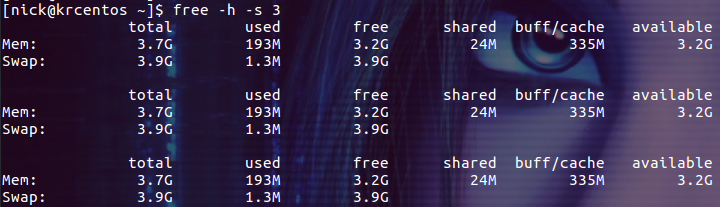
上面的命令每隔 3 秒输出一次内存的使用情况,直到你按下 ctrl + c。
(Ubuntu 16.04 中默认的 free 版本有 bug,使用 -s 选项时报错,所以这张图是在 CentOS 中截的。)
由于 free 命令本身比较简单,所以本文的重点会放在如何通过 free 命令了解系统当前的内存使用状况。
输出简介
下面先解释一下输出的内容:
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
我想只有在理解了一些基本概念之后,上面的输出才能帮助我们了解系统的内存状况。
buff/cache
先来提一个问题: buffer 和 cache 应该是两种类型的内存,但是 free 命令为什么会把它们放在一起呢?要回答这个问题需要我们做些准备工作。让我们先来搞清楚 buffer 与 cache 的含义。
buffer 在操作系统中指 buffer cache, 中文一般翻译为 "缓冲区"。要理解缓冲区,必须明确另外两个概念:"扇区" 和 "块"。扇区是设备的最小寻址单元,也叫 "硬扇区" 或 "设备块"。块是操作系统中文件系统的最小寻址单元,也叫 "文件块" 或 "I/O 块"。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示(下图来自互联网):
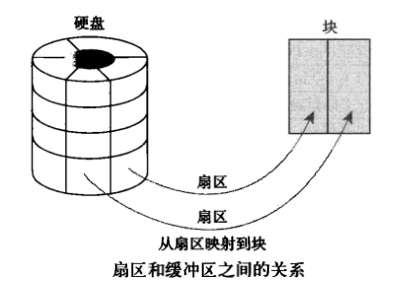
注意,buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而不关心块中究竟存放的是什么格式的文件。
cache 在操作系统中指 page cache,中文一般翻译为 "页高速缓存"。页高速缓存是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面。缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache 呀)和内存映射文件的读写。
页高速缓存对普通文件的缓存我们可以这样理解:当内核要读一个文件(比如 /etc/hosts)时,它会先检查这个文件的数据是不是已经在页高速缓存中了。如果在,就放弃访问磁盘,直接从内存中读取。这个行为称为缓存命中。如果数据不在缓存中,就是未命中缓存,此时内核就要调度块 I/O 操作从磁盘去读取数据。然后内核将读来的数据放入页高速缓存中。这种缓存的目标是文件系统可以识别的文件(比如 /etc/hosts)。
页高速缓存对块设备文件的缓存就是我们在前面介绍的 buffer cahce。因为独立的磁盘块通过缓冲区也被存入了页高速缓存(缓冲区最终是由页高速缓存来承载的)。
到这里我们应该搞清楚了:无论是缓冲区还是页高速缓存,它们的实现方式都是一样的。缓冲区只不过是一种概念上比较特殊的页高速缓存罢了。
那么为什么 free 命令不直接称为 cache 而非要写成 buff/cache? 这是因为缓冲区和页高速缓存的实现并非天生就是统一的。在 linux 内核 2.4 中才将它们统一。更早的内核中有两个独立的磁盘缓存:页高速缓存和缓冲区高速缓存。前者缓存页面,后者缓存缓冲区。当你知道了这些故事之后,输出中列的名称可能已经不再重要了。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列。这二者到底有何区别?
free 是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
如果系统的内存不足,则需要根据物理内存的大小来设置交换空间的大小。具体的策略网上有很丰富的资料,这里笔者不再赘述。
/proc/meminfo 文件
其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观:
$ cat /proc/meminfo
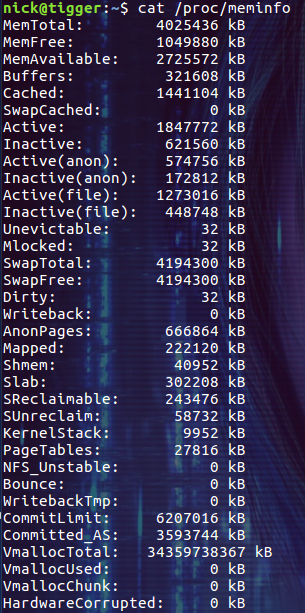
有兴趣的同学可以直接查看这个文件。
总结
free 命令是一个既简单又复杂的命令。简单是因为这个命令的参数少,输出结果清晰。说它复杂则是因为它背后是比较晦涩的操作系统中的概念,如果不清楚这些概念,即便看了 free 命令的输出也 get 不到多少有价值的信息
深入理解linux-free命令原理(2)的更多相关文章
- [转帖]C语言计算时间函数 & 理解linux time命令的输出中“real”“user”“sys”的真正含义
C语言计算时间函数 & 理解linux time命令的输出中“real”“user”“sys”的真正含义 https://blog.csdn.net/willyang519/article/d ...
- [20170705]理解linux su命令.txt
[20170705]理解linux su命令.txt --//我一般在维护时经常使用root用户登录,然后su - oracle 转到其他用户操作--//一般都加入 - 参数.这个已经成了条件反射.. ...
- 理解linux sed命令
理解linux sed命令(2010-02-27 18:21:20) 标签:linuxshellsed替换 分类:革命本钱 1. Sed简介sed是一种在线编辑器,它一次处理一行内容.处理时,把当 前 ...
- 理解linux网络管理命令
linux 管理命令,iproute 查看帮助文件: man ip 以下为常用帮助文件. SEE ALSO ip-address(), ip-addrlabel(), ip-l2tp(), ip-li ...
- 【转帖】linux内存管理原理深入理解段式页式
linux内存管理原理深入理解段式页式 https://blog.csdn.net/h674174380/article/details/75453750 其实一直没弄明白 linux 到底是 段页式 ...
- [转帖]linux中systemctl详细理解及常用命令
linux中systemctl详细理解及常用命令 2019年06月28日 16:16:52 思维的深度 阅读数 30 https://blog.csdn.net/skh2015java/article ...
- linux中systemctl详细理解及常用命令
linux中systemctl详细理解及常用命令 https://blog.csdn.net/skh2015java/article/details/94012643 一.systemctl理解 Li ...
- Linux查找命令:grep,awk,sed
grep grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具 ...
- 理解 Linux 网络栈(2):非虚拟化Linux 环境中的 Segmentation Offloading 技术
本系列文章总结 Linux 网络栈,包括: (1)Linux 网络协议栈总结 (2)非虚拟化Linux环境中的网络分段卸载技术 GSO/TSO/UFO/LRO/GRO (3)QEMU/KVM + Vx ...
随机推荐
- 关闭Win10窗口拖动到桌面边缘自动缩放功能
- MAC下go语言的安装和配置
Mac下安装一些文件都是比较简单的.安装了brew以后,很多的程序只要一条命令就搞定了. brew install go 安装好go语言以后主要是配置go_path,和go_root的地址. go_r ...
- 分享篇:聊一聊 15.5K 的 FileSaver,是如何工作的?
聊一聊 15.5K 的 FileSaver,是如何工作的? FileSaver.js 是在客户端保存文件的解决方案,非常适合在客户端上生成文件的 Web 应用程序.它简单易用且兼容大多数浏览器,被作为 ...
- 第8.6节 Python类中的__new__方法深入剖析:调用父类__new__方法参数的困惑
上节<第8.5节 Python类中的__new__方法和构造方法__init__关系深入剖析:执行顺序及参数关系案例详解>通过案例详细分析了两个方法的执行顺序,不知大家是否注意到了,在上述 ...
- PyQt(Python+Qt)学习随笔:QDateEdit日期编辑部件和QTimeEdit时间编辑部件
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 Designer输入部件中,Date Edit和T ...
- PyQt(Python+Qt)学习随笔:部件拉伸策略sizePolicy优先级
部件的尺寸调整策略或拉伸策略sizePolicy有7个值,如果同一个布局中的不同部件设置了不同的拉伸策略策略,在整个布局空间拉伸时,它们会怎么进行拉伸处理呢? 在未设置拉伸因子的情况下,Qt中这些拉伸 ...
- java视频格式转换
项目中需要对各种视频格式转码为mp4格式,试了好多办法,最后使用ffmpeg 工具完美转码,ffmpeg能解析的格式:(asx,asf,mpg,wmv,3gp,mp4,mov,avi,flv等) 链接 ...
- CSP-S2020 DP专项训练
前言 \(\text{CPS-S2020}\) 已然临近,而 \(\text{DP}\) 作为联赛中的常考内容,是必不可少的复习要点,现根据教练和个人刷题,整理部分好题如下(其实基本上是直接搬--). ...
- CentOS 6.8内核版本升级
1.查看当前版本 [root@www.linuxidc.com docker]# cat /etc/issue CentOS release 6.8 (Final) Kernel \r on an ...
- 转载:c# 获取CPU温度(非WMI,直接读取硬件)
c#获取cpu温度 很早一个项目做远控,所以需要用到获取cpu温度,但是就是不知从何下手,无意中发现了Open Hardware Monitor,令我的项目成功完成 亲测20台清装xp sp2的机器, ...