nginx日志详细说明
Nginx日志主要分为两种:访问日志和错误日志。日志开关在Nginx配置文件(/etc/nginx/nginx.conf)中设置,两种日志都可以选择性关闭,默认都是打开的。
访问日志
访问日志主要记录客户端访问Nginx的每一个请求,格式可以自定义。通过访问日志,你可以得到用户地域来源、跳转来源、使用终端、某个URL访问量等相关信息。Nginx中访问日志相关指令主要有两条:
(1).log_format
log_format用来设置日志格式,也就是日志文件中每条日志的格式,具体如下:
log_format name(格式名称) type(格式样式)
举例说明如下:
log_format main '$server_name $remote_addr -
$remote_user [$time_local] "$request" '
'$status $uptream_status $body_bytes_sent
"$http_referer" '
'"$http_user_agent"
"$http_x_forwarded_for" '
'$ssl_protocol $ssl_cipher $upstream_addr
$request_time $upstream_response_time';
每个样式的含义如下:
$server_name:虚拟主机名称。
$remote_addr:远程客户端的IP地址。
-:空白,用一个“-”占位符替代,历史原因导致还存在。
$remote_user:远程客户端用户名称,用于记录浏览者进行身份验证时提供的名字,如登录百度的用户名scq2099yt,如果没有登录就是空白。
[$time_local]:访问的时间与时区,比如18/Jul/2012:17:00:01 +0800,时间信息最后的"+0800"表示服务器所处时区位于UTC之后的8小时。
$request:请求的URI和HTTP协议,这是整个PV日志记录中最有用的信息,记录服务器收到一个什么样的请求
$status:记录请求返回的http状态码,比如成功是200。
$uptream_status:upstream状态,比如成功是200.
$upstream_addr:后端服务器的IP地址
$upstream_status:后端服务器返回的HTTP状态码
在server{}中添加
add_header backendIP $upstream_addr;
add_header backendCode $upstream_status;
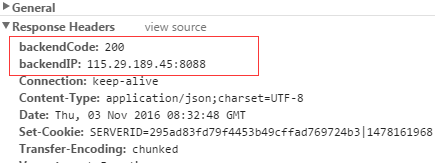
$body_bytes_sent:发送给客户端的文件主体内容的大小,比如899,可以将日志每条记录中的这个值累加起来以粗略估计服务器吞吐量。
$http_referer:记录从哪个页面链接访问过来的。
$http_user_agent:客户端浏览器信息
$http_x_forwarded_for:客户端的真实ip,通常web服务器放在反向代理的后面,这样就不能获取到客户的IP地址了,通过$remote_add拿到的IP地址是反向代理服务器的iP地址。反向代理服务器在转发请求的http头信息中,可以增加x_forwarded_for信息,用以记录原有客户端的IP地址和原来客户端的请求的服务器地址。
$ssl_protocol:SSL协议版本,比如TLSv1。
$ssl_cipher:交换数据中的算法,比如RC4-SHA。
$upstream_addr:upstream的地址,即真正提供服务的主机地址。
$request_time:整个请求的总时间。
$upstream_response_time:请求过程中,upstream的响应时间。
访问日志中一个典型的记录如下:
192.168.1.102 - scq2099yt [18/Mar/2013:23:30:42
+0800] "GET /stats/awstats.pl?config=scq2099yt HTTP/1.1" 200 899
"http://192.168.1.1/pv/" "Mozilla/4.0 (compatible; MSIE 6.0;
Windows XXX; Maxthon)"
需要注意的是:log_format配置必须放在http内,否则会出现如下警告信息:
nginx: [warn] the "log_format"
directive may be used only on "http" level in
/etc/nginx/nginx.conf:97
(2)access_log
access_log指令用来指定日志文件的存放路径(包含日志文件名)、格式和缓存大小,具体如下:
access_log path(存放路径)
[format(自定义日志格式名称) [buffer=size | off]]
举例说明如下:
access_log logs/access.log main;
如果想关闭日志,可以如下:
access_log off;
能够使用access_log指令的字段包括:http、server、location。
需要注意的是:Nginx进程设置的用户和组必须对日志路径有创建文件的权限,否则,会报错。
Nginx支持为每个location指定强大的日志记录。同样的连接可以在同一时间输出到不止一个的日志中。
错误日志
错误日志主要记录客户端访问Nginx出错时的日志,格式不支持自定义。通过错误日志,你可以得到系统某个服务或server的性能瓶颈等。因此,将日志好好利用,你可以得到很多有价值的信息。错误日志由指令error_log来指定,具体格式如下:
error_log
path(存放路径) level(日志等级)
path含义同access_log,level表示日志等级,具体如下:
[ debug | info | notice | warn | error | crit ]
从左至右,日志详细程度逐级递减,即debug最详细,crit最少。
举例说明如下:
error_log logs/error.log info;
需要注意的是:error_log off并不能关闭错误日志,而是会将错误日志记录到一个文件名为off的文件中。
正确的关闭错误日志记录功能的方法如下:
error_log /dev/null;
上面表示将存储日志的路径设置为“垃圾桶”。
nginx日志详细说明的更多相关文章
- Nginx日志增长过快详细分析
前言: Nginx日志里面Mobileweb_access.log增长特别大,一天上百兆,将近100W的访问记录,按照我们目前的规模,热点用户才500个左右,就算人人用手机app访问,怎么可能会有这么 ...
- 烂泥:利用awstats分析nginx日志
本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb 昨天把nginx的日志进行了切割,关于如何切割nginx日志,可以查看<烂泥:切割 ...
- nginx日志分析利器GoAccess
面试的时候一定会被面到的问题是:给出web服务器的访问日志,请写一个脚本来统计访问前10的IP有哪些?访问前10的请求有哪些?当你领略过goaccess之后,你就明白,这些问题,除了考验你的脚本背诵记 ...
- linux shell:nginx日志切割脚本
需求原因:nginx不具备日志切割功能,日志量较大,方便分析. 实现目的:完成nginx日志切割,并根据时间命名 简要命令: mv /usr/local/tengine/logs/access.l ...
- 利用 ELK系统分析Nginx日志并对数据进行可视化展示
一.写在前面 结合之前写的一篇文章:Centos7 之安装Logstash ELK stack 日志管理系统,上篇文章主要讲了监控软件的作用以及部署方法.而这篇文章介绍的是单独监控nginx 日志分析 ...
- nginx日志切割并使用flume-ng收集日志
nginx的日志文件没有rotate功能.如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件.第一步就是重命名日志文件,不用担心重命名后nginx找不到日 ...
- Nginx配置文件nginx.conf详细说明
Nginx配置文件nginx.conf详细说明 #worker_processes 8; #worker_cpu_affinity 00000001 00000010 00000100 0000100 ...
- 【转】Nginx配置文件详细说明
Nginx配置文件详细说明 在此记录下Nginx服务器nginx.conf的配置文件说明, 部分注释收集与网络. #运行用户user www-data; #启动进程,通常设置成和cpu的数量相等 ...
- nginx 日志分割(简单、全面)
Nginx 日志分割 因业务需要做了简单的Nginx 日志分割, 第1章 详细配置如下. #建议在mkdir /home/shell -p 专门写shell 脚本位置 root@localhost ...
随机推荐
- 通过游戏学javascript系列第一节Canvas游戏开发基础
本节教程通过一个简单的游戏小例子,讲解Canvas的基础知识. 最终效果: 点击移动的方块,方块上的分数会增加,方块的行进方向会改变,并且方块的速度会增加. 在线演示 源码 HTML5引入了canva ...
- mysql聚簇索引和非聚簇索引
聚簇索引 InnoDB使用的是聚簇索引 将数据与主键索引放在了一起,索引的叶子节点保存了行数据,找到了主键索引,即找到了行数据. 辅助索引记录了主键的位置,所以查询where name= xxx 时, ...
- C++异常之四 异常类型的生命周期
异常类型的生命周期 1. throw 基本类型: int.float.char 这三种类型的抛出和函数的返回传值类似,为参数拷贝的值传递. 1 int test_1(int num) throw (i ...
- centos 7.5搭建oracle DG
一.背景 1.IP分配 主库:192.168.12.5 node1 备库:192.168.12.6 node2 2.环境 主库已安装数据库软件,已建库,并有业务数据 备库已安装数据库软件,未建库 二. ...
- Excel优雅导出
流程 原来写过一篇文章,是介绍EasyExcel的,但是现在有些业务需要解决,流程如下 1.需要把导出条件转换成中文并存入数据库 2.需要分页导出 3.需要上传FTP或者以后上传OSS 解决方案 大体 ...
- 重写Laravel异常处理类
现在开发前后端分离变得越来越流行了,后端只提供接口返回json格式的数据,即使是错误信息也要以json格式来返回,然而目前无论是Laravel框架还是ThinkPHP框架,都只提供了返回json数据的 ...
- 网络编程-python实现-UDP(1.1.2)
@ 目录 1.UDP是什么 2.代码实现 1.UDP是什么 Internet 协议集支持一个无连接的传输协议,该协议称为用户数据报协议(UDP,User Datagram Protocol).UDP ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- 基于Python实现环形队列高效定时器
定时器Python实现代码 import time import redis import multiprocessing class Base: """ redis配置 ...
- 篇章三:SVN-对文件的操作
添加文件 在检出的工作副本中添加一个Readme文本文件,这时候这个文本文件会显示为没有版本控制的状态,如图: 这时候,你需要告知TortoiseSVN你的操作,如图: 加入以后,你的文件会变成这个状 ...