爬虫入门四 re
title: 爬虫入门四 re
date: 2020-03-14 16:49:00
categories: python
tags: crawler
正则表达式与re库
1 正则表达式简介
编译原理学过的
正则表达式(Regular Expression,简写为regex或RE),使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
Python 中导入 :import re
官方参考文档:https://docs.python.org/3/library/re.html
正则表达式元素可以归为字符和操作符,操作符又包含了限定符和定位符
字符: 字符可以代表一个单独的字符,或者一个字符集合构成的字符串。
限定符:允许你在模式中决定字符或者字符串出现的频率。
定位符:允许你决定模式是否是一个独立的单词,或者出现的位置必须在句
子的开头还是结尾。
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
1.1 正则表达式 常用操作符
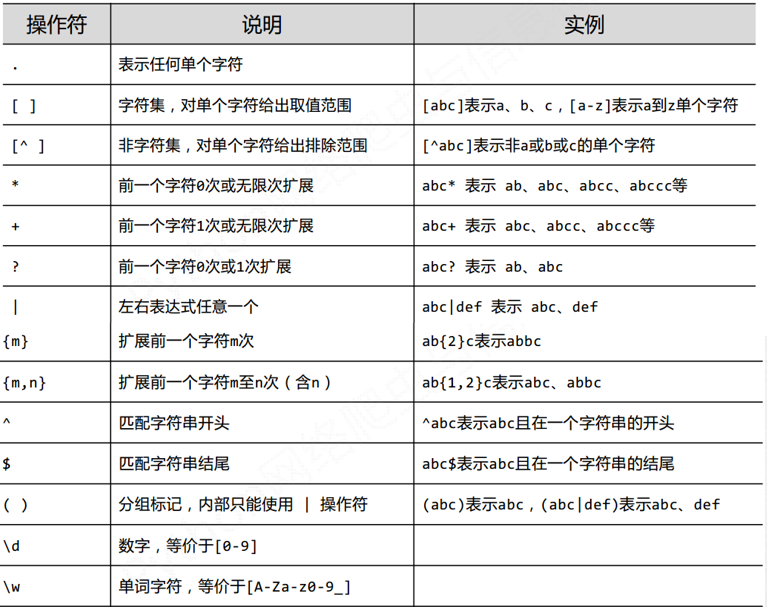
. 表示任何单个字符
[] 字符集,对单个字符给出取值范围 [abc]表示a、b、c, [a-z ]表示a到z单个字符 [\d\.] 表示包含数字和小数点
[^ ] 非字符集,对单个字符给出排除范围 [^abc ]表示非a或b或c的单个字符
* 前一个字符0次或无限次扩展 abc*表示ab、abc、abcc. abccc等
+ 前一个字符1次或无限次扩展 abc+表示abc、abcc、 abccc等
? 前一个字符0次或1次扩展 abc?表示ab、abc
| 左右表达式任意-个 abc|def表示abc、 def
{m} 扩展前一个字符m次 ab{2}c表示abbc
{m,n} 扩展前一个字符m至n次(含n) ab{1, 2}c表示abC、abbc
^ 匹配字符串开头 ^abc表示abc且在一个字符串的开头
$ 匹配字符串结尾 abc$表示abc且在一个字符串的结尾
() 分组标记,内部只能使用|操作符 (abc )表示abc , (abc |def)表示abc、def
\d 数字,等价于[0-9]
\w 单词字符,等价于[A-Za-z0-9]
" 表示转义 "。比如 下面实例淘宝中price":"412.00"
r'"view_price":"[\d.]*"'
[\d.] 表示包含数字和小数点
1.2 re实例
正则表达式在线检查网站:
http://tool.oschina.net/regex/
email地址:
只允许英文字母、数字、下划线、英文句号、以及中划线组成
[1]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$
PY[^TH]?ON 'PYON'、'PYaON'、 ' PYbON'、'PYcON'...
PY{ :3}N 'PN'、 'PYN'、 'PYYN'、 'PYYYN'...
^[A-Za-z]+$ 由26个字母组成的字符串
^[A-Za-z0-9]+$ 由26个字母和数字组成的字符串
^-?\d+$ 整数形式的字符串
^[0-9]*[1-9][0-9]*$ 正整数形式的字符串
[1-9]\d{5} 首位不为0 中国境内邮政编码, 6位
[\u4e00-\u9fa5] 匹配中文字符
\d{3}-\d{8}|\d{4}-\d{7} 国内电话号码, 010-68913536
IP地址字符串形式的正则表达式( IP地址分4段,每段0-255 )
\d+.\d+.\d+.\d+或\d{1,3}. \d{1,3}.\d{1,3}. \d{1,3}
精确写法
0-99: [1-9]?\d
100-199: 1\d{2}
200-249: 2[0-4]\d
250-255: 25[0-5]
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
2 re库
2.1 re库中正则式的使用
re库采用raw string(原生字符串)类型表示正则表达式,表示为:
r'text'
例如: r'[1‐9]\d{5}'
r'\d{3}‐\d{8}|\d{4}‐\d{7}'
>>> import re
>>> m=re.search(r'[0-9]','wu1han2')
>>> print(m.group(0))
可以得到返回结果:1
2.2 re库常用功能函数
re. search( )
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
re. match( )
从一个字符串的开始位置起匹配正则表达式,返回match对象
re. findall()
搜索字符串,以列表类型返回全部能匹配的子串
re. split( )
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re. finditer( )
搜索字符串,返回-一个匹配结果的迭代类型,每个迭代元素是match对象
re.sub( )
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
2.2.1 re.search()
re.search(pattern, string, flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置
pattern : 正则表达式的字符串或原生字符串表示
string : 待匹配字符串
flags : 正则表达式使用时的控制标记
re.I re. IGNORECASE
忽略正则表达式的大小写, [A- Z]能够匹配小写字符
re.M re . MULTILINE
正则表达式中的^操作符能够将给定字符串的每行当作匹配开始
re.S re. DOTALL
正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符
2.2.2 re.match()
re.match(pattern, string, flags=0)
从一个字符串的开始位置起匹配正则表达式
import re
search=re.search(r'[1-9]\d{5}','WuHan 430073')
match1=re.match(r'[1-9]\d{5}','WuHan 430073')
match2=re.match(r'[1-9]\d{5}','430073 WuHan')
print("search结果")
if search:
print(search.group(0))
print("\nmatch1结果")
if match1:
print(match1.group(0))
else:
print("未匹配到结果")
print("\nmatch2结果")
if match2:
print(match2.group(0))
上面输出
430073
未匹配
430073
2.2.3 re.findall .finditer
re.findall(pattern, string, flags=0)
搜索字符串,以列表类型返回全部能匹配的子串
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个匹配结果的迭代类型,每个结果为match对象
import re
findall=re.findall(r'[1-9]\d{5}','WuHan 430073 Beijing 100010')
print("findall匹配结果")
if findall:
print(findall)
print("finditer匹配结果")
for m in re.finditer(r'[1-9]\d{5}','WuHan 430073 Beijing 100010'):
if m:
print(m.group(0))
# 输出
[430073,100010]
430073
100010
2.2.4 re.split()
re.split(pattern, string, maxsplit=0,flags=0)
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
pattern : 正则表达式的字符串或原生字符串表示
string : 待匹配字符串
maxsplit: 最大分割数,剩余部分作为最后一个元素输出
flags : 正则表达式使用时的控制标记
就是把pattern当做分隔符
import re
split1=re.split(r'[1-9]\d{5}','WuHan 430073 Beijing 100010')
split2=re.split(r'[1-9]\d{5}','WuHan 430073 Beijing 100010',maxsplit=1)
print("split1分割结果")
print(split1)
print("split2分割结果")
print(split2)
split1分割结果
['WuHan ', ' Beijing ', '']
split2分割结果
['WuHan ', ' Beijing 100010']
2.2.5 re.sub
re.sub(pattern, repl, string, count=0, flags=0)
在一个字符串中替换所有匹配正则表达式的子串返回替换后的字符串
pattern : 正则表达式的字符串或原生字符串表示
repl : 替换匹配字符串的字符串
string : 待匹配字符串
count : 匹配的最大替换次数
flags : 正则表达式使用时的控制标记
sub = re.sub(r'[1-9]\d{5}', '123456', 'WuHan 430073 Beijing 100010')
print("替换结果")
print(sub)
替换结果
WuHan 123456 Beijing 123456
2.3 re库面向对象用法
regex = re.compile(pattern, flags=0)
pattern : 正则表达式的字符串或原生字符串表示
flags : 正则表达式使用时的控制标记
regex = re.compile(r‘[1‐9]\d{5}’)
将正则表达式的字符串形式编译成正则表达式对象,编译后,可进行多次操作
如下,就相当于用pat代表了这个re,方便了书写
pat = re.compile(r'[1-9]\d{5}')
a = pat.search('wuhan430073')
print("搜索结果")
print(a)
b = pat.sub('...','bj100010 wh430073')
print("替换结果")
print(b)
搜索结果
<re.Match object; span=(5, 11), match='430073'>
替换结果
bj... wh...
这里regex就算自定义的对象,如上面的pat.search()
regex. search( )
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
regex. match( )
从一个字符串的开始位置起匹配正则表达式,返回match对象
regex . findall()
搜索字符串,以列表类型返回全部能匹配的子串
regex.split()
将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
regex. finditer()
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
regex. sub( )
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
2.4 re库的match对象
match对象包含了关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
.string
待匹配的文本
.re
匹配时使用的patter对象(正则表达式)
.pos
正则表达式搜索文本的开始位置 就是待匹配串从哪里开始搜索
.endpos
正则表达式搜索文本的结束位置 就是待匹配串从哪里借结束搜索,比如19,说明搜索到18(含18)
.group(0)
获得匹配后的字符串
.start()
匹配字符串在原始字符串的开始位置
.end()
匹配字符串在原始字符串的结束位置
.span()
返回(.start(), .end()
for m in re.finditer(r'[1-9]\d{5}', 'WuHan 430073 Beijing 100010'):
if m:
print(m.group(0))
print(m.pos)
print(m.endpos)
print(m.start())
print(m.end())
print(m.span())
123456
430073
0
28
6
12
(6, 12)
100010
0
28
22
28
(22, 28)
2.5 re库的贪婪匹配,最小匹配
match = re. search(r'PY.*N', ' PYANBNCNDN' )
match. group(0)
同时匹配长短不同的多项,返回哪个呢?(PYAN PYANBN PYANBNCN ...)
结果:
'PYANBNCNDN'
Re库默认采用贪婪匹配,即输出匹配最长的子串
如何输出最短的子串呢?
match = re. search(r'PY.*?N', ' PYANBNCNDN' )
match. group(0)
'PYAN '
只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配
*? 前一个字符0次或无限次扩展,最小匹配
+? 前一个字符1次或无限次扩展,最小匹配
?? 前一个字符0次或1次扩展,最小匹配
{m,n}? 扩展前一个字符m至n次(含n),最小匹配
3 实例一 淘宝商品定向爬虫
3.1 url的确定
第二页:
https://s.taobao.com/search?q=键盘&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
第三页:
https://s.taobao.com/search?q=键盘&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
观察发现:
每页44个商品。
然后
&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48
&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306
这些信息不用,比如
https://s.taobao.com/search?q=键盘&s=44
%E9%94%AE%E7%9B%98 是搜索的物品。
就可以访问第二页
这里我不清楚,可能是是这些是类似时间戳一类的信息,调用的参数等待??,不明白
第一页可以直接https://s.taobao.com/search?q='goods'访问。
所以url的有效部分就是
https://s.taobao.com/search?q= &s=
https://s.taobao.com/search?q='goods'&s='str(44 * i)'
goods = '键盘'
depth = 3
start_url = 'https://s.taobao.com/search?q='+ goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i)
3.2 商品价格和名称
然后找到商品和价格格式
这里用查看源代码,而不是检查搜索一款键盘的价格//名字
"raw_title":"黑爵AK35i机械键盘青轴黑轴茶轴吃鸡宏电竞"
"view_price":"812.42"
可见格式,用re表达
plt = re.findall(r'"view_price":"[\d.]"', html)
tlt = re.findall(r'"raw_title":".?"', html)
然后,对搜索结果进行分割,以“:”为分割点,价格和格式,为分割点后的内容
添加至列表中
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
eval():将字符串当成有效的表达式来求值并返回计算结果
增加eval()后,返回结果无引号
"99.12"->99.12
3.3 code
步骤1:提交商品搜索请求,循环获取页面
getHTMLText()
步骤2:对于每个页面,提取商品名称和价格信息
parsePage()
步骤3:将信息输出到屏幕上
printGoodsList()
# 淘宝商品定向爬虫,序号,价格,名称
# 问题是在getHTMLText的时候需要登录。待解决。(用cookie,request.session更新cookie?)
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
#print(r.text)
return r.text
except:
print("gethtmlfailed")
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("parsePagefailed")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods ="键盘"
depth = 3
start_url = 'https://s.taobao.com/search?q='+ goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
if __name__=='__main__':
main()
3.4 问题
跑不出来,发现淘宝需要登录。
网络上有一些模拟登陆的方法。
需要request.session
4 实例二 股票信息定向爬取 找寻爬取网址
4.1 问题
实例代码不知道是什么时候的了,股市通web版都倒了
下面的内容看看就好
4.2 可视化进度,处理个别情况
在爬取到个股信息后,需要将其写入文件中,
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
由于爬取数据量大,爬取速度较慢,为了方便用户看到爬取进度,可以定义全局变量count,每爬取一支个股后count=count+1 。总进度为count除以list的长度。
为了显示更新效果,可以在print内容中加入”\r”
使新打印的一行,冲掉之前旧的一行,达到显示进度不断增大的效果。
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="")
同时,使用try:
***
except:
continue
的结构,使个别爬取结果空时不会影响总的爬取过程
4.3 编码加速
在获取HTML时,用到了r.encoding= r.apparent_encoding
r.apparent_encoding需要分析文本,因此运行较慢
因此,当已知目标网页的编码的方式时,可以直接定义code=“编码方式“
令r.encoding = code
通过查看东方财富网的源码,
head中获取到它的编码方式为“gb2312”
而百度股市通编码方式为“utf-8”
优化后爬取速度仍然较慢,因此,当爬取较大数据量的网页信息时,可采取多线程技术、或使用更适合大规模数据爬取的scrapy框架
4.4 股票标号
查看东方财富网网页源码,可以看到,股票标号可以在a标签的href值中找到
用BeautifulSoup的find_all方法找到所有a标签,得到href中的内容,
再使用正则表达式,找到:
以s开头,第二个字母为h或者z之后是六位数字 // sh 上海 sz 深圳
正则表达式为:r"[s][hz]\d{6}“
的对象加入到lst中
4.5 updata split
根据股票列表逐个到百度股票获取个股信息
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
查看个股网页源码
可以看出,股票信息都在class为stock-bets的
div标签下,将其存入stockinfo:
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
股票名存储在class为bets-name的
name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
update()方法语法:dict.update(dict2),把字典dict2的键/值对更新到dict里。
split():当不带参数时以空格进行分割,当代参数时,以该参数进行分割。
4.6 key-value
股票当日数值均在
- 标签的
- 标签中,而这些数值的含义,均在
- 标签的
- 标签中。
因此,可以构建多组键值对:
keyList = stockInfo.find_all(‘dt’) #键
valueList = stockInfo.find_all(‘dd’) #值
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val #将这对键值对存入字典中4.7 code
#CrawBaiduStocksB.py # 这个例子不知道是啥时候的了,股市通web都倒了(哭腔)
#可以换成同花顺?
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return "" def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0 #进度
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)))
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)))
continue def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist = []
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file) main()
a-zA-Z0-9_- ︎
- 标签中。
爬虫入门四 re的更多相关文章
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 爬虫入门(四):urllib2
主要使用python自带的urllib2进行爬虫实验. 写在前面的蠢事:本来新建了一个urllib2.py便于好认识这是urllib2的实验,结果始终编译不通过,错误错误.不能用Python的关键字( ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
随机推荐
- SAP GUI用颜色区分不同的系统
对于经常打开多个窗口的SAP用户,有时候可能同时登录了生产机.测试机和开发机,为了避免误操作,比如在测试要执行的操作,结果在生产机做了,结果可想而知. 虽然可以通过右下角查看再去判断,但是总是没有通过 ...
- Sgu149 Computer Network
Sgu149 Computer Network 题目描述 给你一棵N(N<=10000)个节点的树,求每个点到其他点的最大距离. 不难想到一个节点到其他点的最大距离为:max(以它为根的子树的最 ...
- 入门OJ:亲戚
题目描述 或许你并不知道,你的某个朋友是你的亲戚.他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子.如果能得到完整的家谱,判断两个人是否亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代, ...
- DockerFile关键字相关作用以及解释
Dockerfile 关键字 作用 备注 FROM 指定父镜像 指定dockerfile基于那个image构建 MAINTAINER 作者信息 用来标明这个dockerfile谁写的 LABEL 标签 ...
- TCP三次握手Linux源码解析
TCP是面向连接的协议.面向连接的传输层协议在原点和重点之间建立了一条虚拟路径,同属于一个报文的所有报文段都沿着这条虚拟路径发送,为整个报文使用一条虚拟路径能够更容易地实施确认过程以及对损伤或者丢失报 ...
- Spring之 IOC&依赖注入
0x01.Spring 1什么是Spring Spring 是一个开源框架,是为了解决企业应用程序开发复杂性而创建的(解耦). 框架的主要优势之一就是其分层架构,分层架构允许您选择使用哪一个组 ...
- JavaScript小案例-阶乘!
JavaScript小案例-阶乘! 阶乘:就是像台阶一样一阶一阶的,从高阶到低阶,依次乘下来!代码超少!容易理解! // factorial 阶乘 // 如果 function factorial(n ...
- win server 2019服务器的iis配置以及网站的简单发布
1.首先远程连接到服务器 2.打开服务器管理器 3添加角色和功能 4.安装类型:选择基于角色或基于功能的安装 →服务器角色:从服务器池中选择服务器 5.服务器角色选择Web服务器(iis) 6.功能 ...
- mysqldump导出数据库导入数据库
使用mysqldump命令导出数据库,格式如下,请按实际要求对参数进行替换: mysqldump -u 用户名 -p 数据库名 > 导出的文件名 比如导出数据库business_db: mysq ...
- Java 常见关键字总结:final、static、this、super!
final,static,this,super 关键字总结 final 关键字 final关键字,意思是最终的.不可修改的,最见不得变化 ,用来修饰类.方法和变量,具有以下特点: final修饰的类不 ...