图解JanusGraph系列 - JanusGraph指标监控报警(Monitoring JanusGraph)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~
图数据库文章总目录:
- 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录
源码分析相关可查看github(
码文不易,求个star~): https://github.com/YYDreamer/janusgraph
转载文章请保留以下声明:
作者:洋仔聊编程、微信公众号:匠心Java、原文地址:https://liyangyang.blog.csdn.net/
正文
JanusGraph框架提供了一些可监控的指标,用于我们在使用janus图数据库时可以对一些指标进行监控,下面我们看下如何配置使用Janusgraph监控!
本文主要讲解了3部分:
- 监控的指标类型和配置
- 监控指标数据展示存储的位置(Reporter)
- 实战应用案例,并对打印出的指标进行了分析
- 最后给出一个监控设计的架构图
一:监控的底层实现
JanusGraph通过支持Metrics来实现指标数据收集,什么是Metrics?
Metrics是框架Dropwizard提供的一个lib包,主要用于项目指标的收集作用,JanusGraph就是基于Metrics这个组件开发的指标收集模块;
Dropwizard是一个Java框架,用于开发对操作友好的高性能RESTful Web服务,将来自Java生态系统的稳定,成熟的库汇集到一个简单的程序包中,使我们可以专注于完成工作。
Dropwizard对复杂的配置,应用程序指标,日志记录,操作工具等提供了开箱即用的支持;
二:JanusGraph中的指标
JanusGraph可以收集以下指标:
- begin,commit和 roll back的事务数
- 每种存储后端操作类型的 请求次数 和 失败次数
- 每种存储后端操作类型的响应时间分布
2.1 配置指标收集
要启用指标标准收集,需要在JanusGraph的属性文件中设置以下内容:
# Required to enable Metrics in JanusGraph
metrics.enabled = true
此设置使JanusGraph在运行时使用计时器、计数器、直方图等Metrics类记录测量结果。
自定义默认指标名称
默认情况下,JanusGraph为所有度量标准名称添加“ org.janusgraph”前缀。可以通过metrics.prefix配置属性设置此前缀。例如,将默认的“ org.janusgraph”前缀缩短为“ janusgraph”:
# Optional
metrics.prefix = janusgraph
特定事务指标名称
每个JanusGraph事务都可以选择指定其自己的指标名称前缀,从而覆盖默认的指标名称前缀和 metrics.prefix配置属性。例如,可以将前缀更改为打开JanusGraph事务的前端应用程序的名称。
请注意,Metrics在内存中维护度量标准名称及其相关对象的ConcurrentHashMap,因此,保持不同度量标准前缀的数量较小可能是个好主意。
下面使用案例:
JanusGraph graph = ...; // 获取图实例连接
TransactionBuilder tbuilder = graph.buildTransaction(); // 开启一个事务构建器
JanusGraphTransaction tx = tbuilder.groupName("foobar").start(); // 开启一个事务,并开启指标收集,Metrics前缀为foobar
下面为groupName的方法定义:
* Sets the name prefix used for Metrics recorded by this transaction. If
* metrics is enabled via {@link GraphDatabaseConfiguration#BASIC_METRICS},
* this string will be prepended to all JanusGraph metric names.
*
* @param name Metric name prefix for this transaction
* @return Object containing transaction prefix name property
*/
TransactionBuilder groupName(String name);
分开指标统计
JanusGraph在默认情况下组合了其各种内部存储后端句柄的指标,也就是说:会将所有的操作统一收集为一种类型指标;
存储后端交互的所有指标标准都遵循“ <prefix> .stores.<opname>”模式,无论它们是否是idStore,edgeStore的操作等;
如果想要分开每种操作类型收集的指标,配置以下参数:
metrics.merge-basic-metrics = false
metrics.merge-basic-metrics = false在JanusGraph的属性文件中进行设置时,指标标准名称“stores”将被替换为对应“ idStore”,“ edgeStore”,“ vertexIndexStore”或“ edgeIndexStore”,如下述:
<prefix>.idStore.<opname>
<prefix>.edgeStore.<opname>
<prefix>.vertexIndexStore.<opname>
<prefix>.edgeIndexStore.<opname>
2.2 配置指标报告
要访问这些收集好的指标值,必须配置一个或多个Metrics的Reporting; 也就是说配置一个或多个指标的输出存储的位置;
JanusGraph 支持下述的这7种 Metrics reporters:
- Console
- CSV
- Ganglia
- Graphite
- JMX
- Slf4j
- User-provided/Custom
每种reporter类型独立于其他reporter,并且可以共存。
例如,可以将Ganglia、JMX和Slf4j Metrics报告器配置为同时运行,只需在janusgraph.properties中设置它们各自的配置键即可(并启用metrics.enabled = true)
Console Reporter
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.console.interval | 是 | 将指标转储到控制台之间需要等待的毫秒数 | 空值 |
示例janusgraph.properties片段,每分钟将指标输出到控制台一次:
metrics.enabled = true
# Required; specify logging interval in milliseconds
metrics.console.interval = 60000
CSV文件 Reporter
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.csv.interval | 是 | 写入CSV行之间需要等待的毫秒数 | 空值 |
| metrics.csv.directory | 是 | 写入CSV文件的目录(如果不存在则将创建) | 空值 |
示例janusgraph.properties片段,每分钟将CSV文件写入一次到目录./foo/bar/(相对于进程的工作目录):
metrics.enabled = true
# Required; specify logging interval in milliseconds
metrics.csv.interval = 60000
metrics.csv.directory = foo/bar
Ganglia Reporter
注意
由于Ganglia的LGPL许可与JanusGraph的Apache 2.0许可冲突,因此配置Ganglia需要一个附加的库,该库未与JanusGraph一起打包。要使用Ganglia监视运行,请org.acplt:oncrpc从此处下载 jar 并将其复制到JanusGraph/lib目录,然后再启动服务器。
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.ganglia.hostname | 是 | 将指标发送到的单播主机或多播组 | 空值 |
| metrics.ganglia.interval | 是 | 发送数据报之间等待的毫秒数 | 空值 |
| metrics.ganglia.port | 否 | 我们向其发送指标数据报的UDP端口 | 8649 |
| metrics.ganglia.addressing-mode | 否 | 必须为“unicast”或“multicast” | unicast |
| metrics.ganglia.ttl | 否 | 组播数据报TTL; 忽略单播 | 1个 |
| metrics.ganglia.protocol-31 | 否 | 布尔值 使用Ganglia协议3.1为true,使用3.0为false | true |
| metrics.ganglia.uuid | 否 | 要报告而不是IP:主机名的主机UUID | 空值 |
| metrics.ganglia.spoof | 否 | 覆盖IP:向Ganglia报告的主机名 | 空值 |
示例janusgraph.properties片段,每30秒发送一次单播UDP数据报到默认端口上的localhost:
metrics.enabled = true
# Required; IP or hostname string
metrics.ganglia.hostname = 127.0.0.1
# Required; specify logging interval in milliseconds
metrics.ganglia.interval = 30000
示例janusgraph.properties片段,将单播UDP数据报发送到非默认目标端口,并且还配置报告给Ganglia的IP和主机名:
metrics.enabled = true
# Required; IP or hostname string
metrics.ganglia.hostname = 1.2.3.4
# Required; specify logging interval in milliseconds
metrics.ganglia.interval = 60000
# Optional
metrics.ganglia.port = 6789
metrics.ganglia.spoof = 10.0.0.1:zombo.com
Graphite Reporter
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.graphite.hostname | 是 | 将Graphite纯文本协议数据发送到的IP地址或主机名 | 空值 |
| metrics.graphite.interval | 是 | 将数据推送到Graphite之间需要等待的毫秒数 | 空值 |
| metrics.graphite.port | 否 | Graphite纯文本协议报告发送到的端口 | 2003 |
| metrics.graphite.prefix | 否 | 发送到Graphite的所有度量标准名称前都带有任意字符串 | 空值 |
每分钟将指标发送到192.168.0.1上的Graphite服务器的示例janusgraph.properties片段:
metrics.enabled = true
# Required; IP or hostname string
metrics.graphite.hostname = 192.168.0.1
# Required; specify logging interval in milliseconds
metrics.graphite.interval = 60000
JMX Reporter
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.jmx.enabled | 是 | 布尔型 | false |
| metrics.jmx.domain | 否 | 指标将显示在此JMX域中 | Metrics’s own default |
| metrics.jmx.agentid | 否 | 指标将使用此JMX代理ID报告 | Metrics’s own default |
janusgraph.properties示例片段:
metrics.enabled = true
# Required
metrics.jmx.enabled = true
# Optional; if omitted, then Metrics uses its default values
metrics.jmx.domain = foo
metrics.jmx.agentid = baz
Slf4j Reporter
| 配置键 | 是否必须? | 值 | 默认 |
|---|---|---|---|
| metrics.slf4j.interval | 是 | 将指标转储到记录器之间需要等待的毫秒数 | 空值 |
| metrics.slf4j.logger | 否 | 要使用的Slf4j记录器名称 | "metrics" |
示例janusgraph.properties片段每分钟将一次指标记录到名为的记录器中foo:
metrics.enabled = true
# Required; specify logging interval in milliseconds
metrics.slf4j.interval = 60000
# Optional; uses Metrics default when unset
metrics.slf4j.logger = foo
用户自定义 Reporter
如果上面列出的Metrics报告程序配置选项不足以支持我们当前的业务,JanusGraph提供了一个实用方法来访问单个MetricRegistry实例,该实例保存了它的所有度量;
使用方法如下:
com.codahale.metrics.MetricRegistry janusgraphRegistry =
org.janusgraph.util.stats.MetricManager.INSTANCE.getRegistry();
以这种方式访问janusgraphRegistry的代码可以将非标准报告类型或具有外来配置的标准报告类型附加到janusgraphRegistry。
如果周围的应用程序已经有了度量报告器配置的框架,或者如果应用程序需要JanusGraph支持的报告器类型的多个不同配置的实例,这种方法也很有用。
例如,可以使用这种方法来设置多个Graphite Reporter,而JanusGraph的属性配置仅限于一个Graphite Reporter。
三:实际应用
配置如下:
- 开启指标收集
- 使用
Console Reporter,配置指标打印在Console中,时间间隔为1分钟 - 关闭指标收集
merge操作 - 配置指标收集前缀由默认的
org.janusgraph修改为myprefix
完整具体文件配置如下:
# 其他配置
gremlin.graph=org.janusgraph.core.JanusGraphFactory
storage.backend=hbase
storage.hostname=127.0.0.1
storage.port=2184
storage.hbase.table=testGraph
cache.db-cache=true
cache.db-cache-clean-wait=20
cache.db-cache-time=180000
cache.db-cache-size=0.5
index.search.backend=elasticsearch
index.search.hostname=127.0.0.1
index.search.index-name=search
index.search.port=9200
index.search.elasticsearch.http.auth.type=basic
index.search.elasticsearch.http.auth.basic.username=test
index.search.elasticsearch.http.auth.basic.password=test
query.batch=true
query.batch-property-prefetch=true
# janusgraph监控相关配置
metrics.enabled = true
metrics.prefix = myprefix
metrics.console.interval = 60000
metrics.merge-basic-metrics = false
我们在服务器使用gremlin.sh脚本启动gremlin console,并创建图实例:
./gremlin.sh
graph=JanusGraphFactory.open('/opt/soft/janusgraph-0.5.1-test/conf/janusgraph-hbase-es.properties')
我们就会发现,每隔一分钟就会在控制台打印出对应指标信息,因为指标信息很多,为了便于文章阅读,下述只展示出主要部分:
12/23/20 10:37:28 AM ===========================================================
-- Counters --------------------------------------------------------------------
global.storeManager.openDatabase.calls
count = 20
global.storeManager.startTransaction.calls
count = 461
myprefix.caches.misses
count = 5
// 此处省略部分统计
myprefix.tx.begin
count = 12
myprefix.tx.commit
count = 3
myprefix.tx.rollback
count = 9
org.janusgraph.caches.misses
count = 3
org.janusgraph.caches.retrievals
count = 3
// 此处省略部分统计
org.janusgraph.sys.stores.getSlice.calls
count = 286
org.janusgraph.sys.stores.getSlice.entries-returned
count = 231
org.janusgraph.sys.stores.mutate.calls
count = 7
org.janusgraph.tx.begin
count = 1
-- Histograms ------------------------------------------------------------------
myprefix.stores.getSlice.entries-histogram
count = 7
min = 0
max = 8
mean = 1.57
stddev = 2.88
median = 1.00
75% <= 1.00
95% <= 8.00
98% <= 8.00
99% <= 8.00
99.9% <= 8.00
org.janusgraph.stores.getSlice.entries-histogram // 具体指标统计省略
org.janusgraph.sys.schema.stores.getSlice.entries-histogram // 具体指标统计省略
org.janusgraph.sys.stores.getSlice.entries-histogram // 具体指标统计省略
-- Timers ----------------------------------------------------------------------
myprefix.query.graph.execute.time
count = 2
mean rate = 0.01 calls/second
1-minute rate = 0.01 calls/second
5-minute rate = 0.07 calls/second
15-minute rate = 0.14 calls/second
min = 1.19 milliseconds
max = 2.25 milliseconds
mean = 1.72 milliseconds
stddev = 0.75 milliseconds
median = 1.72 milliseconds
75% <= 2.25 milliseconds
95% <= 2.25 milliseconds
98% <= 2.25 milliseconds
99% <= 2.25 milliseconds
99.9% <= 2.25 milliseconds
myprefix.query.graph.getNew.time // 具体指标统计省略
myprefix.query.graph.hasDeletions.time // 具体指标统计省略
myprefix.query.vertex.execute.time // 具体指标统计省略
myprefix.query.vertex.getNew.time // 具体指标统计省略
myprefix.query.vertex.hasDeletions.time // 具体指标统计省略
myprefix.storeManager.mutate.time // 具体指标统计省略
myprefix.stores.getSlice.time // 具体指标统计省略
myprefix.stores.mutate.time // 具体指标统计省略
org.janusgraph.query.graph.execute.time
count = 2
mean rate = 0.00 calls/second
1-minute rate = 0.00 calls/second
5-minute rate = 0.02 calls/second
15-minute rate = 0.09 calls/second
min = 2.52 milliseconds
max = 221.12 milliseconds
mean = 111.82 milliseconds
stddev = 154.57 milliseconds
median = 111.82 milliseconds
75% <= 221.12 milliseconds
95% <= 221.12 milliseconds
98% <= 221.12 milliseconds
99% <= 221.12 milliseconds
99.9% <= 221.12 milliseconds
org.janusgraph.query.graph.getNew.time // 具体指标统计省略
org.janusgraph.query.graph.hasDeletions.time // 具体指标统计省略
org.janusgraph.stores.getKeys.iterator.hasNext.time // 具体指标统计省略
org.janusgraph.stores.getKeys.iterator.next.time // 具体指标统计省略
org.janusgraph.stores.getKeys.time // 具体指标统计省略 // 具体指标统计省略
org.janusgraph.stores.getSlice.time // 具体指标统计省略
org.janusgraph.sys.schema.query.graph.execute.time // 具体指标统计省略
org.janusgraph.sys.schema.query.graph.getNew.time // 具体指标统计省略
org.janusgraph.sys.schema.query.graph.hasDeletions.time // 具体指标统计省略
org.janusgraph.sys.schema.stores.getSlice.time // 具体指标统计省略
org.janusgraph.sys.storeManager.mutate.time // 具体指标统计省略
org.janusgraph.sys.stores.getSlice.time // 具体指标统计省略
org.janusgraph.sys.stores.mutate.time // 具体指标统计省略
观察上述指标统计数据,我们可以发现,主要分为4大部分:
- 当前统计指标时间,年月日,时间精确到秒
- 统计所有不同操作的数量
Counters - 统计数据直方图的表示
Histograms - 统计所有操作的执行时间
Timers
第一部分:当前统计指标时间,年月日,时间精确到秒
可以作为janusgraph指标监控的横向维度和时间维度
第二部分:统计所有不同操作的数量Counters
这一部分主要用于收集所有操作的总数量,包含事务相关统计、缓存命中相关统计、数据的CURD统计、后端存储不同操作调用统计等48个维度!
具体可以自行尝试;
第三部分:统计数据直方图的表示Histograms
首先,什么是直方图? 直方图,形状类似柱状图却有着与柱状图完全不同的含义。直方图牵涉统计学的概念,首先要对数据进行分组,然后统计每个分组内数据元的数量。 在平面直角坐标系中,横轴标出每个组的端点,纵轴表示频数,每个矩形的高代表对应的频数,称这样的统计图为频数分布直方图
此部分主要涉及对后端存储的统计;
第四部分:统计所有操作的执行时间Timers
这一部分主要收集统计数据CURD操作和数据插入等操作的时间统计包含23种维度!
时间维度包含平均值、最大值、最小值、时间分布等14个时间维度;
四:监控架构图
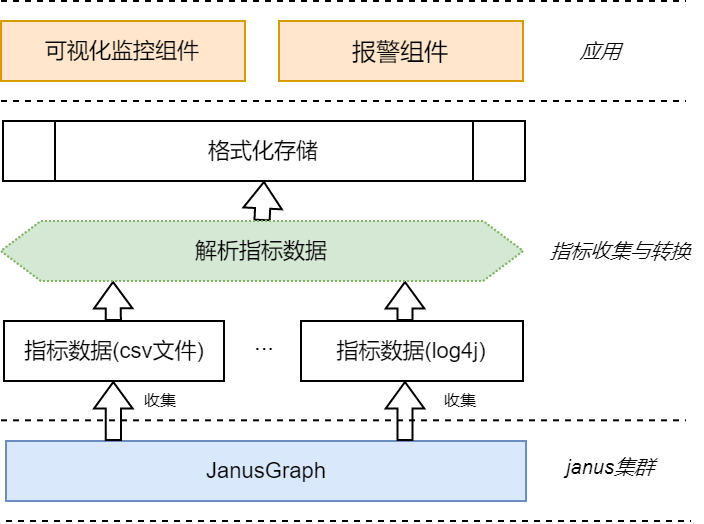
整体分为: 收集指标 --> 解析指标数据 --> 格式化存储 --> 监控组件|报警组件
有任何问题,欢迎交流沟通
参考:JanusGraph官网
图解JanusGraph系列 - JanusGraph指标监控报警(Monitoring JanusGraph)的更多相关文章
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 图解Janusgraph系列-并发安全:锁机制(本地锁+分布式锁)分析
图解Janusgraph系列-并发安全:锁机制(本地锁+分布式锁)分析 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据 ...
- 图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize)
图解Janusgraph系列-图数据底层序列化源码分析(Data Serialize) 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步 ...
- 图解JanusGraph系列 - 关于JanusGraph图数据批量快速导入的方案和想法(bulk load data)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- Kubernetes集群的监控报警策略最佳实践
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/79652064 本文为Kub ...
- Traefik SRE 之使用 Prometheus 进行监控报警
当我们使用 Traefik 作为 Kubernetes 的 Ingress 控制器的时候,我们自然也非常有必要对其进行监控.本文我们将探讨如何使用 Prometheus 和 Grafana 从 Tra ...
- 抛砖系列之redis监控命令
前言 redis是一款非常流行的kv数据库,以高性能著称,其高吞吐.低延迟等特性让广大开发者趋之若鹜,每每看到别人发出的redis故障报告都让我产生一种居安思危,以史为鉴的危机感,恰逢今年十一西安烟雨 ...
- Windows Azure功能更新:弹性伸缩(autoscale)、监控报警、移动服务及网站服务商用、新的虚拟机镜像
Windows Azure功能又更新了.此次更新包括1项重要更新和两个功能更新: 重要更新:云服务.网站支持按策略进行弹性伸缩 功能更新:两个预览版的服务(网站和移动)进入商用,虚拟机服务支持SQL ...
- zabbix实现企业微信监控报警
一.zabbix基本说明 简介:zabbix基于Web界面的分布式系统监控的企业级开源软件.可以监控各种系统与设备,网络参数,保证服务器设备安全运营:提供灵活的通知机制.如果检测到的指标不达标,就实现 ...
随机推荐
- Python判断是否为数字
前言 Python isdigit()方法检测字符串是否只由数字组成. isdigit()方法语法: str.isdigit() 如果字符串只包含数字则返回 True 否则返回 False. 示例 x ...
- CF980C Posterized
先来吐槽一下这个 sb 翻译,根本就没做过题吧-- 大概就是让你给值域分成连续的几组,每组大小不能超过 \(k\),然后将序列中的值全部替换成其组内的最小值,要使得序列的字典序最小. 因为是字典序,所 ...
- JQuery案例:左右选
左右选 <head> <meta charset="UTF-8"> <title></title> <style> se ...
- django搭建
1.进入终端使用虚拟环境安装---pip install django==2.2 2.创建新的工程django-admin startproject bookpro 3.创建app或模块 使用djan ...
- 学Python,只有不到15%的同学会成功
我给大家唱首歌:<坚持的意义> 你看过了许多书籍 你看过了许多视频 你迷失在屏幕上每一道短暂的光阴 你品尝了代码的糟心 你踏过算法的荆棘 你熟记书本里每一段你最爱的公式 却说不出你爱Pyt ...
- kali putty远程连接允许以root身份登录
原文链接:https://blog.csdn.net/long_long_chuang/article/details/70227874 kali linux通过ssh+putty来实现远程登录(亲测 ...
- 【2020.12.02提高组模拟】球员(player)
题目 题目描述 老师们已经知道学生喜欢睡觉,Soaring是这项记录保持者.他只会在吃饭或玩FIFA20时才会醒来.因此,他经常做关于足球的梦,在他最近的一次梦中,他发现自己成了皇家马德里足球俱乐部的 ...
- PyQt(Python+Qt)学习随笔:QMainWindow的takeCentralWidget对QDockWidget作用案例图解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 QMainWindow的takeCentralWidget方法作用是将 ...
- 第15.35节 PyQt编程实战:结合QDial实现的QStackedWidget堆叠窗口程序例子
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.案例说明 本案例是老猿在学习QStackedWidget中的一个测试案例,该案例使用QStack ...
- PyQt(Python+Qt)学习随笔:QTreeWidgetItem项的子项排序sortChildren及获取项对应的树型部件对象方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 1.sortChildren对子项排序 树型部件QTreeWidget中的QTreeWidgetIt ...