AI时代,还不了解大数据?

如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能、大数据和云计算。
这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转型,基本各个公司都在考虑如何进一步挖掘数据价值,提高企业的运营效率。在这种趋势下,大数据技术越来越重要。所以,AI时代,还不了解大数据就真的OUT了!
相比较AI和云计算,大数据的技术门槛更低一些,而且跟业务的相关性更大。我个人感觉再过几年,大数据技术将会像当前的分布式技术一样,变成一项基本的技能要求。
前几天,我在团队内进行了一次大数据的技术分享,重点是对大数据知识做一次扫盲,同时提供一份学习指南。这篇文章,我基于分享的内容再做一次系统性整理,希望对大数据方向感兴趣的同学有所帮助,内容分成以下5个部分:
1、大数据的发展历史
2、大数据的核心概念
3、大数据平台的通用架构和技术体系
4、大数据的通用处理流程
5、大数据下的数仓体系架构
01 大数据的发展历史
在解释「大数据」这个概念之前,先带大家了解下大数据将近30年的发展历史,共经历了5个阶段。那在每个阶段中,大数据的历史定位是怎样的?又遇到了哪些痛点呢?
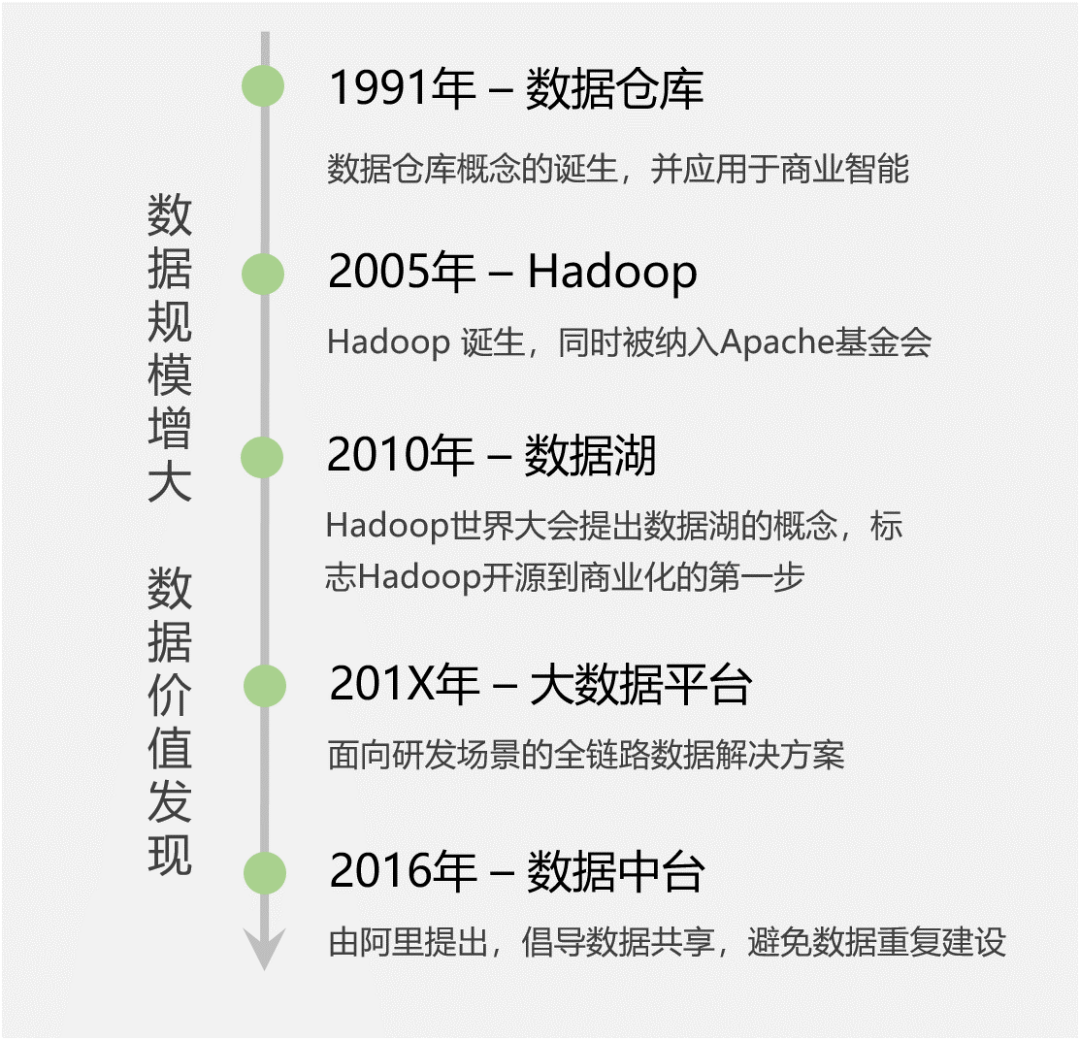
1.1 启蒙阶段:数据仓库的出现
20世纪90年代,商业智能(也就是我们熟悉的BI系统)诞生,它将企业已有的业务数据转化成为知识,帮助老板们进行经营决策。比如零售场景中:需要分析商品的销售数据和库存信息,以便制定合理的采购计划。
显然,商业智能离不开数据分析,它需要聚合多个业务系统的数据(比如交易系统、仓储系统),再进行大数据量的范围查询。而传统数据库都是面向单一业务的增删改查,无法满足此需求,这样就促使了数据仓库概念的出现。
传统的数据仓库,第一次明确了数据分析的应用场景,并采用单独的解决方案去实现,不依赖业务数据库。
1.2 技术变革:Hadoop诞生

2000年左右,PC互联网时代来临,同时带来了海量信息,很典型的两个特征:
数据规模变大:Google、雅虎等互联网巨头一天可以产生上亿条行为数据。
数据类型多样化:除了结构化的业务数据,还有海量的用户行为数据,以图像、视频为代表的多媒体数据。
很显然,传统数据仓库无法支撑起互联网时代的商业智能。2003年,Google公布了3篇鼻祖型论文(俗称「谷歌3驾马车」),包括:分布式处理技术MapReduce,列式存储BigTable,分布式文件系统GFS。这3篇论文奠定了现代大数据技术的理论基础。
苦于Google并没有开源这3个产品的源代码,而只是发布了详细设计论文。2005年,Yahoo资助Hadoop按照这3篇论文进行了开源实现,这一技术变革正式拉开了大数据时代的序幕。
Hadoop相对于传统数据仓库,有以下优势:
- 完全分布式,可以采用廉价机器搭建集群,完全可以满足海量数据的存储需求。
- 弱化数据格式,数据模型和数据存储分离,可以满足对异构数据的分析需求。
随着Hadoop技术的成熟,2010年的Hadoop世界大会上,提出了「数据湖」的概念。
数据湖是一个以原始格式存储数据的系统。
企业可以基于Hadoop构建数据湖,将数据作为企业的核心资产。由此,数据湖拉开了Hadoop商业化的大幕。
1.3 数据工厂时代:大数据平台兴起
商用Hadoop包含上十种技术,整个数据研发流程非常复杂。为了完成一个数据需求开发,涉及到数据抽取、数据存储、数据处理、构建数据仓库、多维分析、数据可视化等一整套流程。这种高技术门槛显然会制约大数据技术的普及。
此时,大数据平台(平台即服务的思想,PaaS)应运而生,它是面向研发场景的全链路解决方案,能够大大提高数据的研发效率,让数据像在流水线上一样快速完成加工,原始数据变成指标,出现在各个报表或者数据产品中。
1.4 数据价值时代:阿里提出数据中台
2016年左右,已经属于移动互联网时代了,随着大数据平台的普及,也催生了很多大数据的应用场景。
此时开始暴露出一些新问题:为了快速实现业务需求,烟囱式开发模式导致了不同业务线的数据是完全割裂的,这样造成了大量数据指标的重复开发,不仅研发效率低、同时还浪费了存储和计算资源,使得大数据的应用成本越来越高。
极富远见的马云爸爸此时喊出了「数据中台」的概念,「One Data,One Service」的口号开始响彻大数据界。数据中台的核心思想是:避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能业务。
02 大数据的核心概念
了解了大数据的发展历史后,再解释下大数据的几个核心概念。
2.1 究竟什么是大数据?
大数据是一种海量的、高增长率的、多样化的信息资产,它需要新的存储和计算模式才能具有更强的决策力、流程优化能力。
下面是大数据的4个典型特征:
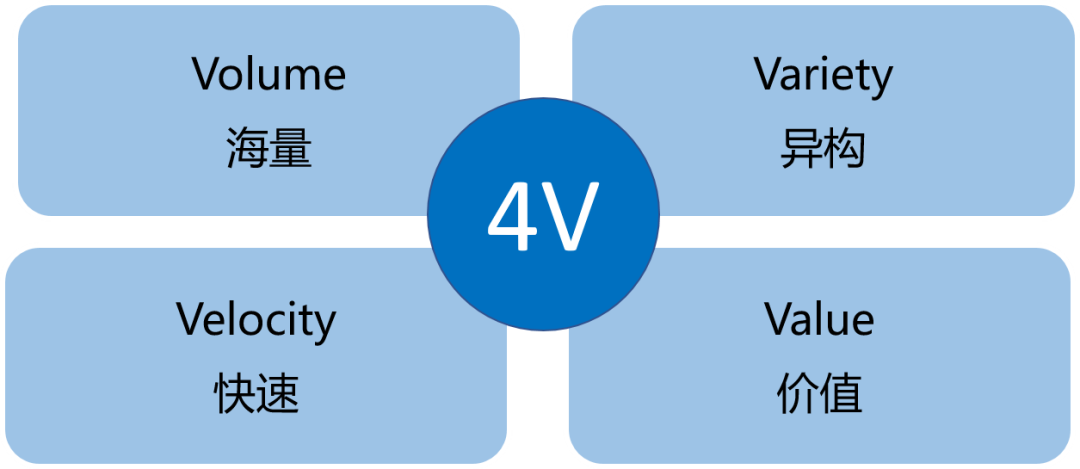
- Volume:海量的数据规模,数据体量达到PB甚至EB级别。
- Variety:异构的数据类型,不仅仅包含结构化的数据、还包括半结构化和非结构化数据,比如日志文件、图像、音视频等。
- Velocity:快速的数据流转,数据的产生和处理速度非常快。
- Value:价值密度低,有价值的数据占比很小,需要用到人工智能等方法去挖掘新知识。
2.2 什么又是数据仓库?
数据仓库是面向主题的、集成的、随着时间变化的、相对稳定的数据集合。
简单理解,数据仓库是大数据的一种组织形式,有利于对海量数据的维护和进一步分析 。
- 面向主题的:表示按照主题或者业务场景组织数据。
- 集成的:从多个异构数据源采集数据,进行抽取、加工、集成。
- 随时间变化的:关键数据需要标记时间属性。
- 相对稳定的:极少进行数据删除和修改,而只是进行数据新增。
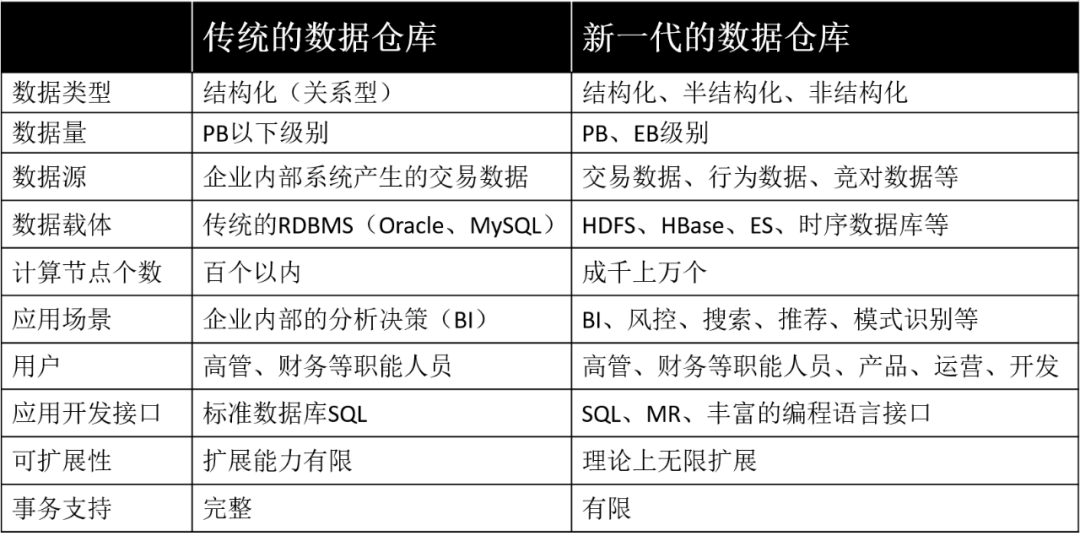
2.3 传统数据仓库 vs 新一代数据仓库
随着大数据时代的到来,传统数据仓库和新一代数据仓库必然有很多不同,下面从多维度对比下两代数据仓库的异同。
03 大数据平台的通用架构
前面谈到大数据相关的技术有几十种,下面通过大数据平台的通用架构来了解下整个技术体系。
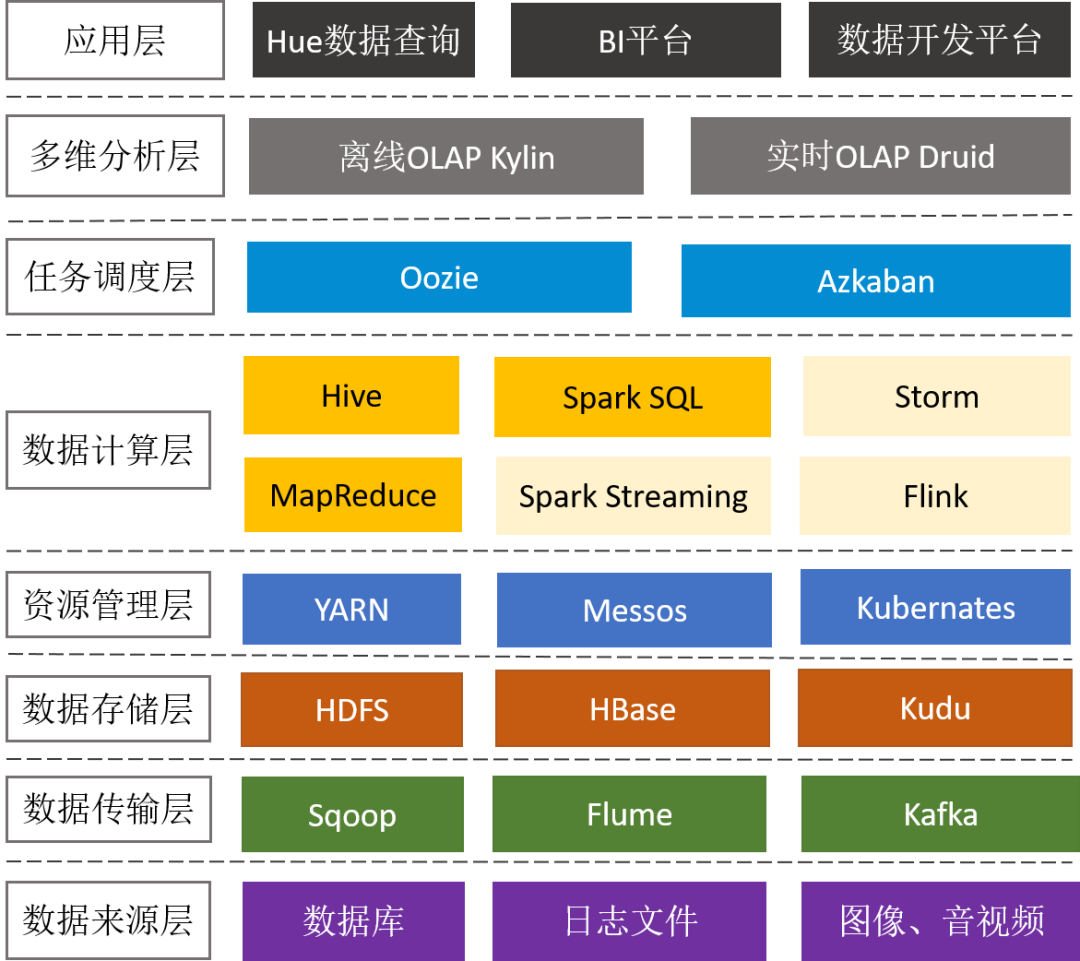
3.1 数据传输层
- Sqoop:支持RDBMS和HDFS之间的双向数据迁移,通常用于抽取业务数据库(比如MySQL、SQLServer、Oracle)的数据到HDFS.
- Cannal:阿里开源的数据同步工具,通过监听MySQL binlog,实现增量数据订阅和近实时同步。
- Flume:用于海量日志采集、聚合和传输,将产生的数据保存到HDFS或者HBase中。
- Flume + Kafka:满足实时流式日志的处理,后面再通过Spark Streaming等流式处理技术,可完成日志的实时解析和应用。
3.2 数据存储层
- HDFS:分布式文件系统,它是分布式计算中数据存储管理的基础,是Google GFS的开源实现,可部署在廉价商用机器上,具备高容错、高吞吐和高扩展性。
- HBase:分布式的、面向列的NoSQL KV数据库, 它是Google BigTable的开源实现,利用HDFS作为其文件存储系统,适合大数据的实时查询(比如:IM场景)。
- Kudu:折中了HDFS和HBase的分布式数据库,既支持随机读写、又支持OLAP分析的大数据存储引擎(解决HBase不适合批量分析的痛点)。
3.3 资源管理层
- Yarn:Hadoop的资源管理器,负责Hadoop集群资源的统一管理和调度,为运算程序(MR任务)提供服务器运算资源(CPU、内存),能支持MR、Spark、Flink等多种框架。
- Kubernates:由Google开源,一种云平台的容器化编排引擎,提供应用的容器化管理,可在不同云、不同版本操作系统之间进行迁移。目前,Spark、Storm已经支持K8S。
3.4 数据计算层
大数据计算引擎决定了计算效率,是大数据平台最核心的部分,它大致了经历以下4代的发展,又可以分成离线计算框架和实时计算框架。
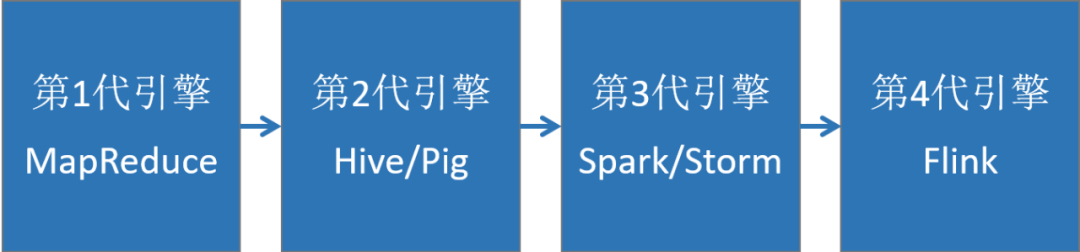
3.4.1 离线计算框架
- MapReduce:面向大数据并行处理的计算模型、框架和平台(将计算向数据靠拢、减少数据传输,这个设计思路非常巧妙)。
- Hive:一个数据仓库工具,能管理HDFS存储的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能(实际运行时,是将Hive SQL翻译成了MapReduce任务),适用离线非实时数据分析。
- Spark sql:引入RDD(弹性分布式数据集)这一特殊的数据结构,将SQL转换成RDD的计算,并将计算的中间结果放在内存中,因此相对于Hive性能更高,适用实时性要求较高的数据分析场景。
3.4.2 实时计算框架
Spark Streaming:实时流数据处理框架(按时间片分成小批次,s级延迟),可以接收Kafka、Flume、HDFS等数据源的实时输入数据,经过处理后,将结果保存在HDFS、RDBMS、HBase、Redis、Dashboard等地方。
Storm:实时流数据处理框架,真正的流式处理,每条数据都会触发计算,低延迟(ms级延迟)。
Flink:更高级的实时流数据处理框架,相比Storm,延迟比storm低,而且吞吐量更高,另外支持乱序和调整延迟时间。
3.5 多维分析层
- Kylin:分布式分析引擎,能在亚秒内查询巨大的Hive表,通过预计算(用空间换时间)将多维组合计算好的结果保存成Cube存储在HBase中,用户执行SQL查询时,将SQL转换成对Cube查询,具有快速查询和高并发能力。
- Druid:适用于实时数据分析的高容错、高性能开源分布式系统,可实现在秒级以内对十亿行级别的表进行任意的聚合分析。
04 大数据的通用处理流程
了解了大数据平台的通用架构和技术体系后,下面再看下针对离线数据和实时数据,是如何运用大数据技术进行处理的?
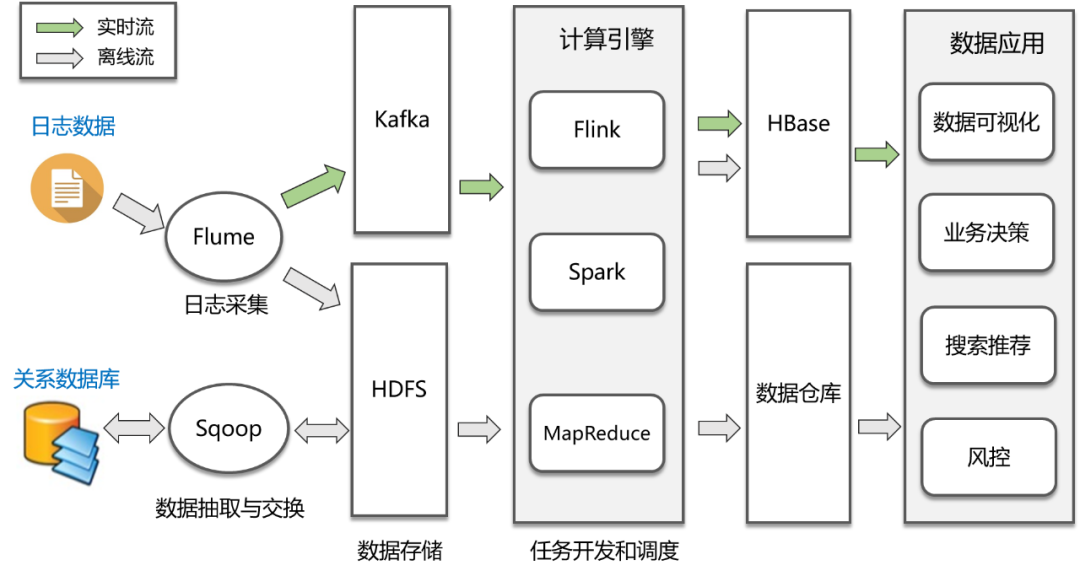
上图是一个通用的大数据处理流程,主要包括以下几个步骤:
- 数据采集:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
- 数据存储:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
- 数据分析:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
- 数据应用:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
05 大数据下的数仓体系架构
数据仓库是从业务角度出发的一种数据组织形式,它是大数据应用和数据中台的基础。数仓系统一般采用下图所示的分层结构。
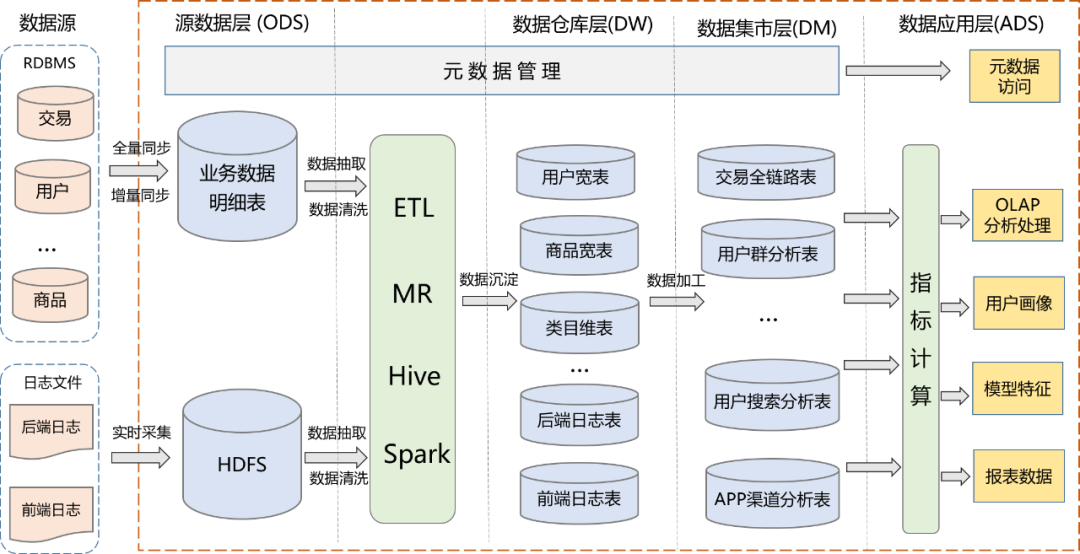
可以看到,数仓系统分成了4层:源数据层、数据仓库层、数据集市层、数据应用层。采用这样的分层结构,和软件设计的分层思想类似,都是为了将复杂问题简单化,每一层职责单一,提高了维护性和复用性。每一层的具体作用如下:
- ODS:源数据层,源表。
- DW:数据仓库层,包含维度表和事实表,通过对源表进行清洗后形成的数据宽表,比如:城市表、商品类目表、后端埋点明细表、前端埋点明细表、用户宽表、商品宽表。
- DM:数据集市层,对数据进行了轻粒度的汇总,由各业务方共建,比如:用户群分析表、交易全链路表。
- ADS:数据应用层,根据实际应用需求生成的各种数据表。
另外,各层的数据表都会采用统一的命名规则进行规范化管理,表名中会携带分层、主题域、业务过程以及分区信息。比如,对于交易域下的一张曝光表,命名可以是这样:

写在最后
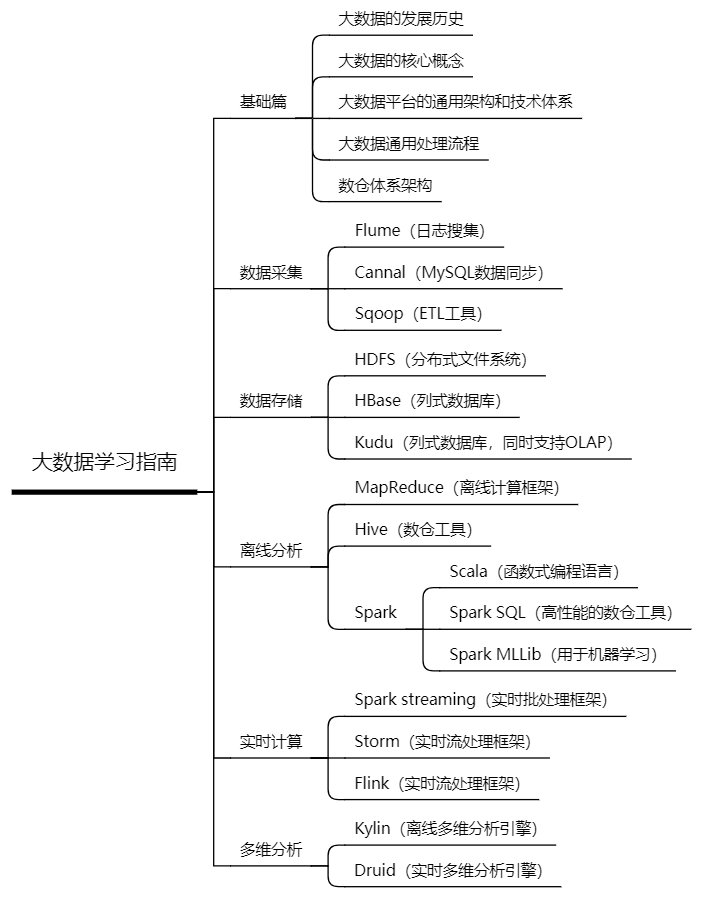
上文对大数据的历史、核心概念、通用架构、以及技术体系进行了系统性总结。如果大家想深入学习大数据技术,建议参考这篇文章,同时结合下面的学习指南展开。
后续会持续带来大数据方向更深度的分享,如果感兴趣,欢迎关注我。
作者简介:985硕士,前亚马逊工程师,现58转转技术总监
欢迎关注我的个人公众号:IT人的职场进阶

AI时代,还不了解大数据?的更多相关文章
- 这可能是AI、机器学习和大数据领域覆盖最全的一份速查表
https://mp.weixin.qq.com/s?__biz=MjM5ODE1NDYyMA==&mid=2653390110&idx=1&sn=b3e5d6e946b719 ...
- 3.5星|《算法霸权》:AI、算法、大数据在美国的阴暗面
算法霸权 作者在华尔街对冲基金德绍集团担任过金融工程师,后来去银行做过风险分析,再后来去做旅游网站的用户分析.后来辞职专门揭露美国社会生活背后的各种算法的阴暗面. 书中提到的算法的技术缺陷,我归纳为两 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(2)
前言:老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点 第6点:HRegionServer架构 为 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点(3) 第13点:HBase表的热点问题 什么是热 ...
- 大白话详解大数据hive知识点,老刘真的很用心(2)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(2) 第12点:hive分桶表 hive知识点主要偏实践, ...
- 大白话详解大数据hive知识点,老刘真的很用心(3)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(3) 从这篇文章开始决定进行一些改变,老刘在博客上主要分享 ...
- 《后会无期》票房赶超《小时代3》 大数据解读韩寒VS四娘之争
7月25日.韩寒导演的处女作<后会无期>零点首映,而郭四娘导演的<小时代3:刺金时代>比<后会无期>早上映一周.也就是7月17日正式公映,韩寒与四娘之间向来不缺乏话 ...
- 大白话详解大数据hive知识点,老刘真的很用心(1)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 01 hive知识点(1) 第1点:数据仓库的概念 由于hive它是基于had ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
随机推荐
- DBA提交脚步规范
工作中需要走脚步流程,申请修改数据库,总结一些常用的语句:)提交时注明为DDL/DML_需求号_日期(各公司标准不一样)//修改字段长度使用;alter table t_task modify tas ...
- MeteoInfoLab脚本示例:中文处理
在脚本中使用中文需要指明是unicode编码,即在含有中文的字符串前加u,比如:u'中文'.还需要将字体指定为一种中文字体.详见下面的例子.脚本程序: x = [1,2,3,4] y = [1,4,9 ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- 四年了自学了C/C++那么久,还写不出项目,正常吗?
前言: 这是之前在V2EX职场话题里看到的一个话题,类似的小编身边人呢也有相似的困扰. 现在大学里基本都开设了计算机课程,看了那么多相关知识性的书,但学了四年出来,仍然写不出项目,这肯定是有问题的. ...
- 单调队列优化题:最大数(P1198)
题目描述 现在请求你维护一个数列,要求提供以下两种操作: 1. 查询操作. 语法:Q L 功能:查询当前数列中末尾L个数中的最大的数,并输出这个数的值. 限制:不超过当前数列的长度.(L>0) ...
- linux(centos8):zabbix配置邮件报警(监控错误日志)(zabbix5.0)
一,zabbix5.0发邮件报警的准备工作: zabbix5.0在linux平台上的安装:参见这一篇: https://www.cnblogs.com/architectforest/p/129125 ...
- centos8平台使用lsof
一,lsof的用途 lsof,List Open Files 列出当前系统打开文件的工具. 在linux环境下,任何事物都以文件的形式存在, 所以lsof通过文件不仅仅可以访问常规数据,还可以访问网络 ...
- 3.QOpenGLWidget-通过着色器来渲染渐变三角形
在上章2.通过QOpenGLWidget绘制三角形,我们学习绘制三角形还是单色的,本章将为三角形每个顶点着色. 1.着色器描述 着色器的开头总是要声明版本,接着是输入和输出变量.uniform和m ...
- 64位Ubuntu14.04配置adb后提示No such file or directory
配置好SDK的环境变量后,输入adb提示 No such file or directory. 原因:由于是64位的linux系统,而Android SDK只有32位的,需要安装一些支持包才能使用 1 ...
- 在centos下启动nginx出现Failed to start nginx.service:unit not found
错误的原因就是没有添加nginx服务,所以启动失败. 解决方法: 1. 在/root/etc/init.d/目录下新建文件,文件名为nginx 或者用命令在根目录下执行:# vim /etc/i ...