题解 洛谷 P6349 【[PA2011]Kangaroos】
先考虑对题目进行转化,我们称两个区间有交集为这两个区间能匹配,每个询问就是在序列中最长能连续匹配的长度。
对序列中的一个区间\([l,r]\)和询问的一个区间\([L,R]\),若满足\(L \leqslant r\)且\(l \leqslant R\),那么这两个区间是能匹配的。
可以将一个区间用点来表示,然后用\(K-D\ Tree\)来维护所有的询问区间,序列区间按顺序一个个去更新每个询问的匹配信息即可。
对\(K-D\ Tree\)中的维护一个矩形来考虑,比如下图的蓝色矩形为这个矩形。
当一个点落在红色矩形时,那么该点和矩形内的所有点都能匹配,对该矩形打上加法标记,使矩形内所有点的当前匹配数加一。
当一个点落在黄色矩形时,那么该点和矩形内的所有点都不能匹配,对该矩形打上清零标记,使矩形内所有点的当前匹配数清零。
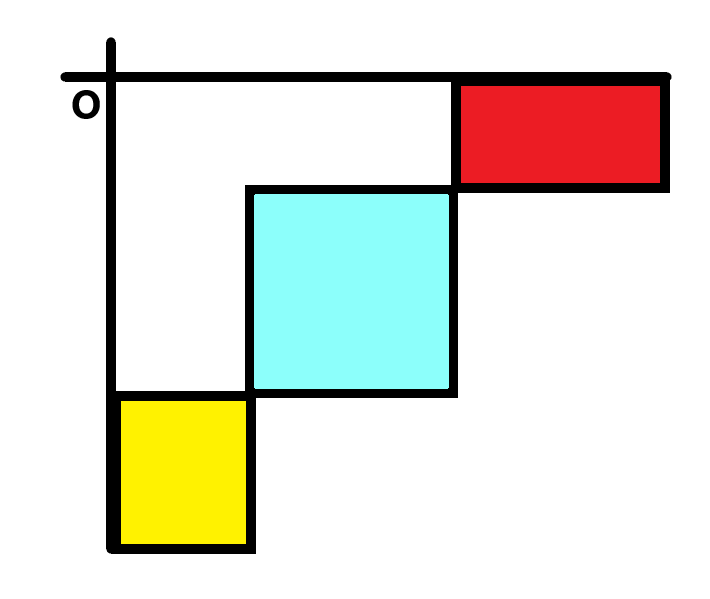
同时记录一个点在整个过程中的历史最大匹配数,其即为最终一个点所对应询问的答案。
对一个矩形清空后,还会进行一系列对其匹配数增加的操作,但此时打上加法标记是错误的,所以给它打上一个赋值标记,打标记时增加赋值标记即可,同时记录下这阶段赋值标记的历史最大值,并用其去更新该点的历史最大匹配数。
标记比较多,有很多细节,具体实现看代码吧。
\(code:\)
#include<bits/stdc++.h>
#define maxn 400010
using namespace std;
template<typename T> inline void read(T &x)
{
x=0;char c=getchar();bool flag=false;
while(!isdigit(c)){if(c=='-')flag=true;c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
if(flag)x=-x;
}
int n,m,root,tot,type;
int cov[maxn],his[maxn],add[maxn],tag[maxn];
int ans[maxn],ma[maxn],cnt[maxn];
struct node
{
int l,r;
}p[maxn];
struct KD_tree
{
int d[2],mi[2],ma[2],ls,rs,id;
}t[maxn],dat[maxn];
bool cmp(const KD_tree &a,const KD_tree &b)
{
return a.d[type]<b.d[type];
}
void pushup(int x)
{
int ls=t[x].ls,rs=t[x].rs;
for(int i=0;i<=1;++i)
{
t[x].ma[i]=t[x].mi[i]=t[x].d[i];
if(ls)
{
t[x].ma[i]=max(t[x].ma[i],t[ls].ma[i]);
t[x].mi[i]=min(t[x].mi[i],t[ls].mi[i]);
}
if(rs)
{
t[x].ma[i]=max(t[x].ma[i],t[rs].ma[i]);
t[x].mi[i]=min(t[x].mi[i],t[rs].mi[i]);
}
}
}
void update(int x,int v)
{
cnt[x]+=v,ma[x]=max(ma[x],cnt[x]);
}
void pushadd(int x,int v)
{
update(x,v);
if(cov[x]) tag[x]+=v,his[x]=max(his[x],tag[x]);
else add[x]+=v;
}
void pushcov(int x)
{
if(!cov[x]) cov[x]=1,his[x]=0;
cnt[x]=tag[x]=0;
}
void pushtag(int x,int v1,int v2)
{
cov[x]=1,his[x]=max(his[x],v2);
cnt[x]=tag[x]=v1,ma[x]=max(ma[x],his[x]);
}
void pushdown(int x)
{
int ls=t[x].ls,rs=t[x].rs;
if(add[x])
{
pushadd(ls,add[x]),pushadd(rs,add[x]);
add[x]=0;
}
if(cov[x])
{
pushtag(ls,tag[x],his[x]),pushtag(rs,tag[x],his[x]);
cov[x]=tag[x]=0;
}
}
void build(int l,int r,int k,int &x)
{
x=++tot,type=k;
int mid=(l+r)>>1;
nth_element(dat+l+1,dat+mid+1,dat+r+1,cmp);
t[x]=dat[mid];
if(l<mid) build(l,mid-1,k^1,t[x].ls);
if(r>mid) build(mid+1,r,k^1,t[x].rs);
pushup(x);
}
bool in(KD_tree tr,int l,int r)
{
return tr.ma[0]<=r&&l<=tr.mi[1];
}
bool out(KD_tree tr,int l,int r)
{
return tr.mi[0]>r||l>tr.ma[1];
}
void modify(int x,int l,int r)
{
int ls=t[x].ls,rs=t[x].rs;
if(in(t[x],l,r))
{
pushadd(x,1);
return;
}
if(out(t[x],l,r))
{
pushcov(x);
return;
}
pushdown(x);
if(t[x].d[0]<=r&&l<=t[x].d[1]) update(x,1);
else cnt[x]=0;
if(ls) modify(ls,l,r);
if(rs) modify(rs,l,r);
}
void dfs(int x)
{
int ls=t[x].ls,rs=t[x].rs;
pushdown(x),ans[t[x].id]=ma[x];
if(ls) dfs(ls);
if(rs) dfs(rs);
}
int main()
{
read(n),read(m);
for(int i=1;i<=n;++i) read(p[i].l),read(p[i].r);
for(int i=1;i<=m;++i)
read(dat[i].d[0]),read(dat[i].d[1]),dat[i].id=i;
build(1,m,0,root);
for(int i=1;i<=n;++i) modify(root,p[i].l,p[i].r);
dfs(root);
for(int i=1;i<=m;++i) printf("%d\n",ans[i]);
return 0;
}
题解 洛谷 P6349 【[PA2011]Kangaroos】的更多相关文章
- 洛谷 P6349 - [PA2011]Kangaroos(KDT+标记下放)
洛谷题面传送门 KDT 上打标记的 hot tea. 考虑将询问 \(A,B\) 看作二维平面直角坐标系上的一个点 \((A,B)\),那么我们这样考虑,我们从左到右扫过全部 \(n\) 个区间并开一 ...
- 题解 洛谷P5018【对称二叉树】(noip2018T4)
\(noip2018\) \(T4\)题解 其实呢,我是觉得这题比\(T3\)水到不知道哪里去了 毕竟我比较菜,不大会\(dp\) 好了开始讲正事 这题其实考察的其实就是选手对D(大)F(法)S(师) ...
- 题解 洛谷 P3396 【哈希冲突】(根号分治)
根号分治 前言 本题是一道讲解根号分治思想的论文题(然鹅我并没有找到论文),正 如论文中所说,根号算法--不仅是分块,根号分治利用的思想和分块像 似却又不同,某一篇洛谷日报中说过,分块算法实质上是一种 ...
- 题解-洛谷P5410 【模板】扩展 KMP(Z 函数)
题面 洛谷P5410 [模板]扩展 KMP(Z 函数) 给定两个字符串 \(a,b\),要求出两个数组:\(b\) 的 \(z\) 函数数组 \(z\).\(b\) 与 \(a\) 的每一个后缀的 L ...
- 题解-洛谷P4229 某位歌姬的故事
题面 洛谷P4229 某位歌姬的故事 \(T\) 组测试数据.有 \(n\) 个音节,每个音节 \(h_i\in[1,A]\),还有 \(m\) 个限制 \((l_i,r_i,g_i)\) 表示 \( ...
- 题解-洛谷P4724 【模板】三维凸包
洛谷P4724 [模板]三维凸包 给出空间中 \(n\) 个点 \(p_i\),求凸包表面积. 数据范围:\(1\le n\le 2000\). 这篇题解因为是世界上最逊的人写的,所以也会有求凸包体积 ...
- 题解-洛谷P4859 已经没有什么好害怕的了
洛谷P4859 已经没有什么好害怕的了 给定 \(n\) 和 \(k\),\(n\) 个糖果能量 \(a_i\) 和 \(n\) 个药片能量 \(b_i\),每个 \(a_i\) 和 \(b_i\) ...
- 题解-洛谷P5217 贫穷
洛谷P5217 贫穷 给定长度为 \(n\) 的初始文本 \(s\),有 \(m\) 个如下操作: \(\texttt{I x c}\),在第 \(x\) 个字母后面插入一个 \(c\). \(\te ...
- 题解 洛谷 P2010 【回文日期】
By:Soroak 洛谷博客 知识点:模拟+暴力枚举 思路:题目中有提到闰年然后很多人就认为,闰年是需要判断的其实,含有2月29号的回文串,前四位是一个闰年那么我们就可以直接进行暴力枚举 一些小细节: ...
随机推荐
- Perl入门(一)Perl的基本类型及运算符
在学习Perl的基础之前,还是希望大家有空去看以下Perl的简介.百度百科 一.Perl的基本类型 Per的基本类型分为两种:数值型和字符串型. 数值型可细分为 整数型.如123. 浮点型.如123. ...
- 【String注解驱动开发】你了解@PostConstruct注解和@PreDestroy注解吗?
写在前面 在之前的文章中,我们介绍了如何使用@Bean注解指定初始化和销毁的方法,小伙伴们可以参见<[Spring注解驱动开发]如何使用@Bean注解指定初始化和销毁的方法?看这一篇就够了!!& ...
- django drf插件(一)
复习 """ 1.vue如果控制html 在html中设置挂载点.导入vue.js环境.创建Vue对象与挂载点绑定 2.vue是渐进式js框架 3.vue指令 {{ }} ...
- 第三方登陆--QQ登陆
从零玩转第三方QQ登陆 在真正开始对接之前,我们先来聊一聊后台的方案设计.既然是对接第三方登录,那就免不了如何将用户信息保存.首先需要明确一点的是,用户在第三方登录成功之后, 我们能拿到的仅仅是一个代 ...
- Python实用笔记 (1)字符串与编码
历史:Ascll-Unicode-UTF-8 对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符: >>> ord('A') ...
- Nginx之upstream的四种配置方式
1.轮询(weight) 指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况.默认当weight不指定时,各服务器weight相同,每个请求按时间顺序逐一分配到不同的后端服务 ...
- 【实践】如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)
如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统) 一.环境配置 1. Python3.7.x(注:我用的是3.7.3.安 ...
- 【Oracle】rman中SBT_TYPE类型的备份如何删除
技阳的rman数据库出现删除rman备份失败,原因是出现SBT_TYPE的磁带备份. [BEGIN] 2018/8/13 13:48:42 RMAN> list backup; List of ...
- CSS粘性定位
粘性定位(position:sticky) 1.定义 粘性定位可以被认为是相对定位和固定定位的混合.元素在跨越特定阈值前为相对定位,之后为固定定位.(MDN传送门) 这个特定阈值指的是 top, ri ...
- day13 函数入门
目录 一.什么是函数 二.为何要有函数 三.如何用函数 1.定义函数的三种形式: 形式一.无参函数(自身能干活) 形式二.有参函数(需要外部的材料来加工) 形式三.空函数(在写框架构思函数的时候) 2 ...