Greenplum 性能优化之路 --(一)分区表
一、什么是分区表
分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面。Greenplum 中分区表的原理和 PostgreSQL 一样,都是通过表继承和约束实现的。
Greenplum 官方给出的分区表示例如下:
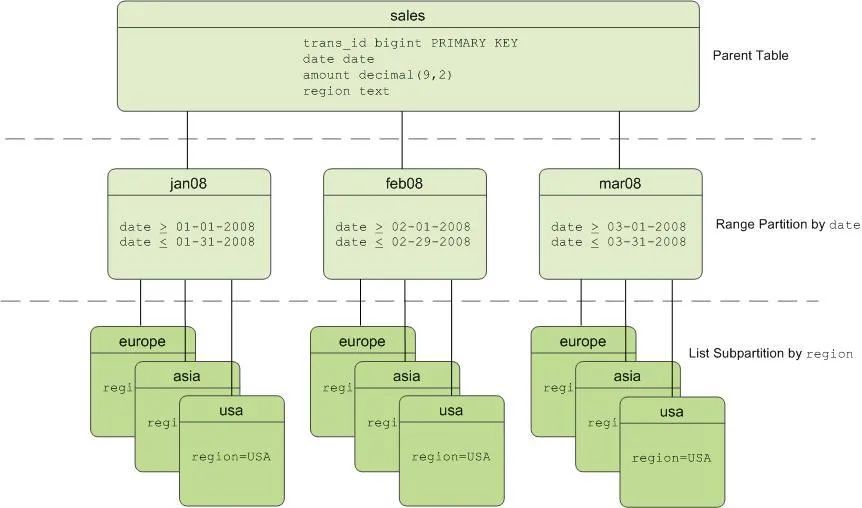
partitions.jpg
二、与分布的区别
分布:DISTRIBUTED
分区:PARTITION
Greenplum 中每个表都需要有一个分布键,如果你建表的时候没有显示使用语法DISTRIBUTED BY (column) 指定一个分布键,系统也会默认为你指定一个。分布目的是把数据打散到每个节点,打散的规则是 hash 或者 randomly。这样在计算时可以充分利用每个节点的资源进行并行计算。
分区特性在本文会详细介绍,两者比较如下:
数据分布是在物理上拆分表数据,将数据打散到各个节点,使数据可以并行计算,这在 Greenplum 中是必须的。
表分区是在逻辑上拆分大表的数据提高查询性能,也有利于数据生命周期的管理,这在 Greenplum 中是可选的。
无论是分区表还是非分区表,在 Greenplum 中,数据都是分散到各个节点上的。
分区不会影响数据在各个节点上的分布情况。
三、什么时候使用分区表
是否使用分区表,可以通过以下几个方面进行考虑:
表数据量是否足够大:通常对于大的事实表,比如数据量有几千万或者过亿,我们可以考虑使用分区表,但数据量大小并没有一个绝对的标准可以使用,一般是根据经验,以及对目前性能是否满意。
表是否有合适的分区字段:如果数据量足够大了,这个时候我们就需要看下是否有合适的字段能够用来分区,通常如果数据有时间维度,比如按天,按月等,是比较理想的分区字段。
表内数据是否具有生命周期:通常数仓中的数据不可能一直存放,一般都会有一定的生命周期,比如最近一年等,这里就涉及到对旧数据的管理,如果有分区表,就很容易删除旧的数据,或者将旧的数据归档到对象存储等更为廉价的存储介质上。
查询语句中是否含有分区字段:如果你对一个表做了分区,但是所有的查询都不带分区字段,这不仅无法提高性能反而会使性能下降,因为所有的查询都会扫描所有的分区表。
四、创建分区表
Greenplum 支持三种分区类型:
范围分区(Range Partition)
列表分区(List Partition)
组合分区(A combination of both types)
范围分区例子:
CREATE TABLE test_range_partition
(
uid int,
fdate character varying(32)
)
PARTITION BY RANGE(fdate)
(
PARTITION p1 START ('2018-11-01') INCLUSIVE END ('2018-11-02') EXCLUSIVE,
PARTITION p2 START ('2018-11-02') INCLUSIVE END ('2018-11-03') EXCLUSIVE,
DEFAULT PARTITION pdefault
);
以上例子是按天建表,如果时间跨度比较大,会导致建表语句很长,书写起来也不方便,这时候可以使用以下语法:
CREATE TABLE test_range_partition_every_1
(
uid int,
fdate date
)
partition by range (fdate)
(
PARTITION pn START ('2018-11-01'::date) END ('2018-12-01'::date) EVERY ('1 day'::interval),
DEFAULT PARTITION pdefault
);
列表分区例子:
CREATE TABLE test_list_partition
(
uid int,
gender char(1)
)
PARTITION BY LIST (gender)
(
PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION pdefault
);
多级分区例子:
CREATE TABLE test_muti_level_partition
(
uid int,
gender char(1),
fdate character varying(32)
)
PARTITION BY RANGE(fdate)
SUBPARTITION BY LIST(gender)
SUBPARTITION template
(
SUBPARTITION s1 VALUES ('F'),
SUBPARTITION s2 VALUES ('M')
)
(
PARTITION p1 START ('2018-11-01') INCLUSIVE END ('2018-11-02') EXCLUSIVE,
PARTITION p2 START ('2018-11-02') INCLUSIVE END ('2018-11-03') EXCLUSIVE,
DEFAULT PARTITION pdefault
)
五、管理分区表
分区表也是一张表,所以对于表的很多操作也可以作用于分区表上,这里列举了常用的一些操作:
清空子分区
ALTER TABLE test_range_partition TRUNCATE PARTITION p1;删除子分区
ALTER TABLE test_range_partition DROP PARTITION p1;注:DROP PARTITION 之后跟的是 partition name,而不是 partition table name,这两者之间是有区别的,如果是使用 EVERY 语法创建的分区表,你需要通过 pg_partitions 表查询到对应分区的 partition name。
新增子分区
ALTER TABLE test_range_partition ADD PARTITION p3 START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE;注:如果分区表中含有 DEFAULT 分区,会出现如下错误,解决办法可以参见 滚动分区:
ERROR: cannot add RANGE partition "p3" to relation "test_range_partition" with DEFAULT partition "pdefault"
滚动分区
通常按时间分区的表,都有一个特性,就是分区会不断往前滚动,比如一个按天分区,保存最近10天的分区表,每到新一天,就会要删除10天前的分表表,并且创建一个新的分区表容纳最新的数据。
如果是含有默认分区的,可以使用分区Split
ALTER TABLE test_range_partition SPLIT DEFAULT PARTITION START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE INTO (PARTITION p3, DEFAULT partition);这样新分区就被添加,同时保留了默认分区,然后在删除老的分区就完成新老分区的更替。
交换分区
交换分区就是将一张普通的表和某张分区表进行交换,这个功能在数据分层存储十分有用。
比如我们会需要根据对象存储的不同目录设置分区,这个需求就可以使用交换分区完成,这样对于一张大表,他的较少查询的历史数据就可以放在对象存储上,语法如下:
ALTER TABLE {table_name} EXCHANGE PARTITION {partition_name|FOR (RANK(number))|FOR (value)} WITH TABLE {cos_table_name} WITHOUT VALIDATION;查询分区
与分区相关的系统表或者视图如下:
pg_partition
pg_partition_columns
pg_partition_encoding
pg_partition_rule
pg_partition_templates
pg_partitions
查看分区基本信息:
t2=# select * from pg_partitions where partitiontablename = 'test_range_partition_1_prt_p1';
-[ RECORD 1 ]------------+---------------------------------------------------------------------------------------------------
schemaname | public
tablename | test_range_partition
partitionschemaname | public
partitiontablename | test_range_partition_1_prt_p1
partitionname | p1
parentpartitiontablename |
parentpartitionname |
partitiontype | range
partitionlevel | 0
partitionrank | 1
partitionposition | 2
partitionlistvalues |
partitionrangestart | '2018-11-01'::character varying(32)
partitionstartinclusive | t
partitionrangeend | '2018-11-02'::character varying(32)
partitionendinclusive | f
partitioneveryclause |
partitionisdefault | f
partitionboundary | PARTITION p1 START ('2018-11-01'::character varying(32)) END ('2018-11-02'::character varying(32))
parenttablespace | pg_default
partitiontablespace | pg_default
查看分区定义
t2=# select pg_get_partition_def('test_range_partition'::regclass,true);
-[ RECORD 1 ]--------+---------------------------------------------------------------------------------------------------------------
pg_get_partition_def | PARTITION BY RANGE(fdate)
| (
| PARTITION p1 START ('2018-11-01'::character varying(32)) END ('2018-11-02'::character varying(32)),
| PARTITION p2 START ('2018-11-03'::character varying(32)) END ('2018-11-04'::character varying(32)),
| DEFAULT PARTITION pdefault
| )
六、查询优化
分区表很大的用途在于提升分析性能,但并不是对大表进行分区就能简单的提升性能,也不是分区越多性能越好。
分区的粒度
通常像范围分区的表都涉及到粒度问题,比如按时间分表,究竟是按天,按周,按月等。粒度越细,每张表的数据就越少,但是分区表的数量就会越多,反之亦然。
关于分区表的数量,这里没有绝对的标准,一般来说分区表的数量在100左右已经算是比较多了。
分区表数目过多,会有多方面的影响,比如查询优化器生成执行计划较慢,同时很多维护工作也都会变慢,比如 vacuum,recovering segment,expanding the cluster, checking disk usage 等。
查询语句
为了充分利用分区表的优势,需要在查询语句中尽量带上分区条件。最终目的是扫描尽量少的分区表。
如下是一个静态分区消除的例子,可以看出 Partitions selected: 11 (out of 15),这里在15张分区表中选择了其中11张
t2=# explain select * from test_range_partition_every_1 where fdate >= '2018-11-05';
QUERY PLAN --------------------------------------------------------------------------------------------------------
--------------------
Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=8)
-> Sequence (cost=0.00..431.00 rows=1 width=8)
-> Partition Selector for test_range_partition_every_1 (dynamic scan id: 1) (cost=10.00..100.
00 rows=50 width=4)
Filter: fdate >= '2018-11-05'::date
Partitions selected: 11 (out of 15)
-> Dynamic Table Scan on test_range_partition_every_1 (dynamic scan id: 1) (cost=0.00..431.00
rows=1 width=8)
Filter: fdate >= '2018-11-05'::date
Optimizer status: PQO version 2.55.13
(8 rows)
注:Greenplum 最新一代的解析引擎 ORCA 是支持动态分区消除的,但是分区的选择并不会打印在执行计划中。
以下是官网的说明:
For queries that involve dynamic partition selection where the partitioning key is compared to a variable, the number of partitions that are scanned will be known only during query execution. The partitions selected are not shown in the EXPLAIN output.
七、从Redshift 迁移到数据仓库
使用过 Redshift 的朋友都知道,Redshift 是不支持分区表的,AWS 官方建议使用 sort key 和distribution key 来优化并行处理,官方建议如下:
CREATE TABLE Amazon Redshift does not support tablespaces, table partitioning, inheritance, and certain constraints. The Amazon Redshift implementation of CREATE TABLE enables you to define the sort and distribution algorithms for tables to optimize parallel processing. Amazon Redshift Spectrum supports table partitioning using the CREATE EXTERNAL TABLE command.
但是涉及到数据生命周期管理,Redshift 通常的做法是每个分区创建不同的表,而在所有表的基础上创建一个视图来管理这些表,仿造出一个分区的特性,这无疑是低效的。因此从Redshift 迁移过来的用户建议在合适的场景下使用分区特性。

关注“腾讯云大数据”公众号,技术交流、最新活动、服务专享一站Get~
Greenplum 性能优化之路 --(一)分区表的更多相关文章
- Greenplum 性能优化之路 --(二)存储格式
一.存储格式介绍 Greenplum(以下简称 GP)有2种存储格式,Heap 表和 AO 表(AORO 表,AOCO 表). Heap 表:这种存储格式是从 PostgreSQL 继承而来的,目前是 ...
- Greenplum 性能优化之路 --(三)ANALYZE
一.为什么需要 ANALYZE 首先介绍下 RBO 和 CBO,这是数据库引擎在执行 SQL 语句时的2种不同的优化策略. RBO(Rule-Based Optimizer) 基于规则的优化器,就是优 ...
- 阿里巴巴 web前端性能优化进阶路
Web前端性能优化WPO,相信大多数前端同学都不会陌生,在各自所负责的站点页面中,也都会或多或少的有过一定的技术实践.可以说,这个领域并不缺乏成熟技术理论和技术牛人:例如Yahoo的web站点性能优化 ...
- 专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路(HipHop,HHVM)
专访阿里巴巴研究员“赵海平”:Facebook的PHP底层性能优化之路 http://www.infoq.com/cn/articles/interview-alibaba-zhaohaiping
- 40+倍提升,详解 JuiceFS 元数据备份恢复性能优化之路
JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同.为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进 ...
- 一些新的web性能优化技术
1.IconFont:图标字体,这是近年来新流行的一种以字体代替图片的技术.它可以适应任何分辨率而不会出现图片模糊问题,与图片相比它具有更小的容量,更高的灵活性(像字体一样可以设置图标大小.颜色.透明 ...
- 如何对react进行性能优化
React本身就非常关注性能,其提供的虚拟DOM搭配上DIff算法,实现对DOM操作最小粒度的改变也是非常高效的,然而其组件的渲染机制,也决定了在对组件更新时还可以进行更细致的优化. react组件 ...
- 从web现状谈及前端性能优化
从web现状谈及性能优化 原文出处:<Karolina Szczur: The State of the Web> 性能优化指南The Internet is growing expone ...
- 【公开课】【阿里在线技术峰会】何登成:AliSQL性能优化与功能突破的演进之路
MySQL的公开课,可能目前用不上这些,但是往往能在以后想解决方案的时候帮助到我.以下是阿里对公开课的整理 摘要: 本文根据阿里高级数据库专家何登成在首届阿里巴巴在线技术峰会上的分享整理而成.他主要介 ...
随机推荐
- Codeforces375D Tree and Queries
dsu on tree 题目链接 点我跳转 题目大意 给定一棵 \(n\) 个节点的树,根节点为 \(1\).每个节点上有一个颜色 \(c_i\) \(m\) 次询问. 每次询问给出 \(u\) \( ...
- 不想错过网课?不妨用Camtasia录制下来!
2020年突发的这场疫情给我们的日常生活与学习带来了一些不便,却也意外的让网课走红了起来.小学.中学.大学都开始通过媒体工具或直播平台开始授课,但网络授课与实际课堂上课还是有区别的,学生们受到环境影响 ...
- 【GIT】命令笔记
1.将本地代码提交到github等仓库 1.创建仓库省略 2.切换到本地需要上传的地址 :初始化仓库 git init 3.配置git,告诉git你是谁 git config --global use ...
- CF453C Little Pony and Summer Sun Celebration
如果一个点需要经过奇数次我们就称其为奇点,偶数次称其为偶点. 考虑不合法的情况,有任意两个奇点不连通(自己想想为什么). 那么需要处理的部分就是包含奇点的唯一一个连通块.先随意撸出一棵生成树,然后正常 ...
- 题解 洛谷 P2612 【[ZJOI2012]波浪】DP+高精
题目描述 题目传送门 分析 因为有绝对值不好处理,所以我们强制从小到大填数 设 \(f[i][j][p][o]\) 为当前填到了第 \(i\) 个数,波动强度为 \(j\),有 \(p\) 个连续段并 ...
- 获取Win和Linux系统启动时间,类似uptime功能,用于判断是否修改过系统时间
目录 前言 测试代码 Win测试 Linux测试 总结 前言 有时候需要判断系统是否有修改过时间,最简单的方法就是获取当前时间A,然后sleep X秒,然后获取 时间B,如果 时间B - 时间A ≠ ...
- LeetCode 036 Valid Sudoku
题目要求:Valid Sudoku Determine if a Sudoku is valid, according to: Sudoku Puzzles - The Rules. The Sudo ...
- 思维导图学 Kotlin
前言 最近做了<Kotlin实战>的思维导图笔记,Kotlin真香-- 目录 基础 函数 类.对象 λ表达式 类型 约定 高阶函数.泛型 公众号 coding 笔记.点滴记录,以后的文章也 ...
- 总结一下 php连接oracle,完全可用。
大致有两种方法 第一种 开启php_pdo_oci扩展,一般集成环境都会有这个扩展. 这个东西还是比较简单的,去官网查看吧 http://php.net/manual/zh/book.pdo.php ...
- zookeeper基础笔记
一.安装 1.安装jdk 2.安装Zookeeper 3.单机模式(stand-alone):安装目录/conf 复制 zoo_sample.cfg 并粘贴到当前目录下,命名zoo.cfg. 二. ...