线程池之Executor框架
线程池之Executor框架
Java的线程既是工作单元,也是执行机制。从JDK5开始,把工作机单元和执行机制分离开来。工作单元包括Runnable和Callable,而执行机制由Executor框架提供。
1. Executor框架简介
1.1 Executor框架的两级调度模型
在上层,Java多线程程序通常把应用分解为若干个任务,然后使用用户级的调度器(Executor框架)将这些任务映射为固定数量的线程。
在底层,操作系统内核将这些线程映射到硬件处理器上。
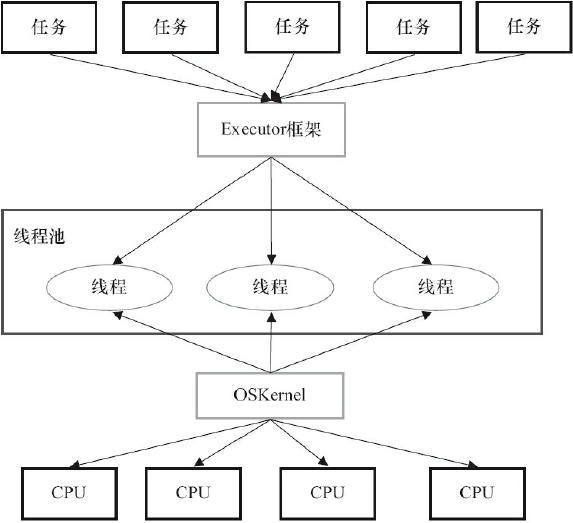
1.2 Executor框架的结构
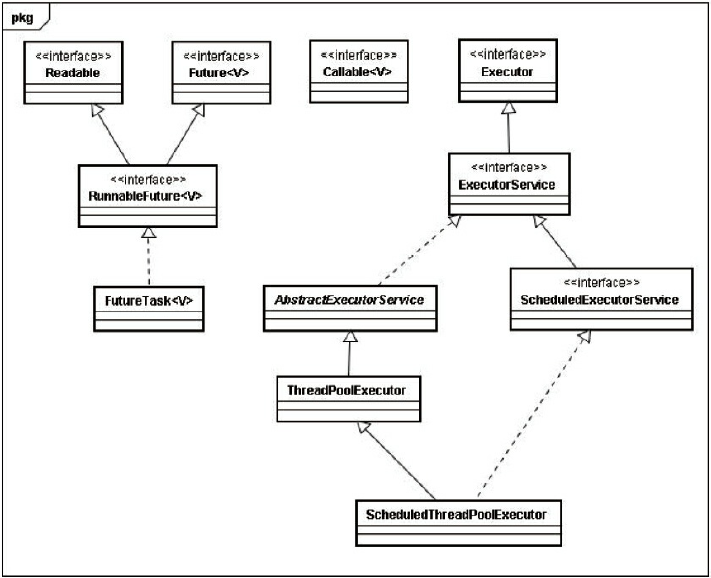
Executor框架主要由3部分组成:
- 任务。包括被执行任务需要实现的接口:Runnable接口或者Callable接口。
- 任务的执行。包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口。Executor框架有两个关键类实现了ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor)。
- 异步计算的结果。包括Future和实现Future的FutureTask类。
Executor框架的成员及其关系可以用一下的关系图表示:
Executor框架的使用示意图:
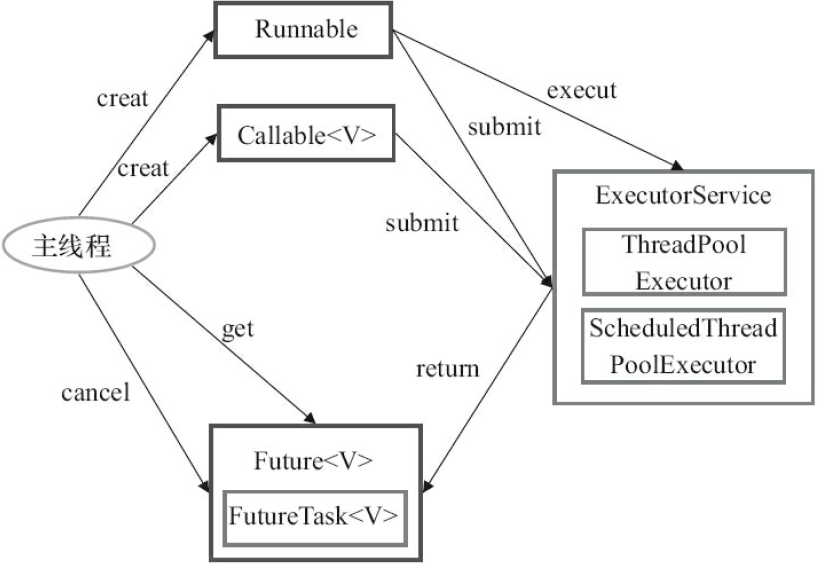
使用步骤:
- 主线程首先创建实现Runnable或Callable接口的任务对象。工具类Executors可以把一个Runnable对象封装为一个Callable对象(
Executors.callable(Runnable task)或Executors.callable(Runnable task, Object result))。 - 创建Executor接口的实现类ThreadPoolExecutor类或者ScheduledThreadPoolExecutor类的对象,然后调用其execute()方法或者submit()方法把工作任务添加到线程中,如果有返回值则返回Future对象。其中Callable对象有返回值,因此使用submit()方法;而Runnable可以使用execute()方法,此外还可以使用submit()方法,只要使用callable(Runnable task)或者callable(Runnable task, Object result)方法把Runnable对象包装起来就可以,使用callable(Runnable task)方法返回的null,使用callable(Runnable task, Object result)方法返回result。
- 主线程可以执行Future对象的get()方法获取返回值,也可以调用cancle()方法取消当前线程的执行。
1.3 Executor框架的使用案例
import java.util.concurrent.*;
public class ExecutorDemo {
// 创建ThreadPoolExecutor实现类
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(
5,
10,
100,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(5),
);
public static void main(String[] args) {
// 采用submit()方法提交Callable对象并返回Future对象
Future<String> future = executor.submit(new callableDemo());
try {
// get()方法获取返回值
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
// 处理异常
e.printStackTrace();
} finally {
// 关闭线程池
executor.shutdown();
}
}
}
/**
* 创建Callable接口的实现类
*/
class callableDemo implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(1000);
String s = "return string";
return s;
}
}
2. Executor框架成员
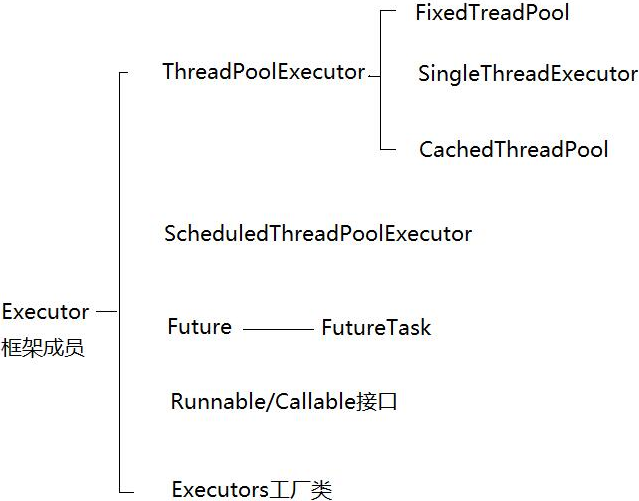
2.1 ThreadPoolExecutor
直接创建ThreadPoolExecutor的实例对象,见https://www.cnblogs.com/chiaki/p/13536624.html
ThreadPoolExecutor通常使用工厂类Executors创建,可以创建3种类型的ThreadPoolExecutor,即FixedThreadPool、SingleThreadExecutor以及CachedThreadPool。
FixedThreadPool:适用于为了满足资源管理的需求,而需要限制当先线程数量的应用场景,适用于负载比较重的服务器。
public static ExecutorService es = Executors.newFixedThreadPool(int threadNums);
public static ExecutorService es = Executors.newFixedThreadPool(int threadNums, ThreadFactory threadFactory);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
把线程池最大线程数量maxmumPoolSize和核心线程池的数量corePoolSize设置为
threadNums,将参数keepAliveTime设置为0L。使用无界队列LinkedBlockingQueue作为阻塞队列,因此当任务不能立刻执行时,都会添加到阻塞队列中,而且maximumPoolSize,keepAliveTime都是无效的。SingleThreadExecutor:适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动地应用场景。**
public static ExecutorService es = Executors.newSingleThreadExecutor();
public static ExecutorService es = Executors.newSingleThreadExecutor(ThreadFactory threadFactory);
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
因为阻塞队列使用的是
LinkedBlockingQueue,因此和FixedThreadPool一样,参数maximumPoolSize以及keepAliveTime都是无效的。corePoolSize为1,因此最多只能创建一个线程。CachedThreadPool:大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
public static ExecutorService es = Executors.newCachedThreadPool();
public static ExecutorService es = Executors.newCachedThreadPool(ThreadFactory threadFactory);
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
CachedThreadPool使用
SynchronizedQueue作为阻塞队列,SynchronizedQueue是不存储元素的阻塞队列,实现“一对一的交付”,也就是说,每次向队列中put一个任务必须等有线程来take这个任务,否则就会一直阻塞该任务,如果一个线程要take一个任务就要一直阻塞知道有任务被put进阻塞队列。因为CachedThreadPool的maximumPoolSize为
Integer.MUX_VALUE,因此CachedThreadPool是无界的线程池,也就是说可以一直不断的创建线程,这样可能会使CPU和内存资源耗尽。corePoolSize为0,因此在CachedThreadPool中直接通过阻塞队列来进行任务的提交。
2.2 ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor类继承了ThreadPoolExecutor并实现了ScheduledExecutorService接口。主要用于在给定的延迟后执行任务或者定期执行任务。
ScheduledThreadPoolExecutor通常使用Executors工厂类来创建,可创建2种类型的ScheduledThreadPoolExecutor,即ScheduledThreadPoolExecutor和SingleThreadScheduledExecutor。
ScheduledThreadPoolExecutor:适用于若干个(固定)线程延时或者定期执行任务,同时为了满足资源管理的需求而需要限制后台线程数量的场景。
public static ScheduledExecutorService ses = Executors.newScheduledThreadPool(int threadNums);
public static ScheduledExecutorService ses = Executors.newScheduledThreadPool(int threadNums, ThreadFactory threadFactory);
SingleThreadScheduledExecutor:适用于需要单个线程延时或者定期的执行任务,同时需要保证各个任务顺序执行的应用场景。
public static ScheduledExecutorService ses = Executors.newSingleThreadScheduledExecutor(int threadNums);
public static ScheduledExecutorService ses = Executors.newSingleThreadScheduledExecutor(int threadNums, ThreadFactory threadFactory);
ScheduledThreadPoolExecutor的实现:
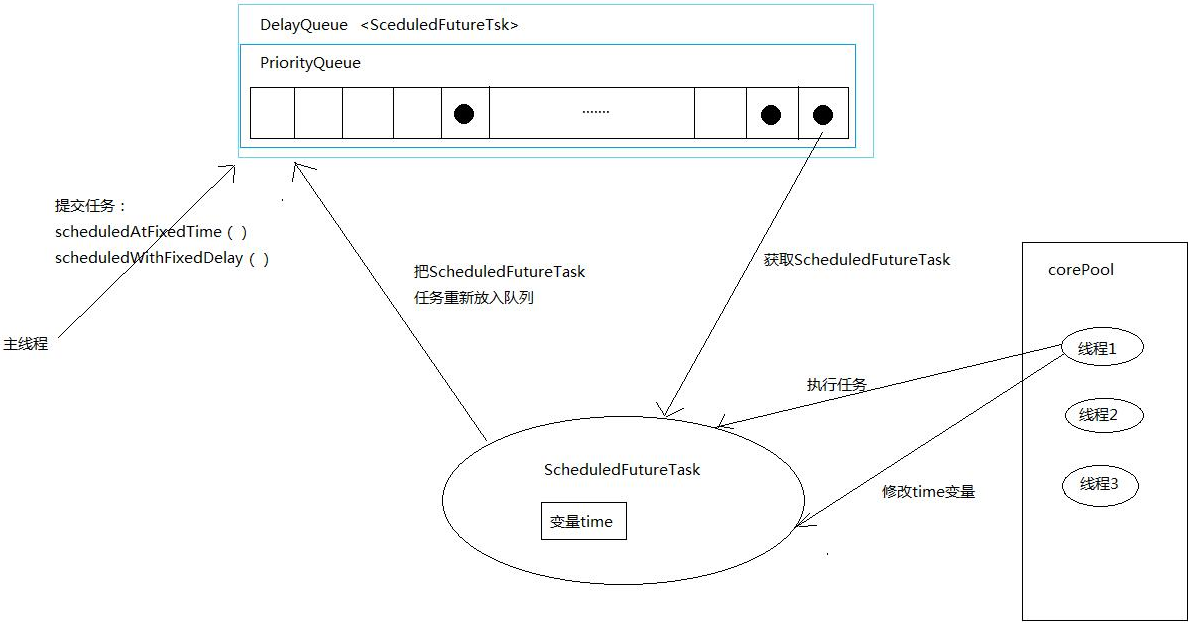
ScheduledThreadPoolExecutor的实现主要是通过把任务封装为ScheduledFutureTask来实现。通过调用scheduledAtFixedTime()方法或者scheduledWithFixedDelay()方法向阻塞队列添加一个实现了RunnableScheduledFutureTask接口的ScheduledFutureTask类对象。ScheduledFutureTask主要包括3个成员变量:
// 序列号,用于保存任务添加到阻塞队列的顺序
private final long sequenceNumber;
// 用于保存该任务将要被执行的具体时间
private long time;
// 周期,用于保存任务直线的间隔周期
private final long period;
ScheduledTreadPoolExecutor的阻塞队列是用无界队列DelayQueue实现的,可以实现元素延时delayTime后才能获取元素,在ScheduledThreadPoolExecutor中,DelayQueue内部封装了一个PriorityQueue,来对任务进行排序,首先对time排序,time小的在前,如果time一样,则sequence小的在前,也就是说如果time一样,那么先被提交的任务先执行。
因为DelayQueue是一个无界的队列,因此线程池的maximumPoolSize是无效的。ScheduledThreadPoolExecutor的工作流程大致如下:
2.3 Future接口/FutureTask实现类
Future接口和实现Future接口的FutureTask实现类,代表异步计算的结果。
2.3.1 FutureTask的使用
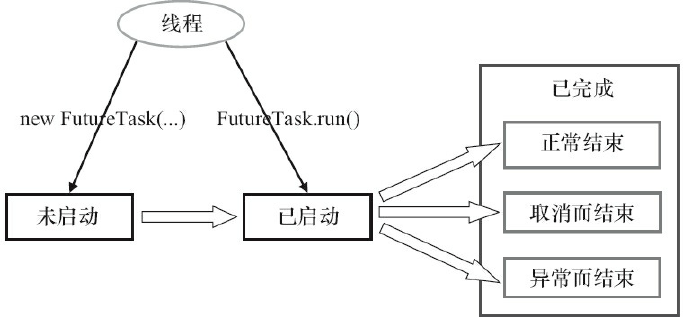
FutureTask除了实现Future接口外还实现了Runnable接口。因此,FutureTask可以交给Executor执行,也可以条用线程直接执行(FutureTask.run())。根据FutureTask.run()方法被执行的时机,FutureTask可处于以下3种状态:
- 未启动:创建了一个FutureTask对象但没有执行FutureTask.run();
- 已启动:FutureTask.run()方法被执行的过程中;
- 已完成:FutureTask.run()正常执行结束,或者FutureTask被取消(
FutureTask.cancel()),或者执行FutureTask.run()时抛出异常而异常结束;
状态迁移示意图:
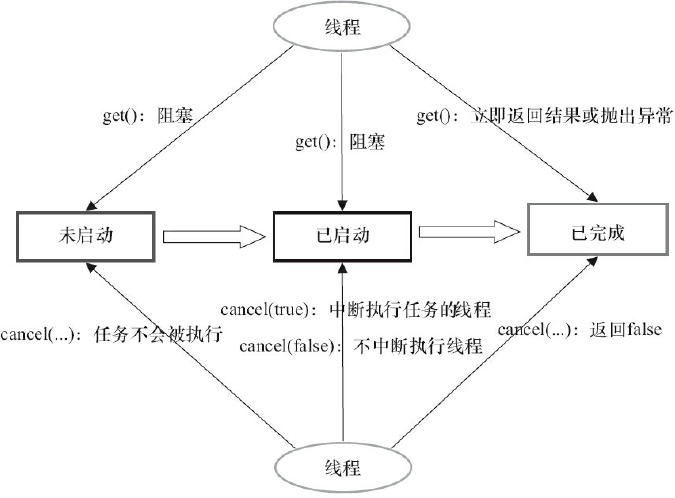
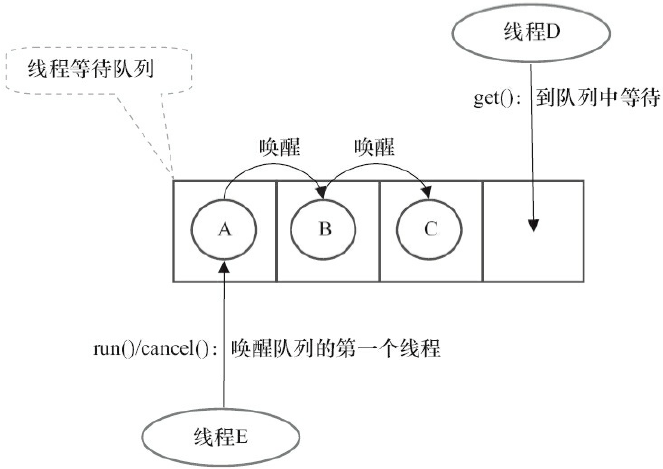
FutureTask的get和cancle执行示意图:
2.3.2 FutureTask的实现
FutureTask是一个基于AQS同步队列实现的一个自定义同步组件,通过对同步状态state的竞争实现acquire或者release操作。
FutureTask的内部类Sync实现了AQS接口,通过对tryAcquire等抽象方法的重写和模板方法的调用来实现内部类Sync的tryAcquireShared等方法,然后聚合Sync的方法来实现FutureTask的get和cancel等方法。
FutureTask的设计示意图:
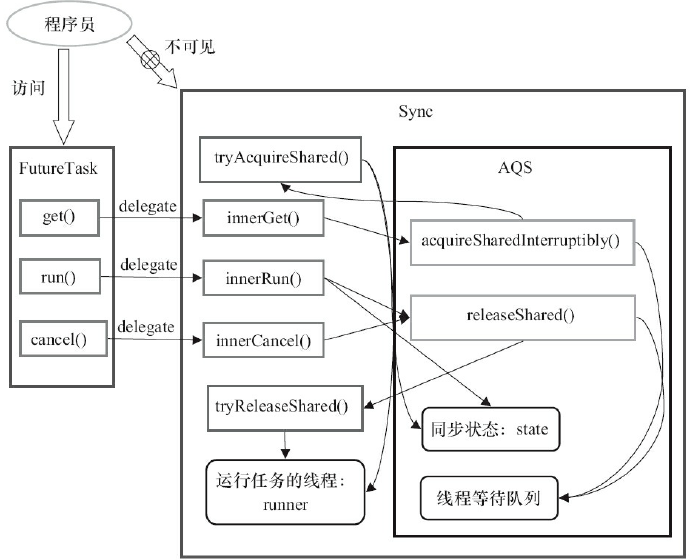
FutureTask的get方法最终会调用AQS.acquireSharedInterruptibly(int arg)方法:
- 调用
AQS.acquireSharedInterruptibly(int arg)方法会首先调用tryAcquireShared()方法判断acquire操作是否可以成功,可以成功的条件是state为执行完成状态RAN或者已取消状态CANCELLED,且runner不为null; - 如果成功则
get()方法立即返回,如果失败则到线程等待队列执行release操作; - 当其他线程执行release操作唤醒当前线程后(比如
FutureTask.run()或FutureTask.cancle(...)),当前线程再次执行tryAcquireShared()将返回正值1,当前线程离开现场等待队列并唤醒它的后继线程(级联唤醒); - 最后返回计算的结果或抛出异常。
2.3.3 FutureTask的使用场景
- 当一个线程需要等待另一个线程把某个任务执行完以后它才能继续执行时;
- 有若干线程执行若干任务,每个任务最多只能被执行一次;
- 当多个线程师徒执行同一个任务,但只能允许一个线程执行此任务,其它线程需要等这个任务被执行完毕以后才能继续执行时。
2.4 Runnable和Callable接口
用于实现线程要执行的工作单元。
2.5 Executors工厂类
提供了常见配置线程池的方法,因为ThreadPoolExecutor的参数众多且意义重大,为了避免配置出错,才有了Executors工厂类。
3. 为什么不建议使用Executors创建线程池?
FixedThreadPool和SingleThreadExecutor:允许请求的队列长度为Integer.MAX_VALUE(无界的阻塞队列),可能堆积大量的请求,从而导致OOM。
CachedThreadPool和ScheduledThreadPool:允许创建的线程数量为Integer.MAX_VALUE(无界的阻塞队列),可能会创建大量线程,从而导致OOM。
线程池之Executor框架的更多相关文章
- Java多线程学习(八)线程池与Executor 框架
目录 历史优质文章推荐: 目录: 一 使用线程池的好处 二 Executor 框架 2.1 简介 2.2 Executor 框架结构(主要由三大部分组成) 2.3 Executor 框架的使用示意图 ...
- 线程池及Executor框架
1.为什么要使用线程池? 诸如 Web 服务器.数据库服务器.文件服务器或邮件服务器之类的许多服务器应用程序都面向处理来自某些远程来源的大量短小的任务.请求以某种方式到达服务器,这种方式可能是通过 ...
- 线程池:Execution框架
每问题每线程:在于它没有对已创建线程的数量进行任何限制,除非对客户端能够抛出的请求速率进行限制. 下边 有些图片看不到,清看原地址:http://www.360doc.com/content/10/1 ...
- 并发07--线程池及Executor框架
一.JAVA中的线程池 线程池的实现原理及流程如下图所示: 如上图所示,当一个线程提交到线程池时(execute()或submit()),先判断核心线程数(corePoolSize)是否已满,如果未满 ...
- 001-多线程-JUC线程池-线程池架构-Executor、ExecutorService、ThreadPoolExecutor、Executors
一.概述 1.1.线程池架构图 1. Executor 它是"执行者"接口,它是来执行任务的.准确的说,Executor提供了execute()接口来执行已提交的 Runnable ...
- B2. Concurrent 线程池(Executor)
[概述] 与数据库连接管理类似,线程的创建和销毁会耗费较大的开销,使用 “池化技术” 来更好地利用当前线程资源,减少因线程创建和销毁带来的开销,这就是线程池产生的原因. [无限创建线程的不足] 在生产 ...
- Java线程池学习
Java线程池学习 Executor框架简介 在Java 5之后,并发编程引入了一堆新的启动.调度和管理线程的API.Executor框架便是Java 5中引入的,其内部使用了线程池机制,它在java ...
- 《java并发编程实战》读书笔记5--任务执行, Executor框架
第6章 任务执行 6.1 在线程中执行任务 第一步要找出清晰的任务边界.大多数服务器应用程序都提供了一种自然的任务边界选择方式:以独立的请求为边界. -6.6.1 串行地执行任务 最简单的任务调度策略 ...
- Java并发编程-Executor框架(转)
本文转自http://blog.csdn.net/chenchaofuck1/article/details/51606224 感谢作者 我们在传统多线程编程创建线程时,常常是创建一些Runnable ...
随机推荐
- OpenLDAP on Centos7
一.环境准备 echo nameserver 114.114.114.114 > /etc/resolv.conf ##更改DNSecho 192.168.0.190 hello.com > ...
- 数据库事务的四个特性ACID
原子性[Atomicity] 原子性指的指的就是这个操作,要么全部成功,要么全部失败回滚.不存在其他的情况. 一致性(Consistency) 一致性是指事务必须使数据库从一个一致性状态变换到另一个一 ...
- JWT生成Token做登录校验
一.JWT的优点 1.服务端不需要保存传统会话信息,没有跨域传输问题,减小服务器开销. 2.jwt构成简单,占用很少的字节,便于传输. 3.json格式通用,不同语言之间都可以使用. 二.使用JWT进 ...
- vue同时安装element ui跟 vant
记一个卡了我比较久的问题,之前弄的心态爆炸各种问题. 现在来记录一下,首先我vant是已经安装成功了的. 然后引入element ui npm i element-ui -S 接着按需引入,安装插件 ...
- dubbo泛化调用 小demo
前两天刚好有个同事来问是否用过 dubbo泛化 调用,不需要通过指定配置.第一次听到的时候,还是有点懵,但觉得有意思,可以学点东西. 立马百度了,找了demo,这篇比较容易上手(http://www. ...
- Python 爬取网易云歌手的50首热门作品
使用 requests 爬取网易云音乐 Python 代码: import json import os import time from bs4 import BeautifulSoup impor ...
- Python time strftime()方法
描述 Python time strftime() 函数接收以时间元组,并返回以可读字符串表示的当地时间,格式由参数format决定.高佣联盟 www.cgewang.com 语法 strftime( ...
- 使用pdf.js实现前端页面预览pdf文档,解决了跨域请求
pdf.js主要包含两个库文件,一个pdf.js和一个pdf.worker.js,,一个负责API解析,一个负责核心解析 官网地址:http://mozilla.github.io/pdf.js/ 下 ...
- ajax模拟表单提交,后台使用npoi实现导入操作 方式一
页面代码: <form id="form1" enctype="multipart/form-data"> <div style=" ...
- JDK8的Optional用法
参考资料:https://www.baeldung.com/java-optional https://mp.weixin.qq.com/s/P2kb4fswb4MHfb0Vut_kZg 1. 描述 ...