python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame
关注公众号“轻松学编程”了解更多。
以下命令都是在浏览器中输入。
cmd命令窗口输入:jupyter notebook
打开浏览器输入网址http://localhost:8888/
一、导入模块
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
二、DataFrame
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
1、 DataFrame的创建
1.1 使用ndarray创建DataFrame
DataFrame(data=np.random.randint(60,100,size=(2,3)),
index=['期中','期末'],
columns=['张三','李四','王老五'])

1.2 使用字典创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引。
使用字典创建的DataFrame后,则columns参数将不可被使用。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
dic={
'期中':[50,60,70],
'期末':[80,90,89]
}
#使用字典创建一个DataFrame
df=DataFrame(data=dic,index=['张三','李四','王老五'])
df

1.3 DataFrame属性:values、columns、index、shape
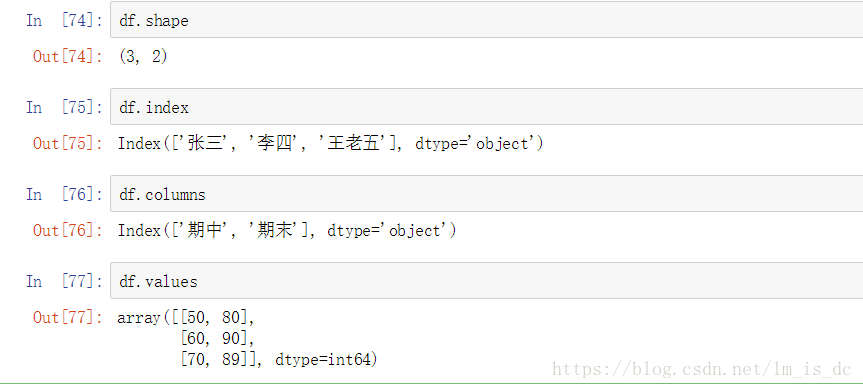
2、 DataFrame的索引
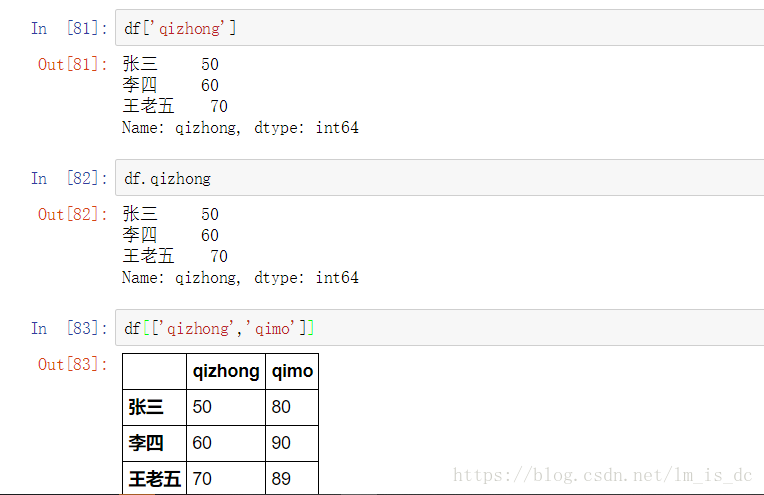
2.1 对列进行索引
- 通过类似字典的方式 df[‘q’]
- 通过属性的方式 df.q
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
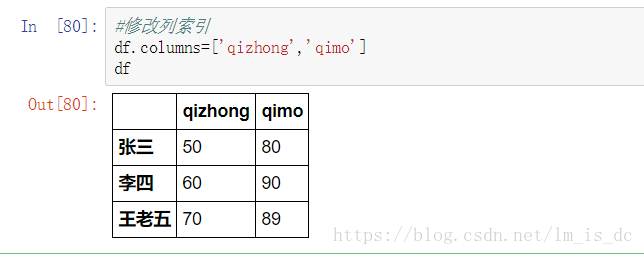
#修改列索引
df.columns=['qizhong','qimo']
df
df['qizhong]
df.qizhong
df[['qizhong','qimo']]
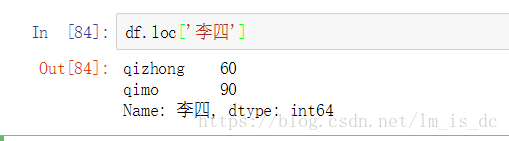
2.2 对行进行索引
- 使用.loc[]加index来进行行索引
- 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。
df.loc['李四']
df.iloc[1]
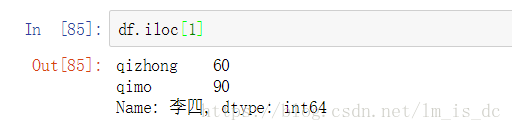
2.3 对元素进行索引的方法
- 使用列索引
- 使用行索引(iloc[3,1] or loc[‘C’,‘q’]) 行索引在前,列索引在后
df.loc['王老五','qimo']

3、切片
使用冒号进行切片。
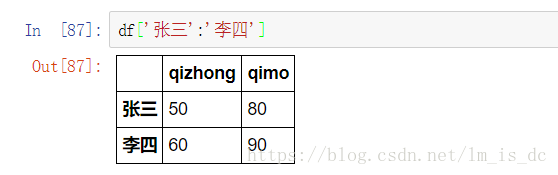
3.1 使用中括号
df['张三':'李四']
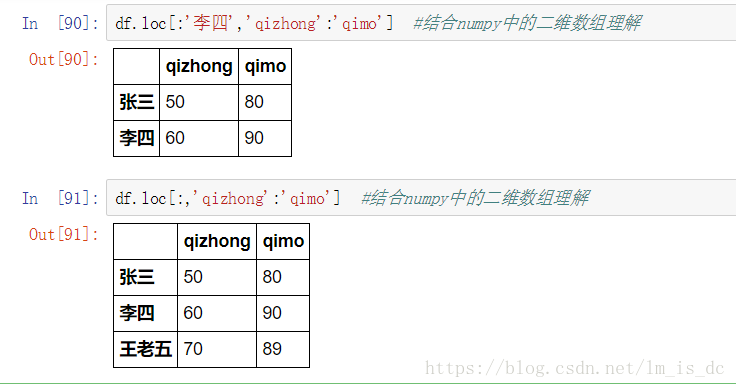
3.2 使用loc和iloc中
如: df.loc[‘B’:‘C’,‘丙’:‘丁’]
df.loc[:'李四','qizhong':'qimo'] #结合numpy中的二维数组理解
【注意】 直接用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
4、 DataFrame的运算
DataFrame之间的运算
同Series一样:
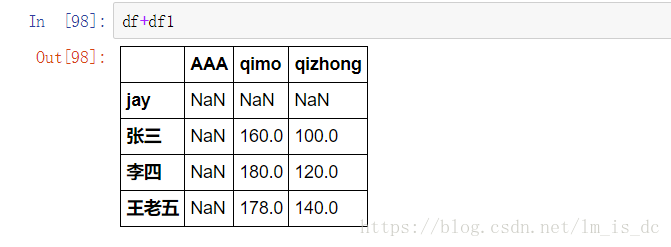
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
4.1 DataFrame之间的运算
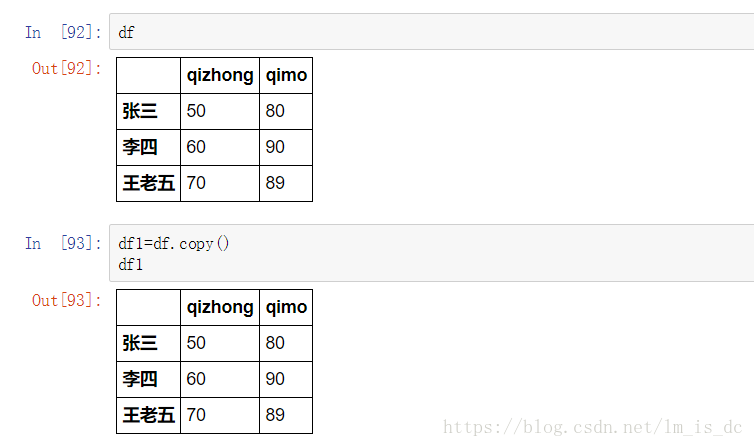
df1=df.copy() #创建df的一个副本
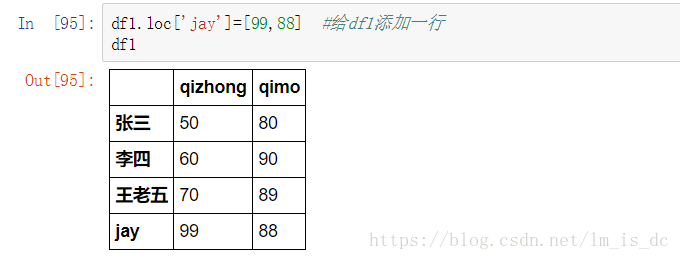
df1.loc['jay']=[99,88] #给df1添加一行
df1
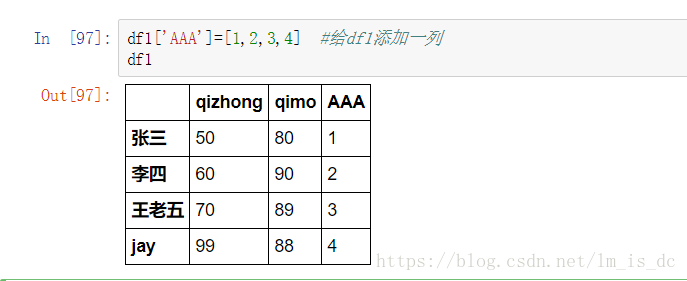
df1['AAA']=[1,2,3,4] #给df1添加一列
df1
df+df1
下面是Python 操作符与pandas操作函数的对应表:
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
5、DataFrame的去重
df.drop_duplicates(subset=None, keep=‘first’, inplace=False)
参数:
- subset:指定是哪些列重复
- keep:去重后留下第几行,{‘first’, ‘last’, False}, default ‘first’}
如果是False,则去除全部重复的行。 - inplace:是否作用于原来的df
df = pd.DataFrame(data=[[1,2,3],
[1,2,4],
[1,2,4],
[1,2,3],
[1,2,5],
[1,2,5]],
columns=['a','b','c'])
df

#去除重复行,保留重复行中最后一行
df.drop_duplicates(keep='last')

#去除'c'列中有重复的值所在的行
df.drop_duplicates(subset=('c',))

#去除重复行,默认保留重复行中第一行,作用于原来的df
df.drop_duplicates(inplace=True)
df

三、处理丢失数据
有两种丢失数据类型:
- None
- np.nan(NaN)
1. None
None是Python自带的,其类型为python object。因此,None不能参与到任何计算中。
#查看None的数据类型
type(None)
结果为:
NoneType
2. np.nan(NaN)
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。
type(np.nan)
结果为:
float
np.nan+10
结果为:
nan
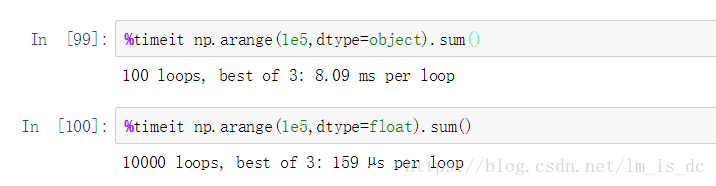
object类型的运算要比int类型的运算慢得多
计算不同数据类型求和时间
%timeit np.arange(1e5,dtype=object).sum()
%timeit np.arange(1e5,dtype=float).sum()
object:运行时间的8.09ms;
float:运行时间是3.159us,可看出使用object做运算,很耗时。
3. pandas中的None与NaN
3.1 pandas中None与np.nan都视作np.nan
在pandas中,None和np.nan统一处理成NAN,numpy并不处理。
处理成NaN,float型,可用于计算,计算结果为NaN.
3.2 pandas处理空值操作
isnull()如果为NaN就返回True,否则返回Falsenotnull()如果为NaN就返回False,否则返回Truedropna(): 过滤丢失数据(NaN)fillna(): 填充丢失数据(NaN)
#创建DataFrame,给其中某些元素赋值为nan
df=DataFrame(np.random.randint(1,100,size=(4,6)),
index=['A','B','C','D'],
columns=['a','b','c','d','e','f'])
df

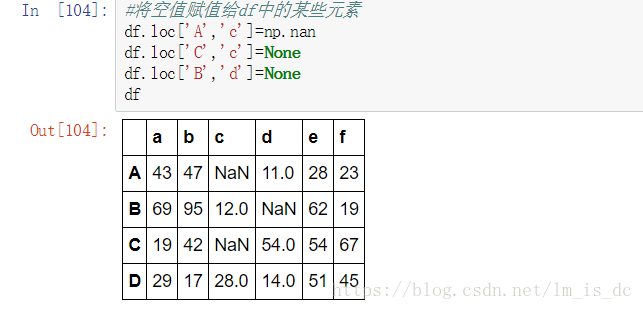
#将空值赋值给df中的某些元素
df.loc['A','c']=np.nan
df.loc['C','c']=None
df.loc['B','d']=None
df
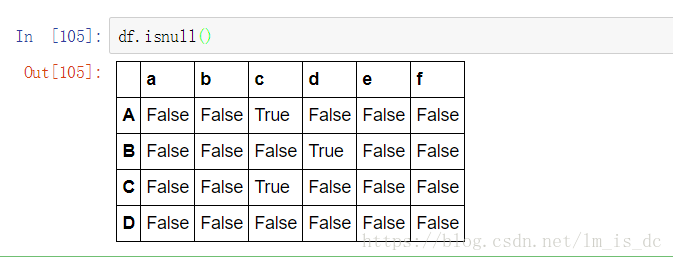
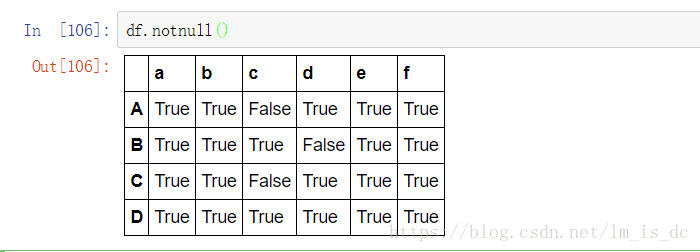
(1)判断函数
isnull()notnull()
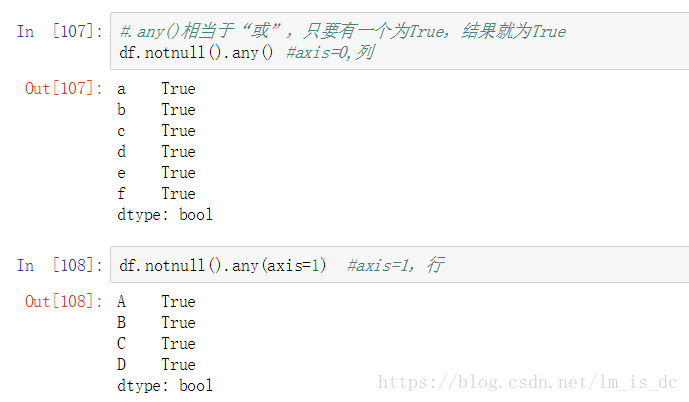
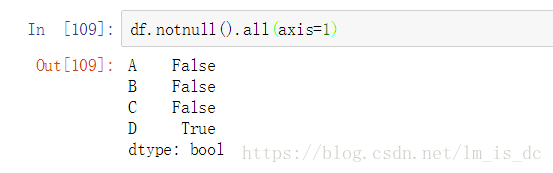
(2)df.notnull().any()/all()
#.any()相当于“或”,只要有一个为True,结果就为True
df.notnull().any() #axis=0,列
判断哪些行中存在空值
#.all()相当于"与",只要有一个为False,结果就为False
df.notnull().all(axis=1)
结果说明只有D行没有空值。
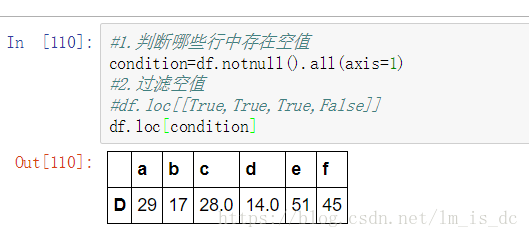
过滤空值:
#1.判断哪些行中存在空值
condition=df.notnull().all(axis=1)
#2.过滤空值
#df.loc[[True,True,True,False]]
df.loc[condition]
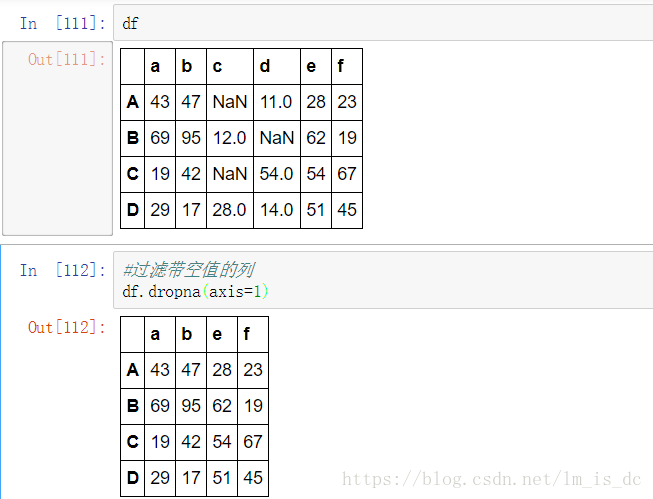
df.dropna() 可以选择过滤的是行还是列(默认为行):axis中0表示行,1表示的列 。
过滤带空值的列
df.dropna(axis=1)
how参数:有两个值’all’表示是所有为空值才过滤;'any’表示有一个为空值就过滤。
默认为’any’,一般使用’any’。

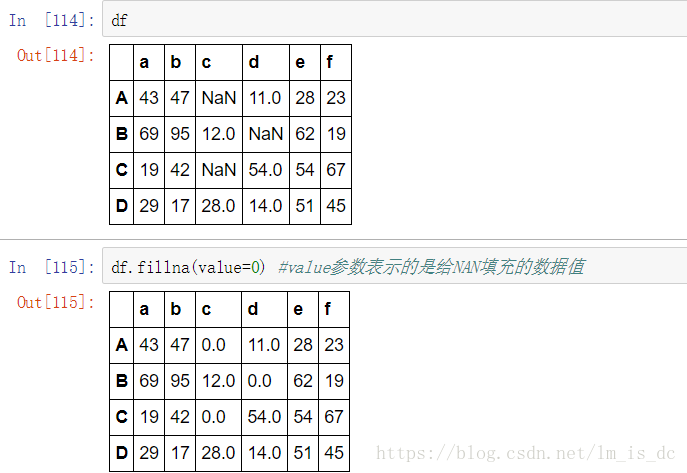
3.3 填充函数
适用于 Series和DataFrame 。
fillna():value和method参数。
value参数表示的是给NAN填充的数据值:
df.fillna(value=0)
method 控制填充的方式 有4种选择,常用(bfill和ffill) 前向填充还是后向填充 。
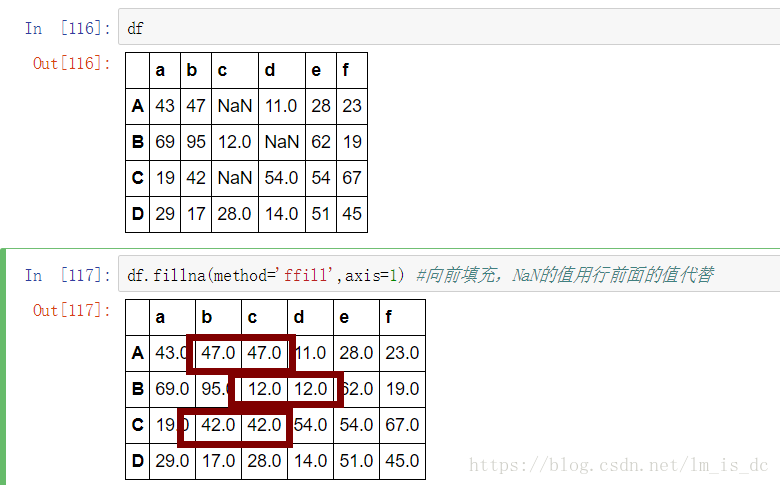
#向前填充,NaN的值用行前面的值代替
#axis=0,则用列前面的值代替
#如果前面没有值,则还是NaN
df.fillna(method='ffill',axis=1)
limit 参数:控制填充的次数
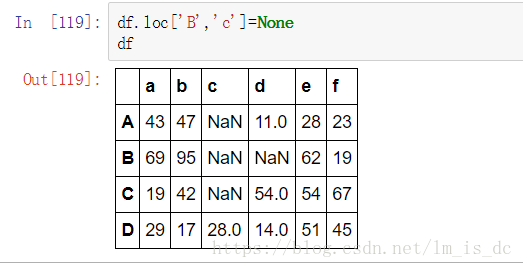
df.loc['B','c']=None
df
#向后填充,列后面的值代替NaN,只填充2次
df.fillna(method='bfill',axis=0,limit=2)

四、创建多层列索引
#导入库
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1、隐式构造
最常见的方法是给DataFrame构造函数的index或者columns参数传递两个或更多的数组
DataFrame(data=np.random.randint(60,120,size=(2,4)),
columns=[['qizhong','qizhong','qimo','qimo'],
['chinese','math','chinese','math']],
index=['tom','jay'])

2、显示构造pd.MultiIndex.from_
2.1 使用数组
#创建了一个索引对象,该索引对象为二层索引
col=pd.MultiIndex.from_arrays([['qizhong','qizhong','qimo','qimo'],
['chinese','math','chinese','math']])
#创建DF对象
DataFrame(data=np.random.randint(60,120,size=(2,4)),index=['tom','jay'],
columns=col)

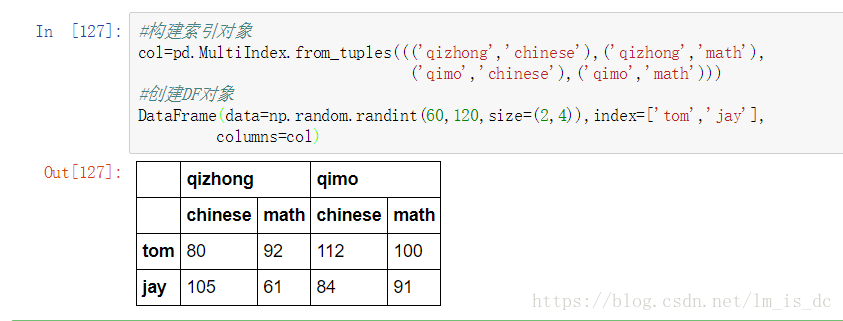
2.2 使用tuple (元组)
#构建索引对象
col=pd.MultiIndex.from_tuples((('qizhong','chinese'),
('qizhong','math'),
('qimo','chinese'),
('qimo','math')))
#创建DF对象
DataFrame(data=np.random.randint(60,120,size=(2,4)),
index=['tom','jay'],
columns=col)
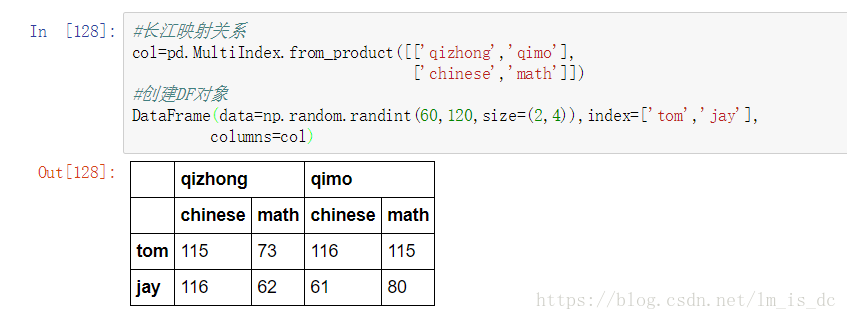
2.3 使用product
最简单,推荐使用
#长江映射关系
col=pd.MultiIndex.from_product([['qizhong','qimo'],
['chinese','math']])
#创建DF对象
DataFrame(data=np.random.randint(60,120,size=(2,4)),
index=['tom','jay'],
columns=col)
五、创建多层行索引
除了行索引index,列索引columns也能用同样的方法创建多层索引
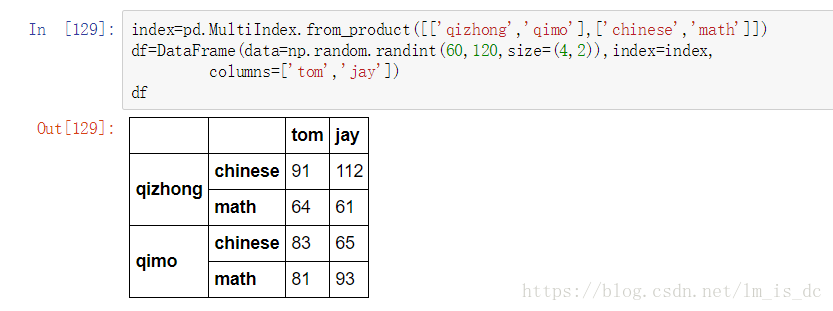
index=pd.MultiIndex.from_product([['qizhong','qimo'],
['chinese','math']])
df=DataFrame(data=np.random.randint(60,120,size=(4,2)),
index=index,
columns=['tom','jay'])
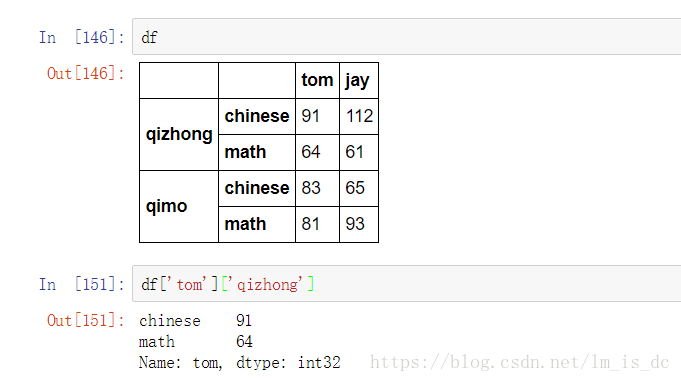
df
六、多层索引对象的索引与切片操作
1、 Series的操作
- Series也会存在多级索引操作
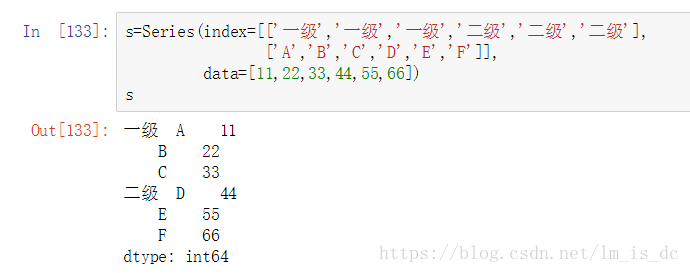
s=Series(index=[['一级','一级','一级','二级','二级','二级'],
['A','B','C','D','E','F']],
data=[11,22,33,44,55,66])
s
1.1 索引
【重要】对于Series来说,直接中括号[]与使用.loc()完全一样,
推荐使用.loc[]索引和切片。
不能跨级(索引级别:一级索引,二级索引)操作。
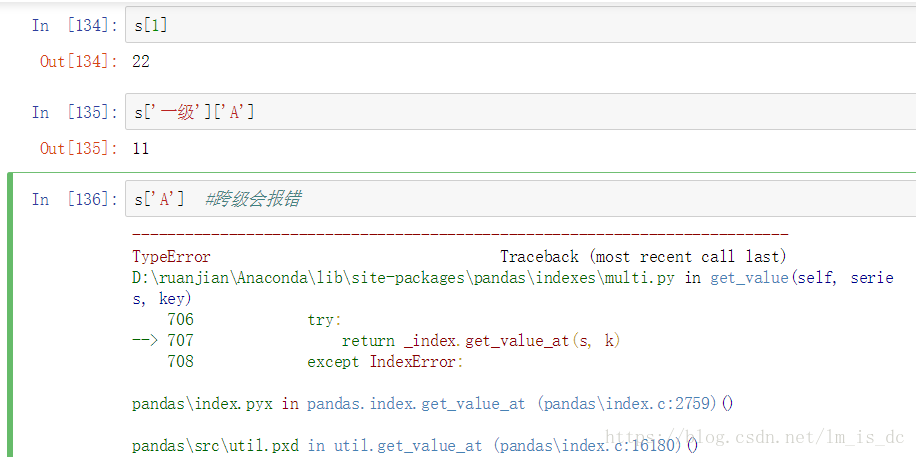
s.loc['一级']

1.2 切片
通过冒号进行切片

2、 DataFrame的操作
2.1 使用列名称来进行列索引
df['tom']['qizhong']
2.2 使用行名称来进行行索引
使用行索引需要用ix[]==iloc[],loc[]
【极其重要】推荐使用loc()函数
df.loc['qimo'].loc['math']
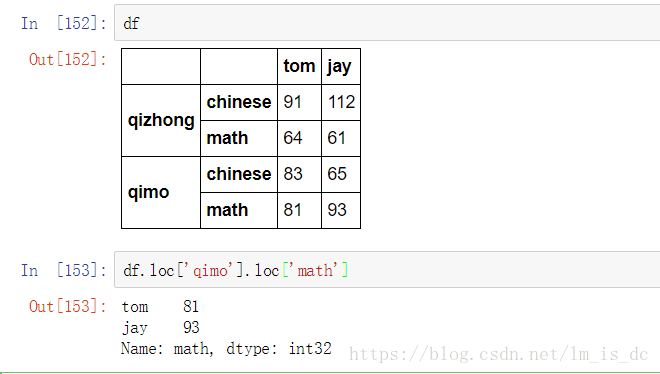
df.ix[0] #与df.iloc[0]效果一样

2.3 切片
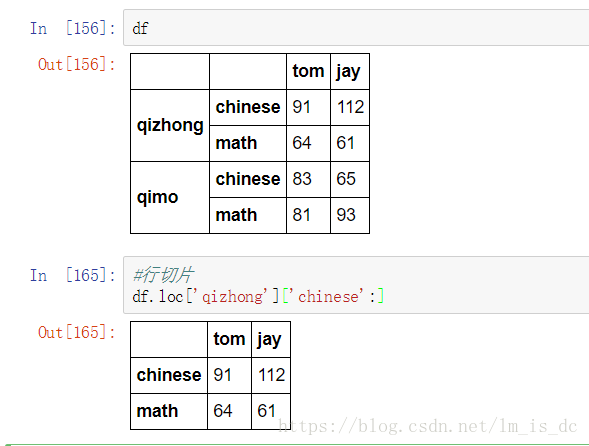
#行切片
df.loc['qizhong']['chinese':]
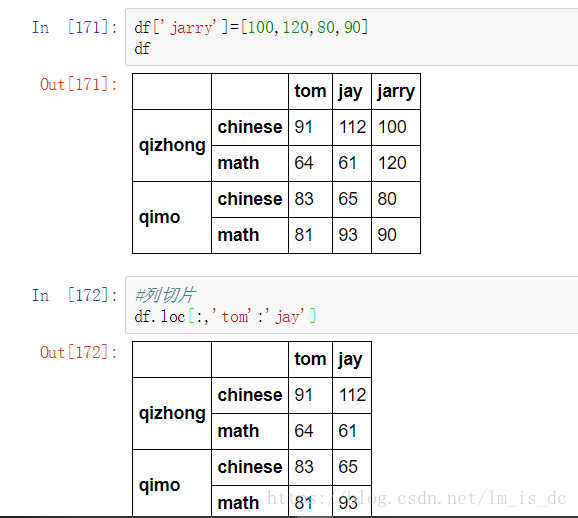
#列切片
df.loc[:,'tom':'jay']
总结:
访问一列或多列 直接用中括号[columnname]
如: [[columname1,columnname2...]]
访问一行或多行 .loc[indexname]
访问某一个元素 .loc[indexname,columnname]
行切片 .loc[index1:index2]
列切片 .loc[:,column1:column2]
七、索引的堆(stack)
对矩阵的索引进行变换处理
stack():把列索引变成行索引 (从上到左)unstack():把行索引变成列索引(从左到上)
1、 stack()
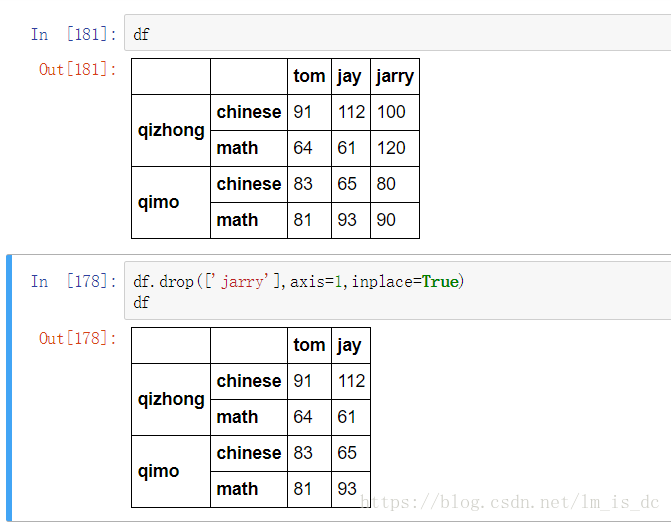
删除列
#axis=1表示删除行,axis=0表示删除列
df.drop(['jarry'],axis=1,inplace=True)
df
#
df.stack()
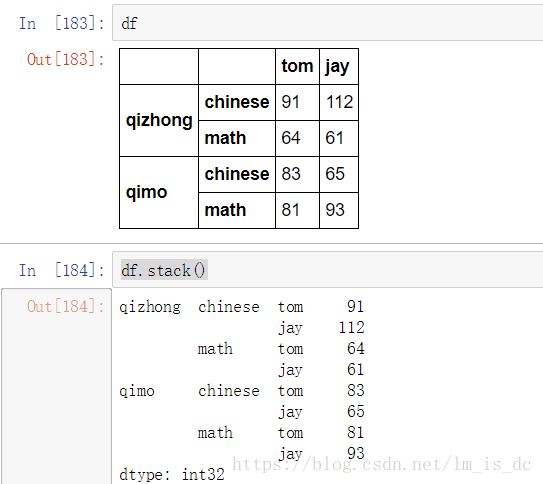
2、 unstack()
df.unstack()
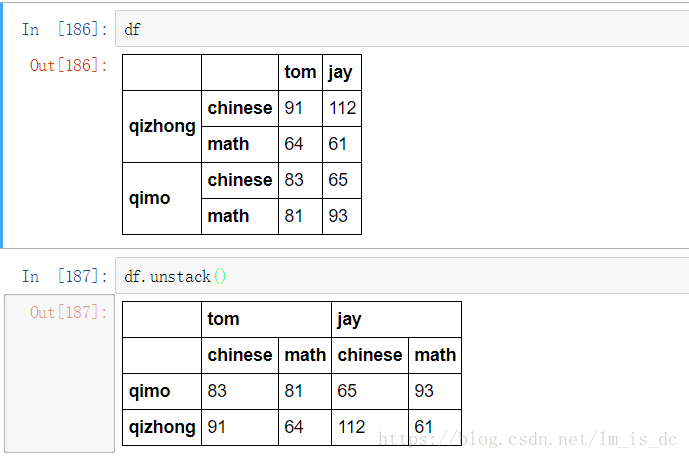
3、level参数
stack()和unstack()都有一个参数level,表示是把哪一级索引进行变换。
df.unstack(level=0)
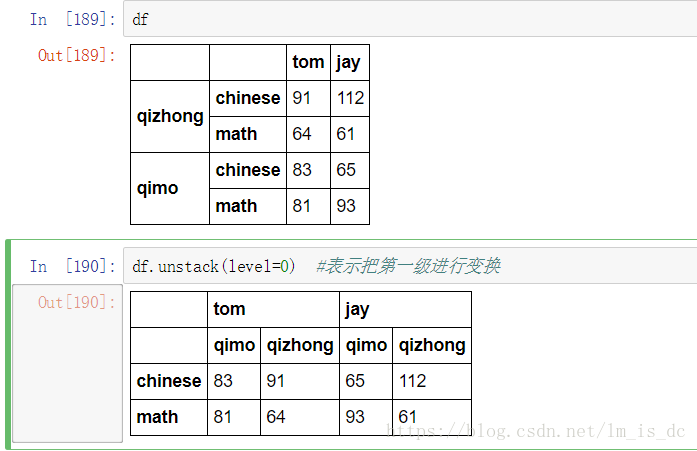
【小技巧】使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
【小技巧】使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
八、聚合操作
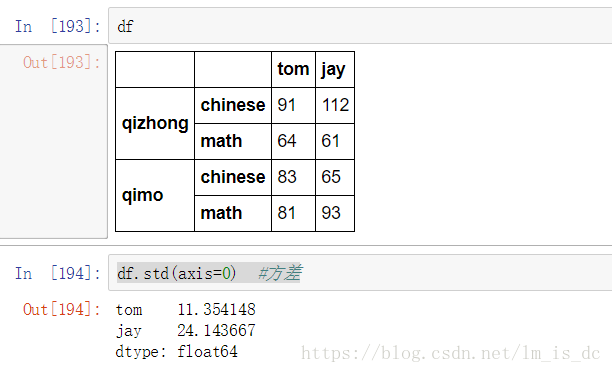
所谓的聚合操作:平均数,方差,最大值,最小值……
df.mean()

df.std(axis=0) #方差
下面是Python 操作符与pandas操作函数的对应表:
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
九、pandas的拼接操作
pandas的拼接分为两种:
- 级联:pd.concat, pd.append
- 合并:pd.merge, pd.join
1、级联
1.1 使用pd.concat()级联
#创建两个3*3的矩阵
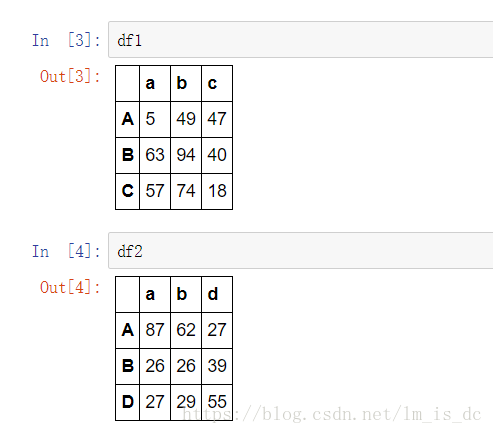
df1=DataFrame(np.random.randint(0,100,size=(3,3)),
index=['A','B','C'],columns=['a','b','c'])
df2=DataFrame(np.random.randint(0,100,size=(3,3)),
index=['A','B','D'],columns=['a','b','d'])
pandas使用pd.concat函数进行级联,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,
outer会将所有的项进行级联(忽略匹配和不匹配),
而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
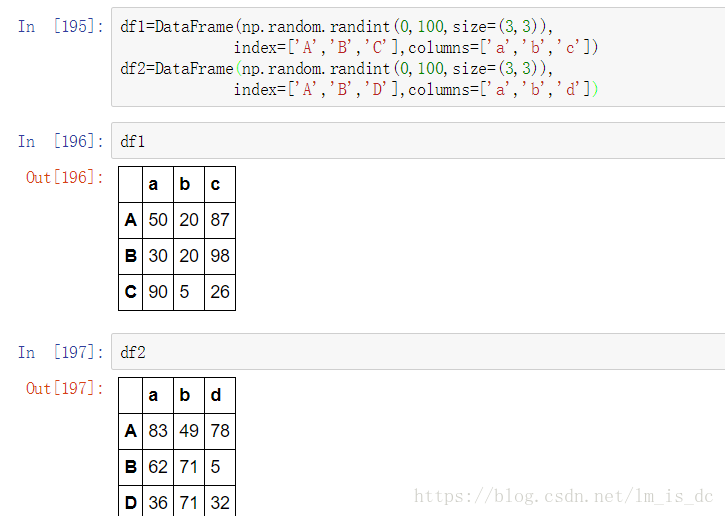
pd.concat([df1,df2],axis=0) #axis=0表示以列连接列的方式级联

pd.concat([df1,df2],axis=1) #axis=1表示以行连接行的方式级联
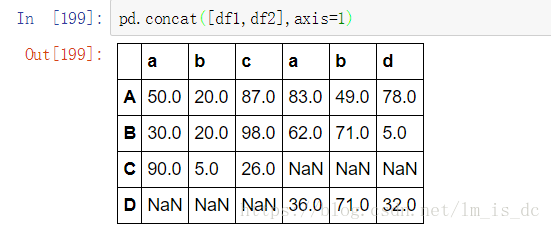
#keys可以用来增加多级索引,标记出原先的表
pd.concat([df1,df2],axis=1,keys=['df1','df2'])
1.2 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
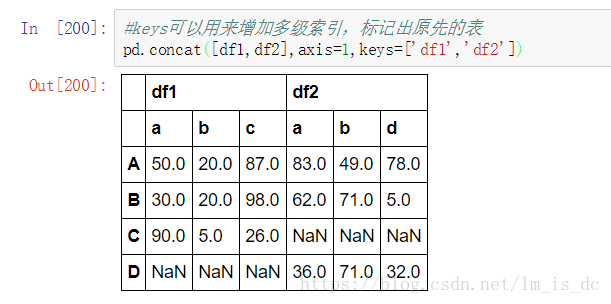
#join默认为'outer',当join='inner'时表示不匹配的将不级联
pd.concat([df1,df2],axis=1,
keys=['df1+++','df2+++'],join='inner')
不同行不同列的两个矩阵进行级联
df3=DataFrame(np.random.randint(0,100,size=(4,4)),
index=['A','B','C','D'],
columns=['a','b','c','d'])
df4=DataFrame(np.random.randint(0,100,size=(3,3)),
index=['A','B','D'],
columns=['a','b','d'])
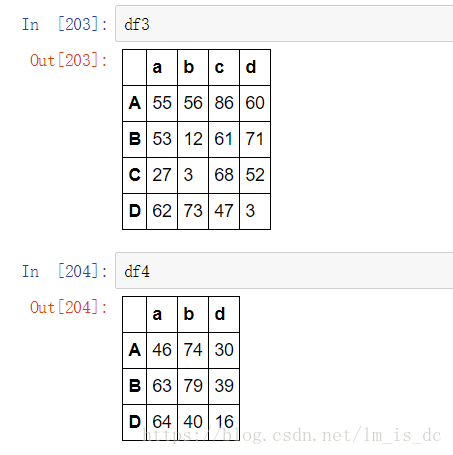
pd.concat([df3,df4])
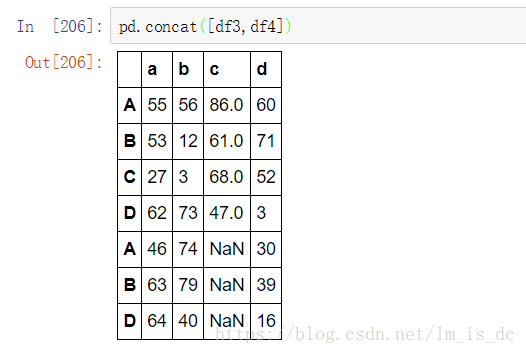
1.3 使用df.append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数append专门用于在后面添加 :
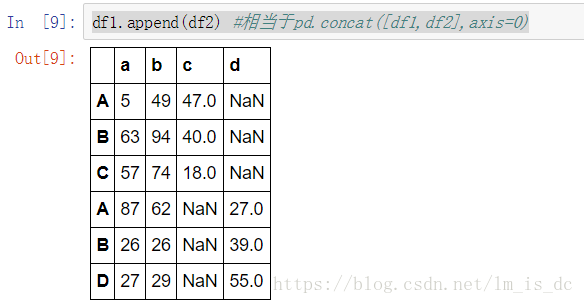
df1.append(df2) #相当于pd.concat([df1,df2],axis=0)
2、合并
使用pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
参数:
- how:outer取并集, inner取交集,left:左合并(包含左表的所有数据,不一定包含右表的所有数据),right:右合并(跟左合并相反)
- on:当有多列相同的时候,可以使用on来指定使用那一列进行合并,on的值为一个列表
2.1 一对一合并
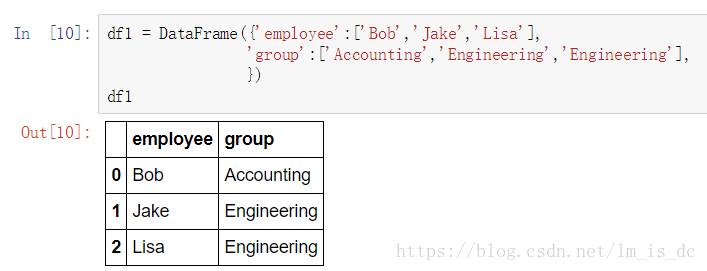
#创建df1
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering',
'Engineering'],
})
df1
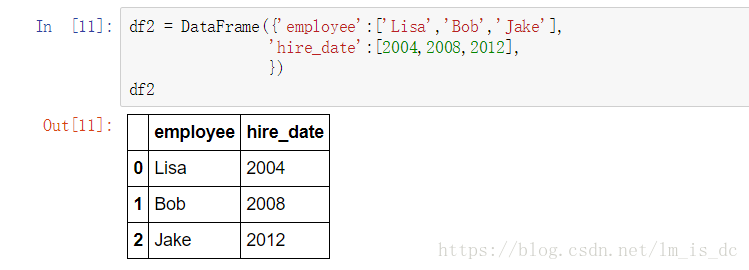
#创建df2
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
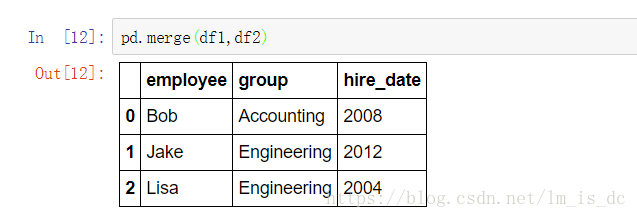
#merge()会自动把df1和df2中的‘employee’合并
pd.merge(df1,df2)
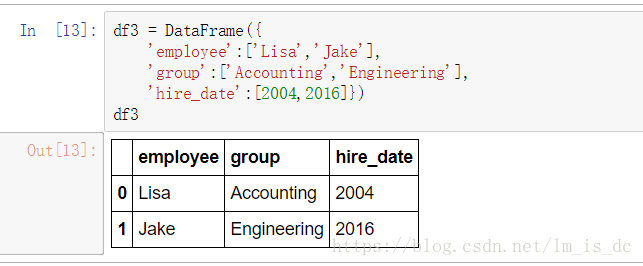
2.2 多对一合并
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
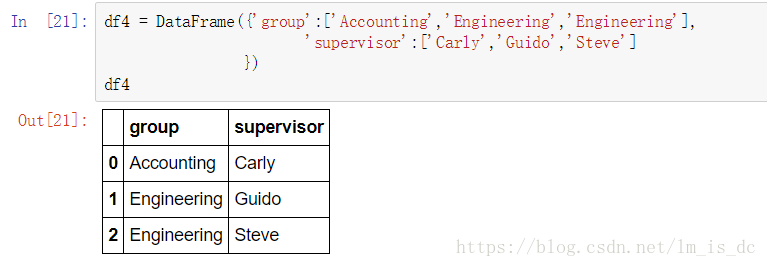
df4 = DataFrame({'group':['Accounting','Engineering',
'Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
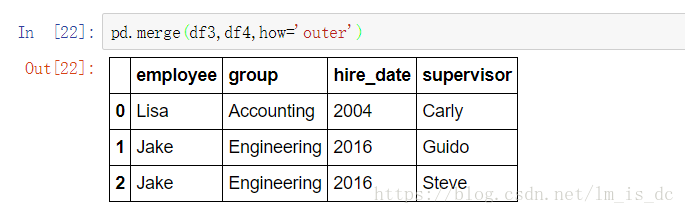
pd.merge(df3,df4,how='outer')
2.3 多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering',
'Engineering']})
df1

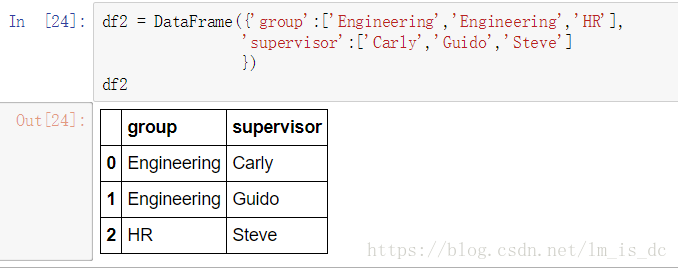
df2=DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df2
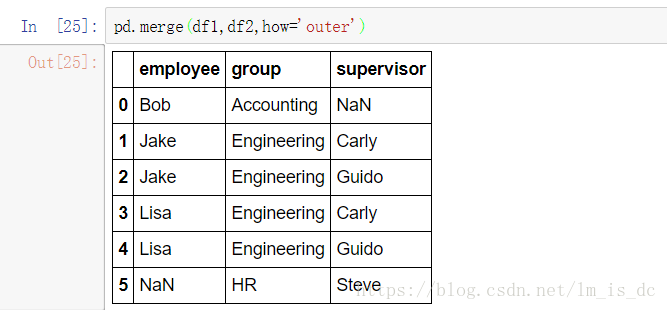
pd.merge(df1,df2,how='outer')
2.4 加载Excel、CSV表格数据
加载excel数据:pd.read_excel(‘excel_path’,sheetname=1)
参数excel_path为Excel文件绝对路径,sheetname为第几个表格(下标从0开始)
加载csv数据:pd.csv(‘csv_path’)
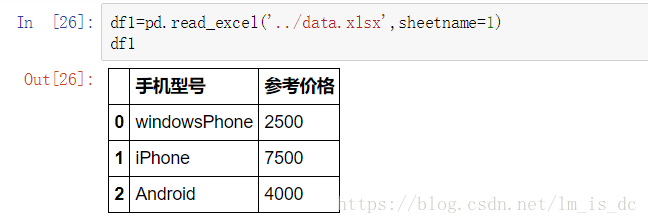
df1=pd.read_excel('../data.xlsx',sheetname=1)
df1
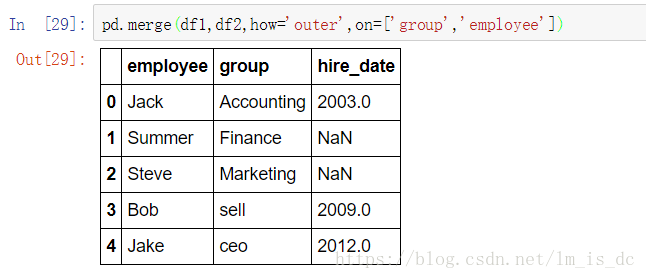
2.5 key的规范化
- 使用on=显式指定哪一列为key,当有多个key相同时使用
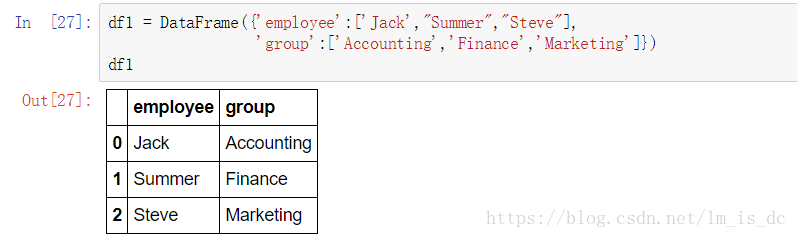
df1 = DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance',
'Marketing']})
df1
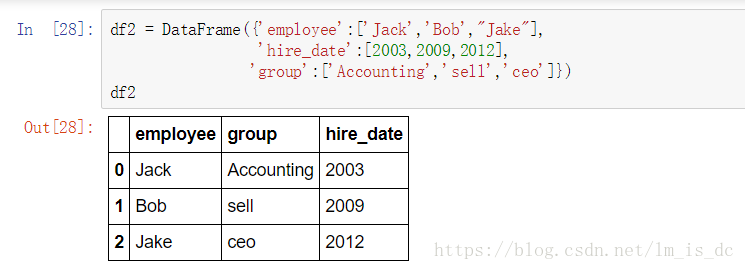
df2 = DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']})
df2
pd.merge(df1,df2,how='outer',on=['group','employee'])
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列作为连接的列
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product',
'Marketing'],
'hire_date':[1998,2017,2018]})
df1
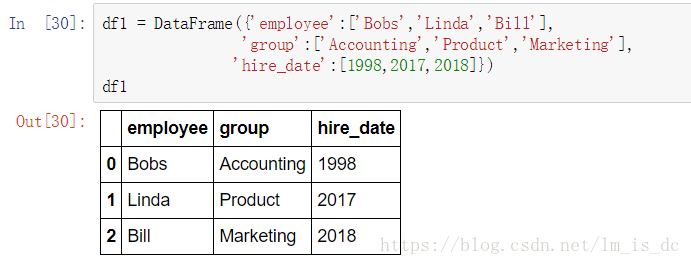
df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df5
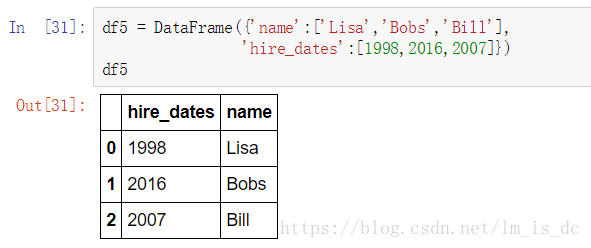
pd.merge(df1,df5,left_on='hire_date',right_on='hire_dates',
how='outer')
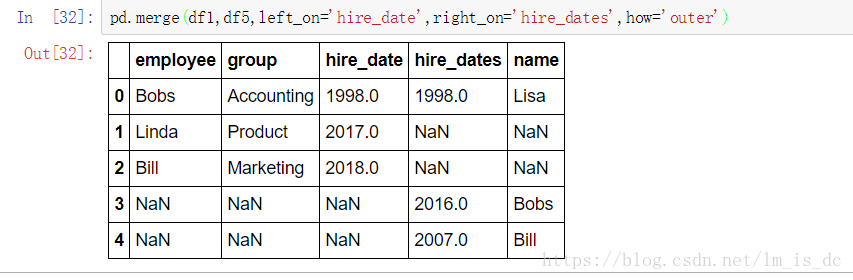
2.6 内合并\外合并\左合并\右合并
how参数={‘inner’,‘outer’,‘left’,‘right’}
- 内合并:只保留两者都有的key(默认模式),how=‘inner’
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df6
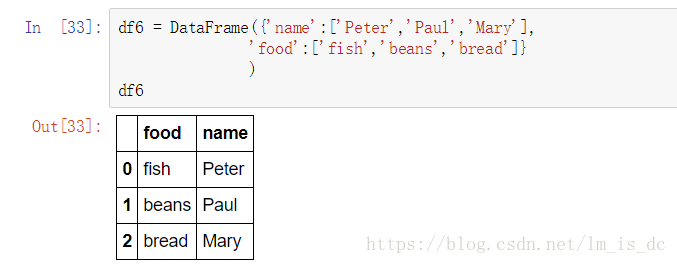
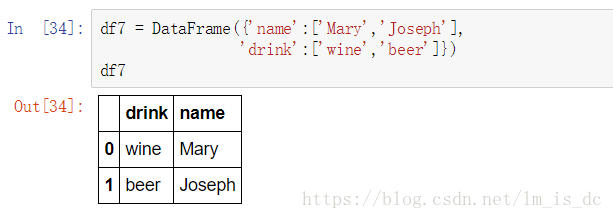
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df7
pd.merge(df6,df7,how='inner')

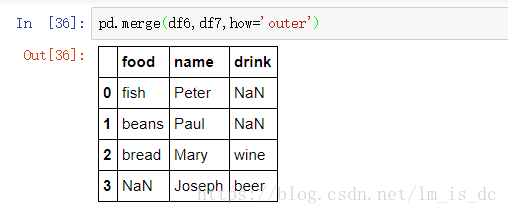
- 外合并 how=‘outer’:补NaN
pd.merge(df6,df7,how='outer')
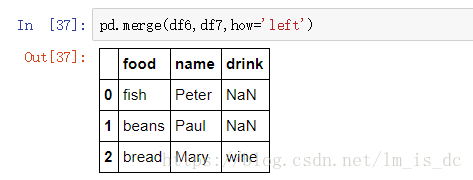
- 左合并:保留左表全部数据,how=‘left’
pd.merge(df6,df7,how='left')
- 右合并:保留右表全部数据,how=‘right’
pd.merge(df6,df7,how='right')

2.7 列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名。
可以使用suffixes=自己指定后缀。
df8 = DataFrame({'name':['Peter','Paul','Mary'],
'rank':[1,2,3]})
df8

df9 = DataFrame({'name':['Peter','Paul','Mary'],
'rank':[5,6,7]})
df9

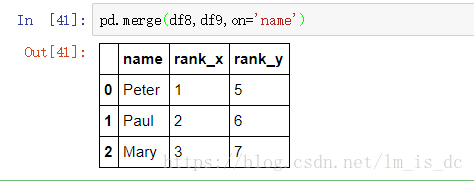
#默认添加_x,_y
pd.merge(df8,df9,on='name')
#指定添加'_L','_R'
pd.merge(df8,df9,on = 'name',suffixes=['_L','_R'])

3、行索引合并
使用行索引作为合并条件,使用left_on指定左表的列索引,然后right_index=True:
dic1={
'name':['tom','jay','helly'],
'age':[11,12,33],
'classRoom':[1,2,3]
}
df1=DataFrame(data=dic1)
df2=DataFrame(data=np.random.randint(60,100,size=(3,3)),
index=['jay','tom','helly'],
columns=['java','python','c'])
df1

df2

pd.merge(df1,df2,left_on='name',right_index=True)

pd.merge(df2,df1,right_on='name',left_index=True)

十、把列变成行索引
使用set_index(列名):
df=DataFrame(data={
'学科':['语文','数学','英语'],
'分数':[100,90,98]
})
df

df.set_index('学科')

后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~
python重要的第三方库pandas模块常用函数解析之DataFrame的更多相关文章
- pandas模块常用函数解析之Series(详解)
pandas模块常用函数解析之Series 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器输入网 ...
- numpy.random模块常用函数解析
numpy.random模块中常用函数解析 numpy.random模块官方文档 1. numpy.random.rand(d0, d1, ..., dn)Create an array of the ...
- numpy模块常用函数解析
https://blog.csdn.net/lm_is_dc/article/details/81098805 numpy模块以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter note ...
- IOS学习:常用第三方库(GDataXMLNode:xml解析库)
IOS学习:常用第三方库(GDataXMLNode:xml解析库) 解析 XML 通常有两种方式,DOM 和 SAX: DOM解析XML时,读入整个XML文档并构建一个驻留内存的树结构(节点树),通过 ...
- Hadoop streaming使用自定义python版本和第三方库
在使用Hadoop的过程中,遇到了自带python版本比较老的问题. 下面以python3.7为例,演示如何在hadoop上使用自定义的python版本以及第三方库. 1.在https://www.p ...
- $python正则表达式系列(2)——re模块常用函数
本文主要介绍正则re模块的常用函数. 1. 编译正则 import re p = re.compile(r'ab*') print '[Output]' print type(p) print p p ...
- (python pip安装第三方库超时问题(raise ReadTimeoutErrorself._pool, None, 'Read timed out.')
(python pip安装第三方库超时问题(raise ReadTimeoutErrorself._pool, None, ‘Read timed out.’)pip工具安装百度经验链接: pip安装 ...
- Python中使用第三方库xlrd来写入Excel文件示例
Python中使用第三方库xlrd来写入Excel文件示例 这一篇文章就来介绍下,如何来写Excel,写Excel我们需要使用第三方库xlwt,和xlrd一样,xlrd表示read xls,xlwt表 ...
- numpy函数库中一些常用函数的记录
##numpy函数库中一些常用函数的记录 最近才开始接触Python,python中为我们提供了大量的库,不太熟悉,因此在<机器学习实战>的学习中,对遇到的一些函数的用法进行记录. (1) ...
随机推荐
- 【性能监控-Perfmon工具】Perfmon工具使用教程
一.Perfmon工具简介 Perfmon是一款Windows自带的性能监控工具,提供了图表化的系统性能实时监视器.性能日志和警报管理.通过添加性能计数器可以实现对CPU.内存.网络.磁盘.进程等多类 ...
- 071 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 03 综合案例-数组移位-显示数组当中所有元素的的方法
071 01 Android 零基础入门 01 Java基础语法 09 综合案例-数组移位 03 综合案例-数组移位-显示数组当中所有元素的的方法 本文知识点:综合案例-数组移位-显示数组当中所有元素 ...
- 基于COCA词频表的文本词汇分布测试工具v0.1
美国语言协会对美国人日常使用的英语单词做了一份详细的统计,按照日常使用的频率做成了一张表,称为COCA词频表.排名越低的单词使用频率越高,该表可以用来统计词汇量. 如果你的词汇量约为6000,那么这张 ...
- matlab中fopen 打开文件或获得有关打开文件的信息
参考:https://ww2.mathworks.cn/help/matlab/ref/fopen.html?searchHighlight=fopen&s_tid=doc_srchtitle ...
- NOIP提高组2013 D2T3 【华容道】
某王 老师给我们考了一场noip2013的真题...心态爆炸! 题目大意: 有一个n*m的棋盘,每个格子上都有一个棋子,有些格子上的棋子能够移动(可移动的棋子是固定的),棋盘中有一个格子是空的,仍何 ...
- Informatica报错“表或视图不存在”的某种原因
软件版本:9.6.1 背景:测试将OLTP数据库的用户信息表(CUST_INFO)抽取到DW库(DW_CUST_INFO) 问题:工作流启动后,报错RR_4035,并告知表或视图不存在 分析:在导入源 ...
- 虚拟主机和ECS的选择——有的坑你可以不躺,有的钱你可以不花(一)
一直想做网站,由于最开始虚拟主机有优惠,所以三年前买了虚拟主机,后来一直续费,间歇性使用过,发现很多功能都不行. 昨天准备买新的,然后想起学生购买有优惠,于是开始了学生认证之旅. 首先,看一下之前 ...
- MeteoInfoLab脚本示例:读取文本文件绘制散度图
MeteoInfoLab中读取文本文件数据的函数是asciiread,获取文本文件行.列数的函数是numasciirow和numasciicol,和NCL中函数名一致,但都是小写字母.本例中的示例数据 ...
- iNeuOS工业互联平台,设备容器(物联网)改版,并且实现设备数据点的实时计算和预警。发布3.2版本
目 录 1. 概述... 2 2. 平台演示... 2 3. 设备容器新版本介绍... 2 4. 全局数据计算及预警平台... 3 5. ...
- 【UER #1】DZY Loves Graph
UOJ小清新题表 题目内容 UOJ链接 DZY开始有\(n\)个点,现在他对这\(n\)个点进行了\(m\)次操作,对于第\(i\)个操作(从\(1\)开始编号)有可能的三种情况: Add a b: ...