Java面试必问之-JUC
JUC:java.util.concurrent (Java并发编程工具类)
代码:D:\JAVA\Java_Learning\Elipse_Project\workspace200301EE\JUC
一般面试提问:面向对象和高级语法、Java集合类、Java多线程、JUC 和高并发、Java IO和 NIO
获取多线程的4种方法:
1.继承Thread类,重写run方法(其实Thread类本身也实现了Runnable接口)
2.实现Runnable接口,重写run方法
3.实现Callable接口,重写call方法(有返回值)
4.使用线程池(有返回值):通过Executors提供四种线程池
进程:
- 笔试:具有一定独立功能的程序关于某个数据集合的一次运行活动,是操作系统动态执行的基本单位。
- 面试:后台运行的一个程序,进程跟操作系统有关,跟编程语言无关,
线程:
笔试:一般一个进程包含多个线程,线程可以利用进程所拥有的资源,在引入线程的操作系统中,把线程作为独立运行和独立调度的基本单位
面试:线程是进程的组成部分,一般一个进程包含多个线程,它代表了一条顺序的执行流。例如IDEA上的代码提示、自动补全、格式化等功能
并发:在同一实体上的两个或多个使事件在同一时间段内发生
并行:在不同实体上的两个或多个事件在同一时刻发生
高内聚:类与类、对象与对象、模块与模块之间高度地聚集和关联
低耦合:AB两个对象可以进行数据共享,但是AB两个对象又各自 独立
在高内聚低耦合的前提下,线程(thread.start())操作(对外暴露的调用方法)资源类(操作的对象):
Thread.currentThread().getName()获取当前线程名Thread(Runnable target, String name)// target:Runnable接口的run() 方法的实现, run():线程处于就绪状态 name:线程名线程(thread.start())操作只是让该线程处于就绪状态而不是启动,具体的执行与否决定于cpu和操作系统底层调度通知
java.util.concurrent.locks(包)
在并发编程中,经常遇到多个线程访问同一个 共享资源 ,为了维护数据一致性,synchronized关键字被常用于维护数据一致性。synchronized机制是给共享资源上锁,只有拿到锁的线程才可以访问共享资源,这样就可以强制使得对共享资源的访问都是顺序的,因为对于共享资源属性访问是必要也是必须的
锁的种类:
乐观锁/悲观锁:
- 乐观锁:核心操作是CAS,认为不存在并发问题,取数据的时候,总认为不会有其他线程对数据进行修改,不会上锁。乐观锁适用于多读的应用类型,提高吞吐量
- 悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,适合写操作非常多的场景
独享锁/共享锁:独享锁是指该锁一次只能被一个线程所持有。共享锁是指该锁可被多个线程所持有。
- 互斥锁/读写锁:互斥锁/读写锁就是独享锁/共享锁具体的实现,分别是ReentrantLock和ReadWriteLock
可重入锁/ 非可重入锁:
可重入锁: 可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞,即再次获取锁而不会出现死锁。ReentrantLock和synchronized都是可重入锁。
非可重入锁:线程再次获取锁会出现死锁,如NonReentrantLock。ReentrantLock和NonReentrantLock都继承父类AQS,其父类AQS中维护了一个同步状态status来计数重入次数,status初始值为0。AQS通过控制status状态来判断锁的状态,对于非可重入锁状态不是0则去阻塞;对于可重入锁如果是0则执行,非0则判断当前线程是否是获取到这个锁的线程,是的话把status状态+1,释放的时候,只有status为0,才将锁释放。即加锁和释放锁次数要相等
公平锁/非公平锁:
- 公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁指多个线程获取锁的顺序不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能会造成优先级反转或饥饿现象
分段锁:类似HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock,是一种锁的设计
偏向锁/轻量级锁/重量级锁:
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁时,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当该线程自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该轻量级锁膨胀为重量级锁。重量级锁会让他申请的线程进入阻塞,性能降低。
自旋锁:尝试获取锁的线程不会立即阻塞,而是采用CAS的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
Lock:比synchronized更牛的锁
已知的实现类:可重复锁ReentrantLock, ReetrantReadWriteLock.ReadLock, ReentrantReadWriteLock.WriteLock
ReentrantLock lock = new ReentrantLock(); // 创建锁对象 lock.lock(); // 上锁 lock.unlock(); // 释放锁相比synchronized 的完全锁整个方法,ReentrantLock() 可以在 lock() 和 unlock() 之间的语句进行同步锁
多线程状态 Thread.State:
- 新建NEW
- 可运行RUNNABLE
- 阻塞BLOCKED :Thread.sleep(醒了手里还有锁) 和 wait(放开手里的锁去睡) 都会导致堵塞
- WAITING:一直等,不见不散
- TIMED_WAITTING: 等10秒,过时不候
- TERMINATED:
Lambda闭包:
拷贝小括号,写死右箭头,落地大括号 、 @FunctionalInterface注解表示为函数式接口,此接口里参数数量相同的方法只能有一个
default 开头的Lambda表达式表示在接口里声明+实现,不会影响参数数量相同的未实现方法。
Java8之前不可以在接口里实现,Java8之后通过default可以在接口里实现方法。一个函数时接口可以有多个default或static实现方法
生产者消费者问题(多线程问题):
- 口诀:高聚低合下,线程操作资源类,判断-干活-通知(this.notifyAll();)。
多线程交互(如
wait(), notifyAll())中,必须要防止多线程的虚拟唤醒,即交互时判断只用while。wait和notify方法都在Object类里新版生产者消费者问题:
在JUC中,Lock代替了
synchronized,Condition 代替了 Object monitor methods(wait, notify, notifyAll)Condition.await() 代替了 this.wait() Condition.signalAll() 代替了 this.notifyAll()
Lock 和 Condition、ReadWriteLock 都是
java.util.concurrent.locks下的子接口相对于
synchronized优势在于:精确通知,顺序访问、可以不局限在整个方法加同步锁,而是在一段语句内public void print5(){
lock.lock();
try {
while(number != 1){
condition1.await();
}
// 干活
for(int i = 1; i <= 5; i++){
System.out.println(Thread.currentThread().getName()+"\t"+i);
}
number = 2; // 修改标志位
condition2.signal(); // 精准通知 condition2
} catch (Exception e) {
e.printStackTrace();
} finally{
lock.unlock();
}
}
private Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
lock.lock(); // 加同步锁
condition.await(); // 等待
condition.signalAll(); // 通知
lock.unlock();
try{ TimeUnit.SECONDS.sleep( 1 ); } catch(InterruptedException e) {e.printStackTrace();}// 拿着锁不会释放try{ TimeUnit.SECONDS.wait( 1 ); } catch(InterruptedException e) {e.printStackTrace();}// 等待期间释放锁
多线程8锁:
public static synchronized void sendEmail() throws Exception {
try{ TimeUnit.SECONDS.sleep( 4 ); } catch(InterruptedException e) {e.printStackTrace();}
System.out.println("sendEmai.."); // 打印邮件
}
public static synchronized void sendSMS() throws Exception {
System.out.println("sendSMS.."); // 打印短信
}
public void hello() {
System.out.println("hello..");
}
Phone phone = new Phone();
Phone phone2 = new Phone();
new Thread(() -> {
try {
phone.sendEmail();
} catch (Exception e) {
e.printStackTrace();
}
}, "A").start();
Thread.sleep(100); new Thread(() -> {
try {
// phone.sendSMS();
// phone.hello();
phone2.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "B").start();
- satatic synchronized 锁的是 Phone phone = new Phone() 的 Phone, 而 synchronized 锁的是 new Phone()
1.两个线程调用同一个对象的两个同步方法:标准访问(无TimeUnit.SECONDS.sleep( 4 )),先打印邮件还是短信?邮件
- synchronized 锁的是该方法所在的当前类实例化对象this,使得同一时间段该资源对象被一个线程访问,因此当一个线程争夺cpui时间片后访问资源对象时,另一个线程等待
2.新增sleep()给某个方法:邮件方法暂停4秒,先打印邮件还是短信?邮件
- 与 情况1 类似,因为线程A在线程B之上,因此大概率会获得cpu时间片,然后先访问资源类的方法sendEmail(), 此时该资源对象被锁住,直到线程A执行完
3.新增一个线程调用新增的一个普通方法:新增普通方法hello(), 先打印邮件还是hello?hello
- 普通方法没有synchronized 修饰,不会受到其他带有锁的方法的影响
4.两个线程调用两个对象的同步方法,其中一个方法有Thread.sleep():两部手机,先打印邮件还是短信?短信
- 两个资源类的同步互相之间不影响
5.将两个方法均设置为static方法,并且让两个线程用同一个对象调用两个方法:两个静态同步方法,同一部手机,先打印邮件还是短信?邮件
- static修饰的同步方法,锁的是整个唯一的资源模板类,因此当一个线程调用该资源类的同步方法时,另一个线程的调用该资源类时将被阻塞
6.两个静态同步方法,2 部手机,先打印邮件还是短信?邮件
- static修饰的同步方法,锁的时整个唯一的资源模板类,因此当一个线程调用该资源类的同步方法时,另一个线程的调用该资源类时将被阻塞
7.一个普通同步方法,一个静态同步方法,1 部手机,先打印邮件还是短信?短信
- 普通同步方法和静态同步方法锁的对象不同,普通同步方法锁的是当前实例对象this,static锁的是资源模板类class
8.一个普通同步方法,一个静态同步方法,2 部手机,先打印邮件还是短信?短信
- 普通同步方法和静态同步方法锁的对象不同,普通同步方法锁的是当前实例对象this,static锁的是资源模板类class
List 线程不安全
2个常用的生成随机数工具类:
UUID.randomUUID().toString().substring(x,x)和System.currentTimeMillis()典型的RuntimeException(运行时异常)包括NullPointerException, ClassCastException(类型转换异常),IndexOutOfBoundsException(越界异常), IllegalArgumentException(非法参数异常),ArrayStoreException(数组存储异常),ArithmeticException(算术异常),BufferOverflowException(缓冲区溢出异常), 并发修改异常 java.util.ConcurrentModificationException、OutOfMemoryError内存溢出
· 当使用线程不安全的集合在高并发会出现异常,抛出并发修改异常 java.util.ConcurrentModificationException
· 如何使线程安全?
· 方法1(不建议):可改用Vector避免并发修改异常, Vector是ArrayList的前身,底层方法实现有synchronized修饰
· List<String> list = Collections.synchronizedList(new ArrayList<>()); 用工具类将ArrayList转换为线程安全的,适用小数据量。
· 还可以是Collections.synchronizedMap()、Collections.synchronizedSet()
· 方法2:List<Object> list = new CopyOnWriteArrayList<>(); 底层用的是lock锁,采用写时复制(读写分离)思想,读和写不同容器,复制一份然后供集体读,CopyOnWriteArrayList的add()底层是:Arrays.copyOf(elements, len + 1); 即从原集合拷贝一份再写, add时扩容每次扩一个
· 类似的还可以有CopyOnWriteArraySet<>()
· Map<Object, Object> map = new ConcurrentHashMap<>();
· 方法3:使用优于Runnable的 Callable 接口
List<String> list = new CopyOnWriteArrayList<>();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, String.valueOf(i)).start();
}
除了vector,statck、hashtable、enumeration、StringBuffer是线程安全,其他的集合类都是线程不安全的
HashSet的底层是HashMap,但操作HashSet时只操作HashMap的key,源码:
map.put(e, PRESENT)==null; PRESENT = new Object();HashMap底层是:node类型的数组+node类型的链表+node类型的红黑树, 容量为16,负载因子0.75(即装载的内存超过容量的3/4会自动扩容,HashMap扩容为原来的一倍,即2^(4+1),ArrayList扩容原来内存的一半)
new HashMap() 等价于 new HashMap(16, 0.75); 默认容量16和负载因子0.75,但可以修改
Callable接口
Runnable和Callable 区别:1.Callable有返回值 2.有抛异常 3.落地方法不同,Callable是call(), Runnable是run()。他们都是函数式接口
new Thread(无法传入Callable.class); 需要先找到 Runnable,再找到它的子接口 RunnableFuture,再找到它实现类FutureTask,该类实现了Runnable接口,再
找到它的构造方法FutureTask(Callable<V> callable), 便可通过这种多态思想找到与Callable和Runnable相关联的方法。class Mythread implements Callable<Integer>{
@Override // Callable是函数式接口,call是他的抽象方法,实现Callable的时候需要重写call方法
public Integer call() throws Exception {
try {TimeUnit.SECONDS.sleep(2);} catch (Exception e) {e.printStackTrace();}
System.out.println("Callable");
return 1024;
}
}
public class CallableDemo {
public static void main(String[] args) throws Exception {
FutureTask<Integer> futureTask = new FutureTask<>(new Mythread());
new Thread(futureTask, "A").start();
new Thread(futureTask, "B").start(); // 只会调用1次new FutureTask<>(new Mythread());
System.out.println(futureTask.get()); // 输出返回值
}
}
因此使用FutureTask来代替 new Thread 从而创建线程。这里用了多态的思想:接口与实现之间即使是在构造方法的参数也可以和接口相关联
细节:Callable的call() 内部有缓存机制,只会调用一次 new FutureTask<>(new Mythread());
CountDownLatch:可以控制多线程的main线程最后执行,countDownLatch.countDown();做的减法
CountDownLatch countDownLatch = new CountDownLatch(6); // 信号数为6
for(int i = 1; i <= 6; i++){
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"\t离开教室");
countDownLatch.countDown(); // 倒计信号数,执行一次减一
}, String.valueOf(i)).start();
}
countDownLatch.await(); // 堵住该main线程直到除main外的其他线程结束后才放行
System.out.println(Thread.currentThread().getName()+"\t班长关门走人"); // 信号数减到0时才执行main线程
CyclicBarrier:可以控制多线程的main线程最后执行,和 CountDownLatch 不同的是CyclicBarrier做的加法
CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {System.out.println("召唤神龙");}); //设置信号数
for (int i = 1; i <= 7; i++) {
final int tempInt = i;
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"\t收集到第:"+tempInt+"颗龙珠");
try {
cyclicBarrier.await();
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}, String.valueOf(i)).start(); // 信号数加到7时才执行main线程
}
Semaphore: 设置信号量,用于多个共享资源的互斥使用,还用于并发线程数的控制,限流
public static void main(String[] args) {
// 模拟资源类,有3个空车位, 当一个线程占用资源后减少一个空车位,应用场景:抢红包
Semaphore semaphore = new Semaphore(3); // 3是设置的信号量,用于多个共享资源的互斥使用,还用于并发线程数的控制,限流
for(int i = 1; i <= 6; i++){
new Thread(() -> {
try {
semaphore.acquire(); // 允许并发线程访问的允许量,默认为1
System.out.println(Thread.currentThread().getName()+"\t抢占到了车位"); // 信号量-1
try{TimeUnit.SECONDS.sleep(3);}catch (Exception e) {e.printStackTrace();}
System.out.println(Thread.currentThread().getName()+"\t离开了车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(); // 释放资源
}
}, String.valueOf(i)).start();
}
}
ReadWriteLock读写锁:写时排它,锁控制数据一致性。唯一写,并发读
- 和 Lock的读写都是同步、线程不共享不同的是:ReadWriteLock的读线程共享,可以有多个线程同时读同一个资源类,但写时线程不共享,即如果有一个线程在写操作共享资源时,不应该有其他线程对该资源进行读或写。
public void put(String key, Object value){
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"\t 开始写入");
map.put(key, value);
System.out.println(Thread.currentThread().getName()+"\t 写入完成");
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
} finally{
readWriteLock.writeLock().unlock();
}
}
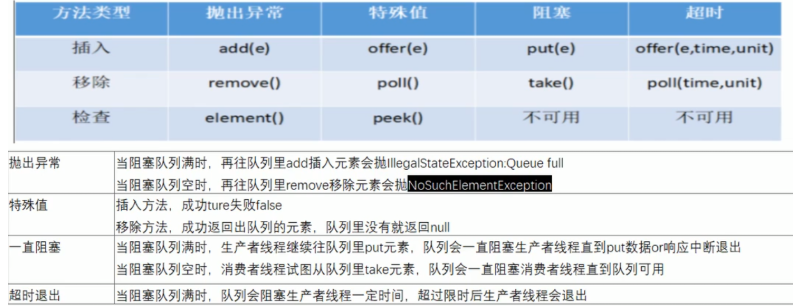
阻塞队列BlockingQueue接口
- 当队列是空,从队列中获取元素的操作将被阻塞;当队列满,从队列中添加元素的操作将会被阻塞
- 不需要关心何时需要阻塞线程,什么时候需要唤醒线程,一切BlockingQueue都一手包办
- 7大BlockingQueue队列,只需掌握3个红色部分

- new ArrayBlockingQueue(队列大小)方法:
ThreadPool 线程池
线程池的工作主要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行
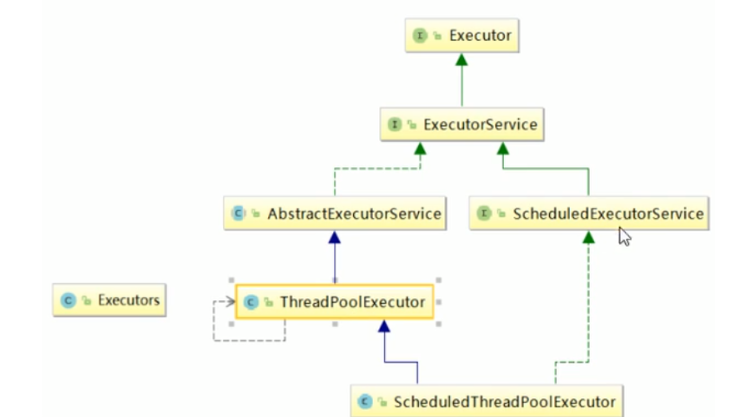
Java线程池是通过Excutor框架实现的, 最主要的类:ThreadPoolExecutor
主要特点:线程复用、控制最大并发数、管理线程
线程池ThreadPoolExecutor的三大方法:
Excutors.newFixedThreadPool(int) : 一池N个固定线程,类似银行受理窗口,执行长期任务性好,底层原理为:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
Excutors.newSingleThreadPool(int):一池单个线程
Excutors.newCachedThreadPool(int):一池有可自动收缩可自动扩充的线程,底层原理为:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, // 三大方法底层调用的都是同个方法ThreadPoolExecutor
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
ThreadPoolExecutor的7大参数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, // 线程池ThreadPoolExecutor构造参数
Executors.defaultThreadFactory(), defaultHandler);
}
// 线程池7大参数
public ThreadPoolExecutor(int corePoolSize, // 1.线程池中常驻的核心线程数,简称核心数。类似银行当天值日窗口
int maximumPoolSize, // 2.线程池中能够容纳同时执行的最大线程数,指可扩容的线程数,必须大于等于1,包含核心数
long keepAliveTime,//3.多余空闲线程(除核心线程的线程)的存活时间,当等待时间超过keepAliveTime的空闲线程会被销毁
TimeUnit unit, // 4.一个枚举, 表示keepAliveTime的单位
BlockingQueue<Runnable> workQueue, // 5.任务阻塞队列,被提交但尚未被执行的任务,类似候客区
ThreadFactory threadFactory, // 6.表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认即可
RejectedExecutionHandler handler) { // 7.拒绝策略,当队列满,并且工作线程大于等于线程池的 最大线程数maximumPoolSize时如何拒绝那些请求执行的runnable的策略
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
关于corePoolSize、maxPoolSize、queueCapacity之间的关系:
queueCapacity是Spring中的缓冲队列,corePoolSize为初始线程个数,当corePoolSize的线程都在执行中时,则将Runnable临时放入queueCapacity的缓冲队列中等待,
当queueCapacity满了时,才会将线程个数从corePoolSize扩展至maxPoolSize,
如果此时queueCapacity缓存队列又 满了,则后续Runnable对象加入其中时就会被abort(根据拒绝策略决定)抛弃。
可通过Spring设置参数
<bean id="resQueryBaseInfoExecutor"
class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="threadNamePrefix" value="resQueryBaseInfoExecutor-" />
<property name="corePoolSize" value="5" />
<property name="keepAliveSeconds" value="100" />
<property name="maxPoolSize" value="10" />
<property name="queueCapacity" value="500" />
</bean>
线程池底层工作原理
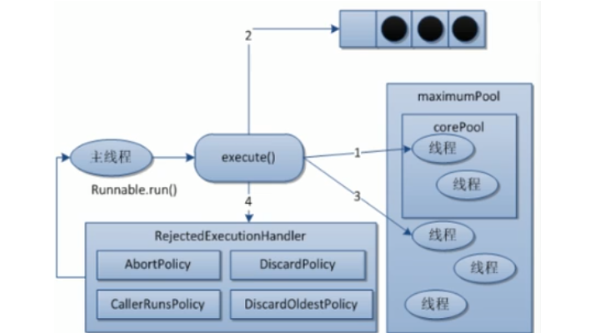
public static void main(String[] args) {
System.out.println(Runtime.getRuntime().availableProcessors()); // 获取计算机内核数
ExecutorService threadPool = new ThreadPoolExecutor(
2,
5, // 如果得到的内核数是CPU密集型,就比核数多1~2
2L,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
try {
for (int i = 0; i <= 10; i++) {
threadPool.execute(() -> { // Runnable 可用Lambda表达式
System.out.println(Thread.currentThread().getName()+"\t办理业务");
});
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
- ThreadPoolExecutor三大方法用哪个?都不用。只能使用自定义

一般使用以下方法创建线程池, 此时线程池最大容纳数是5+3, 最大线程数是5
ExecutorService threadPool = new ThreadPoolExecutor(2, 5, 2L, TimeUnit.SECONDS, new LinkedBlockingDeque<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
- RejectedExecutionHandler四大拒绝策略:

Java.util.function(四大函数式接口):
- 所谓函数式接口,指的是只有一个抽象方法的接口。函数式接口可以被隐式转换为Lambda表达式。函数式接口可以用@FunctionalInterface注解标识。

Consumer
Consumer<String> consumer = s -> {System.out.println(s);};
consumer.accept("a"); // 输出a
Supplier
Supplier<String> supplier = () -> {return "sup";};
System.out.println(supplier.get()); // 固定输出sup
Function<T,R>
public static void main(String[] args) {
Function<String, Integer> function = (s -> {return s.length();});
System.out.println(function.apply("abc")); // 返回s.length()
Predicate
Predicate<String> predicate = s -> {return s.isEmpty();}; // lambda表达式s
System.out.println(predicate.test("")); // true
Stream流式计算
@Accessors
- @Accessors(fluent = true) :设置为true,则getter和setter方法的方法名都是基础属性名,且setter方法返回当前对象
- @Accessors(chain = true) : 链式的,设置为true,则setter方法返回当前对象,可以实现多重setter链式编程
- @Accessors(prefix = "p") : 中文含义是前缀,用于生成getter和setter方法的字段名会忽视指定前缀(遵守驼峰命名)
Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。集合讲的是数据,流讲的是计算!

public static void main(String[] args) { // stream式计算
User u1 = new User(11, "a", 23);
User u2 = new User(12, "b", 24);
User u3 = new User(13, "c", 22);
User u4 = new User(14, "d", 28);
User u5 = new User(16, "e", 26);
List<User> list = Arrays.asList(u1,u2,u3,u4,u5);
// 形参 u 代表 List<User>的泛型User
list.stream().filter(u -> {return u.getId() % 2 == 0;}) // 选取偶数id
.filter(u -> {return u.getAge() > 24;}) // 选取 age 大于 24
.map(m -> {return m.getUserName().toUpperCase();}) // list转为map,名字变为大写
.sorted((o1,o2) -> {return o2.compareTo(o1);}).limit(1) // 逆序,输出第一个对象
.forEach(System.out::println); // 遍历输出E
}
分支合并框架
线程接口中,能干活的线程接口有Runnable (无返回值) 、Callable(有返回值)
ForkJoinPool :类比线程池
ForkJoinTask:类比FutureTask
RecursiveTask:递归任务,继承后可以实现递归调用的任务
抽象类不能直接通过new而实例化,需要创建一个指向自己的对象引用(其子类)来实例化
class MyTask extends RecursiveTask<Integer>{
private static final Integer ADJUST_VALUE = 10;
private int begin;
private int end;
private int result;
public MyTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
protected Integer compute() { // RecursiveTask 的抽象方法,执行递归任务
if((end - begin) <= ADJUST_VALUE){
for(int i = begin; i <= end; i++){
result = result + i;
}
}else{
int middle = (end + begin) / 2;
MyTask task01 = new MyTask(begin, middle);
MyTask task02 = new MyTask(middle+1, end);
task01.fork(); // task01递归、分支直到 (end - begin) <= ADJUST_VALUE
task02.fork(); // task02递归、分支直到 (end - begin) <= ADJUST_VALUE
result = task01.join() + task02.join(); // 将所有子结果合并
}
return result;
}
}
public class ForkJoinDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
MyTask myTask = new MyTask(0, 100);
ForkJoinPool threadPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTask = threadPool.submit(myTask);
System.out.println(forkJoinTask.get());
threadPool.shutdown();
}
}
异步回调
- 阻塞/同步:打一个电话一直到有人接为止
非阻塞:打一个电话没人接,每隔10分钟再打一次,知道有人接为止
异步:打一个电话没人接,转到语音邮箱留言(注册),然后等待对方回电(call back)
public class CompletableFutureDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
System.out.println(Thread.currentThread().getName() + "\t没有返回, update mysql ok");
});
completableFuture.get();
// 异步回调
CompletableFuture<Integer> completableFuture2 = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName() + "\tcompletableFuture2");
// int age = 10/0;
return 1024;
});
System.out.println(completableFuture2.whenComplete((t, u) -> { // 正常时返回 completableFuture2 的返回值
System.out.println("*****t:" + t); // t 为 completableFuture2 异步回调的返回值
System.out.println("*****u:" + u); // u 为 completableFuture2 异步回调的异常信息
}).exceptionally(f -> { // 异常时返回 completableFuture2 的异常
System.out.println("*****exception:" + f.getMessage());
return 444;
}).get()); // 打印返回值结果
}
}
Java面试必问之-JUC的更多相关文章
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- 一线大厂Java面试必问的2大类Tomcat调优
一.前言 最近整理了 Tomcat 调优这块,基本上面试必问,于是就花了点时间去搜集一下 Tomcat 调优都调了些什么,先记录一下调优手段,更多详细的原理和实现以后用到时候再来补充记录,下面就来介绍 ...
- java面试必问问题总结
1. 自我介绍 2. get跟load的区别 3. 什么是重载,什么是重写 4. HashTable跟HashMap的区别 5. Jsp九大隐式对象 6. Forword和redirect 的区别 7 ...
- Java面试必问:ThreadLocal终极篇 淦!
点赞再看,养成习惯,微信搜一搜[敖丙]关注这个互联网苟且偷生的程序员. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系列 ...
- java面试必问:多线程的实现和同步机制,一文帮你搞定多线程编程
前言 进程:一个计算机程序的运行实例,包含了需要执行的指令:有自己的独立地址空间,包含程序内容和数据:不同进程的地址空间是互相隔离的:进程拥有各种资源和状态信息,包括打开的文件.子进程和信号处理. 线 ...
- Java面试必问之线程池的创建使用、线程池的核心参数、线程池的底层工作原理
一.前言 大家在面试过程中,必不可少的问题是线程池,小编也是在面试中被问啥傻了,JUC就了解的不多.加上做系统时,很少遇到,自己也是一知半解,最近看了尚硅谷阳哥的课,恍然大悟,特写此文章记录一下!如果 ...
- 数据结构笔记02:Java面试必问算法题
1. 面试的时候,栈和队列经常会成对出现来考察.本文包含栈和队列的如下考试内容: (1)栈的创建 (2)队列的创建 (3)两个栈实现一个队列 (4)两个队列实现一个栈 (5)设计含最小函数min()的 ...
- Java面试必问-ThreadLocal
前言 在面试环节中,考察"ThreadLocal"也是面试官的家常便饭,所以对它理解透彻,是非常有必要的. 有些面试官会开门见山的提问: “知道ThreadLocal吗?” “讲讲 ...
- Java面试必问,ThreadLocal终极篇
转载自掘金占小狼博客. 前言 在面试环节中,考察"ThreadLocal"也是面试官的家常便饭,所以对它理解透彻,是非常有必要的. 有些面试官会开门见山的提问: “知道Thread ...
随机推荐
- EXCEL 中数据 批量 填充进 word 中
工具:Python3.7 需求描述:将EXCEL中 第二行 数据 填在 word 对应位置上,然后保存为 "姓名+任务.docx"文件. 再将EXCEL中 第三行 数据 填在 wo ...
- leetcode刷题记录——链表
使用java实现链表 单向链表 双向链表 单向循环链表 双向循环链表 题目记录 160.相交链表 例如以下示例中 A 和 B 两个链表相交于 c1: A: a1 → a2 c1 → c2 → c3 B ...
- keepalived的工作原理解析以及安装使用
一.keepalived keepalived是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障. keepalived官网http://www.keepali ...
- MAC安装Navicat Premiun12
链接地址:https://blog.csdn.net/wenyicodedog/article/details/97970154
- Git仓库由HTTPS切换成ssh秘钥连接
Git关联远程仓库可以使用https协议或者ssh协议. [特点/优缺点] ssh: 一般使用22端口: 通过先在本地生成SSH密钥对再把公钥上传到服务器: 速度较慢点 https: 一般使用443端 ...
- Go | Go 语言打包静态文件以及如何与Gin一起使用Go-bindata
系列文章目录 第一章 Go 语言打包静态文件以及如何与Gin一起使用Go-bindata 目录 系列文章目录 前言 一.go-bindata是什么? 二.使用步骤 1. 安装 2. 使用 3. 读取文 ...
- 基于函数的I/O操作(头文件stdio.h)
基于函数库的I/O是C语言标准库的功能,基于系统级I/O函数实现. 系统级I/O函数对文件的标识是文件描述符,C语言标准库中对文件的标识是指向FILE结构的指针.在头文件cstdio或stdio.h中 ...
- 计算机网络-传输层(1)UDP协议
UDP协议基于Internet IP协议,只提供两个基础功能: 分用/复用 分用:主机接收到IP数据报(datagram),每个数据报携带源IP地址.目的IP地址且携带一个传输层的段(Segment) ...
- 区块链入门到实战(17)之以太坊(Ethereum) – 是什么
以太坊的作用:构建基于区块链的分布式应用. 以太坊是什么:可编程的虚拟币. 以太坊(Ethereum)是一个可编程的虚拟币,它是一个基于公共区块链的分布式计算平台,可用于构建基于区块链的分布式应用. ...
- .Net MongoDB批量修改集合中子集合的字段
环境:.Net Core 3.1 (需要导入.Net MongoDB的驱动) 模型 /// <summary> /// 收藏 /// </summary> public cla ...