python进阶(9)多线程
什么是线程?
线程也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行
为什么要使用多线程?
线程在程序中是独立的、并发的执行流。与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存、文件句柄 和其他进程应有的状态。 因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享 内存,从而极大的提升了程序的运行效率。 线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信。 操作系统在创建进程时,必须为进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能高得要多。
多线程优点
进程之间不能共享内存,但线程之间共享内存非常容易。操作系统在创建进程时,需要为该进程重新分配系统资源,但创建线程的代价则小得多。因此使用多线程来实现多任务并发执行比使用多进程的效率高 python语言内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了python的多线程编程。
单线程执行
import time
def hello():
print("你好,世界")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
hello()
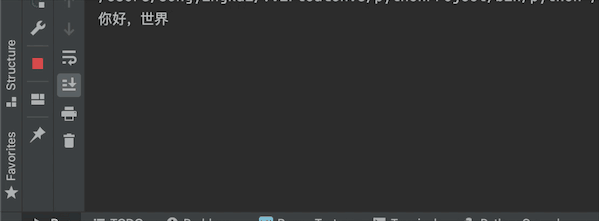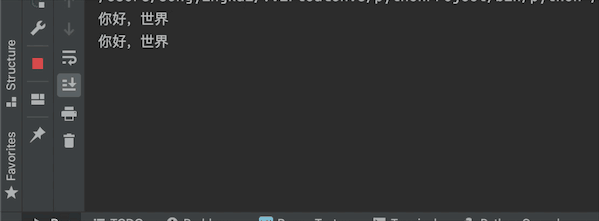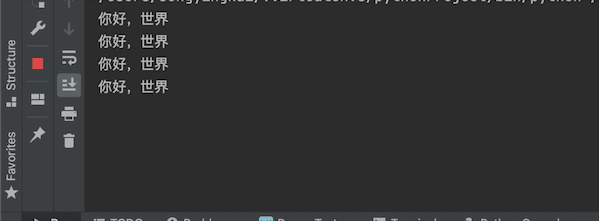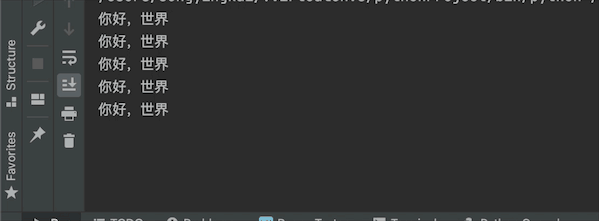
运行结果
多线程执行
import threading
import time
def saySorry():
print("你好,世界")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=saySorry) # 创建线程对象,此时还未启动子线程
t.start() # 启动线程,即让线程开始执行
运行结果
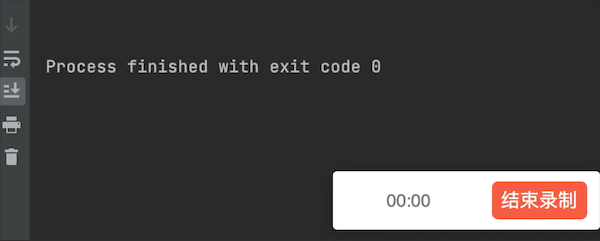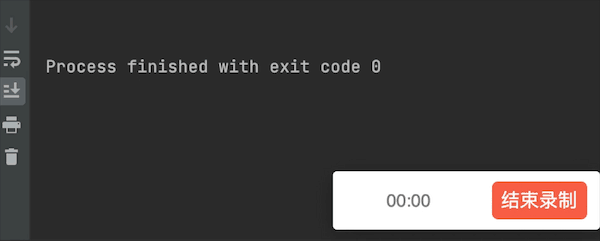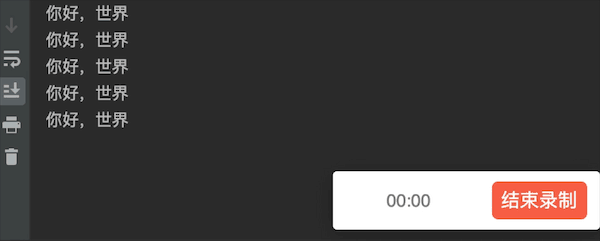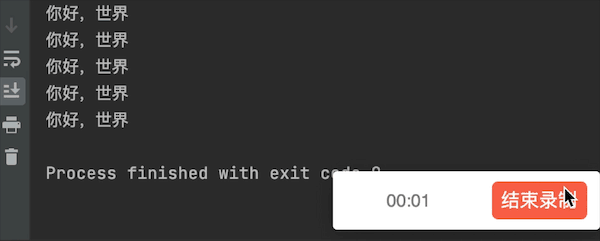
执行速度对比
- 可以明显看出使用了多线程并发的操作,花费时间要短
- 当调用start()时,才会真正的创建线程,并且开始执行
函数式创建多线程
python中多线程使用threading模块,threading模块调用Thread类
self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None
- group:默认为None;预留给将来扩展ThreadGroup时使用类实现。不常用,可以忽略
- target:代表要执行的函数名,不是函数
- name:线程名,默认情况下的格式是"Thread-N",其中N是一个小的十进制数
- args:函数的参数,以元组的形式表示
- kwargs:关键字参数字典
小例子
import threading
from time import sleep
from datetime import datetime
def write(name):
for i in range(3):
print("{}正在写字{}".format(name, i))
sleep(1)
def draw(name):
for i in range(3):
print("{}正在画画{}".format(name, i))
sleep(1)
if __name__ == '__main__':
print(f'---开始---:{datetime.now()}')
t1 = threading.Thread(target=write, args=('Jack', ))
t2 = threading.Thread(target=draw, args=('Tom', ))
t1.start()
t2.start()
print(f'---结束---:{datetime.now()}')
查看线程数量threading.enumerate()
import threading
from datetime import datetime
from time import sleep
def write():
for i in range(3):
print(f"正在写字...{i}")
sleep(1)
def draw():
for i in range(3):
print(f"正在画画...{i}")
sleep(1)
if __name__ == '__main__':
print(f'---开始---:{datetime.now()}')
t1 = threading.Thread(target=write)
t2 = threading.Thread(target=draw)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
print(f'当前运行的线程数为:{length}')
if length <= 1:
break
sleep(0.5)
结果
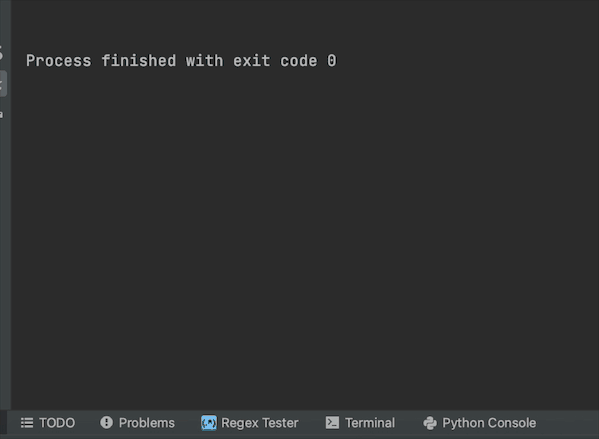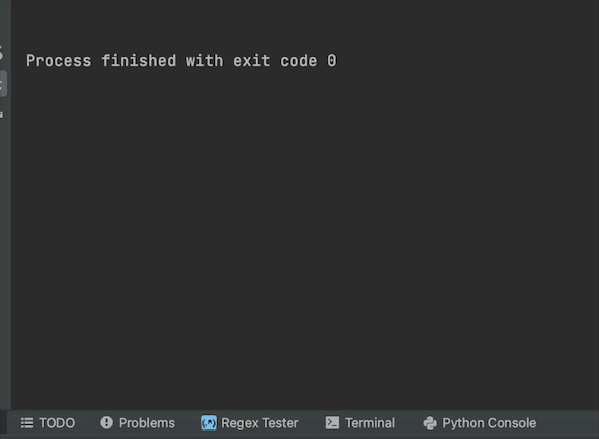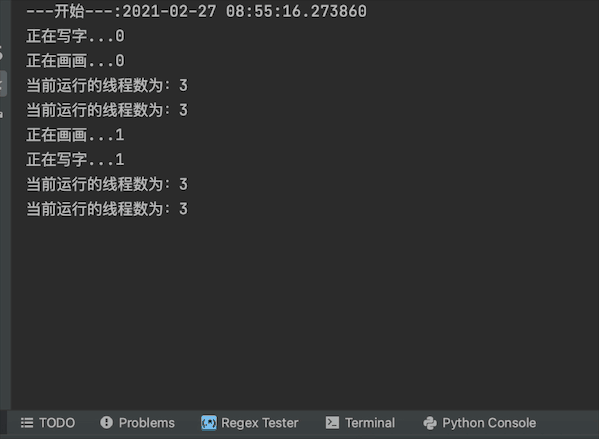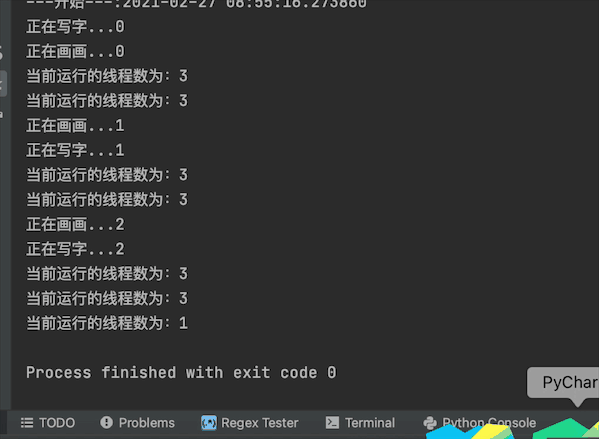
最开始打印线程数为3个,一个主线程+2个子线程t1,t2
最后打印线程数为1个,是因为子线程都结束了,就剩主线程了
自定义线程
继承threading.Thread来定义线程类,其本质是重构Thread类中的run方法
为什么执行run方法,就会启动线程呢?之前写函数时,调用的是start()方法
因为run方法里默认执行了start()方法
import threading
from time import sleep
class MyThread(threading.Thread):
def run(self):
for i in range(5):
sleep(1)
msg = "I'm " + self.name + ' @ ' + str(i) # name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()
结果
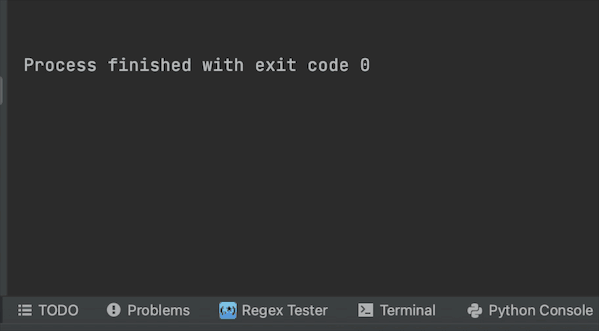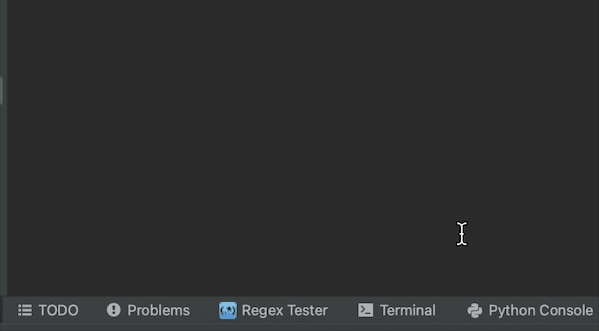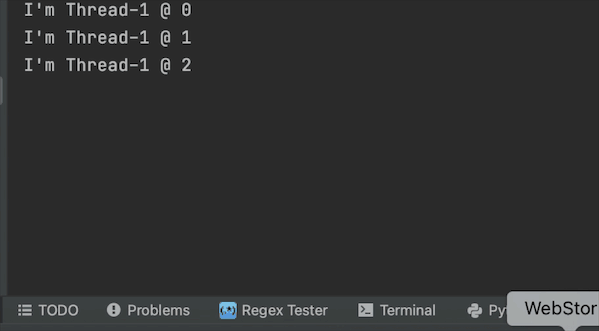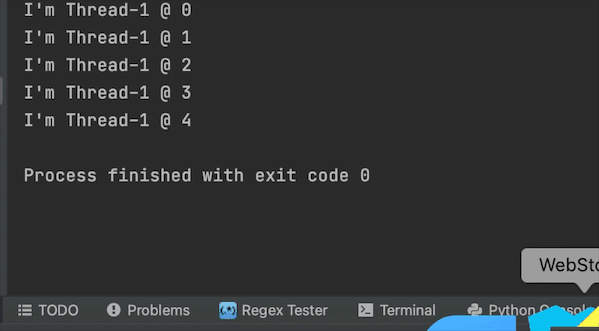
守护线程
'''
这里使用setDaemon(True)把所有的子线程都变成了主线程的守护线程,
因此当主线程结束后,子线程也会随之结束,所以当主线程结束后,整个程序就退出了。
所谓’线程守护’,就是主线程不管该线程的执行情况,只要是其他子线程结束且主线程执行完毕,主线程都会关闭。也就是说:主线程不等待该守护线程的执行完再去关闭。
'''
import threading
import time
def run(n):
print('task', n)
time.sleep(1)
print('3s')
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
if __name__ == '__main__':
t = threading.Thread(target=run, args=('t1',))
t.setDaemon(True)
t.start()
print('end')
结果
task t1
end
通过执行结果可以看出,设置守护线程之后,当主线程结束时,子线程也将立即结束,不再执行
主线程等待子线程结束(join)
为了让守护线程执行结束之后,主线程再结束,我们可以使用join方法,让主线程等待子线程执行
import threading
import time
def run(n):
print('task', n)
time.sleep(1)
print('3s')
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
if __name__ == '__main__':
t = threading.Thread(target=run, args=('t1',))
t.setDaemon(True) # 把子线程设置为守护线程,必须在start()之前设置
t.start()
t.join() # 设置主线程等待子线程结束
print('end')
结果
task t1
3s
2s
1s
end
线程共享变量
'''
多线程共享全局变量
线程时进程的执行单元,进程时系统分配资源的最小执行单位,所以在同一个进程中的多线程是共享资源的
'''
import threading
import time
g_num = 0
def work1(num):
global g_num
for i in range(num):
g_num += 1
print("----in work1, g_num is %d---"%g_num)
def work2(num):
global g_num
for i in range(num):
g_num += 1
print("----in work2, g_num is %d---"%g_num)
print("---线程创建之前g_num is %d---"%g_num)
t1 = threading.Thread(target=work1, args=(1000000,))
t1.start()
t2 = threading.Thread(target=work2, args=(1000000,))
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)
结果
---线程创建之前g_num is 0---
----in work2, g_num is 1451293---
----in work1, g_num is 1428085---
2个线程对同一个全局变量操作之后的最终结果是:1428085
先来看结果,为什么不是200000呢?
原因是多线程共用同一个变量,可能会出现资源竞争的问题,导致数据不准确,那有什么解决办法吗?下面介绍互斥锁
互斥锁
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,当多个线程同时修改同一条数据时可能会出现脏数据,所以出现了线程锁,即同一时刻允许一个线程执行操作。线程锁用于锁定资源,可以定义多个锁,像下面的代码,当需要独占 某一个资源时,任何一个锁都可以锁定这个资源,就好比你用不同的锁都可以把这个相同的门锁住一样。
由于线程之间是进行随机调度的,如果有多个线程同时操作一个对象,如果没有很好地保护该对象,会造成程序结果的不可预期,我们因此也称为线程不安全。
为了防止上面情况的发生,就出现了互斥锁(Lock)
import threading
import time
g_num = 0
# 创建一个互斥锁
# 默认是未上锁的状态
lock = threading.Lock()
def test1(num):
global g_num
for i in range(num):
lock.acquire() # 上锁
g_num += 1
lock.release() # 解锁
print("---test1---g_num=%d"%g_num)
def test2(num):
global g_num
for i in range(num):
lock.acquire() # 上锁
g_num += 1
lock.release() # 解锁
print("---test2---g_num=%d"%g_num)
# 创建2个线程,让他们各自对g_num加1000000次
p1 = threading.Thread(target=test1, args=(1000000,))
p1.start()
p2 = threading.Thread(target=test2, args=(1000000,))
p2.start()
# 等待计算完成
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)
结果
---test2---g_num=1961182
---test1---g_num=2000000
2个线程对同一个全局变量操作之后的最终结果是:2000000
上锁解锁过程
当一个线程调用锁的acquire()方法获得锁时,锁就进入locked状态。 每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为blocked状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入unlocked状态。 线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
锁的好处
- 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处
- 阻止了多线程
并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了 - 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成
死锁
GIL全局解释器
在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少个核同时只能执行一个线程。究其原因,这就是由于GIL的存在导致的。
GIL的全程是全局解释器,来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看做是“通行证”,并且在一个python进程之中,GIL只有一个。拿不到线程的通行证,并且在一个python进程中,GIL只有一个,拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,而只能利用GIL保证同一时间只能有一个线程拿到数据。而在pypy和jpython中是没有GIL的
python在使用多线程的时候,调用的是c语言的原生过程。
python针对不同类型的代码执行效率也是不同的
CPU密集型代码(各种循环处理、计算等),在这种情况下,由于计算工作多,ticks技术很快就会达到阀值,然后出发GIL的 释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。IO密集型代码(文件处理、网络爬虫等设计文件读写操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待, 造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序的执行 效率)。所以python的多线程对IO密集型代码比较友好。
主要要看任务的类型,我们把任务分为I/O密集型和计算密集型,而多线程在切换中又分为I/O切换和时间切换。如果任务属于是I/O密集型,若不采用多线程,我们在进行I/O操作时,势必要等待前面一个I/O任务完成后面的I/O任务才能进行,在这个等待的过程中,CPU处于等待状态,这时如果采用多线程的话,刚好可以切换到进行另一个I/O任务。这样就刚好可以充分利用CPU避免CPU处于闲置状态,提高效率。但是,如果多线程任务都是计算型,CPU会一直在进行工作,直到一定的时间后采取多线程时间切换的方式进行切换线程,此时CPU一直处于工作状态, 此种情况下并不能提高性能,相反在切换多线程任务时,可能还会造成时间和资源的浪费,导致效能下降。这就是造成上面两种多线程结果不能的解释。
结论:I/O密集型任务,建议采取多线程,还可以采用多进程+协程的方式(例如:爬虫多采用多线程处理爬取的数据);对于计算密集型任务,python此时就不适用了。
python进阶(9)多线程的更多相关文章
- Python进阶:多线程、多进程和线程池编程/协程和异步io/asyncio并发编程
gil: gil使得同一个时刻只有一个线程在一个CPU上执行字节码,无法将多个线程映射到多个CPU上执行 gil会根据执行的字节码行数以及时间片释放gil,gil在遇到io的操作时候主动释放 thre ...
- Python进阶(多线程)
多线程结构 import threading def worker():#子线程要执行的具体逻辑代码函数 print('threading') t1 = threading.current_threa ...
- Python进阶基础学习(多线程)
Python进阶学习笔记(一) threading模块 threading.thread(target = (函数)) 负责定义子线程对象 threading.enumerate() 负责查看子线程对 ...
- Python进阶——为什么GIL让多线程变得如此鸡肋?
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 做 Python 开发时,想必你肯定听过 GIL,它经常被 Python 程序员吐槽,说 Pytho ...
- Python进阶之面向对象编程
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数. 面向过程的程序设计把计算机 ...
- Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量
Python进阶----线程基础,开启线程的方式(类和函数),线程VS进程,线程的方法,守护线程,详解互斥锁,递归锁,信号量 一丶线程的理论知识 什么是线程: 1.线程是一堆指令,是操作系统调度 ...
- python进阶强化学习
最近学习了慕课的python进阶强化训练,将学习的内容记录到这里,同时也增加了很多相关知识. 主要分为以下九个模块: 基本使用 迭代器和生成器 字符串 文件IO操作 自定义类和类的继承 函数装饰器和类 ...
- [.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(三) 利用多线程提高程序性能(下)
[.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(二) 利用多线程提高程序性能(下) 本节导读: 上节说了线程同步中使用线程锁和线程通知的方式来处理资源共享问题,这 ...
- [.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中)
[.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中) 本节要点: 上节介绍了多线程的基本使用方法和基本应用示例,本节深入介绍.NET ...
随机推荐
- Linux 查找文件的正确方式
Linux 系统中查找文件的命令有 which.whereis.locate 和 find 等,本文对这四条命令进行简单的介绍.列举了一些简单的使用方式. which 在 PATH 变量中定义的全部路 ...
- 一文弄懂-《Scalable IO In Java》
目录 一. <Scalable IO In Java> 是什么? 二. IO架构的演变历程 1. Classic Service Designs 经典服务模型 2. Event-drive ...
- Java程序操作HDFS
1.新建项目2.导包 解压hadoop-2.7.3.tar.gzE:\工具\大数据\大数据提升资料\01-软件资料\06-Hadoop\安装包\Java1.8环境下编译\hadoop-2.7.3\ha ...
- 【noi 2.5_1789】算24(dfs)
最开始我想的是全排列+枚举符号和括号的方法,但是我自己倒腾了很久还是打不对,只好向他人请教.正解很机智--直接随意将几个数"捆绑"在一起,值存在其中一个数上,其他数标记不可再选,直 ...
- A. Little Pony and Expected Maximum
Twilight Sparkle was playing Ludo with her friends Rainbow Dash, Apple Jack and Flutter Shy. But she ...
- Gym 100796K Profact
Alice is bored out of her mind by her math classes. She craves for something much more exciting. Tha ...
- linux 部署 .net core mvc
1.本地编写一个mvc网站 代码编辑器:Visual studio 2017.2019.Visual Code 均可 1)搭建 略. (请自行搜索如何编辑mvc,或看文末参考链接) 2)配置 Prog ...
- SSH 密钥认证
目录 SSH协议概述 SSH 和 Telnet 的区别 SSH 相关命令 SSH 验证方式 基于密钥的安全认证 SSH 优化 expect 脚本免交互登录 sshpass 免交互登录 SSH协议概述 ...
- JavaScript常见笔试题分析
1.Javascript的typeof可能返回的结果有哪些? 答:共6种,具体为number ,boolean,string,undefined,function,object(对象或者null返 ...
- 洛谷p1198 最大数
#include <iostream> #include <cstdio> #include <algorithm> using namespace std; in ...