python安装及简单爬虫(爬取导师信息)
1.下载:
解释器(我下的是3.8.2版本):https://www.python.org/downloads/
pycharm(我下的是2019.3.3版本):https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows
注意:python安装时要勾选
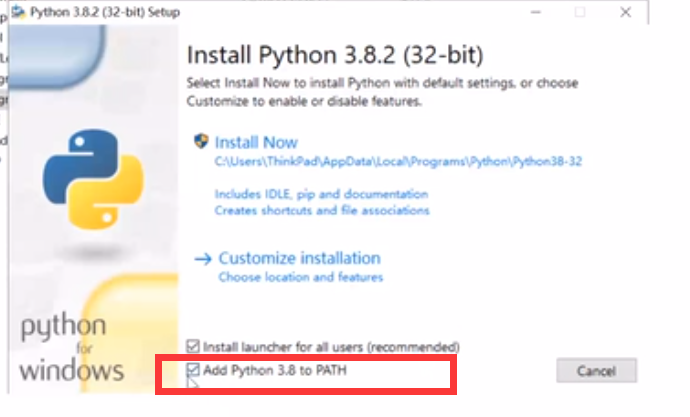
检查python是否安装好可以在cmd命令中输入python,出现下图即可

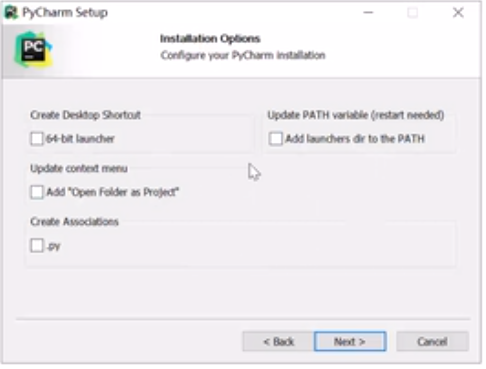
pycharm安装时这四个全选上(只有30天试用期)
JB全家桶永久激活:https://www.exception.site/essay/how-to-free-use-intellij-idea-2019-3
2.爬取网页信息(以浙工大为例)http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id=35


# -*- codeing = utf-8 -*-
#@Time : 2022/2/20 16:44
#@Auther : 叶丹薇
#@File : spider.py
#@Software: PyCharm
from bs4 import BeautifulSoup #网页解析
import re #正则
import urllib.request,urllib.error #制定url 获取网页数据
import sqlite3 #数据库
import xlwt #excel
def main():
baseurl="http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id="
#1.爬取网页
datalist=getData(baseurl)
savepath="导师.xls"
#3保存
saveData(datalist,savepath) findname=re.compile(r'<li><a.*?>(.*?)</a><br/>')#<a href=
finddire=re.compile(r'研究方向:(.*?)</a>')#<a href="#">空间信息计算研究所</a>
findcoll=re.compile(r'<li><a href="#">(.*?)</a>')
#1.爬取网页
def getData(baseurl):
datalist=[]
for j in range(35,50):
url=baseurl+str(j)
html=askURL(url)
if(html==''):continue
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
item0=soup.find_all('div',id="boxtitle3")
item0=str(item0)
colle = re.findall(findcoll,item0)[1]
for item in soup.find_all('div',style="width:100%; float:left"):#查找符合要求的字符串
item=str(item)
teacher=re.findall(findname,item)
director = re.findall(finddire, item)
for i in range(len(teacher)):
data = []
data.append(teacher[i])
data.append(colle)
data.append(director[i])
datalist.append(data)
# print(data)
# print(datalist)
return datalist #得到指定URL的网页内容
def askURL(url):
#模拟浏览器头部,进行伪装
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
request=urllib.request.Request(url,headers=head)#请求
html=""
try:
response=urllib.request.urlopen(request)#响应
html=response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
#print("这页没有内容")
html=''
return html
#保存数据
def saveData(datalist,savepath):
book=xlwt.Workbook(encoding="utf-8")#创建word对象
sheet=book.add_sheet('老师',cell_overwrite_ok=True)#创建sheet表
col=("姓名","研究所","研究方向")
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(0,len(datalist)):
#print("第%d条"%(i+1))
data=datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
book.save(savepath)
if __name__=="__main__":
main()
python安装及简单爬虫(爬取导师信息)的更多相关文章
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- 简单爬虫-爬取免费代理ip
环境:python3.6 主要用到模块:requests,PyQuery 代码比较简单,不做过多解释了 #!usr/bin/python # -*- coding: utf-8 -*- import ...
- python实战之原生爬虫(爬取熊猫主播排行榜)
""" this is a module,多行注释 """ import re from urllib import request # B ...
- PHP简单爬虫 爬取免费代理ip 一万条
目标站:http://www.xicidaili.com/ 代码: <?php require 'lib/phpQuery.php'; require 'lib/QueryList.php'; ...
- 一个简单python爬虫的实现——爬取电影信息
最近在学习网络爬虫,完成了一个比较简单的python网络爬虫.首先为什么要用爬虫爬取信息呢,当然是因为要比人去收集更高效. 网络爬虫,可以理解为自动帮你在网络上收集数据的机器人. 网络爬虫简单可以大致 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- Dubbo 中 Zookeeper 注册中心原理分析
vivo 互联网服务器团队- Li Wanghong 本文通过分析Dubbo中ZooKeeper注册中心的实现ZooKeeperResitry的继承体系结构,自顶向下分析了AbstractRegist ...
- 请求的URI过长:414 Request-URI Too Large
问题:在项目中遇到使用get 请求,发现前端传递的参数超过nginx 服务器的限制.三种解决方法(任选一种): 1.在nginx配置文件里面把这两个缓存加大 文件位置:conf/nginx.conf ...
- STL关联式容器使用注意、概念总结
引入 继上文 STL序列式容器使用注意.概念总结 继续总结关联式容器的概念以及一些使用事项. 关联式容器与容器适配器 基础容器 STL 中的关联式底层容器:RB tree, hash table,可以 ...
- vue学习笔记(一)---- vue指令(浪起来~~~哦耶 的案例)
案例实现分析: 把第一个字符追加到最后一个字符身上去 基本结构: <body> <div id="app"> <input type="bu ...
- TamperMonkey油猴脚本获取
TamperMonkey官网-脚本获取页面 https://www.tampermonkey.net/scripts.php?ext=dhdg 脚本站点1:Userscript.ZoneSear ...
- IIS重定向HTTP至HTTPS
一.安装URL重写模块,自行百度下载 二.选择网站进行添加规则 三.总结 其实就是在站点的Web.config增加了一段配置: <system.webServer> <rewrite ...
- Docker部署Nacos自动停止运行
1.现象 使用docker部署的Nacos在运行一段时间后,就自动停止运行了. 查看docker运行容器,nacos停止了 2.解决 因为是学生购买的轻量级服务器,所以配置很低,出现这种问题我默认是内 ...
- react 高效高质量搭建后台系统 系列 —— 结尾
其他章节请看: react 高效高质量搭建后台系统 系列 尾篇 本篇主要介绍表单查询.表单验证.通知(WebSocket).自动构建.最后附上 myspug 项目源码. 项目最终效果: 表单查询 需求 ...
- day15-SpringMVC执行流程
SpringMVC执行流程 1.SpringMVC执行流程分析图 例子 (1)创建 HaloHandler package com.li.web.debug; import org.springfra ...
- WPF BasedOn 自定义样式 例:ComboBox 组合框
自定义样式 ComboBox 组合框 <Window.Resources> <Style x:Key="ComboBox01" TargetType=" ...