【godis】skiplist
skiplist
前言:在看代码时看到 ZSKIPLIST_MAXLEVEL = 32,当时并不了解 ZSKIPLIST_P 的作用,想着用 2 分法不应该层数是 64 吗?书上和他人的代码都是基于 5.0 的(5.0 上是 64),于是好奇后面又为什么改了。于是查了一些资料做下记录
为什么 ZSKIPLIST_MAXLEVEL = 32 ?
https://stackoverflow.com/questions/60017681/is-zskiplist-maxlevel64-enough-for-264-elements
ZSKIPLIST_MAXLEVEL 和 ZSKIPLIST_P 相关:
- 将元素个数上限设置在 264 已经是一个很大的值了,如果再大也存不下了,因为用来表示总数的 length 的类型 unsigned long 在 64 位机器上也只有 8 个字节
- 平均每两个节点升一层,那么需要 64 层;而如果平均每四个节点升一层,只需要 32 层,此时相对于 n 层,有 1/4 的节点有 n+1 层,因此 ZSKIPLIST_P=0.25。
- 至于为什么取 1/4,下方提供的论文中作者在 Choosing p 中作了说明
跳表原理
https://homepage.cs.uiowa.edu/~ghosh/skip.pdf
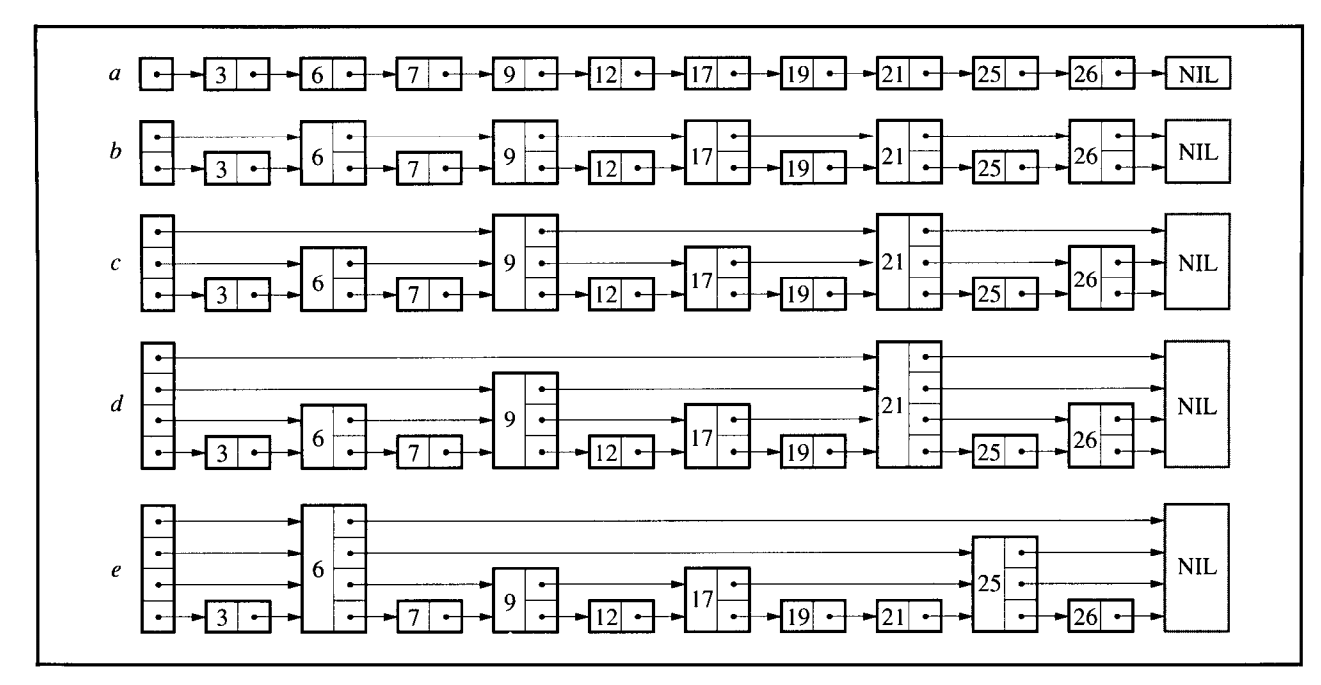
d:
- 优点:
相对于 c: d 的每一层的指针都指向距离它 2level 位置的节点, 因此将搜索的时间复杂度降到了 O(log2n) - 缺点:
增删改节点时,需要时刻考虑修改跳表中其他节点的层数,增大修改的难度
- 优点:
e:
- 优点:
从 d 中可以找到规律,由于层数只会在索引为 2 的倍数的节点上增加,因此索引为单数的节点的层数只有一层,共有 50% 个这样的节点,层数为 2 的节点数量为 25%, 以此类推……因此,不妨将所有节点的层数打乱,但仍然保持这样的比例分配,并且无法修改节点的层数。这样,增删改节点时,都不会影响其他节点的层数。 - 缺点:
就像抛硬币一样,尽管理论上正反面的概率都是 50%,但那也是在大量实验后才会逐渐接近这个理论值。如果节点比较少,计算得到的层数都很低或都很高,那么就变成了一条链表,时间复杂度降低到 O(n)。因此,通过该方式虽然可以减少代码复杂度,但是能否准确的达到预期,这是随机的。
- 优点:
随机层高
实现 e 的关键部分,减小代码实现难度。
假设 d 中的底数为 3,第二层在第一层的基础上每三个加一层;第三层又是在第二层的基础上每三个加一层……最终,只有一层的节点比例为 \(\frac{2}{3}\), 第二层的比例为 \((1-\frac{2}{3})\cdot\frac{2}{3}\)
因此以一般情况 p 代替 \(\frac{2}{3}\),可以得到
\]
random level
func randomLevel() int {
newLevel := 1
for rand.Float64() < p { // 这里的 p 为非该层的概率
newLevel++
}
return newLevel
}
以下用 insert 方法来体现 random_level 的优势:
因为用到了随机高度,因此在插入新节点时无需改动其他节点的高度。但是需要保存所有层级比新节点低的且原本可以指向新节点之后节点的 forward,可以在降低层级时保存每个 forward。
【注】
在论文中,如果插入了含有已存在的 search key 的 element,则会替换旧的 element
func (zsl *zskiplist) Insert(score float64, ele string) *zskiplistNode {
var (
update [ZSKIPLIST_MAXLEVEL]*zskiplistNode
x *zskiplistNode
)
x = zsl.header
for i := zsl.level - 1; i >= 0; i-- {
for x.level[i].forward != nil &&
(x.level[i].forward.score < score ||
(x.level[i].forward.score == score && x.level[i].forward.ele < ele)) {
x = x.level[i].forward
}
update[i] = x
}
x = x.level[0].forward
if x != nil && x.score == score {
x.ele = ele
return x
}
level := randomLevel()
if zsl.level < level {
for i := zsl.level; i < level; i++ {
update[i] = zsl.header
}
zsl.level = level
}
x = zslCreateNode(level, score, ele)
for i := 0; i < zsl.level; i++ {
x.level[i].forward = update[i].level[i].forward
update[i].level[i].forward = x
}
if update[0] == zsl.header {
x.backward = nil
} else {
x.backward = update[0]
}
if x.level[0].forward == nil {
zsl.tail = x
} else {
x.level[0].forward.backward = x
}
zsl.length++
return x
}
【godis】skiplist的更多相关文章
- 【Redis】skiplist跳跃表
有序集合Sorted Set zadd zadd用于向集合中添加元素并且可以设置分值,比如添加三门编程语言,分值分别为1.2.3: 127.0.0.1:6379> zadd language 1 ...
- 【转】SkipList跳表基本原理
增加了向前指针的链表叫作跳表.跳表全称叫做跳跃表,简称跳表.跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表.跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找.跳表不仅 ...
- 基于.NetCore的Redis5.0.3(最新版)快速入门、源码解析、集群搭建与SDK使用【原创】
1.[基础]redis能带给我们什么福利 Redis(Remote Dictionary Server)官网:https://redis.io/ Redis命令:https://redis.io/co ...
- 【Redis】redis各类型数据存储分析
一.简介和应用 Redis是一个由ANSI C语言编写,性能优秀.支持网络.可持久化的K-K内存数据库,并提供多种语言的API.它常用的类型主要是 String.List.Hash.Set.ZSet ...
- 【Redis】内部数据结构自顶向下梳理
本博客将顺着自顶向下的思路梳理一下Redis的数据结构体系,从数据库到对象体系,再到底层数据结构.我将基于我的一个项目的代码来进行介绍:daredis.该项目中,使用Java实现了Redis中所有的数 ...
- Python高手之路【六】python基础之字符串格式化
Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存.[PEP-3101] This ...
- 【原】谈谈对Objective-C中代理模式的误解
[原]谈谈对Objective-C中代理模式的误解 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 这篇文章主要是对代理模式和委托模式进行了对比,个人认为Objective ...
- 【原】FMDB源码阅读(三)
[原]FMDB源码阅读(三) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 FMDB比较优秀的地方就在于对多线程的处理.所以这一篇主要是研究FMDB的多线程处理的实现.而 ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
- 【调侃】IOC前世今生
前些天,参与了公司内部小组的一次技术交流,主要是针对<IOC与AOP>,本着学而时习之的态度及积极分享的精神,我就结合一个小故事来初浅地剖析一下我眼中的“IOC前世今生”,以方便初学者能更 ...
随机推荐
- Spring cloud Sleuth 分布式链路跟踪
在微服务框架种. 一个由客户端发起的请求在后端系统种会经过不同的服务节点来调用协同产生的最后的请求结果. 每一个前端请求都会形成一条复杂的分布式服务调用的链路.链路种出现任何一环出现高延时或者错误都会 ...
- 使用elasticsearch-head修改一个索引的副本数
一.背景 有一个很久以前设置的无副本索引放入了ES集群中,为了提升该索引的稳定性,需要添加一个副本 尝试curl方法失败以及因为es版本太旧(低于5.0.0)用不了kibana,并且用Python修改 ...
- vue 使用import之后就会报Object(...) is not a function的错
最近在学习vue,学到了路由,vue-router, 写demo的时候,想引入import VueRotuer from "vue-router",但是添加这句引用浏览器就会报错, ...
- P1886 滑动窗口 /【模板】单调队列
滑动窗口 /[模板]单调队列 题目描述 有一个长为 \(n\) 的序列 \(a\),以及一个大小为 \(k\) 的窗口.现在这个从左边开始向右滑动,每次滑动一个单位,求出每次滑动后窗口中的最大值和最小 ...
- Codeforces 1228A、Distinct Digits
原题 原题网址 题目大意 给定一个区间(上下界都是整数),判断该区间内是否存在一个整数的数字两两不同. 数据结构 一个数组flag,记录0-9是否出现过. 思路 外层循环枚举该区间内所有整数. 首先初 ...
- springcloud 和springboot版本对比
版本对应关系大版本对应: Spring Cloud Spring Boot Angel版本 兼容Spring Boot 1.2.x Brixton版本 兼容Spring Boot 1.3.x,也兼容S ...
- 2023 2 4 c++NOIP机试 小豫豫在郑州 type
1 #include <iostream> 2 #include <string> 3 using namespace std; 4 int j(string str){ 5 ...
- JDK-11.0.17 + Neo4j-4.4.12
JDK安装 下载地址:https://www.oracle.com/java/technologies/javase-downloads.html 注册Oracle账户,并下载,选择路径安装,将bin ...
- 生产中遇到的spark任务问题
spark版本 2.2.0 日志里面的信息: WARN RowBasedKeyValueBatch: Calling spill() on RowBasedKeyValueBatch. Will no ...
- 初学pwn的课程第一课
pwn的攻击基础原理 我的理解是主要通过分析主文件,然后获得有用信息,通过exploit对服务器输入指定的payload数据,获取服务器的shell,就是进入服务器的终端,获取服务器的控制权,对服务器 ...