2003031121-浦娟-python数据分析五一假期作业
| 项目 | 内容 |
| 课程班级博客链接 | 20级数据班(本) |
| 这个作业要求链接 | Python作业 |
| 博客名称 | 2003031121-浦娟-python数据分析五一假期作业 |
| 要求 | 每道题要有题目,代码(使用插入代码,不会插入代码的自己查资料解决,不要直接截图代码!!),截图(只截运行结果)。 |
作业:
把期中考试代码看懂、运行并调通,要求每一行 或 每个重要功能写上注释。
一、分析1996~2015年人口数据特征间的关系
- import numpy as np
- import matplotlib.pyplot as plt
- #使⽤numpy库读取数据
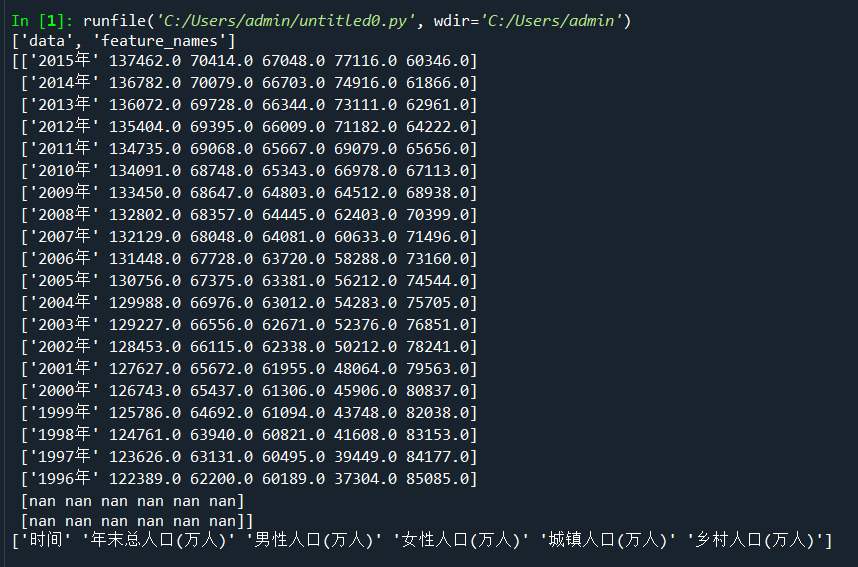
- data=np.load('E:/桌面/populations.npz',allow_pickle=True)
- print(data.files)#查看⽂件中的数组
- print(data['data'])
- print(data['feature_names'])
- plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
- plt.rcParams['axes.unicode_minus'] = False# 防止字符无法显示
- name=data['feature_names']#提取其中的feature_names数组,视为数据的标签
- values=data['data']#提取其中的data数组,视为数据的存在位置
- p1=plt.figure(figsize=(12,12))#确定画布大小
- pip1=p1.add_subplot(2,1,1)#创建一个两行个一列的图并开始绘制
- #在子图上绘制散点图
- plt.scatter(values[0:20,0],values[0:20,1])#,marker='8',color='red'
- plt.ylabel('总人口(万人)')
- plt.legend('年末')
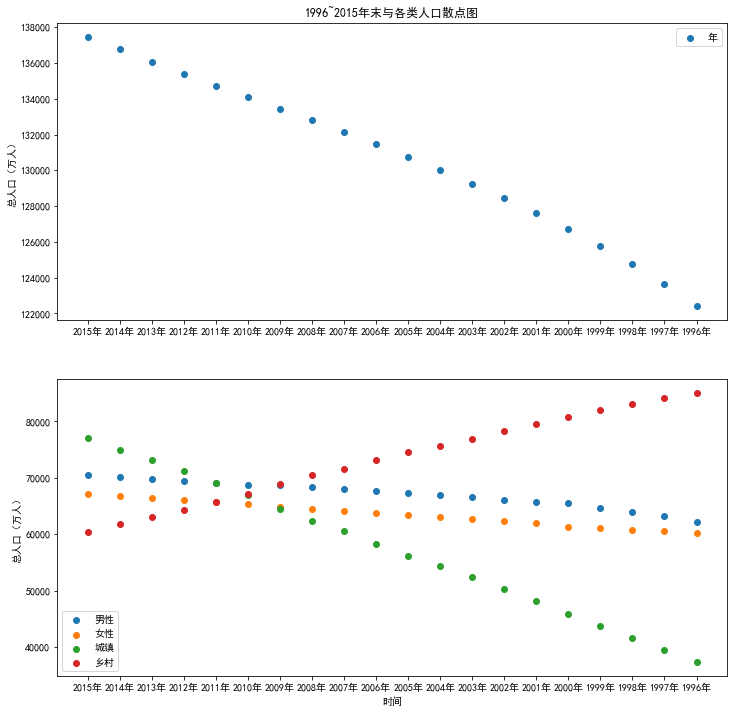
- plt.title('1996~2015年末与各类人口散点图')
- pip2=p1.add_subplot(2,1,2)#绘制图2
- plt.scatter(values[0:20,0],values[0:20,2])#,marker='o',color='yellow'
- plt.scatter(values[0:20,0],values[0:20,3])#,marker='D',color='green'
- plt.scatter(values[0:20,0],values[0:20,4])#,marker='p',color='blue'
- plt.scatter(values[0:20,0],values[0:20,5])#,marker='s',color='purple'
- plt.xlabel('时间')
- plt.ylabel('总人口(万人)')
- plt.xticks(values[0:20,0])
- plt.legend(['男性','女性','城镇','乡村'])
- #在⼦图上绘制折线图
- p2=plt.figure(figsize=(12,12))
- p1=p2.add_subplot(2,1,1)
- plt.plot(values[0:20,0],values[0:20,1])#,linestyle = '-',color='r',marker='8'
- plt.ylabel('总人口(万人)')
- plt.xticks(range(0,20,1),values[range(0,20,1),0],rotation=45)#rotation设置倾斜度
- plt.legend('年末')
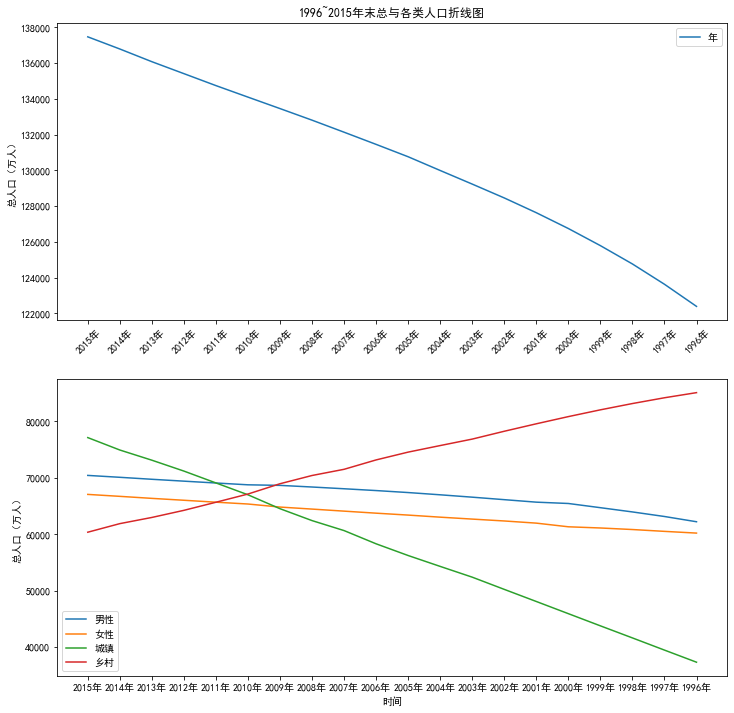
- plt.title('1996~2015年末总与各类人口折线图')
- p2=p2.add_subplot(2,1,2)
- plt.plot(values[0:20,0],values[0:20,2])#,'y-'
- plt.plot(values[0:20,0],values[0:20,3])#,'g-.'
- plt.plot(values[0:20,0],values[0:20,4])#,'b-'
- plt.plot(values[0:20,0],values[0:20,5])#,'p-'
- plt.xlabel('时间')
- plt.ylabel('总人口(万人)')
- plt.xticks(values[0:20,0])
- plt.legend(['男性','女性','城镇','乡村'])
- #显示图片
- plt.show()
二、读取并查看P2P网络贷款数据主表的基本信息
- import os
- import pandas as pd
- master = pd.read_csv('E:/桌面/Training_Master .csv',encoding='gbk')
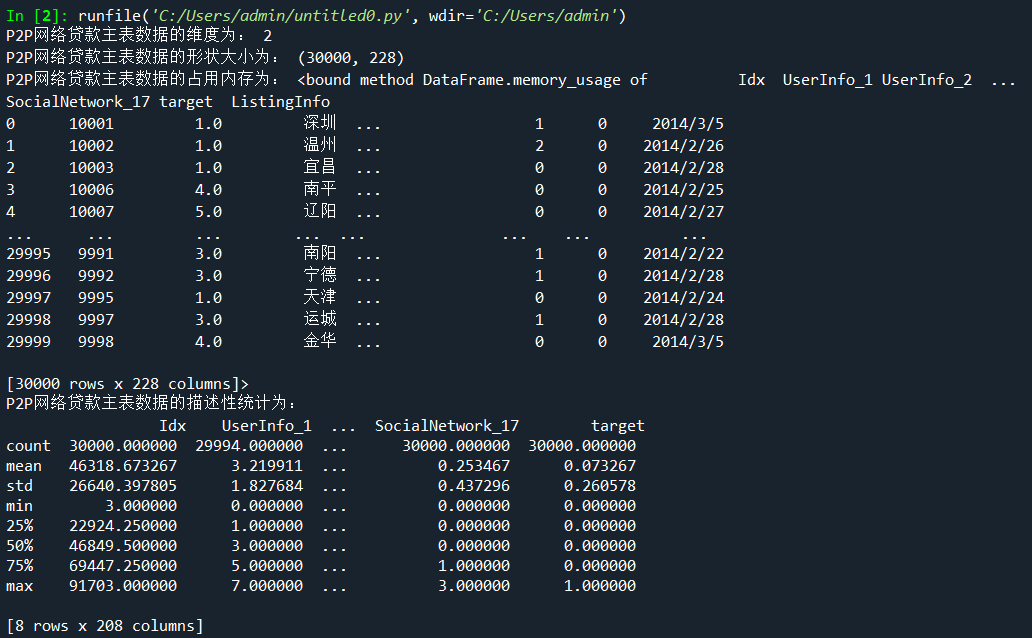
- print('P2P网络贷款主表数据的维度为:',master.ndim)
- print('P2P网络贷款主表数据的形状大小为:',master.shape)
- print('P2P网络贷款主表数据的占用内存为:',master.memory_usage)
- print('P2P网络贷款主表数据的描述性统计为:\n',master.describe())
三、提取用户信息更新表和登录信息表的时间信息
- import pandas as pd
- LogInfo = pd.read_csv('E:/桌面/Training_LogInfo .csv',encoding='gbk')
- Userupdate = pd.read_csv('E:/桌面/Training_Userupdate.csv',encoding='gbk')
- # 转换时间字符串
- LogInfo['Listinginfo1']=pd.to_datetime(LogInfo['Listinginfo1'])
- LogInfo['LogInfo3']=pd.to_datetime(LogInfo['LogInfo3'])
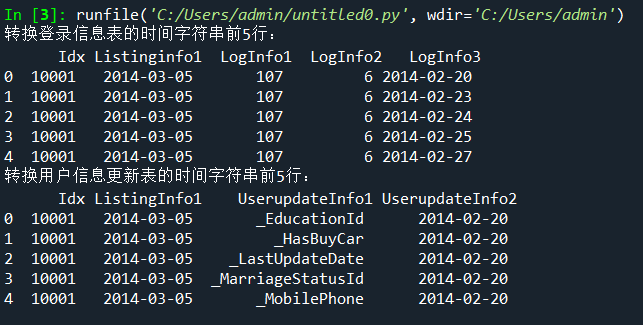
- print('转换登录信息表的时间字符串前5行:\n',LogInfo.head())
- Userupdate['ListingInfo1']=pd.to_datetime(Userupdate['ListingInfo1'])
- Userupdate['UserupdateInfo2']=pd.to_datetime(Userupdate['UserupdateInfo2'])
- print('转换用户信息更新表的时间字符串前5行:\n',Userupdate.head())
四、使用分组聚合方法进一步分析用户信息更新表和登录信息表
- import pandas as pd
- import numpy as np
- LogInfo = pd.read_csv('E:/桌面/Training_LogInfo .csv',encoding='gbk')
- Userupdate = pd.read_csv('E:/桌面/Training_Userupdate.csv',encoding='gbk')
- # 使用groupby方法对用户信息更新表和登录信息表进行分组
- LogGroup = LogInfo[['Idx','LogInfo3']].groupby(by = 'Idx')
- UserGroup = Userupdate[['Idx','UserupdateInfo2']].groupby(by = 'Idx')
- # 使用agg方法求取分组后的最早,最晚,更新登录时间
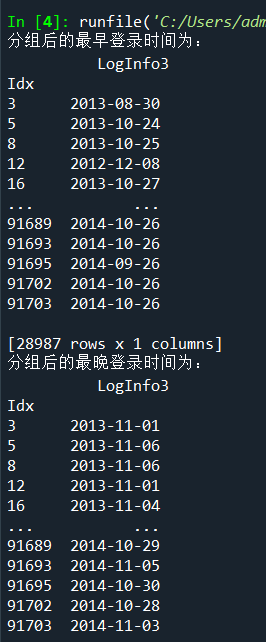
- print('分组后的最早登录时间为:\n',LogGroup.agg(np.min))
- print('分组后的最晚登录时间为:\n',LogGroup.agg(np.max))
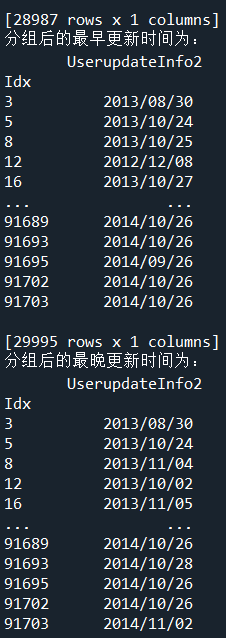
- print('分组后的最早更新时间为:\n',UserGroup.agg(np.min))
- print('分组后的最晚更新时间为:\n',UserGroup.agg(np.max))
- # 使用size方法求取分组后的数据的信息更新次数与登录次数
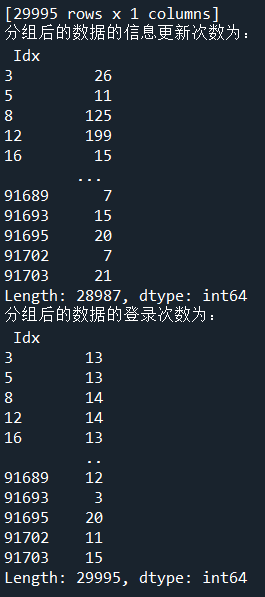
- print('分组后的数据的信息更新次数为:\n',LogGroup.size())
- print('分组后的数据的登录次数为:\n',UserGroup.size())
2003031121-浦娟-python数据分析五一假期作业的更多相关文章
- 2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用
项目 要求 课程班级博客链接 20级数据班(本) 作业要求链接 Python第七周作业 博客名称 2003031121--浦娟--Python数据分析第七周作业--MySQL的安装及使用 要求 每道题 ...
- 2003031121-浦娟-python数据分析第四周作业-第二次作业
项目 内容 课程班级博客链接 20级数据班(本) 作业链接 Python第四周作业第二次作业 博客名称 2003031121-浦娟-python数据分析第四周作业-matolotlib的应用 要求 每 ...
- 2003031121-浦娟-python数据分析第三周作业-第一次作业
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/pexy/20sj 作业链接 https://edu.cnblogs.com/campus/pexy/20s ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (3/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- 零基础学习Python数据分析
网上虽然有很多Python学习的教程,但是大多是围绕Python网页开发等展开.数据分析所需要的Python技能和网页开发等差别非常大,本人就是浪费了很多时间来看这些博客.书籍.所以就有了本文,希望能 ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
随机推荐
- JVM的小总结(转)
ref:http://www.cnblogs.com/ityouknow/p/6482464.html 注1:看了大神:纯洁的微笑的JVM系列篇,发现好多地方还是似懂非懂,理解的并不透彻,jvm的调优 ...
- 在 mapper 中如何传递多个参数?
1.第一种: DAO 层的函数 public UserselectUser(String name,String area); 对应的 xml,#{0}代表接收的是 dao 层中的第一个参数,#{1} ...
- piwik安装部署
1.piwik介绍 Piwik是一个PHP和MySQL的开放源代码的Web统计软件,它给你一些关于你的网站的实用统计报告,比如网页浏览人数,访问最多的页面,搜索引擎关键词等等. Piwik拥有众多不同 ...
- mysql8.0时区问题
今天在mysql新增一条数据的时候,发现时间类型的字段比起现在少了8个小时,查了资料才发现,这个是MySQL8.0出现的问题,讲下解决方法. 1.在java项目中application.yml文件中的 ...
- 攻防世界php_rce
php_rce 进入题目提示为ThinkPHP V5 遇到这种题我们一般去找一下框架的rce漏洞即可,搜索到这样一篇文章 https://www.freebuf.com/articles/web/28 ...
- c++的常用库
C++ 资源大全 关于 C++ 框架.库和资源的一些汇总列表,内容包括:标准库.Web应用框架.人工智能.数据库.图片处理.机器学习.日志.代码分析等. 标准库 C++标准库,包括了STL容器,算法和 ...
- 1. 了解Git和Github
1. 了解Git和Github 1.1 什么是Git Git是一个免费.开源的版本控制软件 1.2 什么是版本控制系统 版本控制是一种记录一个或若干个文件内容变化,以便将来查阅特定版本修订情况得系统. ...
- (stm32f103学习总结)—输入捕获模式
一.输入捕获介绍 在定时器中断实验章节中我们介绍了通用定时器具有多种功能,输入捕获就是其中一种.STM32F1 除了基本定时器 TIM6 和 TIM7,其他定时器都具有输入捕获功能.输入捕获可以对输入 ...
- window onerror 各浏览器下表现总结
window onerror 各浏览器下表现总结 做前端错误上报,必然离不开window onerror,但window onerror在不同设备上表现并不一致,浏览器为避免信息泄露,在一些情况下并不 ...
- This program may be freely redistributed under the terms of the GNU GPL
在centos中安装Google浏览器时 执行[root@server1 opt]# rpm ivh install google-chrome-stable_current_x86_64.rpm 爆 ...