IO学习笔记(全)
IO学习笔记
一、IO前置知识--Linux系统
根据冯诺依曼计算机结构,计算机的组成为:运算器、控制器、存储器、输入输出设备。
在现代计算机中,运算器和控制器集成为了cpu,存储器按照功能可以拆分为内存和磁盘。而输入输出设备也就是键盘、显示器等,统称为IO。
而Linux系统其实也是一个普通的程序,它运行在内存中。但是因为其特殊性,因此它在内存中存放的位置我们称之为kernel,即内核。而内存的其他位置可以用来运行应用程序。因此我们可以将内存分为内核空间和应用空间。

应用程序运行在kernel以外的空间上,应用程序默认整块内存都是可以使用的。
在kernel中,运行Linux系统程序,系统程序使用虚拟文件树(VFS)来管理应用程序。既然是文件,那么必然会伴随着IO的存在,因此kernel中还是用了pageCache来提升IO的效率。同时每一个文件都会有一个Inode标记文件唯一存在。
1.1 Linux系统--虚拟文件系统(VFS)
Linux是一个虚拟文件系统,在Linux中一切皆文件。
1.1.1 首先我们来了解一下Linux中的文件描述
-rw-r--r--. 1 root root 0 Apr 15 13:41 aaa.txt
上面是一个名为aaa.txt的文件,文件的描述信息有-rw-r--r--. 1 root root 0 4月 15 13:41。下面解析此描述信息:
开头的
-就代表这个文件的类型。后面的
rw-r--r--代表的是此文件的权限。每三个为一组,可以分为如下三组:u g ou:表示文件所属用户对此文件所拥有的权限。g:表示文件所属用户所在组的其他用户对此文件所拥有的权限。o: 表示当前系统中所有用户对此文件所拥有的权限。
除了以上三个级别外,还有一个
a的组表示以上三组的总和。上面三组权限信息,每一组又对应了三种权限信息:r: 读w: 写x: 可执行
三种权限对应的
---位置为rwx从前到后。因此我们给一个文件赋其他的权限时可以写:[root@node01 zhaoshuai]# chmod u+x aaa.txt
[root@node01 zhaoshuai]# ll
总用量 0
-rwxr--r--. 1 root root 0 4月 15 13:41 aaa.txt
表示为
aaa.txt文件所属用户赋予可执行的权限。chmod修改文件的权限信息。+表示添加,对应的-表示去除,还有=表示重新定义权限信息。除了使用上面的方式外,我们还会使用
chmod 777 aaa.txt来为文件修改权限信息。因为一组的权限信息rwx,每一位都是用二进制表示时,当rwx同时存在,那么也就是111,正好是7。因此100也就是4就对应的r,2就对应的是w,1对用的x。每一位相加所得得和就是当前组所拥有得权限,最大为7。1 表示这个文件的引用数量。
后面第一个
root表示此文件所属用户名。后面第二个
root表示此文件所属用户所在组的组名。再后面
0表示此文件的大小--字节数大小。当前是一个空文件,所以为0。后面
Apr 15 13:41表示此文件的创建时间。最后就是此文件的文件名
aaa.txt。
1.1.2 文件类型
上面了解了每一项的意思后,我们再来看第一项文件类型
linux中的文件主要分为以下几种类型
-: 普通文件-rw-r--r--. 1 root root 0 Apr 15 13:41 aaa.txt
d: 文件夹drwxr-xr-x. 2 root root 6 Apr 15 14:28 dir
l: 软链接/硬连接链接是一种文件共享的方式。可以将链接简单的理解成window系统中的快捷方式。
首先我们创建一个文件:
[root@node01 zhaoshuai]# mkdir link
[root@node01 zhaoshuai]# cd link
[root@node01 link]# echo "hello world" > aaa.txt
[root@node01 link]# ll
总用量 4
-rw-r--r--. 1 root root 12 4月 15 15:17 aaa.txt
然后使用
stat命令查看aaa.txt文件的信息:[root@node01 link]# stat aaa.txt
文件:"aaa.txt"
大小:12 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:16781506 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:home_root_t:s0
最近访问:2021-04-15 15:17:44.775499928 +0800
最近更改:2021-04-15 15:17:44.775499928 +0800
最近改动:2021-04-15 15:17:44.775499928 +0800
创建时间:-
可以看到一个
Inode的值,每个文件都会有一个Inode号。Inode是什么?在Linux中,文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”,每个扇区存储512字节。
但是操作系统读取文件时并不会按照扇区来读,因为这样效率太低。而是一次读取连续的多个扇区,多个扇区组成一个“块”。操作系统按块读取。块大小常见为
4K,即8个扇区。文件中的数据存放在块中,但是必须还要有一个地方存储文件的元数据信息,比如:文件创建者,创建时间,大小等。这种存放元数据信息的区域就叫做
Inode,中文名:“索引节点”。Inode也是占用磁盘空间的。因此在磁盘格式化时,会自动将磁盘分成两个区域,一个用来存放数据信息的。一个是用来存放inode元数据信息的。每个
Inode节点的大小为128字节或256字节,在格式化阶段,就给定Inode节点的总数,一般每1K或2K就会设定一个Inode。例如:磁盘大小为1G,每个Inode节点大小为128字节,每1K生成一个Inode,那么最终
Inode大小就为128M。每一个文件都会分配一个
Inode,当Inode用完时,就无法再创建新的文件。硬链接:在上面解释了每一个文件都会分配一个
Inode号,这个Inode号指向一个磁盘块,Linux系统通过这个Inode号找到对应的磁盘块,然后加载文件,这个Inode号就像一个指针一样。然后我们为aaa创建一个硬连接:[root@node01 link]# ln aaa.txt bbb.txt
[root@node01 link]# ls -li
16781506 -rw-r--r--. 3 root root 12 4月 15 15:17 aaa.txt
16781506 -rw-r--r--. 3 root root 12 4月 15 15:17 bbb.txt
ln 源文件 输出文件: 通过ln创建链接ls -li参数i可以展示Inode号。通过上面参数可以看出,
aaa.txt和bbb.txt两个文件指向了同一个磁盘块,他们的Inode号都是一样的。因此当删除其中一个文件时,并不影响另一个文件的访问。[root@node01 link]# rm -rf aaa.txt
[root@node01 link]# ll
-rw-r--r--. 1 root root 12 4月 15 15:17 bbb.txt
[root@node01 link]# cat bbb.txt
hello world
即使删掉原文件
aaa.txt,也不影响bbb.txt文件的访问。在linux系统中,会为每一个Inode维护一个引用计数,只要还有一个引用指向这个磁盘块,文件就不会被删除。而
Inode就是这个引用。软连接:我们再对
bbb.txt文件创建一个软链接[root@node01 link]# ll
总用量 4
-rw-r--r--. 1 root root 12 4月 15 15:17 bbb.txt
[root@node01 link]# ln -s bbb.txt ccc.txt
[root@node01 link]# ll -i
总用量 4
16781506 -rw-r--r--. 1 root root 12 4月 15 15:17 bbb.txt
16781507 lrwxrwxrwx. 1 root root 7 4月 19 10:58 ccc.txt -> bbb.txt
可以看到,
bbb.txt和ccc.txt文件的Inode号并不一样,这就说明这两个文件指向的区块是不一样的。ccc.txt的文件类型为l。[root@node01 link]# cat bbb.txt
hello world
[root@node01 link]# cat ccc.txt
hello world
[root@node01 link]# rm -rf bbb.txt
[root@node01 link]# cat ccc.txt
cat: ccc.txt: 没有那个文件或目录
通过上面的操作,可以看出,当源文件存在时,软连接可以正常访问,但是当删除原文件后,访问软连接会报错:没有那个文件或目录。
可以理解为软链接其实内部存放的源文件的地址,当访问软链接时,系统自动重定向到源文件的地址。
在软链接文件的后面会有一个
> xxx的展示,而在linux系统中,>也就是重定向的标志。
b: 块设备。磁盘就属于一个块设备。[root@node01 ~]# ls
anaconda-ks.cfg
[root@node01 ~]# cd /home/zhaoshuai/
[root@node01 zhaoshuai]# ls
aaa.txt dir image link pipline test.txt
[root@node01 zhaoshuai]# cd image/
[root@node01 image]# ll
总用量 0
[root@node01 image]# dd if=/dev/zero of=mydisk.img bs=1048576 count=100
记录了100+0 的读入
记录了100+0 的写出
104857600字节(105 MB)已复制,0.318326 秒,329 MB/秒
[root@node01 image]# ll -h
总用量 100M
-rw-r--r--. 1 root root 100M 4月 20 09:54 mydisk.img
[root@node01 image]# losetup /dev/loop0 mydisk.img
[root@node01 image]# mke2fs /dev/loop0
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: 完成
文件系统标签=
OS type: Linux
块大小=1024 (log=0)
分块大小=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
25688 inodes, 102400 blocks
5120 blocks (5.00%) reserved for the super user
第一个数据块=1
Maximum filesystem blocks=67371008
13 block groups
8192 blocks per group, 8192 fragments per group
1976 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729 Allocating group tables: 完成
正在写入inode表: 完成
Writing superblocks and filesystem accounting information: 完成 [root@node01 image]# cd ..
[root@node01 zhaoshuai]# ll
总用量 4
---xr--r--. 1 root root 0 4月 15 13:41 aaa.txt
drwxr-xr-x. 2 root root 6 4月 15 14:28 dir
drwxr-xr-x. 2 root root 24 4月 20 09:54 image
drwxr-xr-x. 2 root root 21 4月 19 11:01 link
drwxr-xr-x. 2 root root 22 4月 19 11:34 pipline
-rw-r--r--. 1 root root 145 4月 19 16:55 test.txt
[root@node01 zhaoshuai]# mkdir test
[root@node01 zhaoshuai]# mount -t ext2 /dev/loop0 test
[root@node01 zhaoshuai]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17811456 1246864 16564592 8% /
devtmpfs 485820 0 485820 0% /dev
tmpfs 497948 0 497948 0% /dev/shm
tmpfs 497948 7856 490092 2% /run
tmpfs 497948 0 497948 0% /sys/fs/cgroup
/dev/sda1 1038336 135300 903036 14% /boot
tmpfs 99592 0 99592 0% /run/user/0
/dev/loop0 99150 1550 92480 2% /home/zhaoshuai/test
c: 字符设备。我们的键盘,网卡就是字符设备。[root@node01 link]# cd /dev
[root@node01 dev]# ll
...
crw--w----. 1 root tty 4, 51 4月 15 11:52 tty51
crw--w----. 1 root tty 4, 52 4月 15 11:52 tty52
crw--w----. 1 root tty 4, 53 4月 15 11:52 tty53
...
p:pipline管道父子进程
[root@node01 ~]# echo $$
18388
[root@node01 ~]# bash
[root@node01 ~]# echo $$
18410
打开一个shell窗口,当前进程id为
18388,然后在此窗口中执行bash命令,再次打开一个窗口,也就是说在18388这个进程中再次开启了一个子进程,这个进程的id为18410,然后执行ps命令:[root@node01 ~]# ps -ef |grep 18388
root 18388 18384 0 13:37 pts/0 00:00:00 -bash
root 18410 18388 0 13:42 pts/0 00:00:00 bash
root 18420 18410 0 13:44 pts/0 00:00:00 grep --color=auto 18388
从上面可以看出,18410的父进程是18388。那么我们在18388进程中创建一个变量,在子进程中是否能够访问?
[root@node01 ~]# exit
exit
[root@node01 ~]# echo $$
18388
[root@node01 ~]# a=100
[root@node01 ~]# echo $a
100
[root@node01 ~]# bash
[root@node01 ~]# echo $a [root@node01 ~]#
此时再打开一个子进程,是访问不到变量a的,因为进程间互相隔离。但是使用环境变量的方式可以获取到a,因为子进程会继承父进程的环境变量:
[root@node01 ~]# exit
exit
[root@node01 ~]# export a=100
[root@node01 ~]# echo $a
100
[root@node01 ~]# bash
[root@node01 ~]# echo $$
18454
[root@node01 ~]# echo $a
100
管道
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。管道命令使用
|作为界定符号。例如:
[root@node01 zhaoshuai]# ll
总用量 0
---xr--r--. 1 root root 0 4月 15 13:41 aaa.txt
drwxr-xr-x. 2 root root 6 4月 15 14:28 dir
drwxr-xr-x. 2 root root 21 4月 19 11:01 link
drwxr-xr-x. 2 root root 22 4月 19 11:34 pipline
[root@node01 zhaoshuai]# ll |grep aaa
---xr--r--. 1 root root 0 4月 15 13:41 aaa.txt
将左边的
ll命令的输出,作为右边grep命令的输入,最终打印出过滤后信息。在linux中,可以在shell命令行执行代码块,如下:
[root@node01 ~]# { echo "hello"; echo "world"; }
hello
world
那么执行如下代码:
[root@node01 ~]# a=1
[root@node01 ~]# echo $a
1
[root@node01 ~]# { a=9; echo "hello"; }|cat
hello
[root@node01 ~]# echo $a
此时应该输出1还是9?答案是1;因为通过
|创建的管道两边都是子进程。我们打开的shell窗口其实是执行bash命令打开的一个窗口,bash命令其实是一个解释执行的脚本。因此在执行
{ a=9; echo "hello" }| cat命令时,会查看命令,当看到|符号时,会对管道左边的内容打开一个子进程执行,对右边的内容打开另一个子进程执行。验证上面的内容:
[root@node01 ~]# echo $$
18454
[root@node01 ~]# echo $BASHPID|cat
18487
如果使用$$命令,会发现不生效,因为$$的优先级大于管道,因此bash在解释执行时,会先执行echo $$,然后再创建管道。
验证管道pipline:
[root@node01 ~]# echo $$
18454
[root@node01 ~]# { echo $BASHPID; read x; } | { cat; read y ; echo $BASHPID; }
18491
上面shell命令,首先打印了当前父进程的ID,然后通过管道开启两个子进程,左边子进程输出进程id,然后通过read阻塞左边进程,此时再次打开另一个shell窗口,然后通过ps命令查看子进程:
[root@node01 ~]# ps -ef |grep 18454
root 18454 18388 0 13:52 pts/0 00:00:00 bash
root 18491 18454 0 14:13 pts/0 00:00:00 bash
root 18492 18454 0 14:13 pts/0 00:00:00 bash
root 18512 18495 0 14:15 pts/1 00:00:00 grep --color=auto 18454
可以看到,父进程18454创建了两个子进程,分别是18491和18492。然后查看18491进程的文件描述符:
[root@node01 ~]# cd /proc/18491/fd
[root@node01 fd]# ll
总用量 0
lrwx------. 1 root root 64 4月 19 14:17 0 -> /dev/pts/0
l-wx------. 1 root root 64 4月 19 14:17 1 -> pipe:[109901]
lrwx------. 1 root root 64 4月 19 14:15 2 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 14:17 255 -> /dev/pts/0
可以看到文件描述符1后面内容为:
pipe:[109901]指向了一个管道。通过上面内容,证明了管道的存在。然后回到阻塞界面,随便输入内容结束阻塞。
[root@node01 ~]# { echo $BASHPID; read x; } | { cat; read y ; echo $BASHPID; }
18491
1
18492
可以看到输出左边子进程id为18491,右边子进程id为18492。验证了我们上面说的管道两边两个子进程。
s:socket网络通道通过socket获取百度网页:
[root@node01 fd]# exec 8<> /dev/tcp/www.baidu.com/80
[root@node01 fd]# ll
总用量 0
lrwx------. 1 root root 64 4月 19 10:45 0 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 10:45 1 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 10:45 2 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 11:38 255 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 11:47 8 -> socket:[97361]
可以看到文件描述符8指向了一个socket类型的文件。
[eventpoll]: 多路复用
1.2 用户态和内核态
操作系统在运行过程中,cpu有两种状态,用户态和内核态。
用户态:运行所有的用户程序。
内核态:操作系统运行在内核态。内核态主要负责系统调度以及与硬件的交互。
用户态和内核态的区别
内核态与用户态是操作系统的两种运行级别,当程序运行在3级特权上时,就可以称之为运行在用户态。因为这是最低特权级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态;
当程序运行在0级特权级上时,就可以称之为运行在内核态。
运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态(比如操作硬件)。
这两种状态的主要差别是
处于用户态执行时,进程所能访问的内存空间和对象受到限制,其所处于占有的处理器是可被抢占的
处于内核态执行时,则能访问所有的内存空间和对象,且所占有的处理器是不允许被抢占的。
用户态和内核态之间的切换
通常来说会有三种情况导致cpu状态切换
- 系统调用: 用户程序通过系统调用申请使用操作系统提供的服务完成工作。比如java中的创建线程,就是通过操作系统的
fork()操作创建线程的。而fork()操作最终实际是通过操作系统来创建线程的。这里就存在一个用户态到内核态的切换,主要是通过80中断来完成的。 - 异常: 当
cpu在用户态执行程序时,发生了某些不可知的异常。这时就会从用户态切换到处理此异常的内核相关程序中,也就切换到了内核态。 - 外围设备中断: 当外围设备完成用户请求时,就会向cpu发出相应的中断信号。这时cpu就会暂停执行下一条将要执行的指令,转而去处理与中断信号对应的处理程序。
1.3 fd--文件描述符
在Linux系统中,每一个进程都对应着三个文件描述符:
0: 输入
1: 输出
2: 报错
下面我们来验证上面的结论:
lsof命令
lsof命令可以现实进程打开了哪儿些文件。
[root@node01 fd]# lsof -p $$
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 18572 root cwd DIR 0,3 0 118863 /proc/18572/fd
bash 18572 root rtd DIR 253,0 224 64 /
bash 18572 root txt REG 253,0 964608 50332791 /usr/bin/bash
bash 18572 root mem REG 253,0 106075056 258036 /usr/lib/locale/locale-archive
bash 18572 root mem REG 253,0 61624 249276 /usr/lib64/libnss_files-2.17.so
bash 18572 root mem REG 253,0 2151672 249258 /usr/lib64/libc-2.17.so
bash 18572 root mem REG 253,0 19288 249264 /usr/lib64/libdl-2.17.so
bash 18572 root mem REG 253,0 174576 258079 /usr/lib64/libtinfo.so.5.9
bash 18572 root mem REG 253,0 163400 249251 /usr/lib64/ld-2.17.so
bash 18572 root mem REG 253,0 26254 258035 /usr/lib64/gconv/gconv-modules.cache
bash 18572 root 0u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 1u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 2u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 255u CHR 136,0 0t0 3 /dev/pts/0
上面展示信息中每一列分别表示如下信息:
- COMMAND:命令
- PID:进程号
- USER:打开进程的用户
- FD:文件描述符
- TYPE:文件类型
- DEVICE:设备号
- SIZE/OFF:文件大小/偏移量
- NODE:文件的
Inode号 - NAME:文件名
抛开前三列,从第四列开始看:
cwd:
current work dir当前工作目录rtd: root根目录在哪儿
text:当前进程的解释程序文本
mem:当前进程占用的内存资源
然后下面就是0u、1u、2u三个文件描述符,u表示这个文件可以读也可以写。除了使用lsof可以看到这三个文件描述符。还可以通过下面方式来看这三个文件描述符:
[root@node01 pts]# cd /proc/$$/fd
[root@node01 fd]# ll
总用量 0
lrwx------. 1 root root 64 4月 19 16:25 0 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:25 1 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:25 2 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:29 255 -> /dev/pts/0
每一个进程都会有这三个文件描述符。这三个文件描述符对应的文件就是字符类型的:
[root@node01 fd]# cd /dev/pts/
[root@node01 pts]# ll -i
总用量 0
3 crw--w----. 1 root tty 136, 0 4月 19 16:51 0
因为文件描述符0、1、2最终都重定向到了/dev/pts/0这个文件,因此直接查看这个文件信息,可以看到Inode号为3,文件类型为c。字符型文件就代表着我们的输入输出设备。键盘,显示器等。
[root@node01 fd]# cd /home/zhaoshuai/
[root@node01 zhaoshuai]# touch test.txt
[root@node01 zhaoshuai]# vi test.txt
hjkjkhjbhgjhjkh
jhjkbjkkj
jkbjbjhbj
bjnbjhjbhj jh
jbjbhjjgjhbh
njbjhbhjhhghnk
jknjknk
jbjkkb
jbkb
jkbhjkbjh
jkbkjb
jkbkjbkjjk
jbkbjkbj
jkbkbknjk
手动创建一个文件,然后随表输入一些数据。使用当前进程读取这个文件内容:
[root@node01 zhaoshuai]# echo $$
18572
[root@node01 zhaoshuai]# exec 8< test.txt
创建一个名为8的文件描述符,用来读区test.txt的数据。
[root@node01 zhaoshuai]# lsof -p 18572
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 18572 root cwd DIR 253,0 75 16781483 /home/zhaoshuai
bash 18572 root rtd DIR 253,0 224 64 /
bash 18572 root txt REG 253,0 964608 50332791 /usr/bin/bash
bash 18572 root mem REG 253,0 106075056 258036 /usr/lib/locale/locale-archive
bash 18572 root mem REG 253,0 61624 249276 /usr/lib64/libnss_files-2.17.so
bash 18572 root mem REG 253,0 2151672 249258 /usr/lib64/libc-2.17.so
bash 18572 root mem REG 253,0 19288 249264 /usr/lib64/libdl-2.17.so
bash 18572 root mem REG 253,0 174576 258079 /usr/lib64/libtinfo.so.5.9
bash 18572 root mem REG 253,0 163400 249251 /usr/lib64/ld-2.17.so
bash 18572 root mem REG 253,0 123267 50332815 /usr/share/locale/zh_CN/LC_MESSAGES/bash.mo
bash 18572 root mem REG 253,0 26254 258035 /usr/lib64/gconv/gconv-modules.cache
bash 18572 root 0u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 1u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 2u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 8r REG 253,0 145 16781524 /home/zhaoshuai/test.txt
bash 18572 root 255u CHR 136,0 0t0 3 /dev/pts/0
[root@node01 zhaoshuai]# cd /proc/$$/fd
[root@node01 fd]# ll
总用量 0
lrwx------. 1 root root 64 4月 19 16:25 0 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:25 1 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:25 2 -> /dev/pts/0
lrwx------. 1 root root 64 4月 19 16:29 255 -> /dev/pts/0
lr-x------. 1 root root 64 4月 19 17:00 8 -> /home/zhaoshuai/test.txt
可以看到就有了一个8的文件描述符,描述符为8r,r表示读取,然后可以使用cat命令查看8的内容。
查看如下命令:
[root@node01 fd]# read a 0<& 8
read表示读取数据,然后赋给变量a,默认的文件描述符为0,重定向到8,也就是说读区8的内容赋给变量a。
[root@node01 fd]# lsof -p $$
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 18572 root cwd DIR 0,3 0 118863 /proc/18572/fd
bash 18572 root rtd DIR 253,0 224 64 /
bash 18572 root txt REG 253,0 964608 50332791 /usr/bin/bash
bash 18572 root mem REG 253,0 106075056 258036 /usr/lib/locale/locale-archive
bash 18572 root mem REG 253,0 61624 249276 /usr/lib64/libnss_files-2.17.so
bash 18572 root mem REG 253,0 2151672 249258 /usr/lib64/libc-2.17.so
bash 18572 root mem REG 253,0 19288 249264 /usr/lib64/libdl-2.17.so
bash 18572 root mem REG 253,0 174576 258079 /usr/lib64/libtinfo.so.5.9
bash 18572 root mem REG 253,0 163400 249251 /usr/lib64/ld-2.17.so
bash 18572 root mem REG 253,0 123267 50332815 /usr/share/locale/zh_CN/LC_MESSAGES/bash.mo
bash 18572 root mem REG 253,0 26254 258035 /usr/lib64/gconv/gconv-modules.cache
bash 18572 root 0u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 1u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 2u CHR 136,0 0t0 3 /dev/pts/0
bash 18572 root 8r REG 253,0 145 16781524 /home/zhaoshuai/test.txt
bash 18572 root 255u CHR 136,0 0t0 3 /dev/pts/0
可以看到8的偏移量到了145。
此时再次打开一个窗口,然后再执行exec 6< test.txt,会发现两个进程打开了文件test.txt,两个进程都有自己的文件描述符,每个文件描述符维护自己的偏移量。
重定向
重定向,不是命令,而是一种机制。
在linux中,每一个文件都有输入、输出和报错文件,分别是0、1、2。输入输出都是流的形式,使用>表示输出,<表示输入。ll命令也是一个进程,他也会有输入和输出。我们平时使用时:
[root@node01 zhaoshuai]# ll ./
总用量 5
---xr--r--. 1 root root 0 4月 15 13:41 aaa.txt
drwxr-xr-x. 2 root root 6 4月 15 14:28 dir
drwxr-xr-x. 2 root root 24 4月 20 09:54 image
drwxr-xr-x. 2 root root 21 4月 19 11:01 link
drwxr-xr-x. 2 root root 22 4月 19 11:34 pipline
drwxr-xr-x. 3 root root 1024 4月 20 09:56 test
-rw-r--r--. 1 root root 145 4月 19 16:55 test.txt
ll表示启动脚本的命令,./是参数。其实启动ll后会创建0、1、2三个文件,而且默认输出流1重定向到了当前窗口展示目录。可以通过手动指定输出重定向:
[root@node01 zhaoshuai]# ll ./ 1> ~/aaa.txt
[root@node01 zhaoshuai]#
这样页面就没有输出了,因为bash再解释执行时,会发现ll表示命令,./是参数,而后面bash看到1>就会拦截,表示输出重定向到:~/aaa.txt,这样输出就被写入了文件中,查看文件:
[root@node01 zhaoshuai]# cd
[root@node01 ~]# cat aaa.txt
总用量 5
---xr--r--. 1 root root 0 4月 15 13:41 aaa.txt
drwxr-xr-x. 2 root root 6 4月 15 14:28 dir
drwxr-xr-x. 2 root root 24 4月 20 09:54 image
drwxr-xr-x. 2 root root 21 4月 19 11:01 link
drwxr-xr-x. 2 root root 22 4月 19 11:34 pipline
drwxr-xr-x. 3 root root 1024 4月 20 09:56 test
-rw-r--r--. 1 root root 145 4月 19 16:55 test.txt
可以看到ll的输出信息。
重定向操作符
>和文件描述符之间不能有空格,文件描述符必须紧跟着重定向操作符。如:0<,1>。如果有空格,会认为0这个文件描述符是前面命令的参数。如果右边是一个文件描述符,那么需要加一个&,如:
1> aaa.txt 2>& 1
1.4 pageCache
pagecache是kernel中的一个折中方案。
可以没有pagecache,如果没有pagecache的话,那么如果应用想要访问文件的话,应用程序只需要调用kernel,然后kernel访问磁盘,拿到数据后直接返回就结束了,但是磁盘是比较慢的,为了提升效率所以加了pagecache这一层缓存。
就像我们使用java读文件时会使用bytebuffer提升效率一样,kernel中会使用pagecache来提升效率。
当我们的应用程序需要向文件写数据时,一般会经过如下流程:
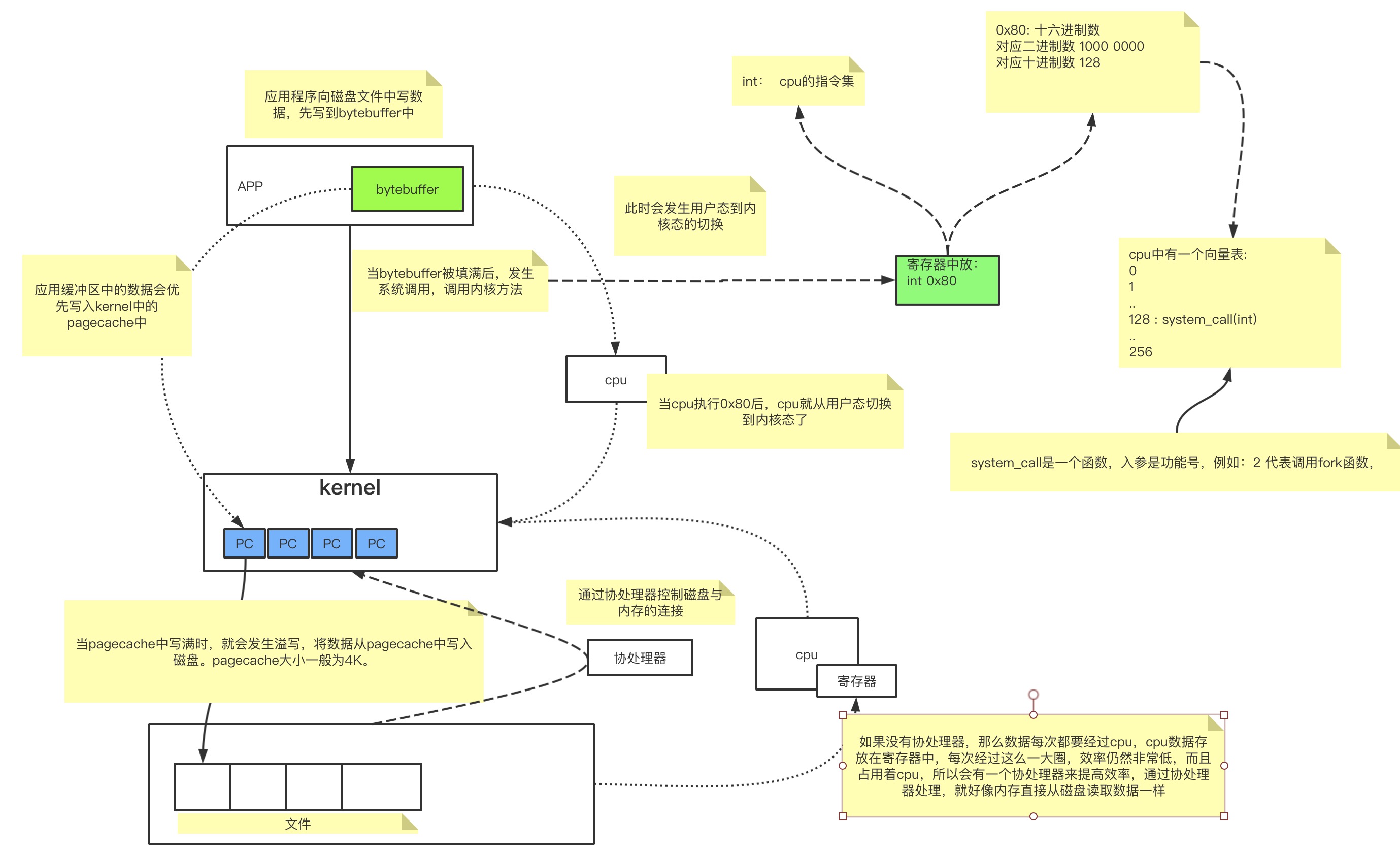
每一个pagecache就对应着磁盘文件的4K的内容,因此如果需要从磁盘中读取数据时也是一样的流程:
- 应用程序调用读文件的方法。
- 进行系统调用,用户态切换到内核态。
- 从pagecache中读数据。当pagecache中没有这一页数据时,就会抛出缺页异常,然后操作系统从磁盘文件中加载数据到pagecache中,然后在将数据返回给应用程序。
缺页异常
在linux系统中,文件存放在磁盘中,是按照块存储的。一块大约4K。当创建一个文件时,就会为这个文件分配一个Inode对象,这个Inode中存放的就是这个文件的块地址映射信息。因此创建一个空的文件时,也会占用4K的大小,1个块,当这个块填满时,如果追加内容,那么则会重新开辟一个块来存储。
当应用程序从文件中读数据时,因为内存大小是有限的,需要给很多应用提供服务,因此不可能把所有的空间都用来存放加载的文件数据。因此内存中使用pagecache来缓存磁盘中加载的数据,每一个pagecache对应磁盘中的一个块,同时内存中维护一张表来存放已经加载的块。在内存中pagecache是不连续的。
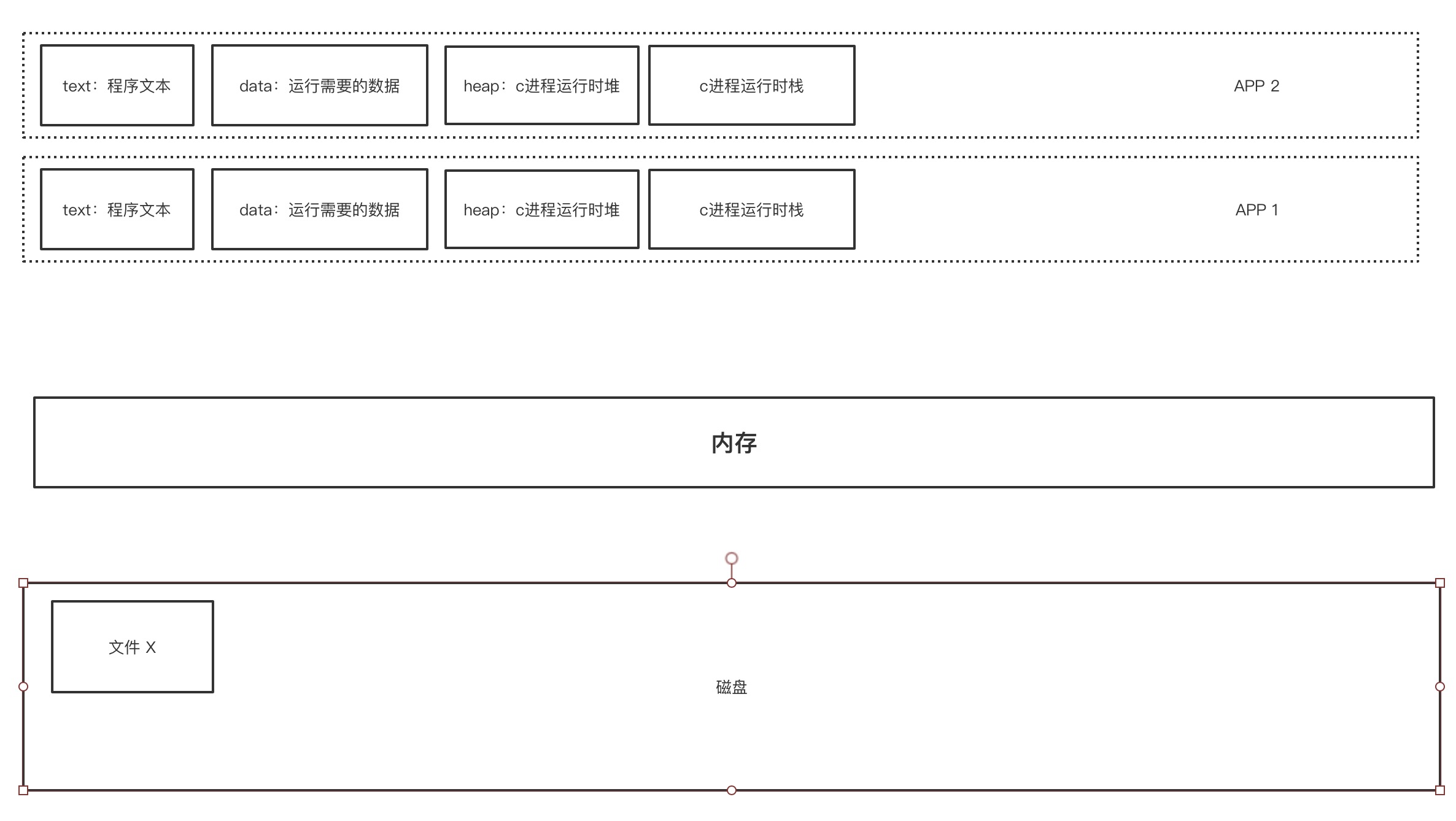
看上图,应用程序默认是整个内存空间都是属于自己可用的。但是实际使用中,一般都是运行多个进程,多个进程共享一个内存空间。如果应用程序直接使用物理内存的话,那么就会发生如下问题:
- 多个进程抢占同一块内存空间。
- 多个进程内数据分配地址不连续,寻址慢。
- 因为直接访问物理内存,那么进程之间可以访问到其他进程的数据,这是不安全的。
为了解决上面的问题,所以抽象出了虚拟内存这一层概念。
每一个进程都有一个自己的虚拟内存空间,这个虚拟内存空间只有自己可以使用,这样就实现了进程间资源的隔离,同时也避免了多个进程抢占同一块内存空间。而且整个虚拟内存只有自己可用,那么数据在分配内存地址时,内存地址是连续的,提升了效率。
而虚拟内存中的地址,会映射到一个实际的物理内存地址。
那么当两个进程同时需要操作一个文件时,因为进程间内存不可互相访问,因此,这个磁盘中的文件内容就会被加载到内存中两次。
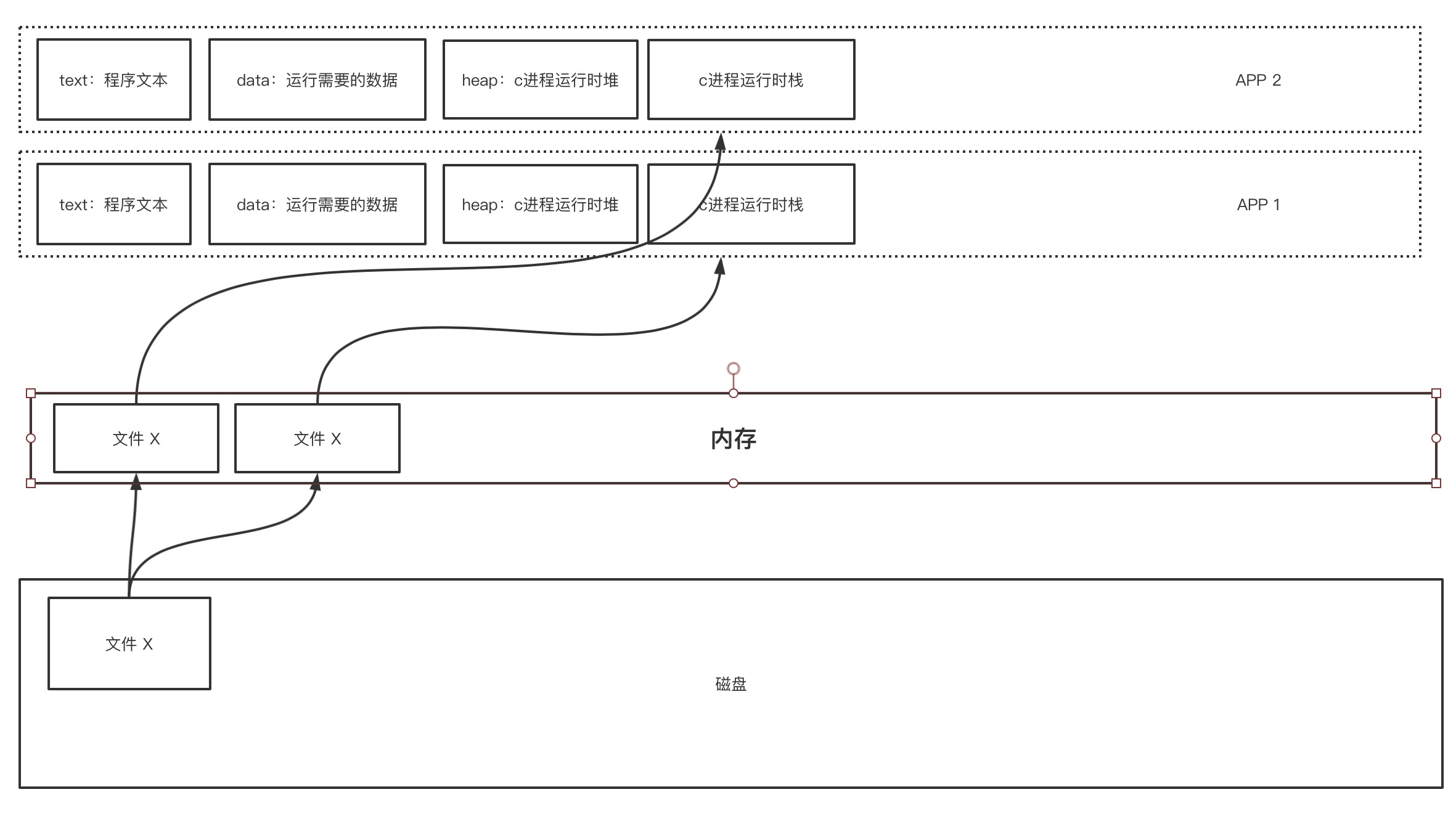
这样就会造成内存的浪费,同时可能两个进程只需要读取文件的一小部分数据,而加载整个文件到内存中,如果文件非常大的话,就会造成内存空间不够的问题。为了解决上面的问题,因此出现了pagecache。
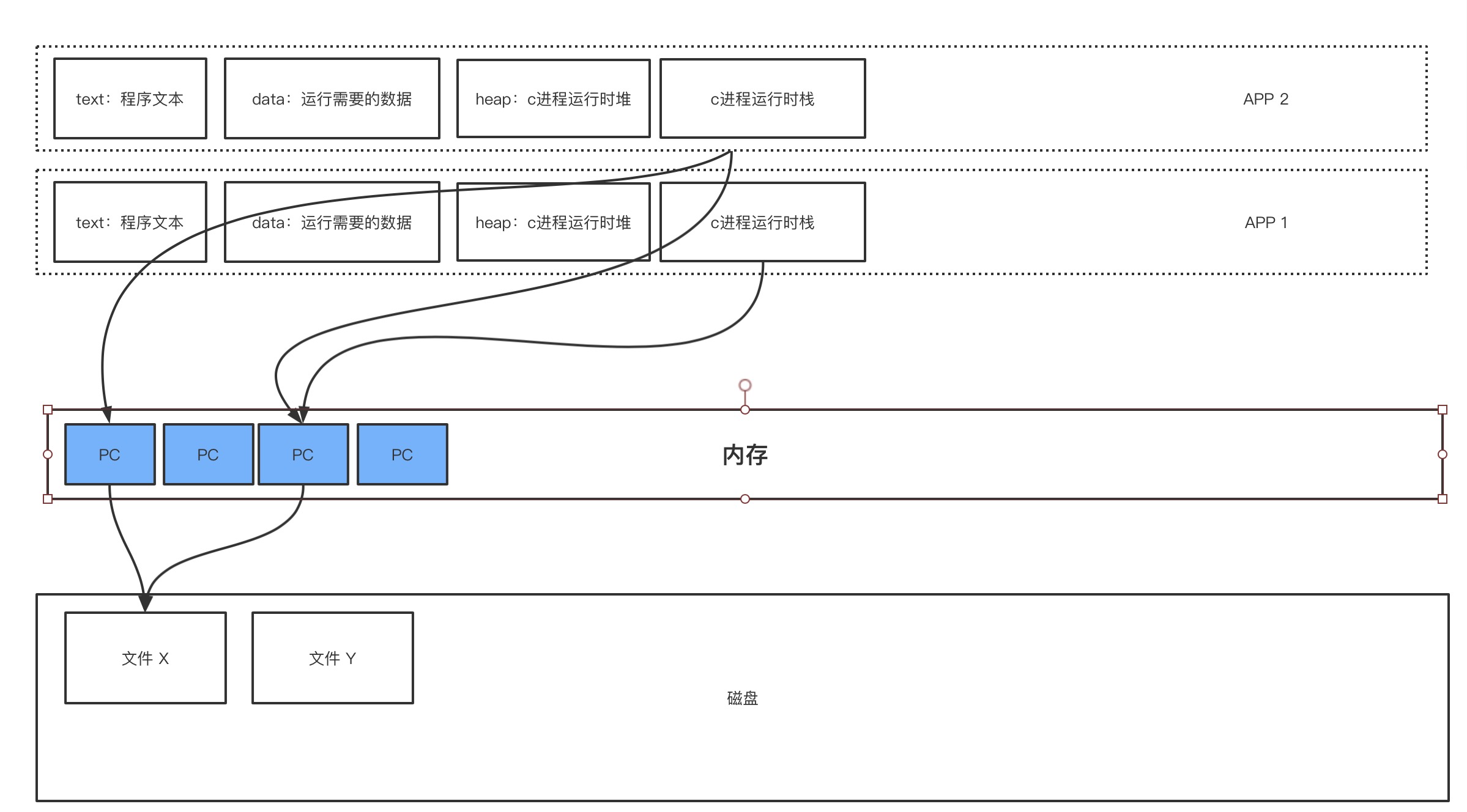
当两个进程都需要访问文件X时,其实内存中会维护一个pagecache的表,表示缓存的文件块范围。如果当前没有缓存要访问的内容,那么就会发生缺页异常,中断,从用户态切换到内核态。然后读取数据到pagecache中,然后返回给应用程序。多个进程访问同一块pagecache时,各自会有一个fd文件。
dirty脏页
文件会优先加载到pagecache中,只要内存还够用,那么就会一直加载。使用脚本pcstat查看文件的pagecache缓存状态。
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author 赵帅
* @date 2021/4/20
*/
public class OSFileIO {
private static final String PATH = "/root/testfileio/output.txt";
private static final byte[] CONTENT = "123456789\n".getBytes();
public static void main(String[] args) throws Exception {
String operation = args[0];
switch (operation) {
case "0":
basicFileIO();
break;
case "1":
bufferFIleIO();
break;
case "2":
randomAccessFileIO();
break;
case "3":
byteBuffer();
break;
default:
break;
}
}
private static void basicFileIO() throws Exception {
File file = new File(PATH);
FileOutputStream os = new FileOutputStream(file);
while (true) {
os.write(CONTENT);
}
}
private static void bufferFIleIO() throws Exception {
File file = new File(PATH);
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file));
while (true) {
bos.write(CONTENT);
}
}
private static void randomAccessFileIO() throws Exception{
RandomAccessFile raf = new RandomAccessFile(PATH, "rw");
raf.write("hello world".getBytes());
raf.write("hello java".getBytes());
System.out.println("write ok........................");
// 阻塞
System.in.read();
raf.seek(4);
raf.write("ooxx".getBytes());
System.out.println("seek finished.....................");
System.in.read();
FileChannel rafchannel = raf.getChannel();
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
map.put("@@@".getBytes());
System.out.println("map--put--------");
}
private static void byteBuffer() {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
}
准备上面的java文件,将这个文件运行在linux中,编辑启动脚本:
#!/bin/bash
# author: 赵帅
if [ $# -lt 1 ];
then
printf "Usage ./start.sh {0|1|2}\n"
exit
fi
operation=$1
rm -rf ./out.*
file_name='OSFileIO'
class_file="${file_name}.class"
if test ! -e $class_file ; then
javac ${file_name}.java
fi
strace -ff -o out /root/jdk1.8.0_221/bin/java $file_name $operation
执行启动脚本,并新开一个窗口不断执行ll -h&& ./pcstat output.txt。
可以看到pagecache缓存页数在不停的增加。
但是内存是有限的,当没有可用内存用来新增pagecache时,就要清理掉一部分pagecache用来增加新的pagecache。该清理掉哪儿写部分呢?这时就有一个dirty脏页的概念。
什么是脏页?
当应用程序向文件中写数据时,优先写在pagecache中,只要pagecache中的数据被修改了,而且修改的内容还没有被刷写到磁盘中,那么这一页pagecache就会被操作系统标记为dirty脏页。脏页中的数据什么时候写入磁盘?
[root@node01 testfileio]# sysctl -a |grep dirty
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens33.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
# 控制脏页内存数量,超过dirty_background_bytes时,内核的flush线程开始回写脏页
vm.dirty_background_bytes = 0
# 控制脏页占可用内存(空闲+可回收)的百分比,达到dirty_background_ratio时,内核的flush线程开始回写脏页。默认值: 10
vm.dirty_background_ratio = 10
# 控制脏页内存数量,达到dirty_bytes时,执行磁盘写操作的进程开始回写脏页
vm.dirty_bytes = 0
# 控制脏页所占可用内存百分比,达到dirty_ratio时,执行磁盘写操作的进程自己开始回写脏数据。默认值:20
vm.dirty_ratio = 30
# 这个值表示page cache中的数据多久之后被标记为脏数据。只有标记为脏的数据在下一个周期到来时pdflush才会刷入到磁盘,这样就意味着用户写的数据在30秒之后才有可能被刷入磁盘,在这期间断电都是会丢数据的。
vm.dirty_expire_centisecs = 3000
# 5s的时间内核flush线程就会被唤起去刷新脏数据
vm.dirty_writeback_centisecs = 500
可以通过以上参数控制脏页的刷写。
vm.dirty_background_bytes和vm.dirty_background_ratio这两个参数只能指定一个,先设定的先生效,另一个会被清零。
vm.dirty_bytes和vm.dirty_ratio也是只能设置一个。
可以将上面配置写入/etc/sysctl.conf文件中。
从上面参数可以看出,dirty的刷写是由阈值或者指定大小控制的,在页面上看到的写入的数据并不一定被写入了磁盘。加了一层pagecache本来是为了提高IO效率,但是响应的就会带来一个丢数据的风险。
pagecache就是一个4K大小的内存空间,linux内核中会为每一个pagecache维护一个索引,dirty标记就是在索引中
butebuffer
首先了解为什么bufferedIO比普通的IO快。
执行./start.sh 0,等几秒钟后停止:
[root@node01 testfileio]# ./start.sh 0
^C[root@node01 testfileio]# ll
总用量 3032
-rw-r--r--. 1 root root 1922 4月 21 09:51 OSFileIO.class
-rw-r--r--. 1 root root 1563 4月 21 09:50 OSFileIO.java
-rw-r--r--. 1 root root 9909 4月 21 17:17 out.7466
-rw-r--r--. 1 root root 261066 4月 21 17:17 out.7467
-rw-r--r--. 1 root root 2710 4月 21 17:17 out.7468
-rw-r--r--. 1 root root 1255 4月 21 17:17 out.7469
-rw-r--r--. 1 root root 1084 4月 21 17:17 out.7470
-rw-r--r--. 1 root root 2121 4月 21 17:17 out.7471
-rw-r--r--. 1 root root 5660 4月 21 17:17 out.7472
-rw-r--r--. 1 root root 3295 4月 21 17:17 out.7473
-rw-r--r--. 1 root root 960 4月 21 17:17 out.7474
-rw-r--r--. 1 root root 15397 4月 21 17:17 out.7475
-rw-r--r--. 1 root root 1832 4月 21 17:17 out.7476
-rw-r--r--. 1 root root 3770 4月 21 17:17 output.txt
-rwxr-xr-x. 1 root root 2759061 4月 20 14:01 pcstat
-rwxr-xr-x. 1 root root 312 4月 20 18:55 start.sh
[root@node01 testfileio]# jps -l
7478 sun.tools.jps.Jps
[root@node01 testfileio]#
最大的out文件就是主线程的文件,打开out.7467,搜索123456789\n可以看到如下内容:
................
write(4, "123456789\n", 10) = 10
write(4, "123456789\n", 10) = 10
write(4, "123456789\n", 10) = 10
write(4, "123456789\n", 10) = 10
write(4, "123456789\n", 10) = 10
write(4, "123456789\n", 10) = 10
..........
会看到非常多的write(4, "123456789\n", 10) = 10,每一个write调用都是一次系统调用,都会产生用户态和内核态的切换,而每次都只写了8个字节的数据。
再执行./start.sh 1,重复上面操作,可以看到如下内容:
..............
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
write(4, "123456789\n123456789\n123456789\n12"..., 8190) = 8190
...........
可以看到调用bufferedIO后,每次调用write方法时,写入的数据为8KB,相比一般IO每次系统调用只写8字节相比。BufferedIO减少了非常多的用户态和内核态的切换过程。所以bufferedIO比一般IO更快。
上面都是阻塞式IO,即传统的BIO(java.io.*),现在java有了nio(java.nio.*),下面尝试使用nio来操作文件。首先了解byteBuffer类,查看OSFileIO的byteBuffer方法:
private static void byteBuffer() {
// 创建一个堆内内存的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 创建一个堆外内存的缓冲区
//ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("abc".getBytes());
System.out.println("-------------put:abc......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
首先查看ByteBuffer内的属性,执行System.out.println("mark:" + buffer)后输出如下:
mark: java.nio.HeapByteBuffer[pos=0 lim=1024 cap=1024]
有三个属性:
postition: 可以理解为头指针limit: 尾指针capacity:容量
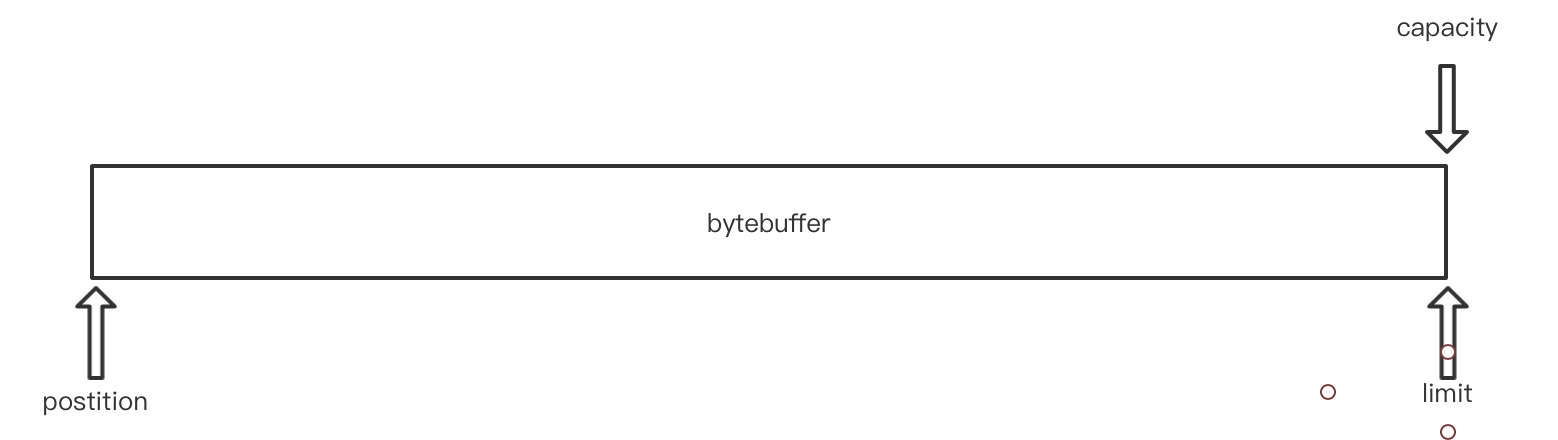
刚初始化时,bytebuffer内部就长着个样子。当调用put方法存入字节数时buffer.put("123".getBytes());
mark: java.nio.HeapByteBuffer[pos=3 lim=1024 cap=1024]
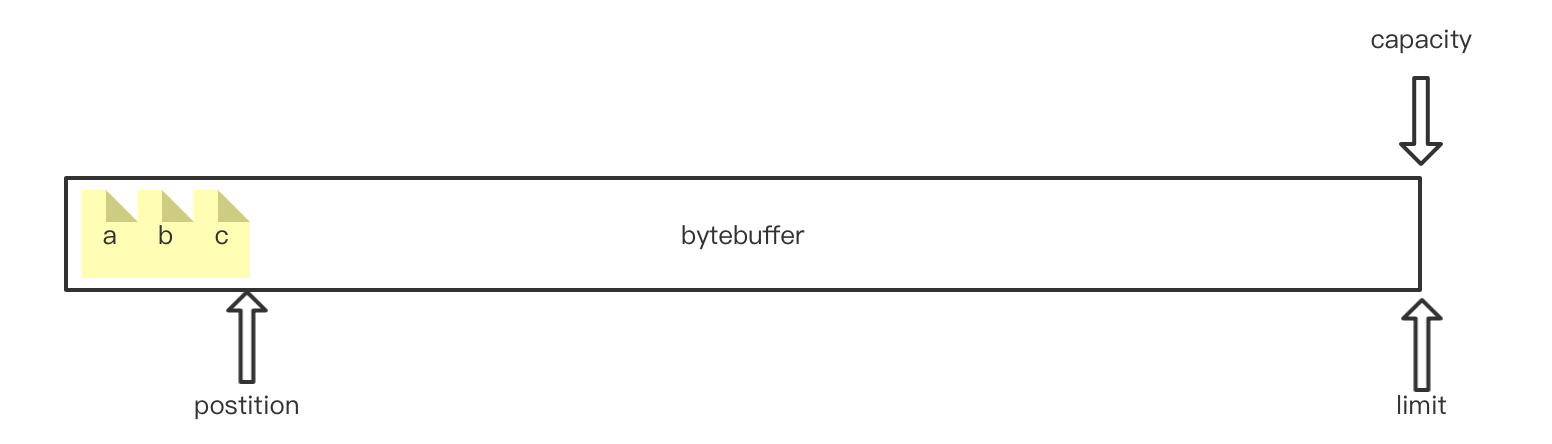
每放一个字节,postition指针右移一位。当postition与limit重合时表示缓冲区满了。
当需要从缓冲区读数据时,需要先调用buffer.flip();进行翻转。翻转后的指针状态为:
mark: java.nio.HeapByteBuffer[pos=0 lim=3 cap=1024]
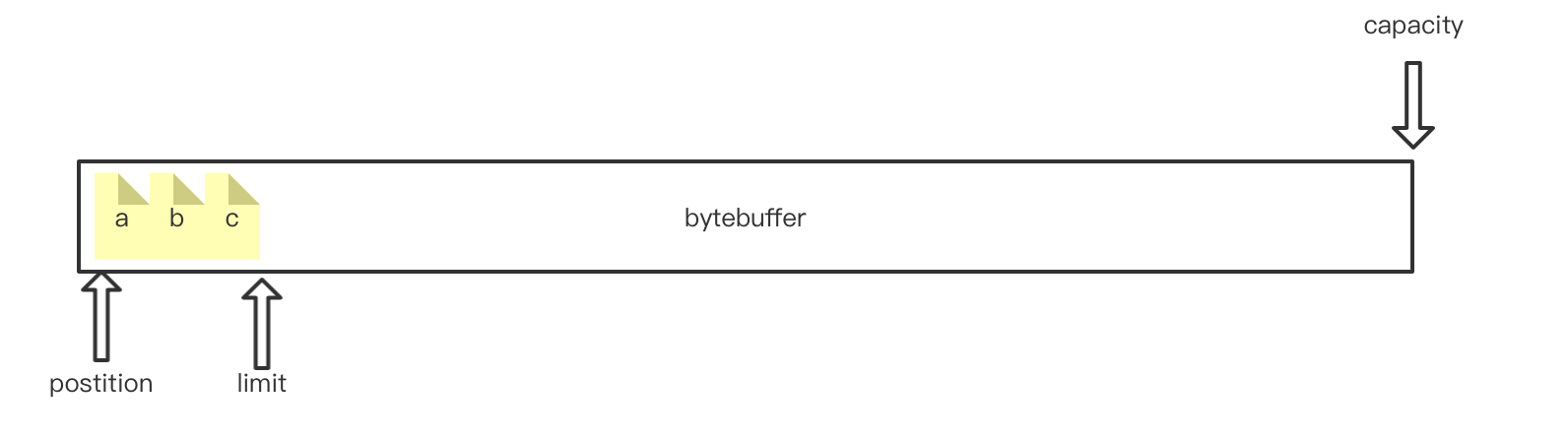
postition表示下一个可读的字节位置,limit表示最后一个可读的字节位置。每调用一次get方法,postition就会右移一位。
compact: 压缩缓冲区,当在上面的基础上取出第一个字节后,postition就会移动到b所在下标,那么此时如果要继续写数据的话,第一个字节位置就空出来了,可以调用compact方法压缩空间,调用后内部结构如下:
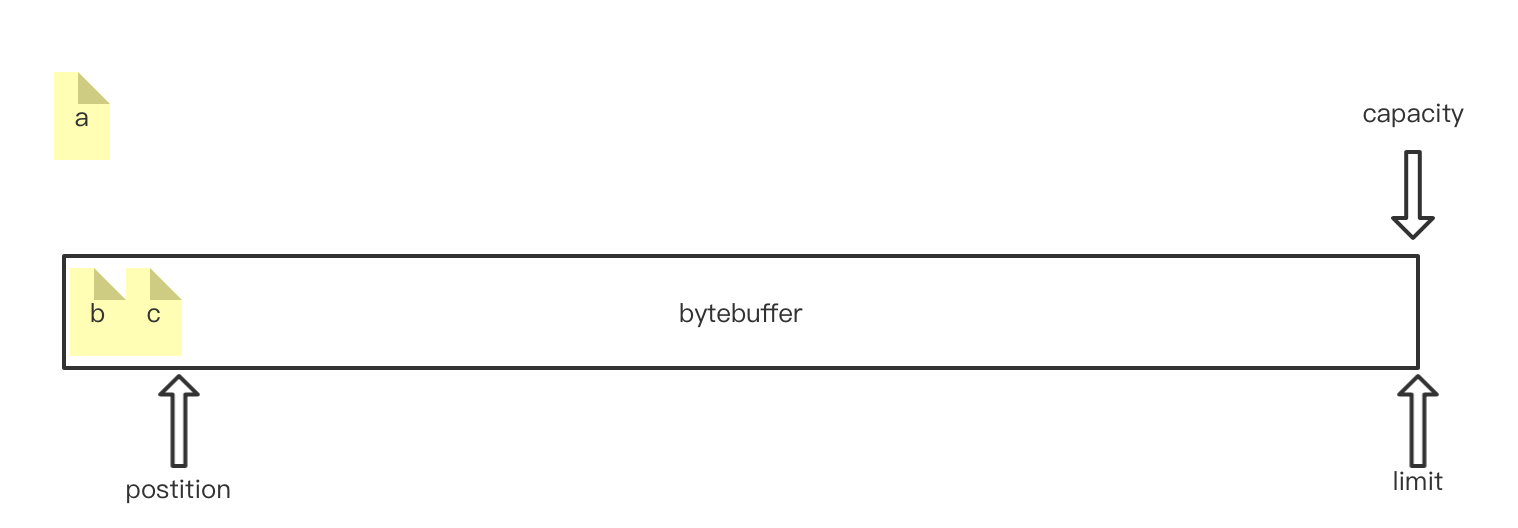
调用压缩方法后,就可以继续写入数据了。
mmap
在pagecache中写到每个进程都会分配一个Heap堆,这个堆事C语言的堆,也就是为这个进程分配的堆。那么在运行java应用程序时。这个堆也就是为java这个进程分配的堆。但是java的运行是多线程的。会有一个jvm的守护线程。这个线程也会有一个堆,java程序的对象都存放在这个堆中。那么关系图就是下面这样:
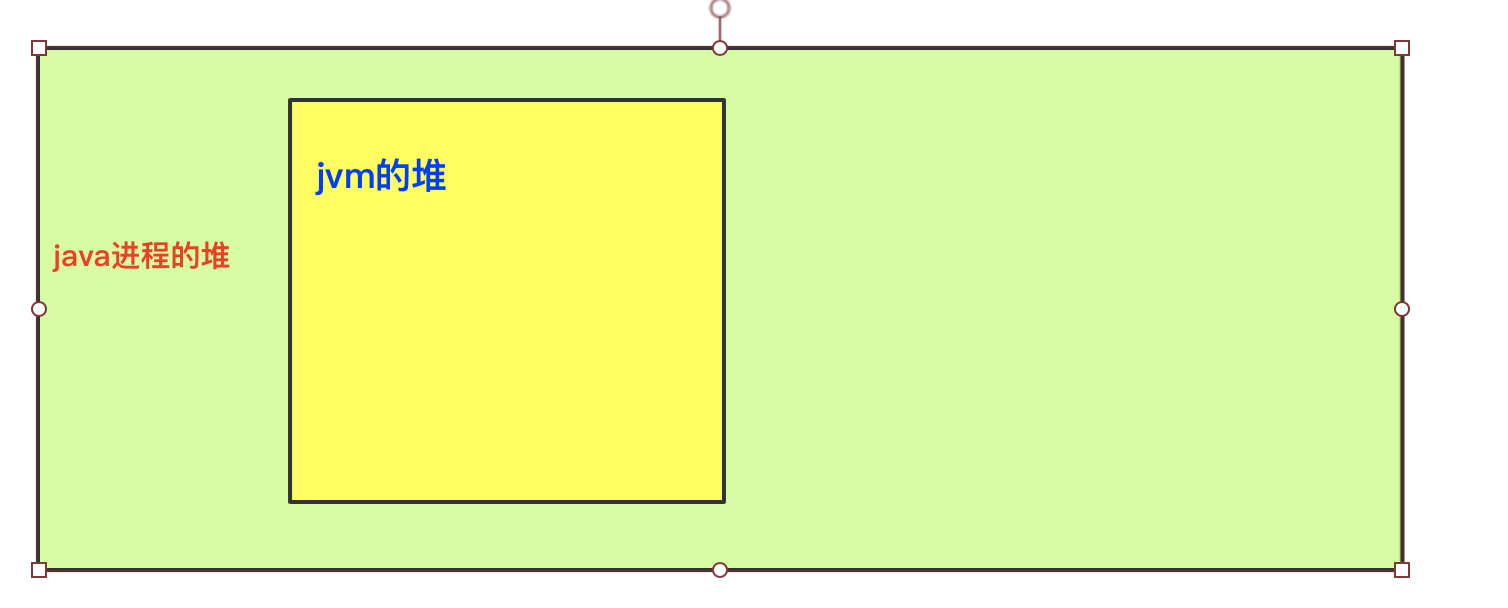
前面说了进程写入文件的所有数据最终都写入了pagecache中,那么当java进程想要将数据写入文件时,会有这么一个过程:
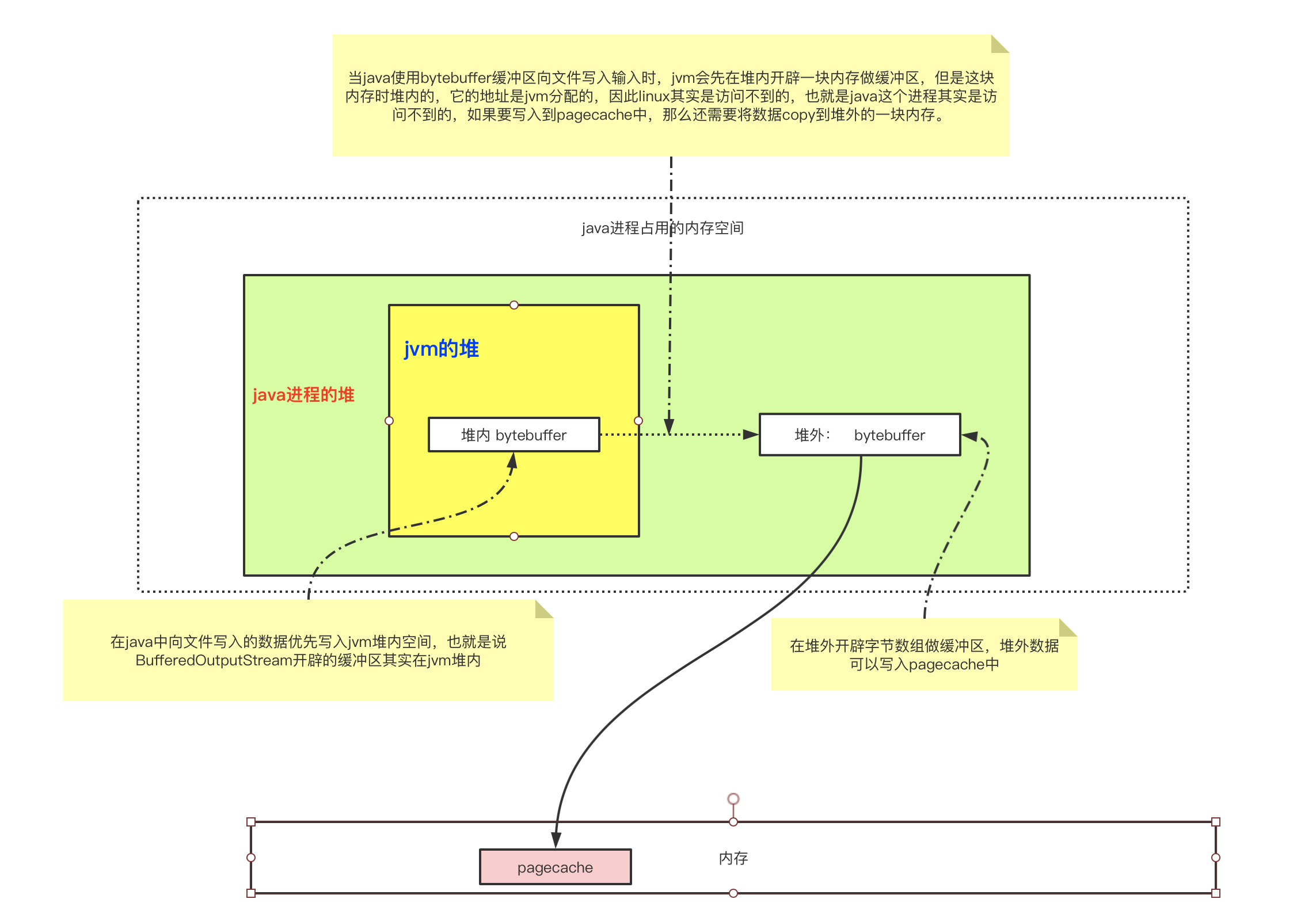
如果写在堆内,就会经过一个堆内数据向堆外数据的拷贝过程,因此堆外比堆内的效率更高。
在文件IO中,还有一种性能更高的方案 mmap。直接写入堆外内存,可以减少一次copy的过程,但是从堆外内存写入pagecache中,仍然存在用户态到内核态的切换,使用mmap就可以在不切换内核态的情况下,在用户态直接将数据写入pagecache中。
什么是mmap
只有文件IO才会有mmap,mmap是通过在应用程序的虚拟地址空间创建一个映射,直接映射到内存的一块pagecache中。这样应用程序写的数据可以直接送到pagecache中,避免了系统调用。
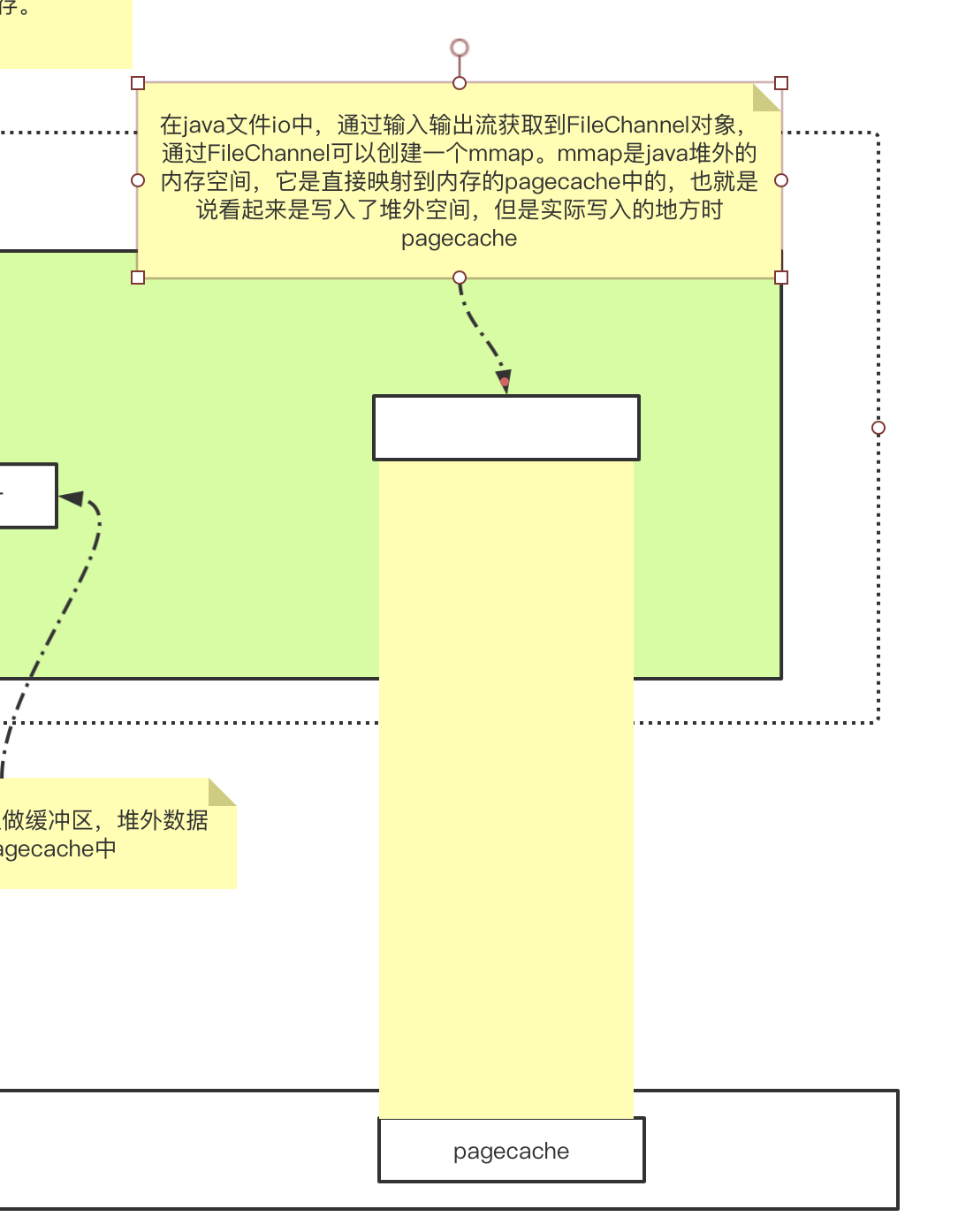
mmap虽然可以直接映射到pagechche中,不需要状态的切换,但是在pagecache将数据刷写到磁盘时,仍然还是需要切换到内核态的,而且使用mmap仍然存在pagecache可能丢数据的缺点。
mmap使用方式:
// 输入输出流获取fileChannel
FileInputStream fis = new FileInputStream();
FileChannel fc = fis.getChannel();
// fc获取mmap
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
二、 Socket编程
常见的IO模型主要有以下分类:
- 同步/异步
- 阻塞/非阻塞
这两个可以互相组合,如同步阻塞模型/同步非阻塞模型,但是没有异步阻塞模型。windows实现了异步模型,但是linux并没有实现,因此linux中的IO都是同步模型的。
2.1 BIO
BIO--即`BlockingIO,也叫同步阻塞IO。BIO的代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/1
*/
public class SocketBIO {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(9000);
System.out.println("step1: new ServerSocket(9000)");
while (true) {
Socket client = serverSocket.accept();
System.out.println("client :" + client.getPort() + " is in");
new Thread(new Runnable() {
public Socket client;
public Runnable setClient(Socket client) {
this.client = client;
return this;
}
public void run() {
InputStream in = null;
try {
in = this.client.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(in));
while (true) {
String str = br.readLine();
if (str != null && !"".equals(str)) {
System.out.println("str = " + str);
} else {
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}.setClient(client)).start();
}
}
}
这就是一个最简单的BIO服务端,当服务启动后,使用nc localhost 9000连接当前服务端。
zhaoshuai:io-study 乄 nc localhost 9000
可以在控制台看到如下输出:
client :52706 is in
然后在终端随便输入内容,可以在控制台看到相应的输出。
但是BIO的弊端就是它是阻塞的:
- 服务端在调用
serverSocket.accept()方法时是阻塞的。 - 服务端为每一个客户端连接开启一个线程,客户端在调用
br.readLine()读取数据时,也是阻塞的。
阻塞点验证
以下内容中可能会出现进程id变化的情况,是因为多次启动进程的情况,文章不是一口气写完的,自行替换pid
通过strace方法可以看到详细的进程启动的服务调用,我们使用strace启动上面的java进程:
- 将上面的代码复制到linux服务器中:
touch SocketBIO.java
vi SocketBIO.java
# 复制粘贴上面的代码,保存退出
编译代码
/root/jdk/j2sdk1.4.2_18/bin/javac SocketBIO.java
使用strace命令启动追踪java进程
strace -ff -o out /root/jdk/j2sdk1.4.2_18/bin/java SocketBIO
启动成功后另起一个shell连接可以看到如下目录:
[root@node01 jdk4]# ll
总用量 688
-rw-r--r--. 1 root root 164417 6月 7 14:00 out.12509
-rw-r--r--. 1 root root 9973 6月 7 14:01 out.12510
-rw-r--r--. 1 root root 1329 6月 7 14:00 out.12511
-rw-r--r--. 1 root root 1324 6月 7 14:00 out.12512
-rw-r--r--. 1 root root 1068 6月 7 14:00 out.12513
-rw-r--r--. 1 root root 1301 6月 7 14:00 out.12514
-rw-r--r--. 1 root root 10366 6月 7 14:00 out.12515
-rw-r--r--. 1 root root 207460 6月 7 14:01 out.12516
-rw-r--r--. 1 root root 1112 6月 7 13:56 SocketBIO.class
-rw-r--r--. 1 root root 1867 6月 7 13:55 SocketBIO.java
使用strace追踪命令,会为进程中的每一个线程都创建一个out.pid的文件,记录此线程的系统调用
此时执行netstat -natp|grep 9000查看socket的端口状态
[root@node01 jdk4]# netstat -natp |grep 9000
tcp6 0 0 :::9000 :::* LISTEN 12509/java
可以看到如上内容,12509进程开启了9000端口,处理LISTEN状态,也就是操作系统此时正在监听9000端口。
然后查看less out.12509也就是主线程的系统调用:
.........
socket(AF_INET6, SOCK_STREAM, IPPROTO_IP) = 3
setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
bind(3, {sa_family=AF_INET6, sin6_port=htons(9000), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0)}, 24) = 0
listen(3, 50) = 0
write(1, "step1: new ServerSocket(9000)", 29) = 29
write(1, "\n", 1) = 1
gettimeofday({tv_sec=1623045647, tv_usec=115119}, NULL) = 0
gettimeofday({tv_sec=1623045647, tv_usec=115292}, NULL) = 0
gettimeofday({tv_sec=1623045647, tv_usec=115330}, NULL) = 0
gettimeofday({tv_sec=1623045647, tv_usec=115493}, NULL) = 0
gettimeofday({tv_sec=1623045647, tv_usec=115525}, NULL) = 0
gettimeofday({tv_sec=1623045647, tv_usec=115642}, NULL) = 0
accept(3,
可以看到如上内容:
首先通过
socket(AF_INET6, SOCK_STREAM, IPPROTO_IP) = 3创建了一个套接字,返回一个3的文件描述符。可以通过
lsof -p 12509来查看进程打开的文件描述符:[root@node01 jdk4]# lsof -p 12509
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
......
java 12509 root mem REG 253,0 2107692 16791640 /usr/lib/libc-2.17.so
java 12509 root mem REG 253,0 17716 17503682 /usr/lib/libdl-2.17.so
java 12509 root mem REG 253,0 133736 17503701 /usr/lib/libpthread-2.17.so
java 12509 root mem REG 253,0 16384 50792961 /tmp/hsperfdata_root/12509
java 12509 root mem REG 253,0 158768 16791632 /usr/lib/ld-2.17.so
java 12509 root 0u CHR 136,2 0t0 5 /dev/pts/2
java 12509 root 1u CHR 136,2 0t0 5 /dev/pts/2
java 12509 root 2u CHR 136,2 0t0 5 /dev/pts/2
java 12509 root 3u IPv6 210892 0t0 TCP *:cslistener (LISTEN)
java 12509 root 4u sock 0,7 0t0 210890 protocol: TCPv6
可以看到文件描述符3是一个TCP连接。
然后通过
bind()函数将文件描述符3和9000端口进行绑定。listne(3, 50)监听文件描述符3。accetp(3,阻塞等待客户端连接。
然后在本地通过nc命令创建一个客户端连接(java代码写客户端也可以, 懒省事用nc)。
[root@node01 jdk4]# nc localhost 9000
然后新开一个窗口再次执行netstat -natp |grep 9000
tcp6 0 0 :::9000 :::* LISTEN 12784/java
tcp6 0 0 ::1:9000 ::1:44612 ESTABLISHED 12784/java
tcp6 0 0 ::1:44612 ::1:9000 ESTABLISHED 12792/nc
可以看到,本地创建打开了一个端口44612用于与9000建立一个TCP连接,然后在查看主线程的out文件:
accept(3, {sa_family=AF_INET6, sin6_port=htons(44612), inet_pton(AF_INET6, "::1", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, [28]) = 5
gettimeofday({tv_sec=1623051290, tv_usec=728682}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=728721}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=728750}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=728822}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=728851}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=729000}, NULL) = 0
write(1, "client \357\274\23244612 is in", 21) = 21
write(1, "\n", 1) = 1
gettimeofday({tv_sec=1623051290, tv_usec=729976}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=730028}, NULL) = 0
stat64("/root/io-study/bio/jdk4/SocketBIO$1.class", {st_mode=S_IFREG|0644, st_size=1400, ...}) = 0
open("/root/io-study/bio/jdk4/SocketBIO$1.class", O_RDONLY|O_LARGEFILE) = 6
fstat64(6, {st_mode=S_IFREG|0644, st_size=1400, ...}) = 0
stat64("/root/io-study/bio/jdk4/SocketBIO$1.class", {st_mode=S_IFREG|0644, st_size=1400, ...}) = 0
read(6, "\312\376\272\276\0\0\0.\0U\n\0\26\0#\t\0\25\0$\n\0%\0&\7\0'\7\0(\n"..., 1400) = 1400
close(6) = 0
gettimeofday({tv_sec=1623051290, tv_usec=730648}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=730716}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=730747}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=730846}, NULL) = 0
mmap2(NULL, 528384, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0xea915000
mprotect(0xea915000, 4096, PROT_NONE) = 0
clone(child_stack=0xea995424, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0xea995ba8, tls={entry_number=12, base_addr=0xea995b40, limit=0x0fffff, seg_32bit=1, contents=0, read_exec_only=0, limit_in_pages=1, seg_not_present=0, useable=1}, child_tidptr=0xea995ba8) = 12793
futex(0x86d9d34, FUTEX_WAIT_PRIVATE, 1, NULL) = 0
futex(0x86d9be4, FUTEX_WAIT_PRIVATE, 2, NULL) = 0
futex(0x86d9be4, FUTEX_WAKE_PRIVATE, 1) = 0
sched_setscheduler(12793, SCHED_OTHER, [5]) = -1 EINVAL (无效的参数)
accept(3,
从第一行可以看到
accetp()函数,接收了一个客户端,返回了一个文件描述符5,这个文件描述符5就是客户端与服务端之间一个点对点的通道,可以通过lsof -p 12784查看:[root@node01 jdk4]# lsof -p 12784
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
.....
java 12784 root mem REG 253,0 158768 16791632 /usr/lib/ld-2.17.so
java 12784 root 0u CHR 136,2 0t0 5 /dev/pts/2
java 12784 root 1u CHR 136,2 0t0 5 /dev/pts/2
java 12784 root 2u CHR 136,2 0t0 5 /dev/pts/2
java 12784 root 3u IPv6 219987 0t0 TCP *:cslistener (LISTEN)
java 12784 root 4u sock 0,7 0t0 219985 protocol: TCPv6
java 12784 root 5u IPv6 219988 0t0 TCP localhost:cslistener->localhost:44612 (ESTABLISHED)
在下面通过
clone()函数为客户端创建了一个新线程。返回的12793也就是客户端子线程的线程id。然后ll查看out.12793文件。...........
mprotect(0xea924000, 12288, PROT_NONE) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732258}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732293}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732320}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732361}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732390}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732432}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732494}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732527}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732554}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732610}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732638}, NULL) = 0
gettimeofday({tv_sec=1623051290, tv_usec=732691}, NULL) = 0
recv(5,
可以看到系统调用
recv(5,阻塞等待接受客户端数据。然后再次在
accept()处阻塞。
通过上面代码就可以了解BIO的整个系统调用流程,了解整体阻塞点。
注意
在jdk1.7以前,主线程是第一个线程,也就是进程号就是主线程。但是在jdk1.7以后主线程是第二个线程。因此查看系统调用时要看第二个(大小最大的文件)。
[root@node01 jdk8]# ll
总用量 260
-rw-r--r--. 1 root root 9724 6月 7 17:42 out.12931
-rw-r--r--. 1 root root 181394 6月 7 17:43 out.12932
-rw-r--r--. 1 root root 1573 6月 7 17:43 out.12933
-rw-r--r--. 1 root root 931 6月 7 17:43 out.12934
-rw-r--r--. 1 root root 1055 6月 7 17:43 out.12935
-rw-r--r--. 1 root root 975 6月 7 17:43 out.12936
-rw-r--r--. 1 root root 4740 6月 7 17:43 out.12937
-rw-r--r--. 1 root root 3747 6月 7 17:43 out.12938
-rw-r--r--. 1 root root 931 6月 7 17:43 out.12939
-rw-r--r--. 1 root root 12938 6月 7 17:43 out.12940
-rw-r--r--. 1 root root 1641 6月 7 10:12 SocketBIO$1.class
-rw-r--r--. 1 root root 1153 6月 7 10:12 SocketBIO.class
在1.4中是通过
accept()阻塞接受客户端的,在jdk1.7之后是通过poll函数,仍然是阻塞的:bind(5, {sa_family=AF_INET6, sin6_port=htons(9000), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0
listen(5, 50) = 0
mprotect(0x7f9acc0d3000, 4096, PROT_READ|PROT_WRITE) = 0
write(1, "step1: new ServerSocket(9000)", 29) = 29
write(1, "\n", 1) = 1
lseek(3, 58905332, SEEK_SET) = 58905332
read(3, "PK\3\4\n\0\0\10\0\0\240#\344Ny\271LV\2416\0\0\2416\0\0\25\0\0\0", 30) = 30
lseek(3, 58905383, SEEK_SET) = 58905383
read(3, "\312\376\272\276\0\0\0004\1\345\n\0\6\1\27\t\0\233\1\30\t\0\233\1\31\t\0\233\1\32\t\0"..., 13985) = 13985
poll([{fd=5, events=POLLIN|POLLERR}], 1, -1
C10K问题
上面写了BIO模型的实现以及细节。由于BIO的缺陷,引起一个C10K的问题,即10000个客户端。
上面的BIO的方式会为每一个客户端创建一个线程,那么当有10K个客户端时,也就会有10K个线程。这样就会造成资源浪费。以及10K个线程同时运行,线程切换耗时增加,响应会很慢。
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.List;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/15
*/
public class C10KClient {
private static List<SocketChannel> clients = new ArrayList<>();
public static void main(String[] args) {
InetSocketAddress server = new InetSocketAddress("127.0.0.1", 9000);
long start = System.currentTimeMillis();
try {
for (int i = 10000; i < 65000; i++) {
SocketChannel client1 = SocketChannel.open();
client1.bind(new InetSocketAddress("127.0.0.1", i));
client1.connect(server);
clients.add(client1);
}
} catch (Exception ignore) {
// 系统占用端口可能引发端口占用异常
}
System.out.println("connection time consuming:" + (System.currentTimeMillis() - start));
System.out.println("clients = " + clients.size());
}
}
创建一个C10K客户端,然后启动BIO服务端,再启动上面的客户端(ps:因为只是为了查看一下效率,我是使用本地启动的服务端和客户端)
结果如下:
服务端:
client :14070 is in
client :14071 is in
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.gouxiazhi.io.SocketBIO.main(SocketBIO.java:53)
.......
客户端:
connection time consuming:27909
clients = 4122
可以看到使用BIO的方式时,只连了四千多个链接,就因为无法创建新的链接而报错了(因为我是使用本地,如果在linux服务器上跑的话,使用root用户可以多创建一些链接及线程,但是仍然无法避免资源耗尽的风险)
2.2 NIO
由于上面BIO的弊端,以及为了解决C10K的问题,出现了NIO模型(NonBlockingIO)。java中的nio指new io,而linux中的nio指NonblockingIO。
NIO是同步非阻塞模型。
代码如下:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/2
*/
public class SocketNIO {
public static void main(String[] args) throws IOException {
ArrayList<SocketChannel> clients = new ArrayList<>();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9000));
ssc.configureBlocking(false);
while (true) {
// 如果没有客户端连接进来则返回null
SocketChannel newClient = ssc.accept();
if (newClient != null) {
System.out.println("client " + newClient.getRemoteAddress() + " is in");
newClient.configureBlocking(false);
clients.add(newClient);
}
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
for (SocketChannel client : clients) {
int read = client.read(byteBuffer);
if (read > 0) {
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.limit()];
byteBuffer.get(bytes);
System.out.println("client:" + client.socket().getPort() + " write: " + new String(bytes));
byteBuffer.clear();
}
}
}
}
}
用一个线程去处理10K个客户端连接。
再次使用strace去追踪启动服务端,查看主线程系统调用:
........
accept(4, 0x7f2fbc0d21a0, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d4d50, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc72f070, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d19e0, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d21a0, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d4d50, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc72f070, [28]) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d19e0, [28]) = -1 EAGAIN (资源暂时不可用)
可以看到服务端是不再阻塞的,每次循环accept()方法如果没有接收到客户端连接,就返回-1,对应java里就返回null,然后继续下一次循环。使用nc连接服务端,发送数据,然后可以在主线程的系统调用文件out.13101中找到发送的数据,而且后续调用为:
accept(4, 0x7f2fbc0d19e0, [28]) = -1 EAGAIN (资源暂时不可用)
read(5, 0x7f2fbc0ff6a0, 1024) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbcea0cb0, [28]) = -1 EAGAIN (资源暂时不可用)
read(5, 0x7f2fbc0ffab0, 1024) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d4d50, [28]) = -1 EAGAIN (资源暂时不可用)
read(5, 0x7f2fbc0ffec0, 1024) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d21a0, [28]) = -1 EAGAIN (资源暂时不可用)
read(5, 0x7f2fbc1002d0, 1024) = -1 EAGAIN (资源暂时不可用)
accept(4, 0x7f2fbc0d19e0, [28]) = -1 EAGAIN (资源暂时不可用)
read(5, 0x7f2fbc1006e0, 1024) = -1 EAGAIN (资源暂时不可用)
同一个线程同时accept和从客户端read数据,没有时都返回null。
使用C10K客户顿端调用,服务端控制台输出结果如下:
// 服务端
client /127.0.0.1:20210 is in
client /127.0.0.1:20211 is in
client /127.0.0.1:20212 is in
Exception in thread "main" java.io.IOException: Too many open files
at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:424)
// 客户端
connection time consuming:52739
clients = 10214
(ps: 因为我是本地调用,所以可用fd不够,可以在linux下通过cat /proc/sys/fs/file-max命令查看当前用户可打开的fd数量,使用root用户时这个数量非常大,可以正常连接完这10w个连接数的。但是NIO仍无法避免的问题一个问题就是 fd文件不够,因为在生产环境不可能使用root用户来启动服务)
虽然本地无法启动建立完所有的连接,但是使用在linux上是可以建立的。我们使用c10K问题主要是为了看IO效率,至于fd不够的问题,通过扩容来解决(一台不够就再加一台),但是在使用NIO的时候,瓶颈并不在连接数上,因为只从fd考虑,NIO单台服务器就可以支持十万。从效率上看,我本地建立10214个连接耗时 52739毫秒。这里记一下下面我们会有更高效的方法
2.3 多路复用
但是NIO仍有它的缺陷,因为服务端和客户端都在一个线程中,主线程遍历客户端集合去每一个客户端都问一遍:你有没有数据,这样的话,如果有10K个客户端,只有最后一个客户端才收到了信息,但是取数据时还是要去将前面的99999个客户端问一遍,但是前面的遍历其实都是无用功。所以还要继续优化,就有了多路复用
回顾NIO的缺陷就是遍历。每次需要遍历所有的客户端,调用客户端的read()方法来取数据,没有数据继续调用下一个客户端的read()方法。每一次read()调用就对应一次系统调用----系统调用会产生中断,牵扯到保护现场恢复现场耗时增加。而当客户端非常多但是真正发送数据的客户端较少,频繁的调用进行read系统调用,但是真正 有效的调用(能够拿到客户端发来的数据)却很少,造成的后果就是:
- 频繁系统调用耗时,资源利用率低(有效调用少)
- 有效客户端如果位置靠后,则需要遍历前面所有客户端之后才会轮到它,时间复杂度是O(n)
那么能不能每次调用read时,只调用真正发来数据的客户端。
此时的问题就是如何才能知道哪儿些客户端是有数据的呢?
多路复用就是解决这个问题的。我们通过上面的学习知道了每一个客户端连接都会对应一个fd文件描述符。多路复用会通过在内核观察这些文件描述符的状态,然后返回给服务端到底哪儿些fd是有数据的,服务端读取时只需要读取这些有数据的fd就行了。
根据操作系统的不通,多路复用有多种实现。
2.3.1 select/poll
基本所有操作系统都会遵循POSIX协议--支持select,有的会支持poll。但是select和poll两种实现方式差不多。
使用man命令查看select:
int
select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict errorfds, struct timeval *restrict timeout);
查看poll:
int
poll(struct pollfd fds[], nfds_t nfds, int timeout);
select和poll的区别
select和poll其实很相似,两个都是需要传一个fd的集合,然后交由操作系统内核kernel,内核对fds进行遍历,筛选出可以读到数据的fds,返回给服务端,然后服务端就可以只对这些有数据的客户端进行read系统调用。这样时间复杂度就由O(n)降低到了O(m)
不同的是select可以穿的fds大小是有限制的,而poll取消了这个限制。
2.3.2 epoll
select和poll两种方式将遍历fds这件事提到了kernel级别,在kernel中进行fds的筛选,减少了系统调用。
但是它的弊端就是:
- 每次都需要传全量的fds
- 每次对全量的fds进行遍历,最终只筛选出可读的fds,时间复杂度仍然是O(n)
为了解决这两个问题,出现了epoll。
在计算机中存在中断,中断分为软中断和硬中断。硬中断就是时钟中断,软中断就是系统调用等。IO中断也是软中断。软中断即int 80会触发回调函数callback,发生中断时会保护现场,callback就是用来恢复现场的。中断完成后的操作。
IO中断会触发callback
而在计算机组成中,有网卡设备。网卡是有自己的buffer的。在内存中,除了kernel程序之外,网卡也有对应的DMA网卡驱动程序。当数据到达网卡后,会触发IO中断,通知cpu/或通知DMA网卡驱动 接收数据。有三种方式:
- package: 每到达一个数据包就触发一次IO中断,通知cpu接收数据到内存中
- buffer(平时常使用):每一个数据包就中断通知一次cpu这种方式效率太慢了,cpu频繁中断切换太忙了,因此可以使用DMA,DMA可以绑定网卡,产生一个buffer,数据达到网卡后先存到buffer中,然后通过dma直接将数据放入内存中,dma将数据放入内存后会触发IO中断。
- 轮询:如果数据发送非常频繁,而且很快就满了,那么不如就不发生中断了,就直接一直轮询接受网卡的数据。
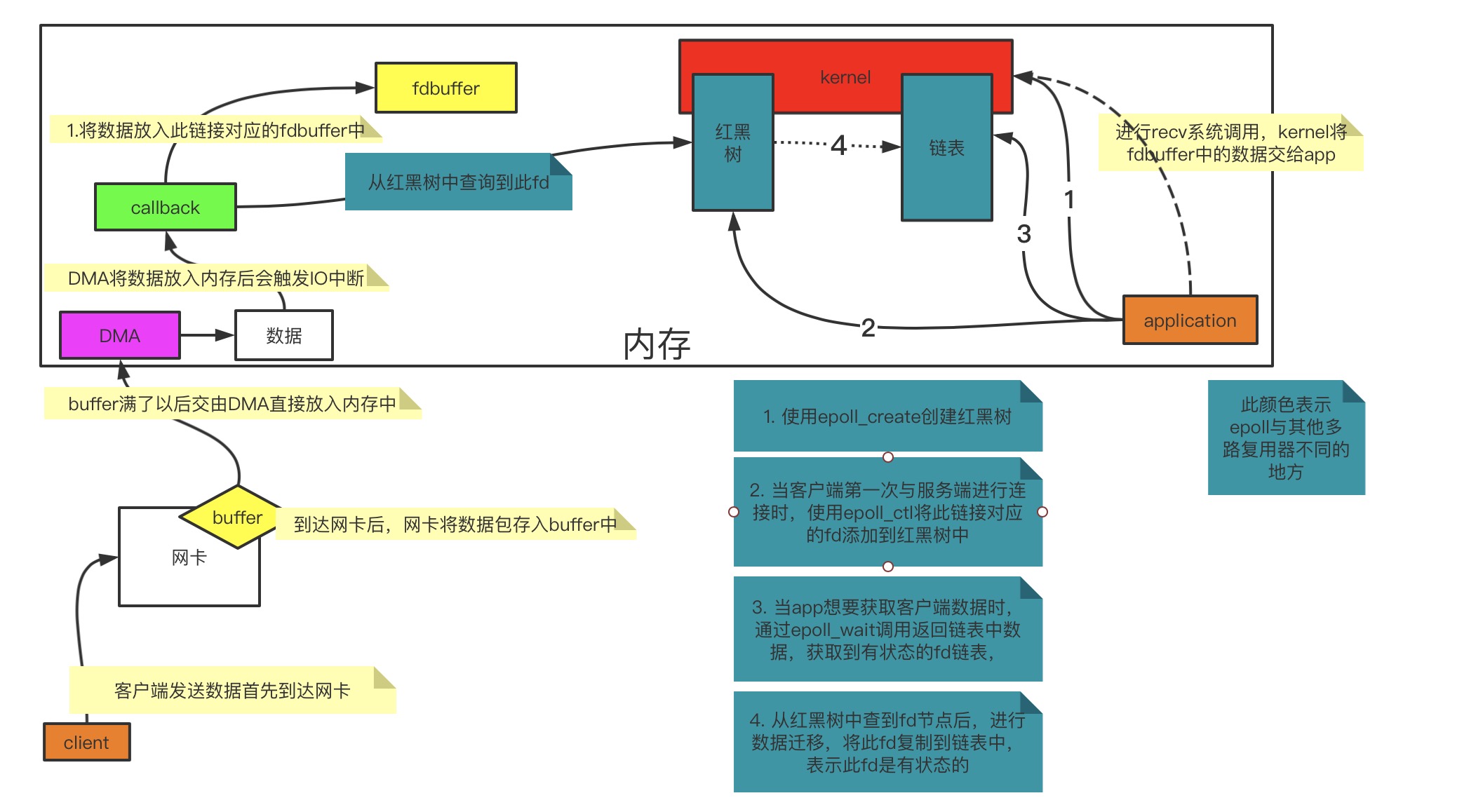
当触发IO中断,接收网卡的数据后,就会触发callback。之前的处理方式就是将网卡数据经过网络协议栈,最终绑定到fd的buffer。所以当应用程序某一时刻询问kernel某个或某些fd是否可读或可写,就会有状态返回。
epoll原理
epoll与select和poll的区别就是epoll在callback层做了其他处理:
epoll在内核中开辟了两块空间,一块是一个红黑树,用来存放全量fd,另一块用来存放状态被修改的fds链表(fds也就是fd的集合),也就是可读/可写的fds。
在以往的select/poll,都是需要传fds,然后内核对fds进行遍历筛选,它并没有将fd进行保存,因此每次都要传全量的fds。
而epoll在kernel中开辟了两块内存空间,一块是一个红黑树,用来存放交给它的fd,另一块用来存放有状态的fd返回给用户程序。
epoll分为三个系统调用:
epoll_create: 在kernel中开辟空间,创建一个红黑树,用来存放fdepoll_ctl: 对红黑树中的fd进行操作epoll_wait: 等待回调事件的产生,获取有状态的fd链表
当client向网卡发送一段数据后,那么整个数据处理流程如下:
简单实用代码实现多路复用
package com.gouxiazhi.io;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/15
*/
public class SingletonMultiplexingIO {
private Selector selector;
public void init() {
try {
// 创建服务端
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9090), 20);
// 设置非阻塞io
ssc.configureBlocking(false);
// 创建多路复用器
selector = Selector.open();
// 向多路复用器注册fd
ssc.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
init();
System.out.println("服务端启动了");
while (true) {
try {
while (selector.select() > 0) {
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
iterator.remove();
if (selectionKey.isAcceptable()) {
acceptHandler(selectionKey);
} else if (selectionKey.isReadable()) {
readHandler(selectionKey);
}
}
}
} catch (Exception ignore) {
}
}
}
public void acceptHandler(SelectionKey selectionKey) throws IOException {
ServerSocketChannel ssc = (ServerSocketChannel) selectionKey.channel();
SocketChannel client = ssc.accept();
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
client.register(selector, SelectionKey.OP_READ, buffer);
System.out.println("新客户端:" + client.getRemoteAddress());
}
public void readHandler(SelectionKey selectionKey) throws IOException {
SocketChannel client = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.clear();
while (true) {
int read = client.read(buffer);
System.out.println("read = " + read);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
client.write(buffer);
}
buffer.clear();
} else if (read == 0) {
break;
} else {
client.close();
}
}
}
public static void main(String[] args) {
SingletonMultiplexingIO smio = new SingletonMultiplexingIO();
smio.start();
}
}
启动上面服务端,再次使用C10K客户端去链接:
// 服务端
新客户端:/127.0.0.1:20208
新客户端:/127.0.0.1:20209
Exception in thread "main" java.lang.ExceptionInInitializerError
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:378)
at com.gouxiazhi.io.SingletonMultiplexingIO.readHandler(SingletonMultiplexingIO.java:77)
at com.gouxiazhi.io.SingletonMultiplexingIO.start(SingletonMultiplexingIO.java:51)
at com.gouxiazhi.io.SingletonMultiplexingIO.main(SingletonMultiplexingIO.java:95)
Caused by: java.io.IOException: Too many open files
at sun.nio.ch.FileDispatcherImpl.init(Native Method)
// 客户端
connection time consuming:1589
clients = 10214
可以看到同样是10214个连接,使用多路复用的方式,1589毫秒就完成了,效率要比NIO的方式快的多。
2.4 多路复用javaAPI
在上面我们简单java代码实现了多路复用,是一个单线程版的。讲上面的epoll代码复制到linux服务器中,使用strace追踪系统调用。
javaAPI会根据系统类型自动选择最优的多路复用器,因此在linux下默认就是使用epoll模型,也可以通过启动参数指定多路复用器模型。
# 因为默认是epoll,所以系统调用起名为epoll开头
strace -ff -o epoll java SingletonMultiplexingIO
# 再指定poll 起名为poll开头的
strace -ff -o poll java -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.PollSelectorProvider SingletonMultiplexingIO
执行完上面两条命令后就可以得到如下文件:
total 2160
-rw-rw-r-- 1 xz xz 13911 Jun 22 17:13 epoll.32474
-rw-rw-r-- 1 xz xz 526239 Jun 22 17:13 epoll.32475
-rw-rw-r-- 1 xz xz 62970 Jun 22 17:13 epoll.32476
-rw-rw-r-- 1 xz xz 1033 Jun 22 17:13 epoll.32477
-rw-rw-r-- 1 xz xz 1157 Jun 22 17:13 epoll.32478
-rw-rw-r-- 1 xz xz 2183 Jun 22 17:13 epoll.32479
-rw-rw-r-- 1 xz xz 28151 Jun 22 17:13 epoll.32480
-rw-rw-r-- 1 xz xz 20128 Jun 22 17:13 epoll.32481
-rw-rw-r-- 1 xz xz 1033 Jun 22 17:13 epoll.32482
-rw-rw-r-- 1 xz xz 1214432 Jun 22 17:13 epoll.32483
-rw-rw-r-- 1 xz xz 1935 Jun 22 17:13 epoll.32589
-rw-rw-r-- 1 xz xz 13661 Jun 22 17:13 poll.32595
-rw-rw-r-- 1 xz xz 9633 Jun 22 17:13 poll.32596
-rw-rw-r-- 1 xz xz 13954 Jun 22 17:13 poll.32602
-rw-rw-r-- 1 xz xz 206806 Jun 22 17:13 poll.32603
-rw-rw-r-- 1 xz xz 2121 Jun 22 17:13 poll.32604
-rw-rw-r-- 1 xz xz 1033 Jun 22 17:13 poll.32605
-rw-rw-r-- 1 xz xz 1157 Jun 22 17:13 poll.32606
-rw-rw-r-- 1 xz xz 2342 Jun 22 17:13 poll.32607
-rw-rw-r-- 1 xz xz 6577 Jun 22 17:13 poll.32608
-rw-rw-r-- 1 xz xz 3897 Jun 22 17:13 poll.32609
-rw-rw-r-- 1 xz xz 1033 Jun 22 17:13 poll.32610
-rw-rw-r-- 1 xz xz 10674 Jun 22 17:13 poll.32611
-rw-rw-r-- 1 xz xz 1935 Jun 22 17:13 poll.32612
-rw-rw-r-- 1 xz xz 3317 Jun 22 17:07 SingletonMultiplexingIO.class
-rw-rw-r-- 1 xz xz 3520 Jun 22 17:06 SingletonMultiplexingIO.java
查看epoll.32475:
...
# 首先创建一个socket套接字,得到文件描述符4
socket(PF_INET, SOCK_STREAM, IPPROTO_IP) = 4
...
# 绑定端口9000到文件描述符4上,并监听文件描述符4
bind(4, {sa_family=AF_INET, sin_port=htons(9000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(4, 20)
...
# 设置非阻塞
fcntl(4, F_SETFL, O_RDWR|O_NONBLOCK) = 0
...
# 打印创建socket成功
write(1, "create socket 9000 successful", 29) = 29
# 建立一个管道,占用文件描述符5,6,这两个文件描述符先不管
...
pipe([5, 6]) = 0
...
# 创建epoll,得到文件描述符7 这个7就是epoll在内核空间开辟的红黑树对应的文件描述符
epoll_create(256) = 7
...
# 调用epoll_ctl,将5添加到epoll中,这个不管
epoll_ctl(7, EPOLL_CTL_ADD, 5, {EPOLLIN, {u32=5, u64=4613014228473741317}}) = 0
write(1, "create multiplexing successful", 30) = 30
...
write(1, "register socket to epoll success"..., 35) = 35
...
# 将4通过 epoll_ctl 添加(EPOLL_CTL_ADD)到epoll中。这里注意,我们代码中,
# 打印: register socket to epoll success 这句话位置是在socket创建完成后,selector.select()代码执行前
# 但是在实际的调用中,注册4到epoll中在那句话后面打印的,因此实际执行中,在第一次执行 selector.select()时才注册 serverSocket到epoll中,其实是懒加载
epoll_ctl(7, EPOLL_CTL_ADD, 4, {EPOLLIN, {u32=4, u64=5340325089890009092}}) = 0
# selector.select(50) 对应的就是下面的epoll_wait
epoll_wait(7, {}, 8192, 50) = 0
epoll_wait(7, {}, 8192, 50) = 0
...
然后再看poll.32596:
...
# 首先创建一个socket套接字,得到文件描述符4
socket(PF_INET6, SOCK_STREAM, IPPROTO_IP) = 4
...
# 绑定端口9000到文件描述符4上,并监听文件描述符4
bind(4, {sa_family=AF_INET, sin_port=htons(9000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(4, 20)
...
# 设置非阻塞
fcntl(4, F_SETFL, O_RDWR|O_NONBLOCK) = 0
...
write(1, "create socket 9000 successful", 29) = 29
pipe([5, 6]) = 0
write(1, "create multiplexing successful", 30) = 30
write(1, "register socket to epoll success"..., 35) = 35
poll([{fd=5, events=POLLIN}, {fd=4, events=POLLIN}], 2, 50) = 0 (Timeout)
通过上面两个文件,可以很详细的看出两种方式的系统调用的区别。
然后我们来看如何使用java代码实现多路复用器:
单线程多路复用器
也就是上面我们做测试用的多路复用器:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/15
*/
public class SingletonMultiplexingIO {
private Selector selector;
public void init() {
try {
// 创建服务端 socket 系统调用
// socket(...) = 4
ServerSocketChannel ssc = ServerSocketChannel.open();
// bind(4, 9000)
// listen(4, 20)
ssc.bind(new InetSocketAddress(9000), 20);
// 设置为非阻塞
// fcntl(4, F_SETFL, O_RDWR|O_NONBLOCK) = 0
ssc.configureBlocking(false);
System.out.println("create socket 9000 successful");
// 创建多路复用器, 如果是epoll 则相当于调用 epoll_create
selector = Selector.open();
System.out.println("create multiplexing successful");
// 向多路复用器注册fd
// 代码虽然写在这里,但是实际调用是在下面第一次调用 selector.select()
// 原因是懒加载
ssc.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("register socket to epoll successful");
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
init();
System.out.println("服务端启动了");
while (true) {
try {
// selector.select()
// 如果使用 select/poll 模型的话,那么就相当于调用select/poll
// 如果使用epoll,就相当于调用epoll_wait
while (selector.select(50) > 0) {
// 获取有状态的fd
// poll的话就是传一堆fd过去,筛选出有状态的fd
// epoll就是返回链表中的fd
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 迭代处理每一个fd
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
// 每处理一个fd就从集合中remove掉
iterator.remove();
if (selectionKey.isAcceptable()) {
// 是可接收的fd
acceptHandler(selectionKey);
} else if (selectionKey.isReadable()) {
// 是可读的fd
readHandler(selectionKey);
}
// else if (selectionKey.isWritable()) {
// 暂时先不考虑此状态,但是要知道有这个状态
// }
}
}
} catch (Exception ignore) {
}
}
}
public void acceptHandler(SelectionKey selectionKey) throws IOException {
ServerSocketChannel ssc = (ServerSocketChannel) selectionKey.channel();
SocketChannel client = ssc.accept();
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
// 将这个可读的fd注册到红黑树中
// epoll_ctl( fd, EPOLL_CTL_ADD...
client.register(selector, SelectionKey.OP_READ, buffer);
System.out.println("新客户端:" + client.getRemoteAddress());
}
public void readHandler(SelectionKey selectionKey) throws IOException {
SocketChannel client = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.clear();
while (true) {
int read = client.read(buffer);
System.out.println("read = " + read);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
// 读到什么东西就写回去什么
client.write(buffer);
}
buffer.clear();
} else if (read == 0) {
break;
} else {
client.close();
}
}
}
public static void main(String[] args) {
SingletonMultiplexingIO smio = new SingletonMultiplexingIO();
smio.start();
}
}
来看上面这种单线程的多路复用器代码,这个版本的实现只有一个线程,也就是说所有的fd都是在一个线程中处理的,这样如果有一个线程执行时间耗时较长的话(在readHandler中处理时间过长)就会导致其他的fd都会被阻塞住往后延迟。因此我们可以很自然的想到,在处理读写事件时,使用多线程去处理。也就是下面这种方式:
基于多线程的多路复用器V1(version 1)
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/22
*/
public class MultiplexingIOThreads {
/**
* 线程池,处理事件
*/
private ExecutorService executor = Executors.newFixedThreadPool(5);
private Selector selector;
/**
* 初始化
*/
private void init() {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9000), 20);
ssc.configureBlocking(false);
this.selector = Selector.open();
ssc.register(this.selector, SelectionKey.OP_ACCEPT);
} catch (IOException ignore) {
}
}
private void start() {
this.init();
try {
while (true) {
while (selector.select(50) > 0) {
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> ski = selectionKeys.iterator();
while (ski.hasNext()) {
SelectionKey selectionKey = ski.next();
ski.remove();
if (selectionKey.isAcceptable()) {
acceptHandler(selectionKey);
} else if (selectionKey.isReadable()) {
// selectionKey.cancel() 取消key
selectionKey.cancel();
System.out.println("**selectionKey cancel**");
readHandler(selectionKey);
} else if (selectionKey.isWritable()) {
selectionKey.cancel();
writeHandler(selectionKey);
}
}
}
}
} catch (Exception ignore) {
}
}
private void writeHandler(SelectionKey selectionKey) {
executor.execute(() -> {
System.out.println("writeHandler ...");
SocketChannel sc = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.flip();
try {
sc.write(buffer);
} catch (IOException ignore) {
}
// 数据写完,将此fd重新置为可读状态
buffer.clear();
try {
sc.register(selector, SelectionKey.OP_READ, buffer);
} catch (ClosedChannelException e) {
e.printStackTrace();
}
});
}
private void readHandler(SelectionKey selectionKey) {
// 另起一个线程处理读事件
executor.execute(() -> {
System.out.println("readHandler ...");
SocketChannel sc = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.clear();
try {
while (true) {
// 可以读到数据
if (sc.read(buffer) > 0) {
// 反转buffer
buffer.flip();
// 读客户端发送的数据
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
System.out.println("client write: = " + new String(bytes));
buffer.clear();
buffer.put("successful".getBytes());
// 读取完数据后,将此链接注册为可写事件
sc.register(selector, SelectionKey.OP_WRITE, buffer);
} else {
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}
});
}
private void acceptHandler(SelectionKey selectionKey) throws IOException {
ServerSocketChannel ssc = (ServerSocketChannel) selectionKey.channel();
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
sc.register(selector, SelectionKey.OP_READ, buffer);
}
public static void main(String[] args) {
MultiplexingIOThreads instance = new MultiplexingIOThreads();
instance.start();
}
}
追踪启动上面的进程,然后使用nc连接服务端,主要是为了查看selectionKey.cancel()这个方法的系统调用:
# readhandler开辟新线程
clone(child_stack=0x7f5d048d3fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f5d048d49d0, tls=0x7f5d048d4700, child_tidptr=0x7f5d048d49d0) = 2
7579
futex(0x7f5d1404c354, FUTEX_WAIT_PRIVATE, 39, NULL) = 0
futex(0x7f5d1404c328, FUTEX_WAIT_PRIVATE, 2, NULL) = 0
futex(0x7f5d1404c328, FUTEX_WAKE_PRIVATE, 1) = 0
# 下一次执行epoll_wait即select()前先执行删除key操作
epoll_ctl(7, EPOLL_CTL_DEL, 8, {0, {u32=8, u64=1958317697552875528}}) = 0
futex(0x7f5d14107154, FUTEX_WAKE_OP_PRIVATE, 1, 1, 0x7f5d14107150, {FUTEX_OP_SET, 0, FUTEX_OP_CMP_GT, 1}) = 1
futex(0x7f5d14107128, FUTEX_WAKE_PRIVATE, 1) = 0
# 执行select()
epoll_wait(7, {}, 8192, 50)
关于
selectionKey.cancel()方法:
cancel()方法被调用时,会在下一次调用select()方法时将key从红黑树中删除,通过epoll_ctl(7, EPOLL_CTL_DELETE....)删除。
为什么要调用cancel()?
在之前的版本中,数据的输入和输出操作都是在同一个线程一个方法中进行,我们读完数据立即就执行了写操作,因此当一个方法执行完时,就代表这个key中的数据已经被读完了,但是现在使用多线程处理读写操作,因此可能出现的情况就是:当启动了一个子线程,但是因为需要读的数据非常大,比较耗时,子线程还在读数据是,主线程进入了下一次循环,仍然找到了这个fd,那么就会重新开劈子进程,重新读取fd数据,出现重复读数据的情况。因此当使用这种多线程读时,就需要调用cancel()去删除这个key,这样下次就不会再读到它了。
但是因为
线程池大小难控制,多线程间线程切换会影响效率,多线程会有线程安全性问题
cancel()实际调用的是epoll_ctl(DELETE)也是属于系统调用,IO模型的进化 BIO->NIO->多路复用,本就是为了减少 系统调用,因此这种方式违背了初心,不可取。
所以就进化出了新的多线程模型。
基于多线程的多路复用器V2
由于上面版本的多线程的问题,提出的解决方案就是:
开辟多个selector,每一个selector内部是单线程的,多个selector是并行的。同时利用了多线程和单线程的优点。
代码实现:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/30
*/
public class MultiplexingIOThreads_V2 {
private Selector selector1;
private Selector selector2;
private Selector selector3;
void init() {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9000));
ssc.configureBlocking(false);
selector1 = Selector.open();
selector2 = Selector.open();
selector3 = Selector.open();
ssc.register(selector1, SelectionKey.OP_ACCEPT);
ssc.register(selector2, SelectionKey.OP_ACCEPT);
ssc.register(selector3, SelectionKey.OP_ACCEPT);
} catch (IOException ignore) {
}
}
public static void main(String[] args) {
MultiplexingIOThreads_V2 mt_v2 = new MultiplexingIOThreads_V2();
mt_v2.init();
new SelectorThread(mt_v2.selector1, "selector1").start();
new SelectorThread(mt_v2.selector2, "selector2").start();
new SelectorThread(mt_v2.selector3, "selector3").start();
}
/**
* 每一个selector对应一个单线程
*/
static class SelectorThread extends Thread{
private Selector selector;
public SelectorThread(Selector selector, String threadName) {
super(threadName);
this.selector = selector;
}
@Override
public void run() {
try {
while (true) {
while (selector.select(50) > 0) {
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> ski = selectionKeys.iterator();
while (ski.hasNext()) {
SelectionKey selectionKey = ski.next();
ski.remove();
if (selectionKey.isAcceptable()) {
acceptHandler(selectionKey);
} else if (selectionKey.isReadable()) {
readHandler(selectionKey);
}
}
}
}
} catch (Exception ignore) {
}
}
public void acceptHandler(SelectionKey selectionKey) throws IOException {
ServerSocketChannel ssc = (ServerSocketChannel) selectionKey.channel();
SocketChannel client = ssc.accept();
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
// 将这个可读的fd注册到红黑树中
// epoll_ctl( fd, EPOLL_CTL_ADD...
client.register(selector, SelectionKey.OP_READ, buffer);
System.out.println(this.getName() + "新客户端:" + client.getRemoteAddress());
}
public void readHandler(SelectionKey selectionKey) throws IOException {
SocketChannel client = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.clear();
while (true) {
int read = client.read(buffer);
System.out.println("read = " + read);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
// 读到什么东西就写回去什么
client.write(buffer);
}
buffer.clear();
} else {
break;
}
}
}
}
}
首先看这一版本的多线程实现。多个selector线程共同处理客户端的连接请求。通过前面的C10K去验证此服务端。会发现一个问题:
因为多个线程的优先级是一样的,因此在客户端连接进来时,是随机分配给每个selector的,一个是不可控问题,可能有的selector注册的特别多,特别忙,有的selector却很闲。我们希望是多个selector协同处理所有的fd。因此我们做一下改动:
package com.gouxiazhi.io;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author shuai.zhao@going-link.com
* @date 2021/6/30
*/
public class MultiplexingIOThreads_V3 {
private Selector selector1;
void init() {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(9000));
ssc.configureBlocking(false);
selector1 = Selector.open();
ssc.register(selector1, SelectionKey.OP_ACCEPT);
} catch (IOException ignore) {
}
}
public static void main(String[] args) throws IOException {
MultiplexingIOThreads_V3 mt_v3 = new MultiplexingIOThreads_V3();
mt_v3.init();
new SelectorThread("boss", 2, mt_v3.selector1).start();
new SelectorThread("worker1").start();
new SelectorThread("worker2").start();
}
/**
* 每一个selector对应一个单线程
*/
static class SelectorThread extends Thread {
/**
* 统计当前boss所接收的客户端总数
*/
private static AtomicInteger idx = new AtomicInteger();
/**
* 下边有几个小弟
*/
private static int workers;
/**
* 一个小弟分一个任务链
*/
private volatile static LinkedBlockingQueue<SocketChannel>[] queues;
/**
* 干活的小弟
*/
private Selector selector;
/**
* 小弟编号
*/
private int id;
/**
* boss线程构造器
*
* @param name 线程名
* @param workers 小弟数量
* @param selector boss
*/
public SelectorThread(String name, int workers, Selector selector) {
super(name);
this.selector = selector;
SelectorThread.workers = workers;
queues = new LinkedBlockingQueue[workers];
for (int i = 0; i < workers; i++) {
queues[i] = new LinkedBlockingQueue<>();
}
}
public SelectorThread(String name) throws IOException {
super(name);
this.selector = Selector.open();
this.id = idx.getAndIncrement() % workers;
}
@Override
public void run() {
System.out.println(this.getName() + "start running");
try {
while (true) {
// 收集key
while (selector.select(50) > 0) {
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> ski = selectionKeys.iterator();
while (ski.hasNext()) {
SelectionKey selectionKey = ski.next();
ski.remove();
// boss线程会出现
if (selectionKey.isAcceptable()) {
acceptHandler(selectionKey);
}
// worker线程会出现
else if (selectionKey.isReadable()) {
readHandler(selectionKey);
}
}
}
if (!queues[id].isEmpty()) {
SocketChannel sc = queues[id].take();
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4096);
sc.register(this.selector, SelectionKey.OP_READ, byteBuffer);
System.out.println(this.getName() + "新客户端:" + sc.getRemoteAddress());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void acceptHandler(SelectionKey selectionKey) throws IOException {
ServerSocketChannel ssc = (ServerSocketChannel) selectionKey.channel();
SocketChannel client = ssc.accept();
client.configureBlocking(false);
// 给小弟的链表添加工作任务
int num = idx.getAndIncrement() % workers;
queues[num].add(client);
}
public void readHandler(SelectionKey selectionKey) throws IOException {
SocketChannel client = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
buffer.clear();
try {
while (true) {
int read = client.read(buffer);
System.out.println(this.getName() + "read = " + read);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
// 读到什么东西就写回去什么
client.write(buffer);
}
buffer.clear();
} else {
break;
}
}
} catch (Exception ignore) {
}
}
}
}
在上面这个版本中我们实现了多线程协作处理,其实已经有了netty的雏形,IO笔记至此完。
IO学习笔记(全)的更多相关文章
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- Java IO学习笔记总结
Java IO学习笔记总结 前言 前面的八篇文章详细的讲述了Java IO的操作方法,文章列表如下 基本的文件操作 字符流和字节流的操作 InputStreamReader和OutputStreamW ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- Java IO学习笔记一
Java IO学习笔记一 File File是文件和目录路径名的抽象表示形式,总的来说就是java创建删除文件目录的一个类库,但是作用不仅仅于此,详细见官方文档 构造函数 File(File pare ...
- nodejs的socket.io学习笔记
socket.io学习笔记 1.服务器信息传输: 2.不分组,数据传输: 3.分组数据传输: 4.Socket.io难点大放送(暂时没有搞定): 服务器信息传输 1. // send to curre ...
- 阻塞 io 非阻塞 io 学习笔记
阻塞 io 非阻塞 io 学习笔记
- Java IO学习笔记一:为什么带Buffer的比不带Buffer的快
作者:Grey 原文地址:Java IO学习笔记一:为什么带Buffer的比不带Buffer的快 Java中为什么BufferedReader,BufferedWriter要比FileReader 和 ...
- Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer
作者:Grey 原文地址:Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer ByteBuffer.allocate()与ByteBuffer.allocateD ...
- Java IO学习笔记三:MMAP与RandomAccessFile
作者:Grey 原文地址:Java IO学习笔记三:MMAP与RandomAccessFile 关于RandomAccessFile 相较于前面提到的BufferedReader/Writer和Fil ...
随机推荐
- vue + video.js/videojs-contrib-hls 实现hls拉流播放
当时接手拉流播放时使用的是西瓜播放器插件,神奇的是 安卓手机显示正常,但是苹果一直显示加载,pc端使用https格式不能播放,但是去掉s改为http即可进行播放 后面查看大佬文章后总算解决了这一需求 ...
- java基础(完整版)
java javaSE 注释: block块级 line 行 标识符和关键字 组成部分.变量名.类名.方法名--------标识符 $\数字._\字母 数据类型 强类型语言---安全性高--速度会慢 ...
- 修改Element - plus的样式
把显示再浏览器上的对应css选择器全部写上,并且添加 !important </script> <style lang='scss' scoped> //修改 element ...
- Luogu P3919 【模板】可持久化线段树 1(可持久化数组)
板子,正好温习一下主席树的写法 记得数组开 \(32\) 倍!! \(Code\) #include<cstdio> using namespace std; const int N = ...
- 单例 Bean 的线程安全问题
最近面试遇到一个问题:单例 Bean 的线程安全问题怎么解决的. 之前了解但是没有深究它的解决方法.大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题. 大部分 Bean 实际都是无状 ...
- Windows 注册表是什么
注册表的概念 历史发展 在 Windows 3.x 操作系统中,注册表是一个极小文件,其文件名为 Reg.dat,里面只存放了某些文件类型的应用程序关联,大部分的设置是被放在 win.ini.syst ...
- postgresql索引使用情况及坏索引处理
1.postgresql中索引系统视图pg_stat_user_indexes TEST=# \d+ sys_stat_user_indexes View "SYS_CATALOG.sys_ ...
- LeetCode-1669 合并两个链表
来源:力扣(LeetCode)链接:https://leetcode.cn/problems/merge-in-between-linked-lists 题目描述 给你两个链表 list1 和 lis ...
- 【3】java之string类
String 是一个字符串类型的类,使用双引号定义的内容都是字符串,但是 String 本身是一个类,使用上会有一些特殊. 一. String类对象的两种实例化方式 1.1 直接赋值 public c ...
- cisco ios 密码恢复
如果没有break键,使用仿真软件模仿一个break 密码恢复请执行以下步骤 1. 关闭或断开路由器电源 2.开启路由器.在通电后的前30秒内按下break键(或通过仿真程序发送一个间断序列),来中断 ...