Elasticsearch: rollover API
rollover使您可以根据索引大小,文档数或使用期限自动过渡到新索引。 当rollover触发后,将创建新索引,写别名(write alias)将更新为指向新索引,所有后续更新都将写入新索引。
对于基于时间的rollover来说,基于大小,文档数或使用期限过渡至新索引是比较适合的。 在任意时间rollover通常会导致许多小的索引,这可能会对性能和资源使用产生负面影响。
Rollover历史数据
在大多数情况下,无限期保留历史数据是不可行的
- 时间序列数据随着时间的流逝而失去价值,我们最终不得不将其删除
- 但是其中一些数据对于分析仍然非常有用
Elasticsearch 6.3引入了一项新的rollover功能,该功能
- 以紧凑的聚合格式保存旧数据
- 仅保存您感兴趣的数据

就像上面的图片看到的那样,我们定义了一个叫做logs-alias的alias,对于写操作来说,它总是会自动指向最新的可以用于写入index的一个索引。针对我们上面的情况,它指向logs-000002。如果新的rollover发生后,新的logs-000003将被生成,并对于写操作来说,它自动指向最新生产的logs-000003索引。而对于读写操作来说,它将同时指向最先的logs-1,logs-000002及logs-000003。在这里我们需要注意的是:在我们最早设定index名字时,最后的一个字符必须是数字,比如我们上面显示的logs-1。否则,自动生产index将会失败。
rollover例子
我们还是先拿一个rollover的例子来说明,这样比较清楚。首先我们定义一个log-alias的alias:
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"log_alias": {
"is_write_index": true
}
}
}
如果大家对于上面的字符串“%3Clogs-%7Bnow%2Fd%7D-1%3E”比较陌生的话,可以参考网站https://www.urlencoder.io/。实际上它就是字符串“<logs-{now/d}-1>”的url编码形式。请注意上面的is_write_index必须设置为true。运行上面的结果是:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "logs-2019.10.21-1"
}
显然,它帮我们生产了一个叫做logs-2019.10.21-1的index。接下来,我们先使用我们的Kibana来准备一下我们的index数据。我们运行起来我们的Kibana:
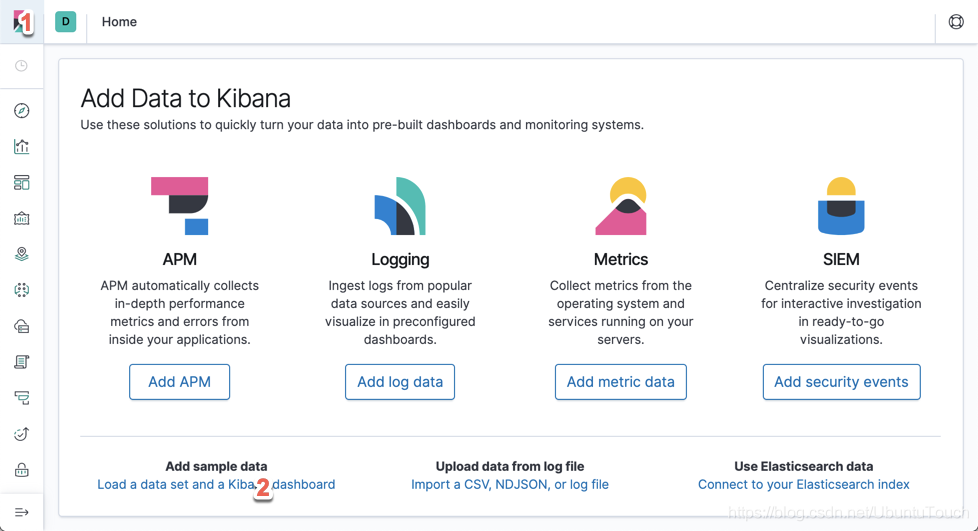
我们分别点击上面的1和2处:
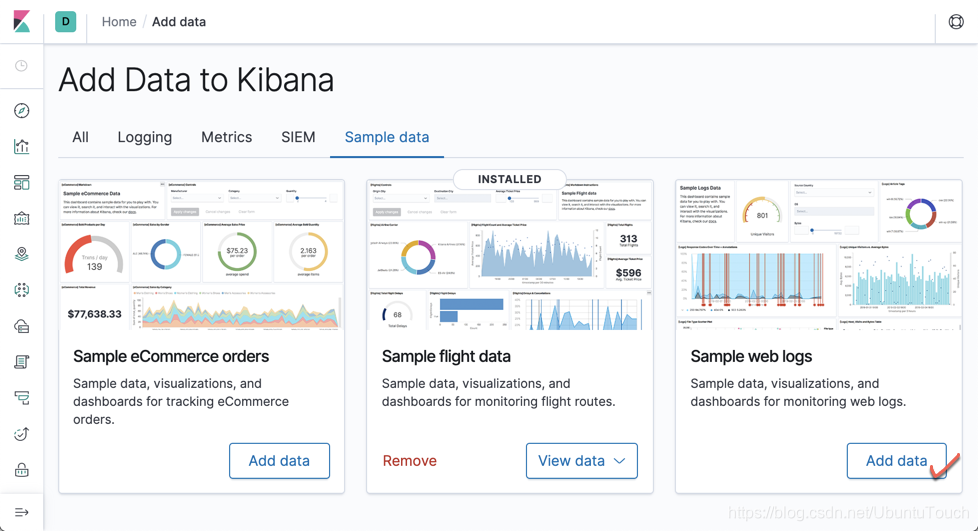
点击上面的“Add data”。这样我们就可以把我们的kibana_sample_data_logs索引加载到Elasticsearch中。我们可以通过如下的命令进行查看:
GET _cat/indices/kibana_sample_data_logs
命令显示结果为:
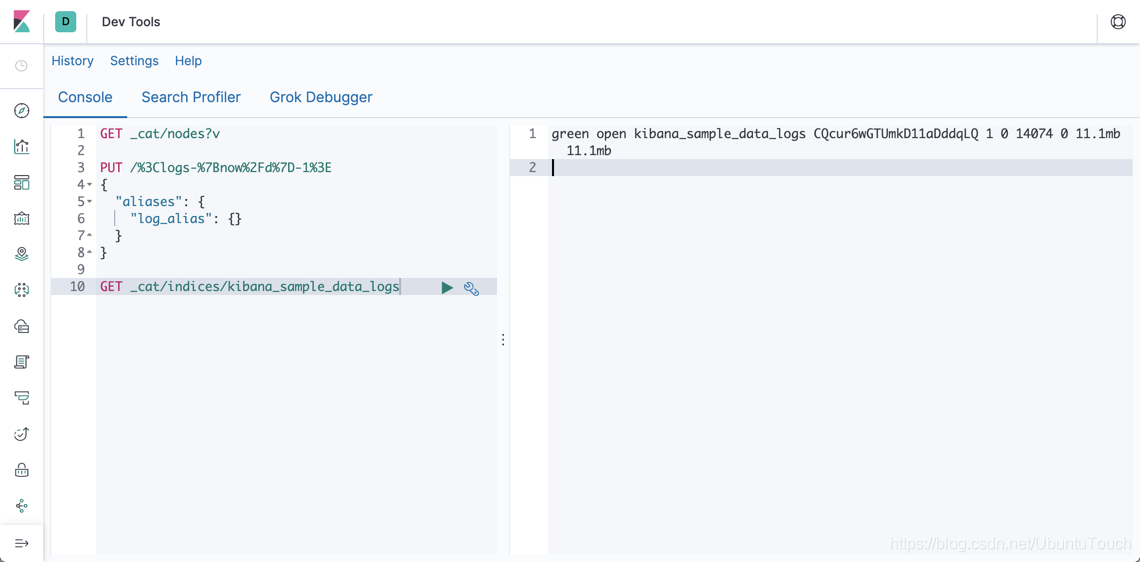
它显示kibana_sample_data_logs具有11.1M的数据,并且它有14074个文档:
我们接下来运行如下的命令:
POST _reindex
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "log_alias"
}
}
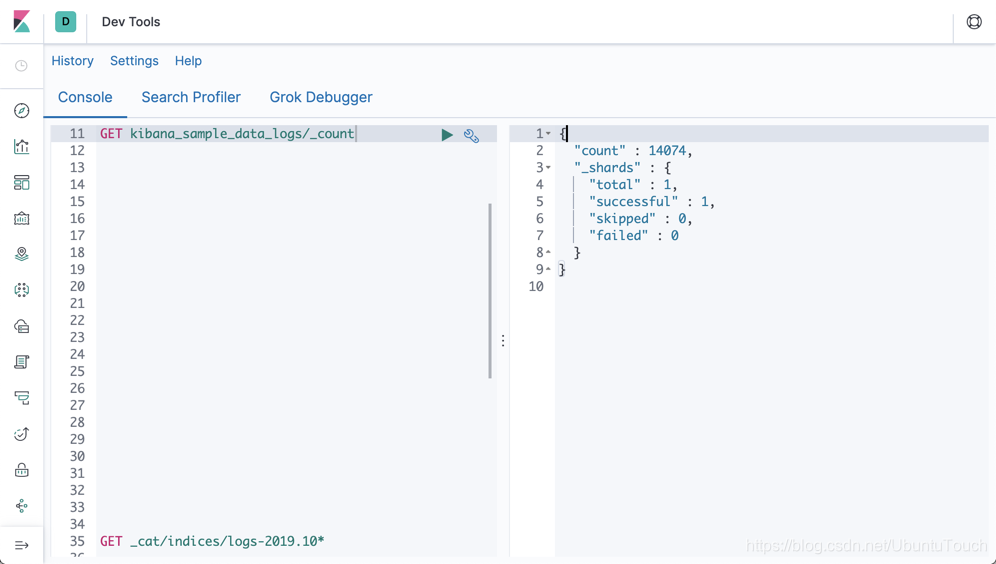
这个命令的作用是把kibana_sample_data_logs里的数据reindex到log_alias所指向的index。也就是把kibana_sample_data_logs的文档复制一份到我们上面显示的logs-2019.10.21-1索引里。我们做如下的操作查看一下结果:
GET logs-2019.10.21-1/_count
显示的结果是:
{
"count" : 14074,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
显然,我们已经复制到所有的数据。那么接下来,我们来运行如下的一个指令:
POST /log_alias/_rollover?dry_run
{
"conditions": {
"max_age": "7d",
"max_docs": 14000,
"max_size": "5gb"
}
}
在这里,我们定义了三个条件:
- 如果时间超过7天,那么自动rollover,也就是使用新的index
- 如果文档的数目超过14000个,那么自动rollover
- 如果index的大小超过5G,那么自动rollover
在上面我们使用了dry_run参数,表明就是运行时看看,但不是真正地实施。显示的结果是:
{
"acknowledged" : false,
"shards_acknowledged" : false,
"old_index" : "logs-2019.10.21-1",
"new_index" : "logs-2019.10.21-000002",
"rolled_over" : false,
"dry_run" : true,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
根据目前我们的条件,我们的logs-2019.10.21-1文档数已经超过14000个了,所以会生产新的索引logs-2019.10.21-000002。因为我使用了dry_run,也就是演习,所以显示的rolled_over是false。
为了能真正地rollover,我们运行如下的命令:
POST /log_alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1400,
"max_size": "5gb"
}
}
显示的结果是:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "logs-2019.10.21-1",
"new_index" : "logs-2019.10.21-000002",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
说明它已经rolled_ovder了。我们可以通过如下写的命令来检查:
GET _cat/indices/logs-2019*
显示的结果为:

我们现在可以看到有两个以logs-2019.10.21为头的index,并且第二文档logs-2019.10.21-000002文档数为0。如果我们这个时候直接再想log_alias写入文档的话:
POST log_alias/_doc
{
"agent": "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1",
"bytes": 6219,
"clientip": "223.87.60.27",
"extension": "deb",
"geo": {
"srcdest": "IN:US",
"src": "IN",
"dest": "US",
"coordinates": {
"lat": 39.41042861,
"lon": -88.8454325
}
},
"host": "artifacts.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "223.87.60.27",
"machine": {
"ram": 8589934592,
"os": "win 8"
},
"memory": null,
"message": """
223.87.60.27 - - [2018-07-22T00:39:02.912Z] "GET /elasticsearch/elasticsearch-6.3.2.deb_1 HTTP/1.1" 200 6219 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1"
""",
"phpmemory": null,
"referer": "http://twitter.com/success/wendy-lawrence",
"request": "/elasticsearch/elasticsearch-6.3.2.deb",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2019-10-13T00:39:02.912Z",
"url": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.deb_1",
"utc_time": "2019-10-13T00:39:02.912Z"
}
显示的结果:
{
"_index" : "logs-2019.10.21-000002",
"_type" : "_doc",
"_id" : "xPyQ7m0BsjOKp1OsjsP8",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
显然它写入的是logs-2019.10.21-000002索引。我们再次查询log_alias的总共文档数:
GET log_alias/_count
显示的结果是:
{
"count" : 14075,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
}
}
显然它和之前的14074个文档多增加了一个文档,也就是说log_alias是同时指向logs-2019.10.21-1及logs-2019.10.21-000002。
总结:在今天的文档里,我们讲述了如何使用rollover API来自动管理我们的index。利用rollover API,它可以很方便地帮我们自动根据我们设定的条件帮我们把我们的Index过度到新的index。在未来的文章里,我们将讲述如何使用Index life cycle policy来帮我们管理我们的index。
Elasticsearch: rollover API的更多相关文章
- elasticsearch REST API方式批量插入数据
elasticsearch REST API方式批量插入数据 1:ES的服务地址 http://127.0.0.1:9600/_bulk 2:请求的数据体,注意数据的最后一行记得加换行 { &quo ...
- [搜索]ElasticSearch Java Api(一) -添加数据创建索引
转载:http://blog.csdn.net/napoay/article/details/51707023 ElasticSearch JAVA API官网文档:https://www.elast ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- Elasticsearch java api 常用查询方法QueryBuilder构造举例
转载:http://m.blog.csdn.net/u012546526/article/details/74184769 Elasticsearch java api 常用查询方法QueryBuil ...
- ElasticSearch的API介绍
ElasticSearch的API介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.ES是基于Restful风格 1>ES是基于Restful风格 Elasticsea ...
- 搜索引擎Elasticsearch REST API学习
Elasticsearch为开发者提供了一套基于Http协议的Restful接口,只需要构造rest请求并解析请求返回的json即可实现访问Elasticsearch服务器.Elasticsearch ...
- 第08章 ElasticSearch Java API
本章内容 使用客户端对象(client object)连接到本地或远程ElasticSearch集群. 逐条或批量索引文档. 更新文档内容. 使用各种ElasticSearch支持的查询方式. 处理E ...
- Elasticsearch 常用API
1. Elasticsearch 常用API 1.1.数据输入与输出 1.1.1.Elasticsearch 文档 #在 Elasticsearch 中,术语 文档 有着特定的含义.它是指最顶 ...
- elasticsearch REST api
elasticsearch REST api========================================命令模式:<REST Verb> /<Index>/ ...
随机推荐
- Mybatis-Generator 自定义注释
继承DefaultCommentGenerator 或者CommentGenerator package com.zhianchen.mysqlremark.toword.config;import ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- vivado没用上的寄存器变量
vivado中定义了但没用上的寄存器变量,在综合时会被移除,即没有综合出来.(如下cnt,虽然在y的过程块中用了cnt作为判断条件,但实际上cnt用了跟没用效果一样,所以综合时cnt_reg就被放弃了 ...
- CodeSys中编程实现串口通讯
第一步:Linux中启用串口设备.[以树莓派4B为例] 树莓派4B有6个串口,参考上一篇<>,在 /boot/config.txt 中添加一行,开启 uart2 功能: dtoverl ...
- Java基础语法02
回顾前面的章节,我们学习了(1.注释,2.标识符和关键字,3.数据类型)今天让我们继续加油. 四.变量,常量,作用域1.变量是什么:存数的(可以变化的量) Java是一种强类型语言,每个变量都必须声明 ...
- YII自定义第三方扩展
cat.php <?php /** * Created by PhpStorm. * Date: 2016/5/25 * Time: 15:23 */ namespace vendor\anim ...
- Nginx 平滑升级、Nginx的一些基础配置
# Nginx 平滑升级 # 方案一:使用Nginx服务信号进行升级 # 1.将就版本的sbin目录下可执行nginx进行备份(mv nginx nginxold) # 2.将新版本 configur ...
- Flutter-填平菜鸟和高手之间的沟壑
Flutter-填平菜鸟和高手之间的沟壑 准备写作中... 1.Flutter-skia-影像,Flutter skia-图形渲染层.应用渲染层2.方法通道使用示例,用于演示如何使用方法通道实现与原生 ...
- openjdk的bug
容器内就获取个cpu利用率,怎么就占用单核100%了呢 背景:这个是在centos7 + lxcfs 和jdk11 的环境上复现的 下面列一下我们是怎么排查并解这个问题的. 一.故障现象 oppo内核 ...
- 大家都能看得懂的源码 - 那些关于DOM的常见Hook封装(二)
本文是深入浅出 ahooks 源码系列文章的第十五篇,该系列已整理成文档-地址.觉得还不错,给个 star 支持一下哈,Thanks. 本篇接着针对关于 DOM 的各个 Hook 封装进行解读. us ...