Python 国家地震台网中心地震数据集完整分析、pyecharts、plotly,分析强震次数、震级分布、震级震源关系、发生位置、发生时段、最大震级、平均震级
前情提要
编写这篇文章是为了记录自己是如何分析地震数据集,使用模块,克服一系列 \(bug\) 的过程。如果你是 \(python\) 初入数据分析的小白,那么这篇文章很适合你。阅读栏目时建议不要跳过任何步骤,从头看到尾你会收获很多。
本篇文章代码注释使用了 \(vscode\) 的 better-comments 拓展
数据获取
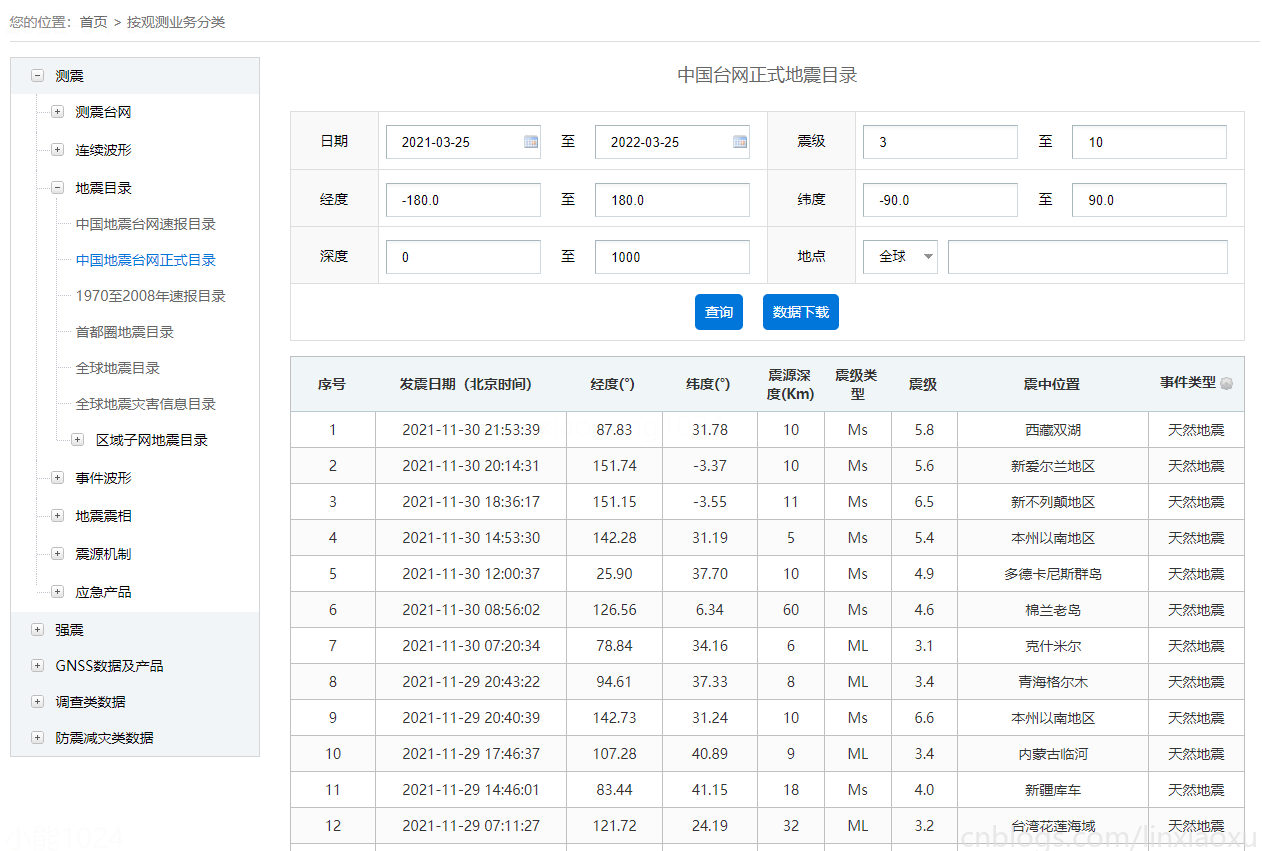
数据来源于中国地震台网中心 国家地震科学数据中心
我们挑选时间范围 12 年内,震级 >= 3 级的数据集。低于3级的为无感地震,出现次数较为频繁不作考虑。
![]()
运行环境
\(Python\) 版本 \(3.10.2\),使用模块(包含两个主流绘图库)
- \(pyecharts\)
- \(plotly\)
- \(requests\)
- \(pandas\)
- \(numpy\)
基本目标
- 经纬度转换(不同地图运营商)(暂不考虑)
- 数据读取、数据清理
- 经纬度转换省份城市
- 省份强震次数图(词云、地图)
- 地震震级分布图
- 前十大地震表格
- 震级震源深度散点图
- 世界地震热力图
- 中国地震热力图
- 按年地震次数曲线图
- 按月地震次数曲线图
- 24小时段地震发生百分比图
- 最大震级与平均震级折线图
- 图表合并
读取数据
从 excel 读取
# ^ 读取中国地震数据集
data = pd.read_excel("./china.xls")
data.columns = ["id", "date", "lon", "lat", "depth", "type", "level", "loc", "incident"]
print(data.shape, "\n", data.dtypes)
(6848, 9)
id int64
date datetime64[ns]
lon float64
lat float64
depth int64
type object
level float64
loc object
incident object
dtype: object
读取数据集的方式很简单,由于列名为中文且带有特殊符号,我们这里对其进行简化全部修改为英文。可以直接修改 \(dataframe\) 的属性。或者使用 \(rename\) 方法。
\(read\_excel\) 更多参数可参考 pandas.read_excel — pandas 1.4.2 documentation (pydata.org)
数据清洗
一般来说中国地震台网中心提供的数据比较权威,不会有问题。但是为了以防万一,我们还是要进行数据清理,删除空行、重复行。
# ^ 数据清理
# @ 统计NaN个数
x = data.isnull().sum().sum()
# @ 第一次sum()算出各个列有几个,第二次算出全部
print('共有NaN:', x)
# @ 统计重复行个数
x = data.duplicated().sum()
print('共有重复行:', x)
共有NaN: 0
共有重复行: 0
可以看出数据还是比较可靠的。
经纬度转换省份城市
申请 api
注册高德地图个人开发者,申请API,选择 Web服务。申请完成后查看开发文档,选择坐标转换。
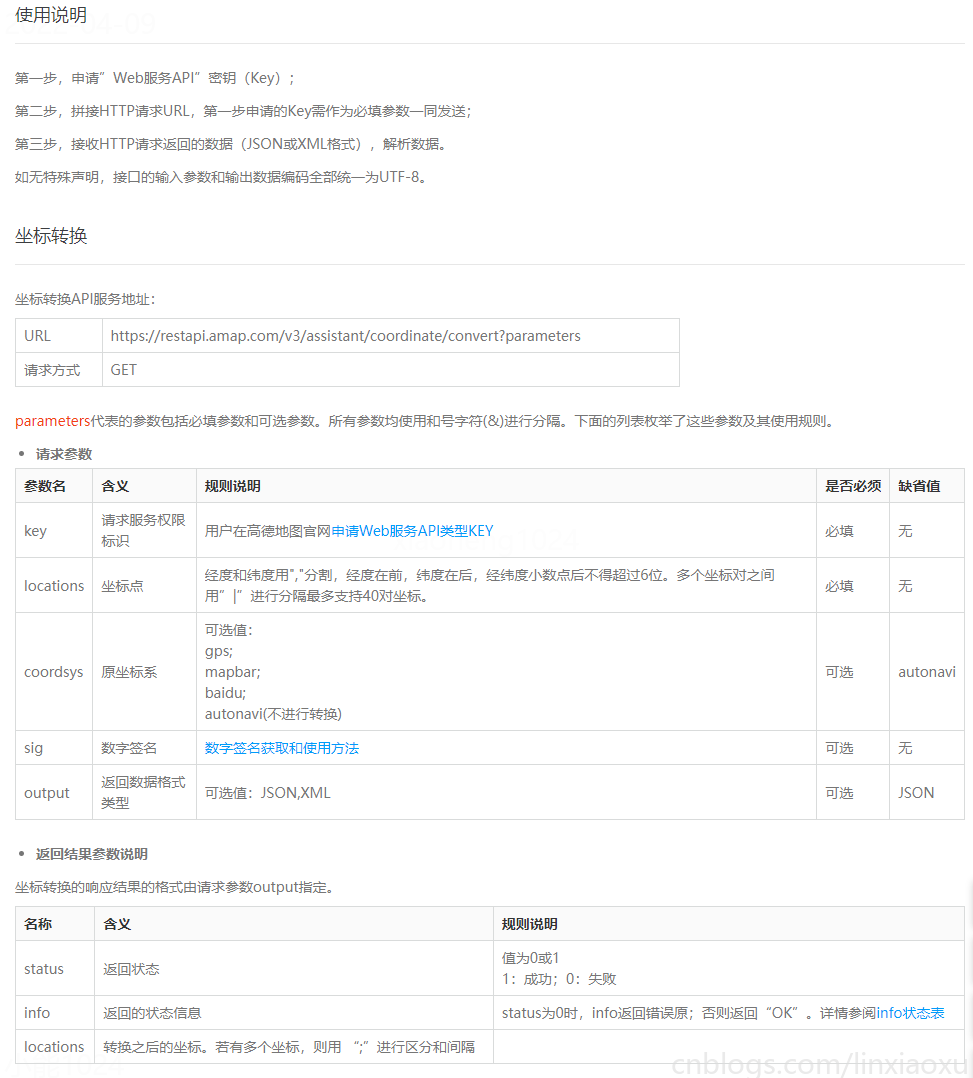
为了让函数能够重复使用、整体代码更加简洁,将坐标转换的方法分离出来单独放入一个 \(utils.py\) 工具包类。
数据迭代方式
比较以下两种方式获取的数据
df = data.head(3)
# ^ 选取其中两列,分别是经度纬度
print(df[['lon', 'lat']])
print(df[['lon', 'lat']].values)
lon lat
0 87.83 31.78
1 94.61 37.33
2 107.28 40.89
[[ 87.83 31.78]
[ 94.61 37.33]
[107.28 40.89]]
可以看到 \(.values\) 返回的是可迭代的 \(numpy\) 数组对象。我们就可以按照接口规定的方式发送请求了。
Return a Numpy representation of the DataFrame.
Only the values in the DataFrame will be returned, the axes labels will be removed.
测试 api 接口
import requests
# ^ 测试 API 接口 坐标转换
location = "{0[0]},{0[1]}".format([87.83, 31.78])
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': '不给你看',
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
r = requests.get(url, params=params)
data = r.json()
print(data)
{'status': '1', 'regeocode': {'addressComponent': {'city': '那曲市', 'province': '西藏自治区', 'adcode': '540630', 'district': '双湖县', 'towncode': '540630100000', 'streetNumber': {'number': [], 'direction': [], 'distance': [], 'street': []}, 'country': '中国', 'township': '措折
罗玛镇', 'businessAreas': [[]], 'building': {'name': [], 'type': []}, 'neighborhood': {'name': [], 'type': []}, 'citycode': '0896'}, 'formatted_address': '西藏自治区那曲市双湖县措折罗玛镇'}, 'info': 'OK', 'infocode': '10000'}
通过测试接口拿到的 \(json\) 中,我们关心的数据是 \(regeocode\) -> \(addressComponent\) -> \(city、province\)
上面代码中关于字符串格式化 \(format\) 更多的信息参考 Python format 格式化函数 | 菜鸟教程 (runoob.com)
编写函数(have bug)
def latitude_longitude_conversion(df):
# step 将经纬度坐标转换为省份城市,作为两列添加到df
citys = []
provinces = []
# ^ 选取其中两列, 分别是经度纬度
for location in df[['lon', 'lat']].values:
# ^ 将每行的经纬度转换成特定字符串
location = "{0[0]},{0[1]}".format(location)
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': API_KEY,
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
# ^ 发送 get 请求
r = requests.get(url, params=params)
# ^ 接收数据转换为 json 格式
data = r.json()['regeocode']
city = data['addressComponent']['city']
province = data['addressComponent']['province']
# ^ 上海市,上海市
if len(city) == 0:
city = province
citys.append(city)
provinces.append(province)
df['city'] = citys
df['province'] = provinces
循环遍历然后把省份城市加到两个数组内,最后再绑定到 \(dataframe\) 的两个新列上。
if len(city) == 0:
city = province
这部分代码的意思是假如拿到的 \(city\) 为空,应当把省份给 \(city\),否则会出现数据缺省。
测试函数(find bug)
from utils import latitude_longitude_conversion
# ^ 测试经纬度坐标转换
df_test = data.head(3)
latitude_longitude_conversion(df_test)
print(df_test)
引入编写的工具库函数,进行测试。警告如下
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
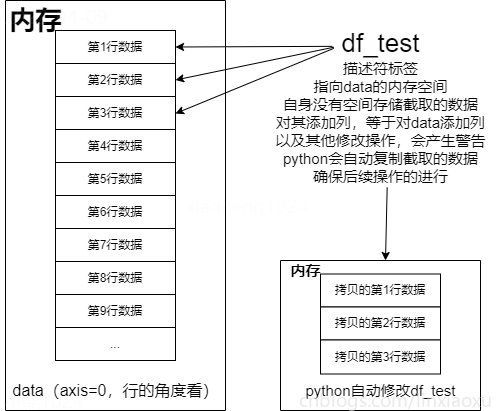
变量 \(df\)(df_test) 其实是一个“标签”(描述符)而不是一个“容器”。截取数据的前三行,\(df\) 实际是一个指向 \(data\) 前三行的描述符,在内存中并没有为 \(df\) 分配新的地址存储希望截取的数据。
因此针对 \(df\) 的修改,会产生警告。因为 \(df\) 既没有数据也没有列名,其指向的是 \(data\) 的前三行。
这就是 \(python\) 所谓的“链式索引”(chained indexing)而引起的错误或警告。
但 \(python\) 比较聪明,为了防止报错退出程序,会自己拷贝一份我们希望截取的内容,使 \(df\) 指向拷贝的数据块,才能完成变更列名以及完成后面的计算。
解决方法是在截取数据的语句后加一个 \(.copy()\) 复制一份数据给 \(df\) 。
最终函数(fix bug)
def latitude_longitude_conversion(df):
# step 将经纬度坐标转换为省份城市,作为两列添加到df
df = df.copy()
citys = []
provinces = []
# ^ 选取其中两列, 分别是经度纬度
for location in df[['lon', 'lat']].values:
# ^ 将每行的经纬度转换成特定字符串
location = "{0[0]},{0[1]}".format(location)
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': API_KEY,
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
# ^ 发送 get 请求
r = requests.get(url, params=params)
# ^ 接收数据转换为 json 格式
data = r.json()['regeocode']
city = data['addressComponent']['city']
province = data['addressComponent']['province']
# ^ 上海市,上海市
if len(city) == 0:
city = province
citys.append(city)
provinces.append(province)
df['city'] = citys
df['province'] = provinces
return df
在第一行加 df = df.copy() ,并在末尾添加 return df
再次测试(final)
还是原来的代码,这里我们限定一些列防止行输出过长。
# ^ 测试经纬度坐标转换
df_test = data.head(3)
df_test = latitude_longitude_conversion(df_test)
print(df_test[['id', 'lon', 'lat', 'level', 'city', 'province']])
id lon lat level city province
0 1 87.83 31.78 5.8 那曲市 西藏自治区
1 2 94.61 37.33 3.4 海西蒙古族藏族自治州 青海省
2 3 107.28 40.89 3.4 巴彦淖尔市 内蒙古自治区
成功通过接口处理数据!
保存为 csv
因为接口有使用次数限制,为了方便后续调试。我们将 \(6000\) 多行数据统一转换,保存为 \(csv\) 文件。这也会加快 \(pandas\) 模块读取数据集的速度。
# ^ 将所有数据坐标进行转换并保存为 csv 文件
data = latitude_longitude_conversion(data)
data.to_csv('china_new.csv', index=False)
由于是单线程,网络速率不是很快,等待时间会长一点,处理完成后是图下结果。

读取 csv
# STEP 读取数据集
data = pd.read_csv('./china_new.csv')
print(data.shape)
# STEP 对 city、province 进行修改
data["province"].replace("[]", "其他", inplace=True)
data["city"].replace("[]", "其他", inplace=True)
data["province"].replace("中华人民共和国", "其他", inplace=True)
data["city"].replace("中华人民共和国", "其他", inplace=True)
有部分境内但没有明确城市省份的地震统一归为其他(一般为海域、边境地区)。 对 \(city、province\) 进行替换
多图表合并 pyecharts
像生成了许多 \(html\) 图表文件,可以使用 \(echarts.Page\) 统一合并为一个 \(html\) 文件。
# STEP 多图表合并
page = Page(layout=Page.SimplePageLayout)
page.add(
depth_info, level_info, c5, c1, c2, c3, c4, c6, c7, c8, c9_1, c9_2, c9_3, c10, c11
) # 可以多次添加 pycharts 图表信息
page.render("完整版.html")
这段代码放在末尾,用于一次性生成完整的 \(html\) 文件,具体可参考
Page - Page_simple_layout - Document (pyecharts.org)
导入模块
\(pyecharts\) 和 \(plotly\) 分开写在两个文件中,引入需要的库。
import pandas as pd
import numpy as np
from utils import province_to_short
from pyecharts import options as opts
from pyecharts.charts import WordCloud, Page, Bar, Scatter, Line
from pyecharts.globals import SymbolType, ThemeType
from pyecharts.charts import Map
from pyecharts.components import Table
from pyecharts.options import ComponentTitleOpts
from pyecharts.commons.utils import JsCode
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
省份强震次数图
地震级别划分标准
M>=4.5级的属于可造成破坏的地震,但破坏轻重还与震源深度、震中距等多种因素有关。发震时刻、震级、震中统称为"地震三要素"。
- M≥3级,小于4.5级的称为有感地震,这种地震人们能够感觉到,但一般不会造成破坏。
- M≥4.5级,小于6级的称为中强震。
- M≥6级,小于7级的称为强震。
- M≥7级,小于8级的称为大地震。
- 8级以及8级以上的称为巨大地震 (5·12汶川地震,3·11日本地震)。
统计各地区强震次数
统计 \(12\) 年内各地区发生 \(M>=4.5\) 强震的次数。
# STEP 各地区强震次数
df1 = data.query('level>=4.5 and province!="其他"').groupby("province")
print("level>=4.5 共有地区 ", df1.ngroups)
只考虑省份,不考虑境内其他地方,通过 \(query\) 进行过滤,再用 \(groupby\) 进行分组。
词云绘图 pyecharts
Wordcloud - Wordcloud_diamond - Document (pyecharts.org)
# 接上面部分
maxCount = df1.size().max() # @ 选择可视化地图标尺的最大值
df1 = list(df1.size().items()) # @ 是右边的简写形式 [(val, idx) for idx, val in s.iteritems()]
print(df1)
# ^ pycharts 绘制词云
c1 = (
WordCloud()
.add("", df1, word_size_range=[20, 55], shape=SymbolType.DIAMOND) # @ 字体太大会导致过长字段无法显示
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年各省份M>=4.5地震次数"))
)
# c1.render("1_省份强震次数图_词云.html")
\(maxCount\) 获取分组中最大值,也就是可视化地图最大深度值。使用了巧妙的方式将 \(Series\) 对象转换成元组数组,可以参考 python - how to convert pandas series to tuple of index and value - Stack Overflow
地图绘图 pyecharts
转化短省份名
由于 \(pyecharts\) 地图模块的省份名必须是短省份名,否则将无法正确显示。为 \(utils\) 工具包编写如下函数,原理是根据字典查询并返回短省份名。
def province_to_short(province):
P2S = {
"北京市": "北京",
"天津市": "天津",
"重庆市": "重庆",
"上海市": "上海",
"河北省": "河北",
"山西省": "山西",
"辽宁省": "辽宁",
"吉林省": "吉林",
"黑龙江省": "黑龙江",
"江苏省": "江苏",
"浙江省": "浙江",
"安徽省": "安徽",
"福建省": "福建",
"江西省": "江西",
"山东省": "山东",
"河南省": "河南",
"湖北省": "湖北",
"湖南省": "湖南",
"广东省": "广东",
"海南省": "海南",
"四川省": "四川",
"贵州省": "贵州",
"云南省": "云南",
"陕西省": "陕西",
"甘肃省": "甘肃",
"青海省": "青海",
"台湾省": "台湾",
"内蒙古自治区": "内蒙古",
"广西壮族自治区": "广西",
"宁夏回族自治区": "宁夏",
"新疆维吾尔自治区": "新疆",
"西藏自治区": "西藏",
"香港特别行政区": "香港",
"澳门特别行政区": "澳门"
}
return P2S.get(province)
绘制地图(gotcha)
Map - Map_visualmap - Document (pyecharts.org)
# ^ pycharts 绘制地图
# print(maxCount, type(maxCount))
df1 = [(province_to_short(x[0]), x[1]) for x in df1] # @ 需要将完整省份名转换成短省份名,否则无法显示
c2 = (
Map()
.add("强震次数", df1, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="2010-2022年各省份M>=4.5地震次数"),
visualmap_opts=opts.VisualMapOpts(max_=int(maxCount)),
)
)
# c2.render("1_省份强震次数图_地图.html")
这里有个明显的 \(gotcha\),前面使用 maxCount = df1.size().max() 获取到标尺的最大值。输出也是浮点数,但是你需要注意这是 numpy.int64 类型,是不能被直接用的,需要进行显式转换。所以你可以看到在绘图的过程中使用了 max_=int(maxCount) 。
图表效果

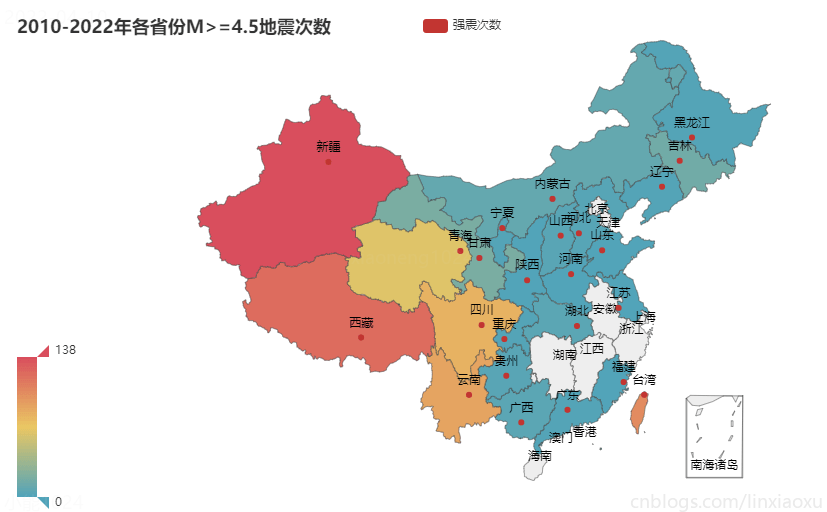
结论
通过统计2010-2022年各省份 M>= 4.5 地震次数
- 12年内新疆强震次数最多为138次。其次为西藏121次,台湾省103次,云南89次,四川81次。
- 强震多发生于第一级阶梯、第二级阶梯地势高的地方。地势低且平缓的第三级阶梯发生强震少,部分地区没有发生过强震。
地震震级分布图
柱状图绘图 pyecharts
Bar - Bar_base - Document (pyecharts.org)
# STEP 地震震级分布
mags = data.groupby("level")
print("震级分组 ", mags.ngroups)
mags = mags.size().items()
# ^ mags 只可以迭代一次
xaxis, yaxis = [], []
for x in mags:
xaxis.append(x[0])
yaxis.append(x[1])
c3 = (
Bar()
.add_xaxis(xaxis)
.add_yaxis("震次", yaxis, category_gap=8)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年国内地震震级分布", subtitle="地震次数"))
)
# c3.render("2_地震震级分布.html")
需要注意的是使用 \(items()\) 获取的迭代器只能完整迭代一次。再次迭代会得到空数组。
category_gap=8 为各个柱体的间隔距离。
opts.LabelOpts(is_show=False) 不在柱体上显示数字标签。
# FIXME 这部分应该还可以优化,太慢了
mags = data.groupby(lambda x: int(data.iloc[x]['level']))
mags = mags.size().items()
xaxis, yaxis = [], []
for x in mags:
xaxis.append(x[0])
yaxis.append(x[1])
c4 = (
Bar()
.add_xaxis(xaxis)
.add_yaxis("震次", yaxis, category_gap=50)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年国内地震震级分布", subtitle="地震次数"))
)
使用 \(lambda\) 匿名函数处理每行字段震级化为整数再进行 \(groupby\) ,速度较慢,后续有新方法会更新。
图表效果
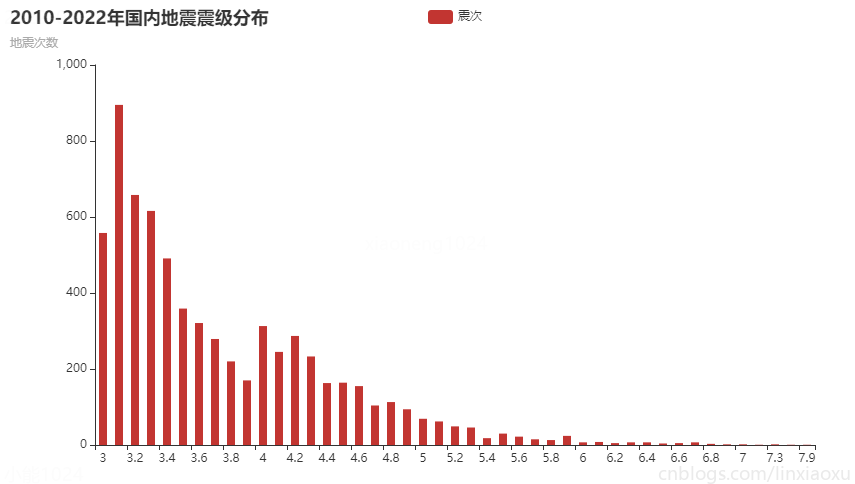
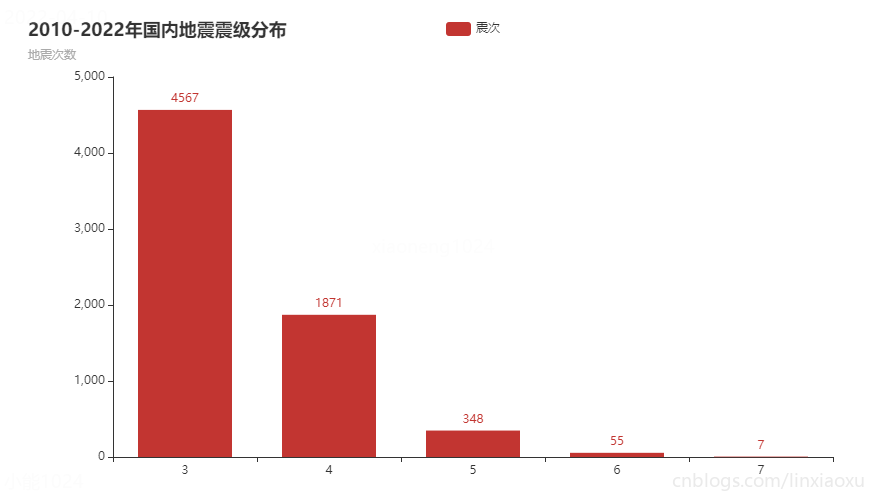
结论
通过统计2010-2022年国内地震震级分布
- 震级分布明显成斜向下的曲线函数。
- 中强震较多,破坏性地震较少。
国内前十大地震
表格绘图 pyecharts
Table - Table_base - Document (pyecharts.org)
# STEP 挑选前十大地震
c5_df = data.sort_values('level', ascending=False).head(10)
print(c5_df.values, c5_df.columns.values)
c5 = Table()
headers = c5_df.columns.values.tolist()
rows = c5_df.values.tolist()
# print(type(headers)) # BUG <class 'numpy.ndarray'>
c5.add(headers, rows)
c5.set_global_opts(
title_opts=ComponentTitleOpts(title="2010-2022国内前十大地震", subtitle="地震信息")
)
使用 \(sort\_values\) 对特定列排序,并给定 \(ascending\) 参数要求降序排序,最后挑选前十个。
这里需要注意如果不使用 \(tolist()\) 会出现如下错误
The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
具体原因还是类型问题,默认 \(values\) 拿到的是 <class 'numpy.ndarray'>。转换成普通类型就好了。
图表效果
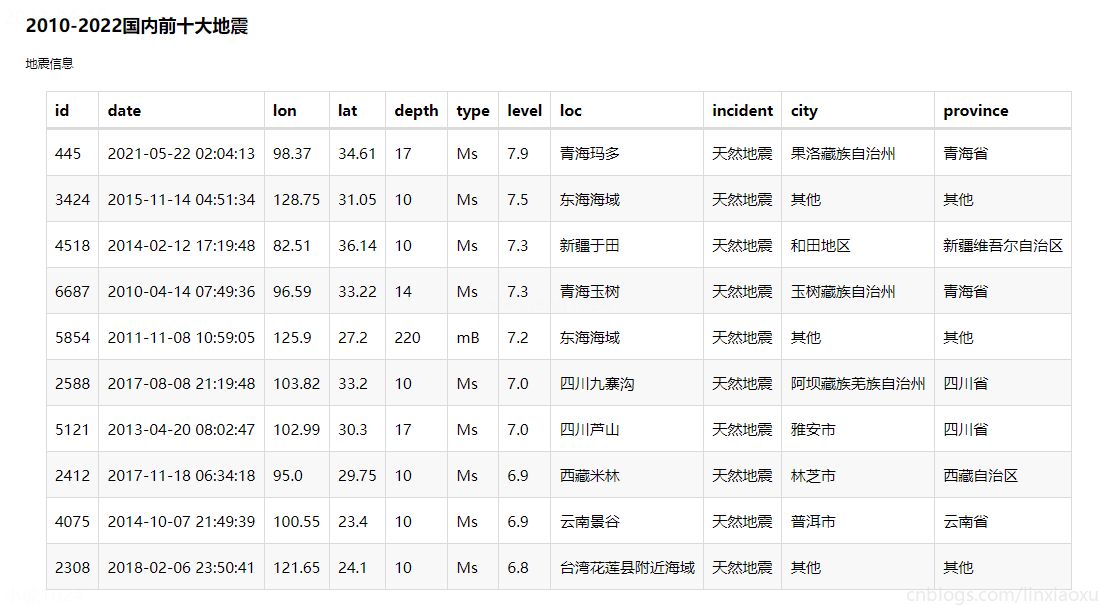
结论
通过统计2010-2022年中国前十大地震
- 青海、东海、四川都发生过两次特大地震。
- 特大地震震源深度众数为 10 km,但是东海海域震源深度为 220 km 比较特殊。
- 特大地震震级都在 7 级左右。
震级震源深度散点图
散点图绘图
Scatter - Basic_scatter_chart - Document (pyecharts.org)
全局配置项 - pyecharts - A Python Echarts Plotting Library built with love.
# STEP 震级震源深度散点图
c6_df = data[["level", "depth"]].copy()
c6_df.drop_duplicates(inplace=True)
c6_df = c6_df.values.tolist()
c6_df.sort(key=lambda x: x[0])
x_data = [d[0] for d in c6_df]
y_data = [d[1] for d in c6_df]
c6 = (
Scatter(init_opts=opts.InitOpts(width="1600px", height="1000px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震源深度",
y_axis=y_data,
symbol_size=8,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts(is_show=True), min_=3, name="震级(M)"
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="深度(KM)",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=True),
title_opts=opts.TitleOpts(title="2010-2022年震级震源深度散点图"),
)
)
复制了两个列表,然后删除相同行。用 \(c6\_df.sort(key=lambda x: x[0])\) 对数组进行一次排序,然后遍历数组。
\(symbol\_size\) 为点的大小。\(min\_=3\) 将图表前部分剔除。因为数据集的数据 \(M>=3\)。
图表效果
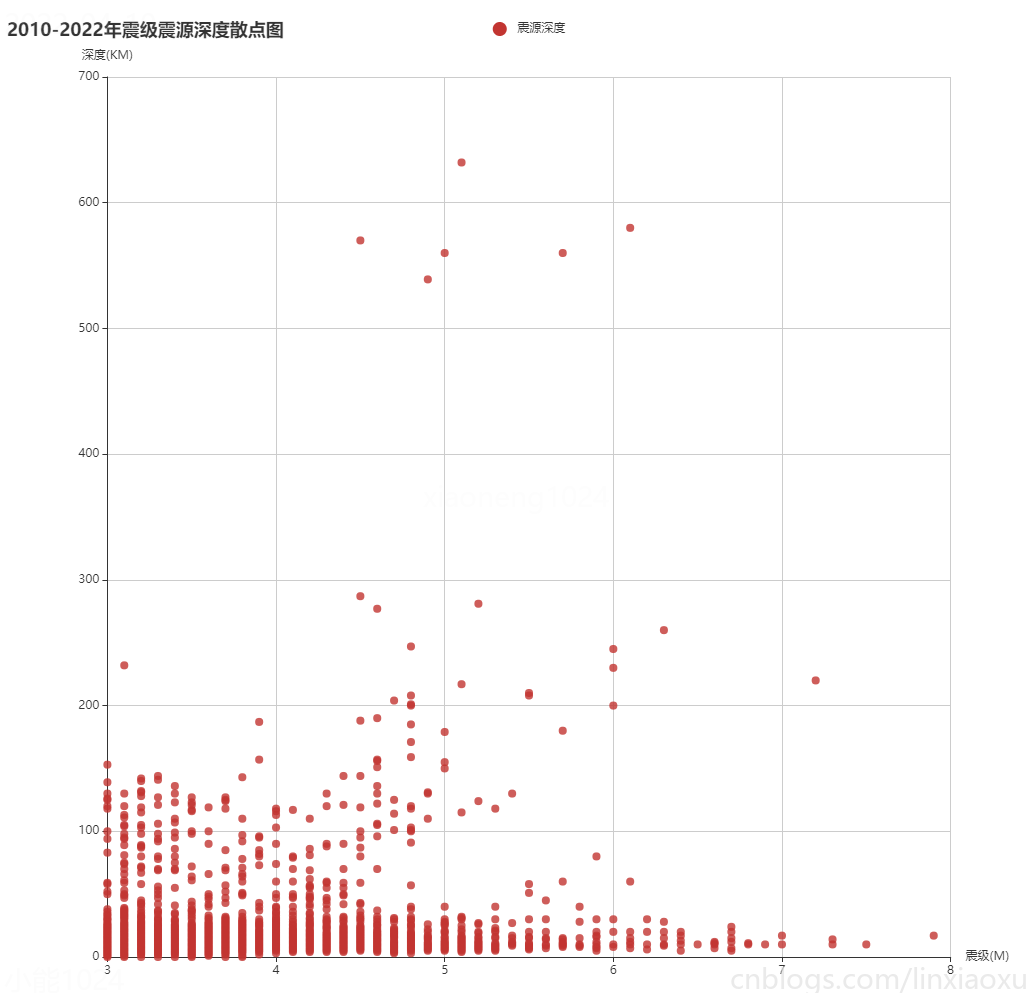
总结
通过震级震源深度散点图
- 震级和震源深度呈现不均匀分布。总体来看两者没有多大关系。
- 由于内陆经常发生中小型地震,震源深度一般不会过高。致使左下角震级与震源深度的堆积
世界地震热力图
绘制热力图 plotly
# STEP 世界地震热力图 plotly
p1_data = pd.read_csv("./world_new.csv")
# step 筛选 >= 4.5 地震
p1_data = p1_data.query('level>=4.5')
my_map = go.Densitymapbox(lat=p1_data['lat'], lon=p1_data['lon'], z=p1_data['level'], radius=10)
fig = go.Figure(my_map)
p1 = fig.update_layout(mapbox_style="stamen-terrain")
p1.write_html("p1.html", include_plotlyjs='cdn')
# pip install -U kaleido
# p1.write_image("p1.png", format="png")
需要注意的是给定一个 \(mapbox\_style\) 否则图表将无法正常显示。
write_html("p1.html", include_plotlyjs='cdn') 将图表导出为 \(html\) 文件。\(js\) 需要配置为 \(cdn\) 加速加载速度。
图表效果
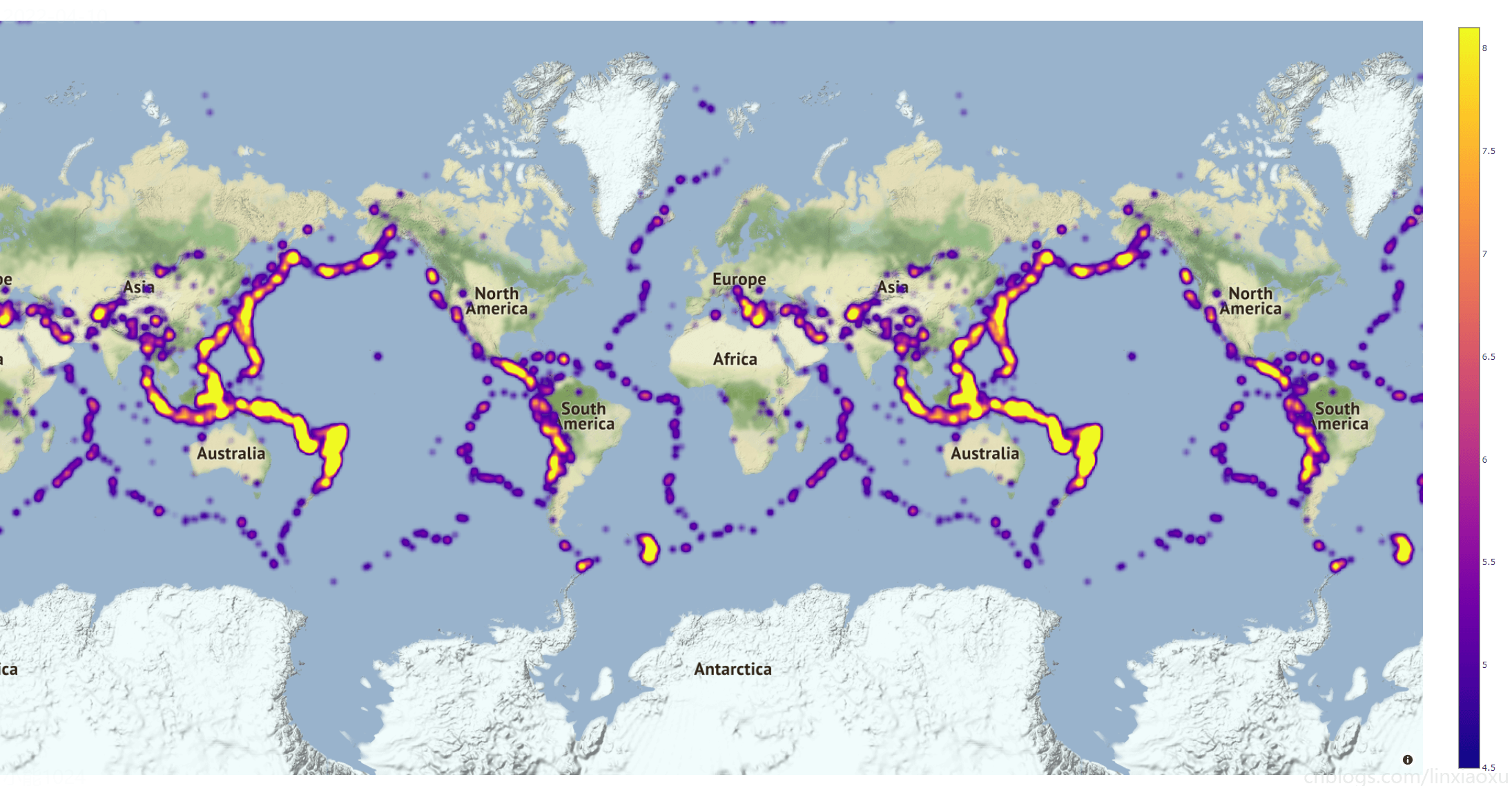
总结
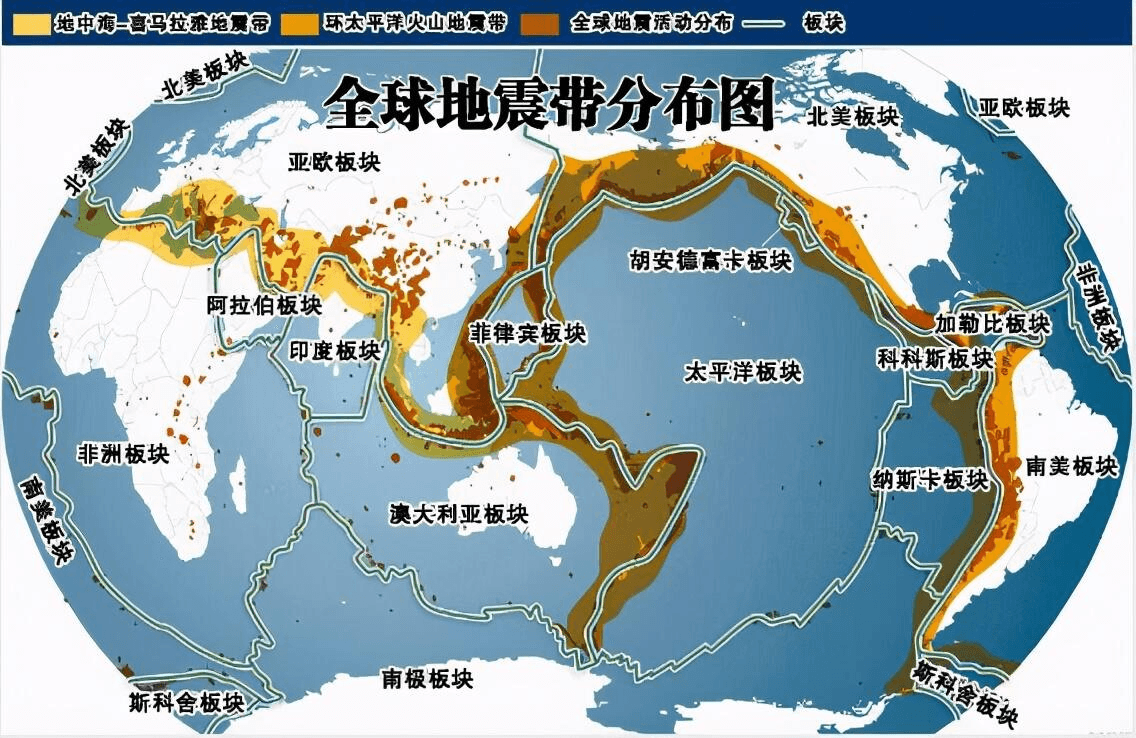
结合全球地震带分布图分析,可以看出热力图轮廓与全球地震带分布图轮廓非常相似。基本上吻合。强地震大部分都发生在板块交界处。
中国地震热力图
绘制热力图 plotly
# STEP 中国地震热力图 plotly
p2_data = pd.read_csv("./china_new.csv")
p2 = px.density_mapbox(p2_data, lat='lat', lon='lon', z='level', radius=10,
center=dict(lat=34, lon=108), zoom=4,
mapbox_style="stamen-terrain")
p2.write_html("p2.html", include_plotlyjs='cdn')
这里用了另外一种方法,比上面的方法更加简洁,并明确指定了初始化图表的中心方位。
图表效果

结论
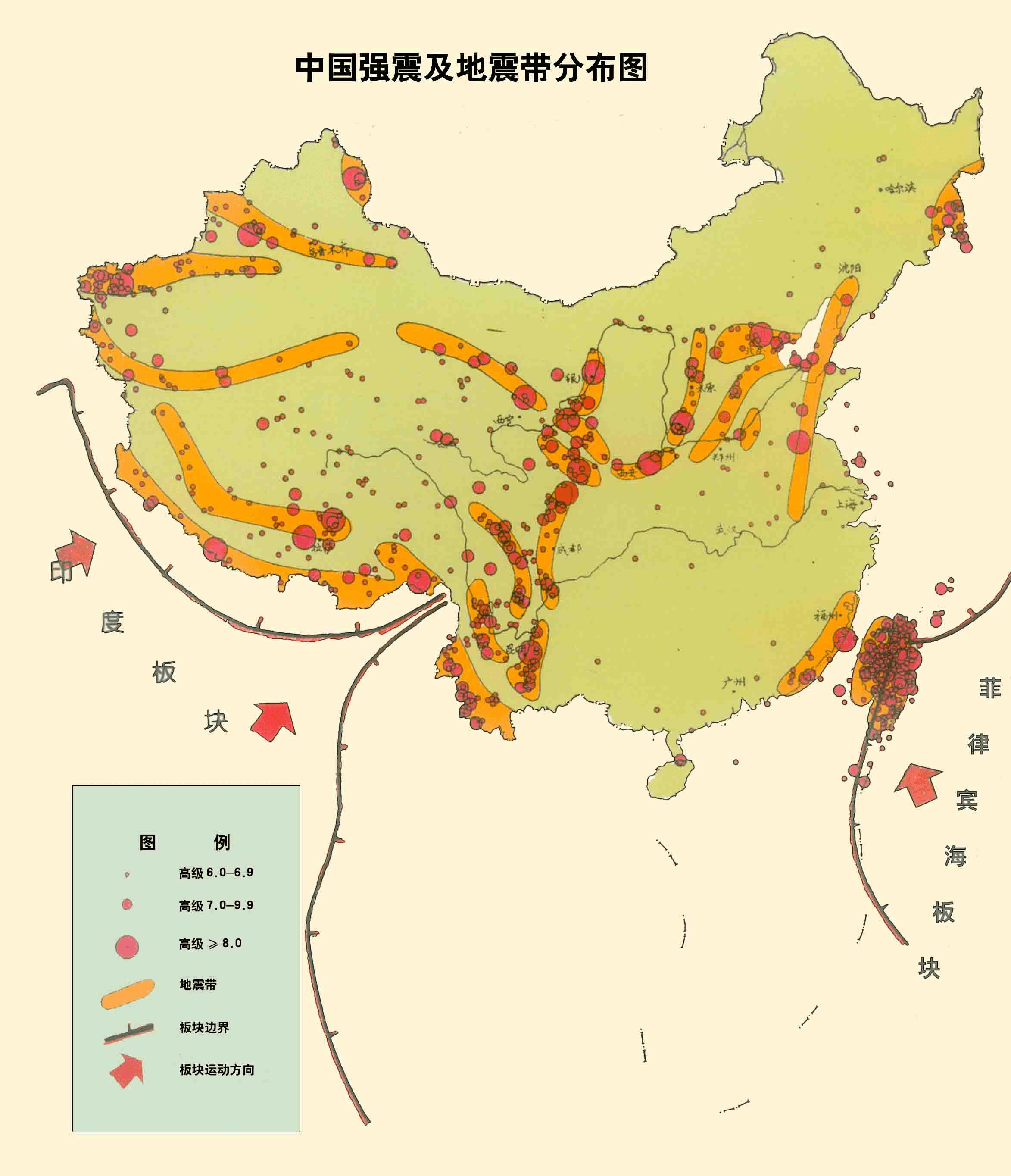
- 结合中国地震带分布图,可以看出热力图轮廓与其轮廓非常相似,大体吻合。
- 台湾省发生的地震强震次数明显,在地图中高亮显示。原因是台湾刚好地处环太平洋地震带,所以是我国地震频率最高的省份。
我国位于亚欧大陆东部,太平洋的西岸地区,两大地震带对于我国都有影响。我国的西南地区的喜马拉雅山脉和横断山脉地区就是地中海-喜马拉雅地震带经过的区域,亚欧板块和印度洋板块在南北方向上碰撞挤压,形成一系列呈东西走向的地震断裂带,以及横断山脉地区南北走向的地震断裂带。与此有关的地震带包括喜马拉雅地震带、青藏高原地震带、西北地震带、南北地震带、腾冲-澜沧地震带、滇西地震带和滇东地震带。
我国西部地区总体而言是地震相对高发的地区,包括西藏自治区、青海省、新疆维吾尔自治区、甘肃省、宁夏回族自治区、四川省和云南省等地都有较高的地震风险,其中越靠近地中海-喜马拉雅地震带,地震风险越高,比如说云南、四川、西藏等地区都是地震高风险省区。此外,我国东部海域地区又处在环太平洋地震带通过的地区,亚欧板块和太平洋板块在东西方向上相互挤压,形成一系列东北西南走向的地震断裂带。与此有关的地震带包括环太平洋地震带、东南沿海地震带和华北地震带。
相对而言环太平洋地震带离我国的距离比地中海-喜马拉雅地震带要远一些,因此,总体影响要小一些,但是某些地区地震活跃程度却非常高,比如我国的台湾省刚好地处环太平洋地震带,是我国地震频率最高的省份。除此之外广东省、福建省、安徽省、江苏省、山东省、河北省、河南省、山西省、陕西省、北京市、天津市、辽宁省、吉林省和黑龙江省都有地震带的分布。除去以上省份,我们发现内蒙古自治区、上海市、浙江省、江西省、湖北省、湖南省、贵州省和广西壮族自治区基本上没有地震带涉及,也就是地震风险相对较低的省份。
年月地震次数曲线图
绘制曲线图 pyecharts
Line - Smoothed_line_chart - Document (pyecharts.org)
# STEP 按年地震次数曲线图
# ^ 日期转换
data['date'] = pd.to_datetime(data['date'])
c7_data = data.groupby(data['date'].dt.year)
c7_data = c7_data.size().items()
x_data, y_data = [], []
for x in c7_data:
x_data.append(str(x[0])) # IMPORTANT 必须是字符串
y_data.append(x[1])
c7 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="2010-2022年按年地震次数曲线图"),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=True),
)
)
c8_data = data.groupby([data['date'].dt.year, data['date'].dt.month])
c8_data = c8_data.size().items()
x_data, y_data = [], []
for x in c8_data:
x_data.append(str(x[0]))
y_data.append(x[1])
c8 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="2010-2022年按月地震次数曲线图"),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=False),
)
)
为了能够使用特殊日期函数,必须进行整列的日期转换。
data['date'] = pd.to_datetime(data['date'])
需要注意图表属性 \(x\_axis\) 必须是字符串数组,否则将不能正常显示。
日期函数
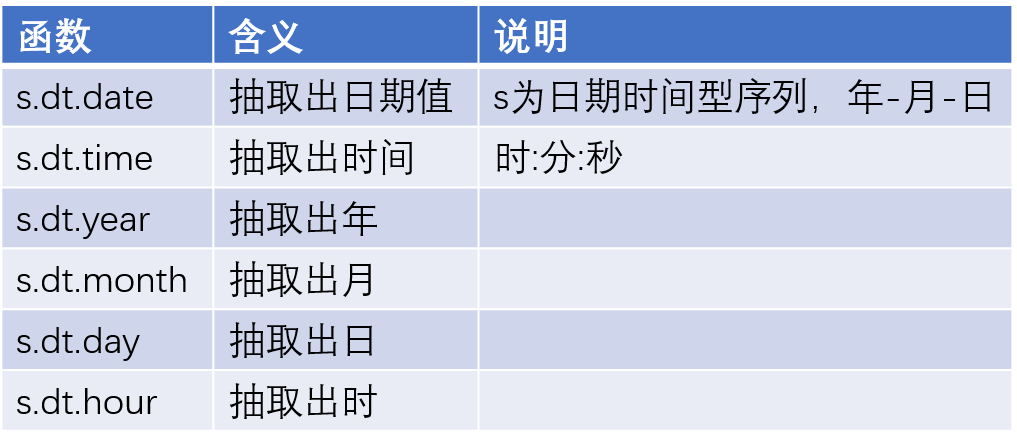
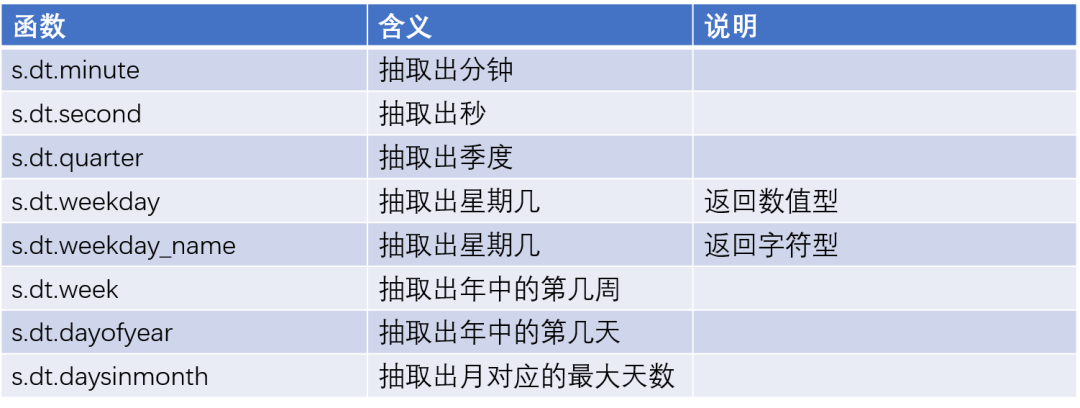
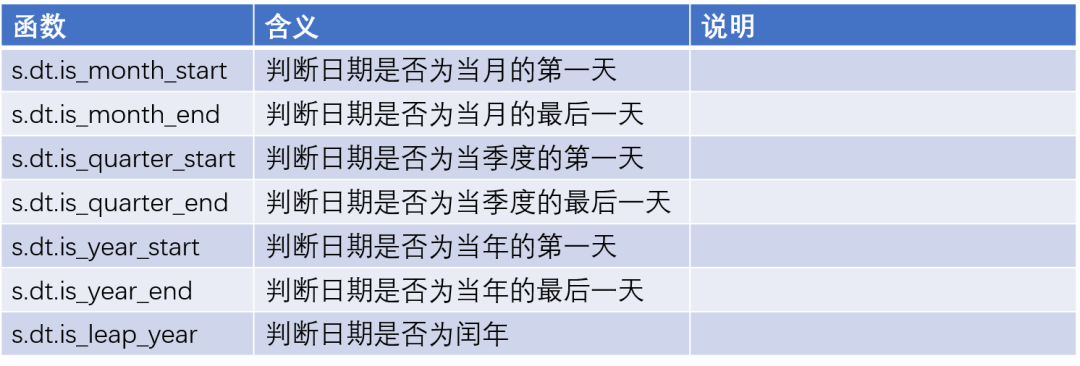
月份绘图函数
def month_count(year):
c9_data = data[data['date'].dt.year == year].groupby(data['date'].dt.month)
c9_data = c9_data.size().items()
x_data, y_data = [], []
for x in c9_data:
x_data.append(str(x[0]))
y_data.append(x[1])
c9 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="{}年按月地震次数曲线图".format(year)),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=True),
)
)
return c9
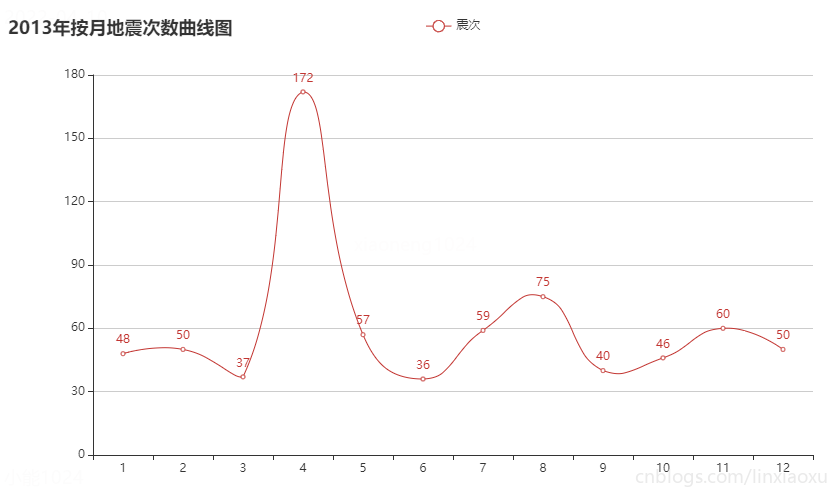
c9_1 = month_count(2013)
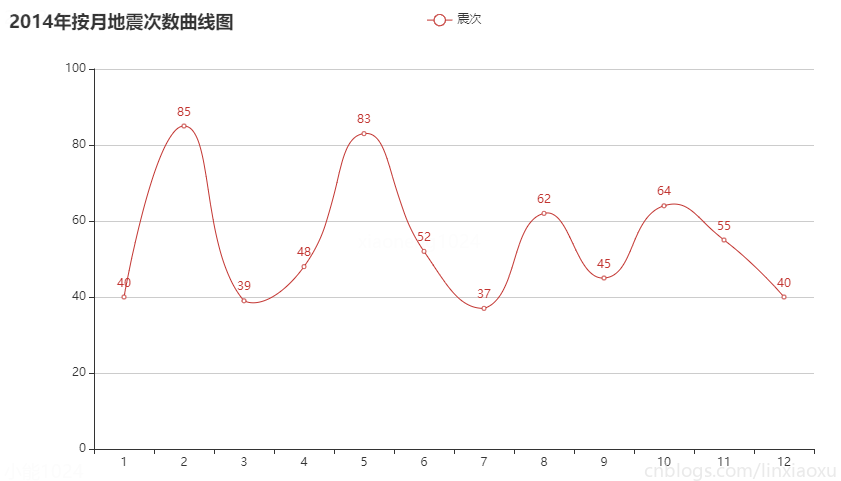
c9_2 = month_count(2014)
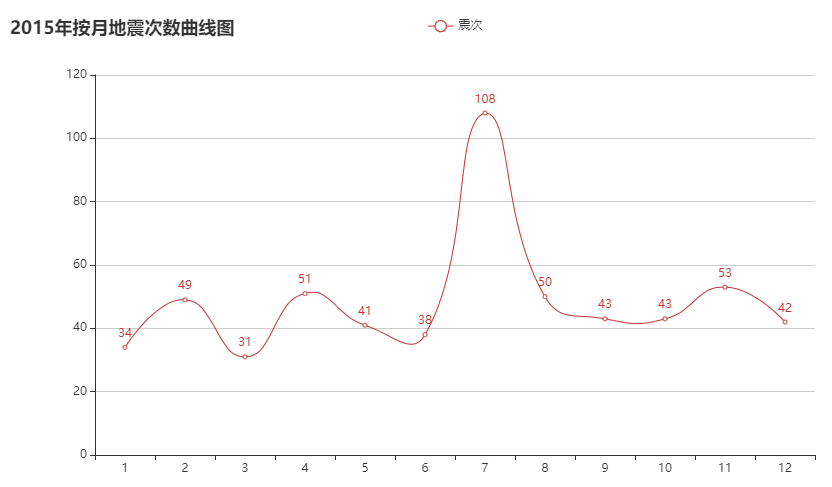
c9_3 = month_count(2015)
图表效果
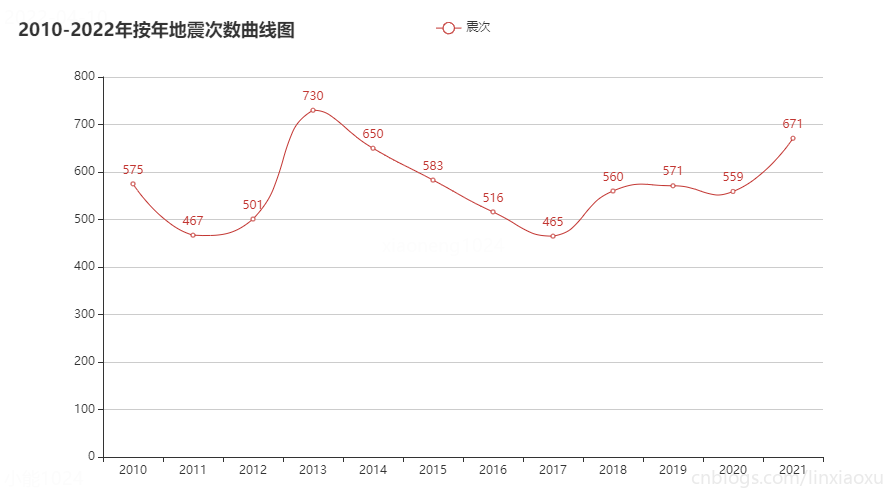
结论
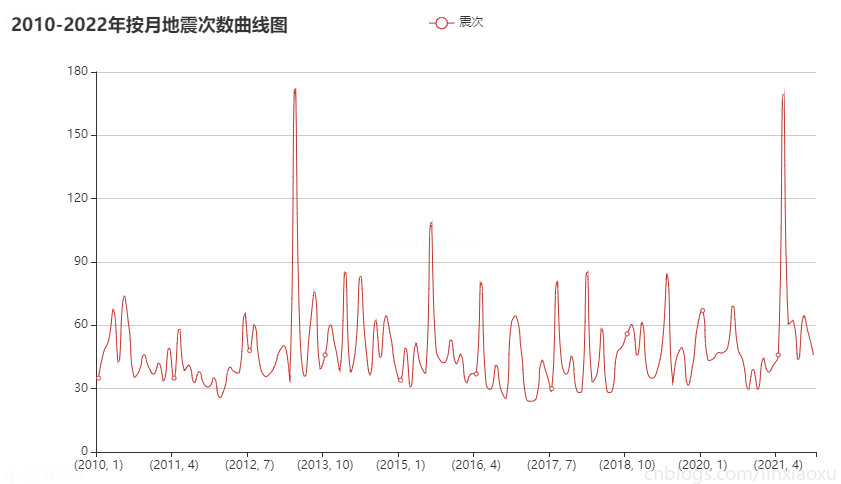
按月份来看每月地震次数在 30~90 次的范围波动。可通过方差判断各年月地震次数波动。
偶尔会有地震次数高峰期,可能是因为地壳活动过于强烈。
24小时段地震发生百分比图
绘图 pyecharts
Bar - Stack_bar_percent - Document (pyecharts.org)
# STEP 24小时段地震发生百分比图
c10_data = data.groupby(data['date'].dt.hour)
total = c10_data.size().sum()
c10_data = c10_data.size().items()
x_data, y_data = [], []
for x in c10_data:
x_data.append(str(x[0]))
y_data.append({"value": x[1], "percent": x[1]/total})
c10 = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(x_data)
.add_yaxis("震次", y_data, category_gap="50%")
.set_series_opts(
label_opts=opts.LabelOpts(
position="top",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="24小时段地震发生百分比图"),
)
)
这里引入了 \(Jscode\) 特殊化要显示的标签。前面数据我们需要获取到字典数组。\(total\) 实际上是在计算行数。
图表效果
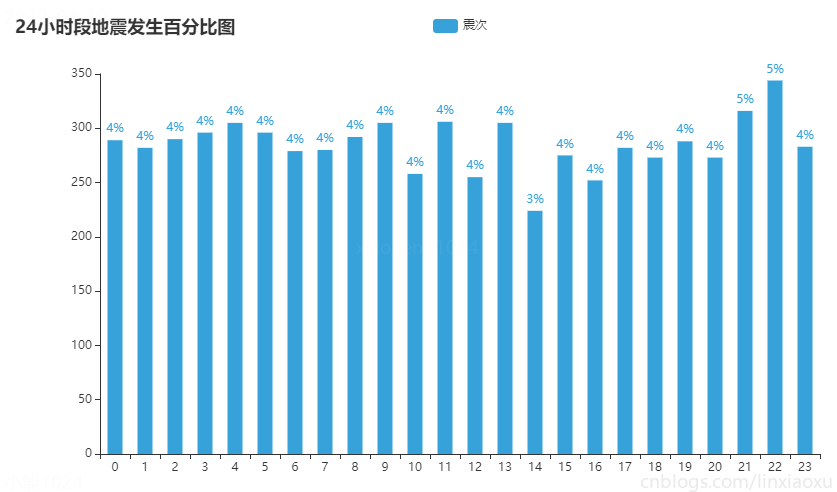
结论
- 每个时间段发生的地震次数较为均匀,没有出现比较大的差别。
最大震级与平均震级折线图
绘图 pyecharts
Line - Line_base - Document (pyecharts.org)
# STEP 2010-2022年最大震级与平均震级折线图
c11_data = data.groupby(data['date'].dt.year)
x_data, y1_data, y2_data = [], [], []
for name, group in c11_data:
x_data.append(str(name)) # IMPORTANT
y1_data.append(group['level'].max())
y2_data.append(round(group['level'].mean(), 2))
print(x_data, y1_data, y2_data)
c11 = (
Line()
.add_xaxis(x_data)
.add_yaxis("最大震级", y1_data, linestyle_opts=opts.LineStyleOpts(width=2),)
.add_yaxis("平均震级", y2_data, linestyle_opts=opts.LineStyleOpts(width=2),)
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年最大震级与平均震级折线图"))
)
opts.LineStyleOpts(width=2) 设置线条宽度。
图表效果
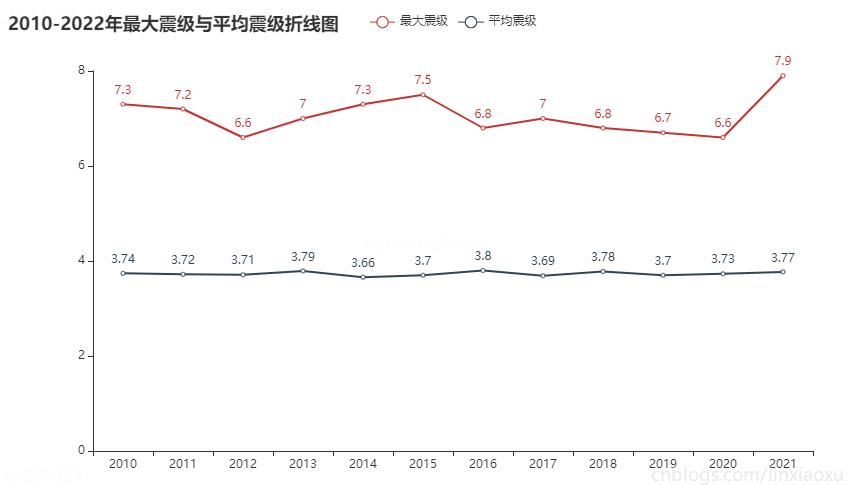
结论
- 每年平均震级均在 3.7 级左右,数值比较稳定,基本成一条直线。
- 每年最大震级均在 6 级以上,在 7 级左右。
震源、震级基本信息
# STEP info 基本信息
info_data = data.describe()
depth_data = info_data['depth']
headers = depth_data.index.to_list()
rows = [[str(round(x, 2)) for x in depth_data.values]]
depth_info = Table().add(headers, rows).set_global_opts(
title_opts=ComponentTitleOpts(title="震源深度信息")
)
level_data = info_data['level']
headers = level_data.index.to_list()
rows = [[str(round(x, 2)) for x in level_data.values]]
level_info = Table().add(headers, rows).set_global_opts(
title_opts=ComponentTitleOpts(title="震级信息")
\(rows\) 必须是二维数组,且元素应该是字符串。


工程下载
数据集
图表
代码
Python 国家地震台网中心地震数据集完整分析、pyecharts、plotly,分析强震次数、震级分布、震级震源关系、发生位置、发生时段、最大震级、平均震级的更多相关文章
- Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图 ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
- 国家授时中心的NTP服务器地址 210.72.145.44
国家授时中心的NTP服务器地址 210.72.145.44
- x264源代码简单分析:宏块分析(Analysis)部分-帧间宏块(Inter)
===================================================== H.264源代码分析文章列表: [编码 - x264] x264源代码简单分析:概述 x26 ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- django源码分析——本地runserver分析
本文环境python3.5.2,django1.10.x系列 1.根据上一篇文章分析了,django-admin startproject与startapp的分析流程后,根据django的官方实例此时 ...
- 常用 Java 静态代码分析工具的分析与比较
常用 Java 静态代码分析工具的分析与比较 简介: 本文首先介绍了静态代码分析的基 本概念及主要技术,随后分别介绍了现有 4 种主流 Java 静态代码分析工具 (Checkstyle,FindBu ...
- Memcached源代码分析 - Memcached源代码分析之消息回应(3)
文章列表: <Memcached源代码分析 - Memcached源代码分析之基于Libevent的网络模型(1)> <Memcached源代码分析 - Memcached源代码分析 ...
随机推荐
- Skye无人机刷Betaflight详细图文教程
前言 首先十分感谢B站TASKBL up主的视频教程以及他的耐心指导,视频链接Skye 原机主板刷BetaFlight 参考教程_哔哩哔哩_bilibili.整个改造过程耗时三天,现把改造过程以及遇 ...
- Java有没有goto?
goto是Java中的保留字,暂时还不是Java的关键字.
- 阐述 ArrayList、Vector、LinkedList 的存储性能和特性?
ArrayList 和 Vector 都是使用数组方式存储数据,此数组元素数大于实际存储的 数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉 及数组元素移动等内存操作,所以索引数 ...
- Dubbo 如何停机?
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才 会执行.
- 构造器注入和 setter 依赖注入,那种方式更好?
每种方式都有它的缺点和优点.构造器注入保证所有的注入都被初始化,但是 setter 注入提供更好的灵活性来设置可选依赖.如果使用 XML 来描述依赖, Setter 注入的可读写会更强.经验法则是强制 ...
- 学习FastDfs(一)
一.简介 FastDFS是一个开源的轻量级分布式文件系统,由跟踪服务器(tracker server).存储服务器(storage server)和客户端(client)三个部分组成 fastfds有 ...
- MySQL怎么用命令修改字段名
一.SQL MySQL怎么用命令修改字段名的 -- alter table 表名 change 旧属性 新属性 新的数据类型 ==>(可以不写) COMMENT '备注' ALTER TABLE ...
- (stm32f103学习总结)—printf重定向
一.printf重定向简介 我们知道C语言中printf函数默认输出设备是显示器,如果要实现在 串口或者LCD上显示,必须重定义标准库函数里调用的与输出设备相关的函数.比如使用printf输出到串口, ...
- git提交错误 git config --global user.email “you@example.com“ git config --global user.name “Your Name
1 Commit failed - exit code 128 received, with output: '*** Please tell me who you are. 2 3 Run 4 5 ...
- transformjs 污染了 DOM?是你不了解它的强大
原文链接:https://github.com/AlloyTeam/AlloyTouch/wiki/Powerful-transformjs 写在前面 上星期在React微信群里,有小伙伴觉得tran ...