决策树3:基尼指数--Gini index(CART)


既能做分类,又能做回归。
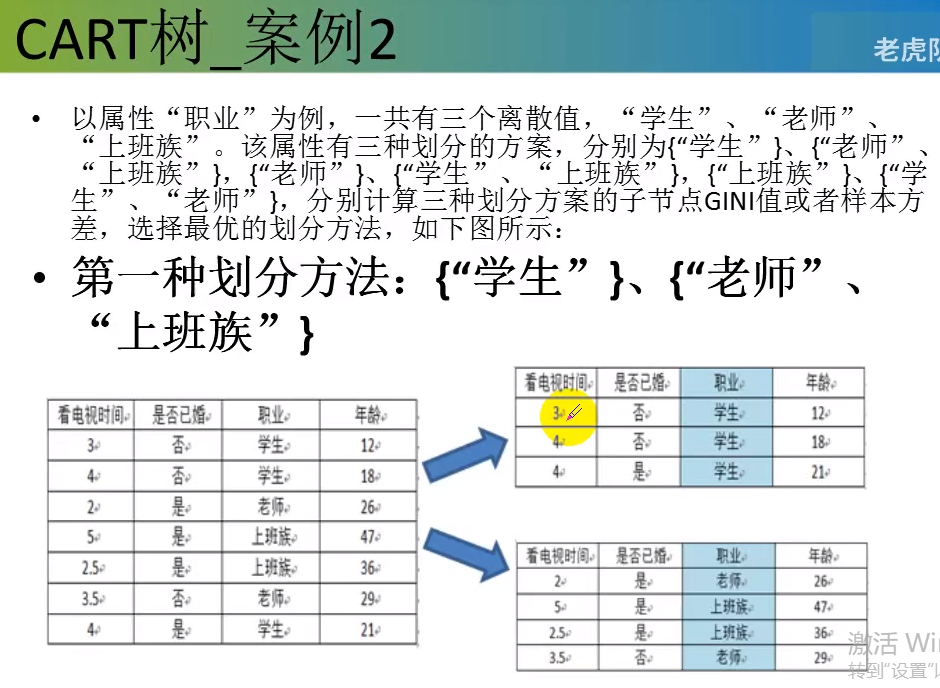
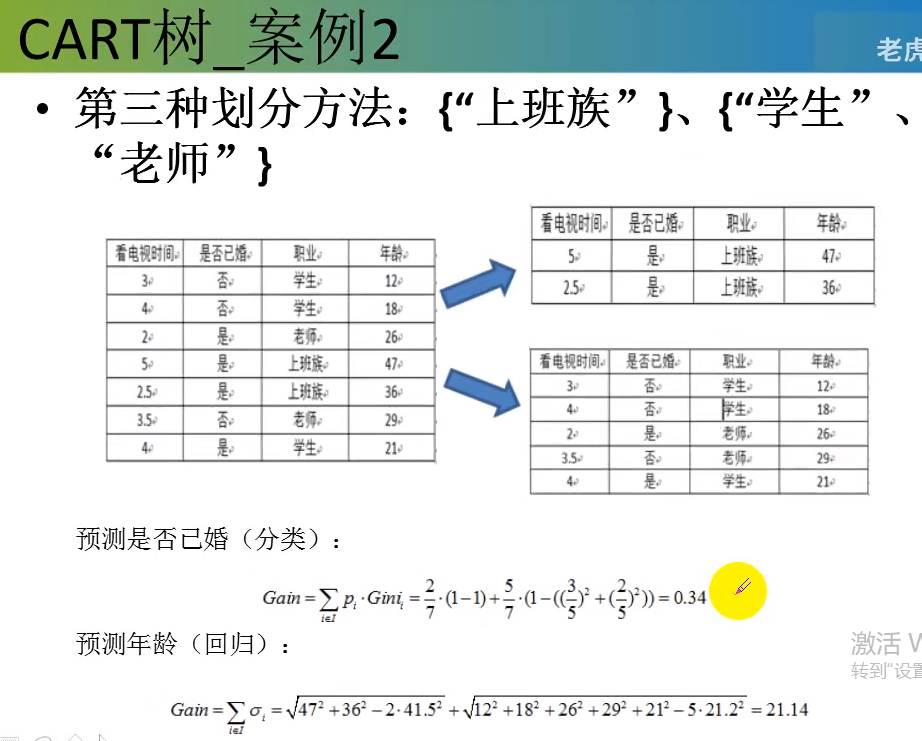
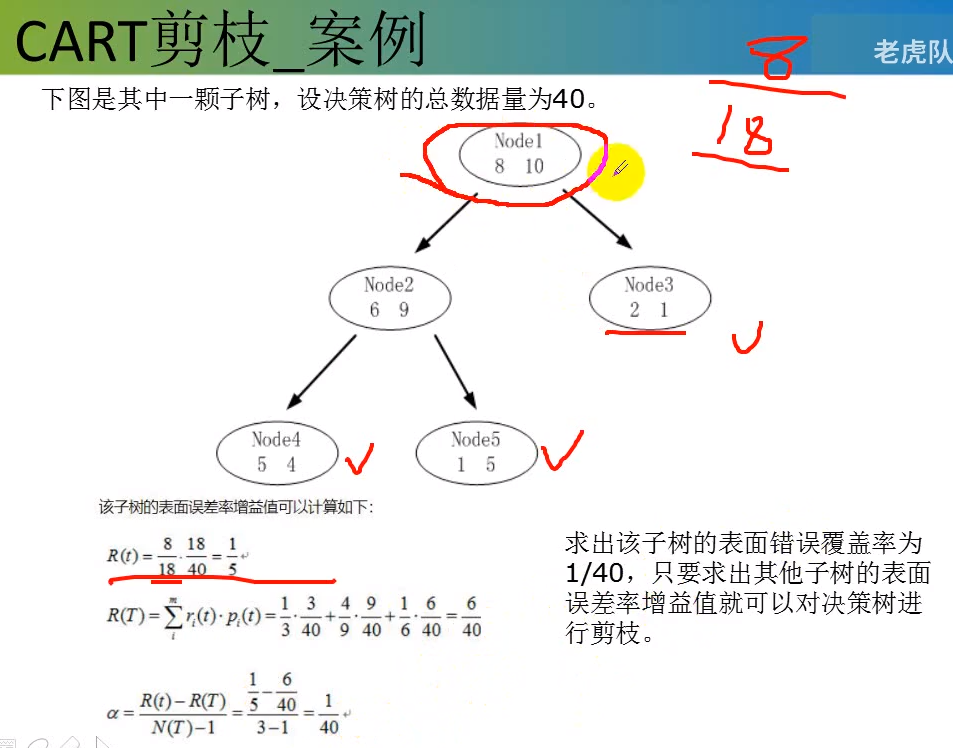
分类:基尼值作为节点分类依据。
回归:最小方差作为节点的依据。


节点越不纯,基尼值越大,熵值越大
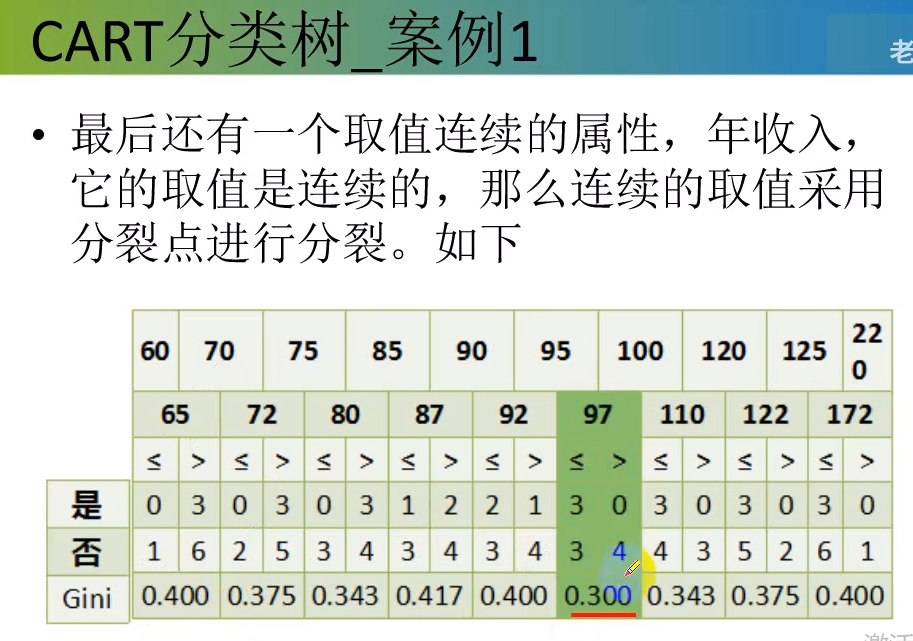
pi表示在信息熵部分中有介绍,如下图中介绍



方差越小越好。




选择最小的那个0.3



代码:
#整个c4.5决策树的所有算法:
import numpy as np
import operator def creatDataSet():
"""
outlook-> 0:sunny | 1:overcast | 2:rain
temperature-> 0:hot | 1:mild | 2:cool
humidity-> 0:high | 1:normal
windy-> 0:false | 1:true
"""
dataSet = np.array([[0, 0, 0, 0, 'N'],
[0, 0, 0, 1, 'N'],
[1, 0, 0, 0, 'Y'],
[2, 1, 0, 0, 'Y'],
[2, 2, 1, 0, 'Y'],
[2, 2, 1, 1, 'N'],
[1, 2, 1, 1, 'Y']])
labels = np.array(['outlook', 'temperature', 'humidity', 'windy'])
return dataSet, labels def createTestSet():
"""
outlook-> 0:sunny | 1:overcast | 2:rain
temperature-> 0:hot | 1:mild | 2:cool
humidity-> 0:high | 1:normal
windy-> 0:false | 1:true
"""
testSet = np.array([[0, 1, 0, 0],
[0, 2, 1, 0],
[2, 1, 1, 0],
[0, 1, 1, 1],
[1, 1, 0, 1],
[1, 0, 1, 0],
[2, 1, 0, 1]])
return testSet def dataset_entropy(dataset):
"""
计算数据集的信息熵
"""
classLabel=dataset[:,-1]
labelCount={}
for i in range(classLabel.size):
label=classLabel[i]
labelCount[label]=labelCount.get(label,0)+1 #将所有的类别都计算出来了
#熵值(第一步)
cnt=0
for k,v in labelCount.items():
cnt += -v/classLabel.size*np.log2(v/classLabel.size) return cnt #接下来切分,然后算最优属性
def splitDataSet(dataset,featureIndex,value):
subdataset=[]
#迭代所有的样本
for example in dataset:
if example[featureIndex]==value:
subdataset.append(example)
return np.delete(subdataset,featureIndex,axis=1) def classLabelPi(dataset):
#多叉树
classLabel=dataset[:,-1]
labelCount={}
for i in range(classLabel.size):
label=classLabel[i]
labelCount[label]=labelCount.get(label,0)+1
valueList=list(labelCount.values())
sum=np.sum(valueList)
pi=0
for i in valueList:
pi+=(i/sum)**2
return pi def chooseBestFeature(dataset,labels):
"""
选择最优特征,但是特征是不包括名称的。
如何选择最优特征:增益率最小
"""
#特征的个数
featureNum=labels.size
baseEntropy=dataset_entropy(dataset)
#设置最大增益值
maxRatio,bestFeatureIndex=0,None
#样本总数
n=dataset.shape[0]
#最小基尼值
minGini=1
for i in range(featureNum):
#指定特征的条件熵
featureEntropy=0
gini=0
#返回所有子集
featureList=dataset[:,i]
featureValues=set(featureList)
for value in featureValues:
subDataSet=splitDataSet(dataset,i,value)
pi=subDataSet.shape[0]/n
gini+=pi*(1-classLabelPi(subDataSet))
if minGini > gini:
minGini=gini
bestFeatureIndex=i
return bestFeatureIndex #最佳增益 def mayorClass(classList):
labelCount={}
for i in range(classList.size):
label=classList[i]
labelCount[label]=labelCount.get(label,0)+1
sortedLabel=sorted(labelCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedLabel[0][0] def createTree(dataset,labels):
"""
参考hunt算法那张图片
"""
classList=dataset[:,-1]
if len(set(dataset[:,-1]))==1:
return dataset[:,-1][0] #返回类别
if labels.size==0 or len(dataset[0])==1: #条件熵最少的一定是类别最多的
#条件熵算不下去的时候,
return mayorClass(classList)
bestFeatureIndex=chooseBestFeature(dataset,labels)
bestFeature=labels[bestFeatureIndex]
dtree={bestFeature:{}} #用代码表示这棵树
featureList=dataset[:,bestFeatureIndex]
featureValues=set(featureList)
for value in featureValues:
subdataset=splitDataSet(dataset,bestFeatureIndex,value)
sublabels=np.delete(labels,bestFeatureIndex)
dtree[bestFeature][value]=createTree(subdataset,sublabels) #将原始的labels干掉一列
return dtree def predict(tree,labels,testData):
#分类,预测
rootName=list(tree.keys())[0]
rootValue=tree[rootName]
featureIndex =list(labels).index(rootName)
classLabel=None
for key in rootValue.keys():
if testData[featureIndex]==int(key):
if type(rootValue[key]).__name__=="dict":
classLabel=predict(rootValue[key],labels,testData) #递归
else:
classLabel=rootValue[key]
return classLabel def predictAll(tree,labels,testSet):
classLabels=[]
for i in testSet:
classLabels.append(predict(tree,labels,i))
return classLabels if __name__ == "__main__":
dataset,labels=creatDataSet()
# print(dataset_entropy(dataset)
# s=splitDataSet(dataset,0)
# for item in s:
# print(item)
tree=createTree(dataset,labels)
testSet=createTestSet()
print(predictAll(tree,labels,testSet))
····························································
输出:
['N', 'N', 'Y', 'N', 'Y', 'Y', 'N']



决策树3:基尼指数--Gini index(CART)的更多相关文章
- Python实现CART(基尼指数)
Python实现CART(基尼指数) 运行环境 Pyhton3 treePlotter模块(画图所需,不画图可不必) matplotlib(如果使用上面的模块必须) 计算过程 st=>start ...
- B-经济学-基尼指数
目录 基尼指数 一.基尼指数简介 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/ni ...
- (二)《机器学习》(周志华)第4章 决策树 笔记 理论及实现——“西瓜树”——CART决策树
CART决策树 (一)<机器学习>(周志华)第4章 决策树 笔记 理论及实现——“西瓜树” 参照上一篇ID3算法实现的决策树(点击上面链接直达),进一步实现CART决策树. 其实只需要改动 ...
- 决策树(上)-ID3、C4.5、CART
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可全面了解决策树): 1.https://zhuanlan.zhihu.com/p/85731206 2.https://zhuanla ...
- 【机器学习速成宝典】模型篇06决策树【ID3、C4.5、CART】(Python版)
目录 什么是决策树(Decision Tree) 特征选择 使用ID3算法生成决策树 使用C4.5算法生成决策树 使用CART算法生成决策树 预剪枝和后剪枝 应用:遇到连续与缺失值怎么办? 多变量决策 ...
- 机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点. 决策树:是一种基本的分类和回归方法.在分类问题中,是基于特征对实例进行分类.既可以认为是if-then ...
- 决策树之ID3,C4.5及CART
决策树的基本认识 决策树学习是应用最广的归纳推理算法之一,是一种逼近离散值函数的方法,年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它 ...
- Theoretical comparison between the Gini Index and Information Gain criteria
Knowledge Discovery in Databases (KDD) is an active and important research area with the promise for ...
- 多分类度量gini index
第一份工作时, 基于 gini index 写了一份决策树代码叫ctree, 用于广告推荐. 今天想起来, 好像应该有开源的其他方法了. 参考 https://www.cnblogs.com/mlhy ...
随机推荐
- elasticsearch7.8.0,kibana7.8.0安装
目录 Windows下安装Elasticsearch Linux下安装Elasticsearch docker下安装Elasticsearch Kibana安装 chrome ElasticSearc ...
- cmd:WIN7操作系统下cmd窗口下的复制粘贴
1.右击cmd的顶部栏,点开属性 2.在 选项 下,勾选"快速编辑模式" 3.按住鼠标左键标注需要复制的区域 再点击一下右键,则上文的标记区域就已经被复制了,可以通过ctrl+v进 ...
- HarmonyOS UI组件在线预览,程序员直呼“不要太方便~”
一.介绍 以往大家如果想查看组件的使用效果,需要打开DevEco Studio构建工程.现在为了便于大家高效开发,文档上线了JS UI组件在线预览功能,无需本地构建工程,在线即可修改组件样式等参数.一 ...
- 联邦学习:按混合分布划分Non-IID样本
我们在博文<联邦学习:按病态独立同分布划分Non-IID样本>中学习了联邦学习开山论文[1]中按照病态独立同分布(Pathological Non-IID)划分样本. 在上一篇博文< ...
- 『现学现忘』Docker基础 — 12、通过RPM软件包方式安装Docker
CentOS环境下的Docker官方推荐的三种安装方式 yum安装方式 本地RPM安装方式 脚本安装方式 目录 1.下载Docker的RPM安装包 2.安装Docker 3.通过RPM安装包安装Doc ...
- php在windows上安装kafka扩展
一.下载kafka扩展包 链接:https://pecl.php.net/package/rdkafka 二.解压安装包 三.修改php.ini 复制librdkafka.dll 到php\php7. ...
- spring源码干货分享-对象创建详细解析(set注入和初始化)
记录并分享一下本人学习spring源码的过程,有什么问题或者补充会持续更新.欢迎大家指正! 环境: spring5.X + idea 建议:学习过程中要开着源码一步一步过 Spring根据BeanDe ...
- MYSQL安装后自带用户的作用
user表中host列的值的意义% 匹配所有主机localhost localhost不会被解析成IP地址,直接通过UNIXsocket连接127.0.0 ...
- BBS项目分布搭建四(点赞点踩及评论功能准备)
BBS项目分布搭建四(点赞点踩及评论功能) 1. 点赞点踩样式准备 # 在base.html文件中 head标签内 添加css模块: {% block css %} {% endblock %} # ...
- VuePress 博客优化之增加 Vssue 评论功能
前言 在 <一篇带你用 VuePress + Github Pages 搭建博客>中,我们使用 VuePress 搭建了一个博客,最终的效果查看:TypeScript 中文文档. 本篇讲讲 ...