论文解读(SAGPool)《Self-Attention Graph Pooling》
论文信息
论文标题:Self-Attention Graph Pooling
论文作者:Junhyun Lee, Inyeop Lee, Jaewoo Kang
论文来源:2019, ICML
论文地址:download
论文代码:download
1 Introduction
图池化三种类型:
- Topology based pooling;
- Hierarchical pooling;(使用所有从 GNN 获得的节点表示)
- Hierarchical pooling;
关于 Hierarchical pooling 聚类分配矩阵:
$\begin{array}{j}S^{(l)}=\operatorname{softmax}\left(\mathrm{GNN}_{l}\left(A^{(l)}, X^{(l)}\right)\right) \\A^{(l+1)}=S^{(l) \top} A^{(l)} S^{(l)}\end{array} \quad\quad\quad\quad(1)$
gPool 取得了与 DiffPool 相当的性能,gPool 需要的存储复杂度为 $\mathcal{O}(|V|+|E|)$,而 DiffPool 需要 $\mathcal{O}\left(k|V|^{2}\right)$,其中 $V$、$E$ 和 $k$ 分别表示顶点、边和池化率。gPool 使用一个可学习的向量 $p$ 来计算投影分数,然后使用这些分数来选择排名靠前的节点。投影得分由 $p$ 与所有节点的特征之间的点积得到。这些分数表示可以保留的节点的信息量。下面的公式大致描述了 gPool 中的池化过程:
$\begin{array}{l} y=X^{(l)} \mathbf{p}^{(l)} /\left\|\mathbf{p}^{(l)}\right\|\\ \mathrm{idx}=\operatorname{top}-\operatorname{rank}(y,\lceil k N\rceil)\\A^{(l+1)}=A_{\mathrm{idx}, \mathrm{idx}}^{(l)}\end{array} \quad\quad\quad\quad(2)$
2 Method
框架如下:
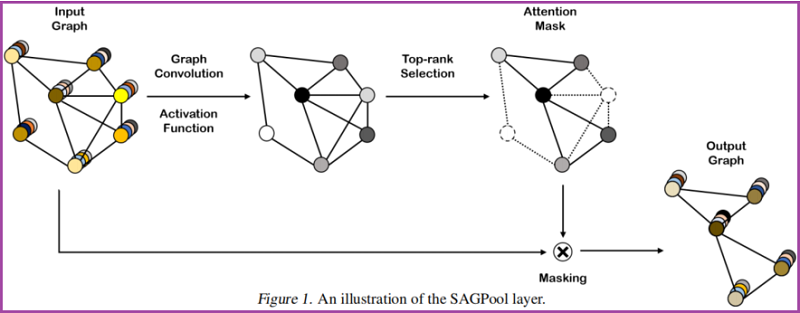
2.1. Self-Attention Graph Pooling
Self-attention mask
本文使用图卷积来获得自注意分数:
$Z=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} X \Theta_{a t t}\right) \quad\quad\quad\quad(3)$
其中,自注意得分 $Z \in \mathbb{R}^{N \times 1}$、邻接矩阵 $\tilde{A} \in \mathbb{R}^{N \times N}$、注意力参数矩阵 $\Theta_{a t t} \in \mathbb{R}^{F \times 1}$、特征矩阵 $X \in \mathbb{R}^{N \times F}$、度矩阵 $\tilde{D} \in \mathbb{R}^{N \times N}$。
这里考虑节点选择方法,即使输入不同大小和结构的图,也会保留输入图的部分节点。
$\begin{array}{l} \mathrm{idx}=\operatorname{top}-\operatorname{rank}(Z,\lceil k N\rceil)\\Z_{\text {mask }}=Z_{\mathrm{idx}}\end{array} \quad\quad\quad\quad(4)$
基于自注意得分 $Z$ ,选择保留前 $ \lceil k N\rceil$ 个节点,其中 $k \in(0,1]$ 代表着池化率(pooling ratio),$Z_{\text{mask}}$ 是 feature attention mask。。
Graph pooling
接着获得新特征矩阵和邻接矩阵:
$\begin{array}{l} X^{\prime}=X_{\mathrm{idx},:}\\X_{\text {out }}=X^{\prime} \odot Z_{\text {mask }}\\A_{\text {out }}=A_{\mathrm{idx}, \mathrm{idx}}\end{array} \quad\quad\quad\quad(5)$
其中,$\odot$ is the broadcasted elementwise product。
Variation of SAGPool
$Z=\sigma(\operatorname{GNN}(X, A)) \quad\quad\quad\quad(6)$
$Z=\sigma\left(\operatorname{GNN}\left(X, A+A^{2}\right)\right) \quad\quad\quad\quad(7)$
$Z=\sigma\left(\mathrm{GNN}_{2}\left(\sigma\left(\mathrm{GNN}_{1}(X, A)\right), A\right)\right) \quad\quad\quad\quad(8)$
$Z=\frac{1}{M} \sum_{m} \sigma\left(\mathrm{GNN}_{m}(X, A)\right) \quad\quad\quad\quad(9)$
2.2 Model Architecture
本节用来验证模块的有效性。
Convolution layer
图卷积 GCN:
$h^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} h^{(l)} \Theta\right) \quad\quad\quad\quad(10)$
与 $\text{Eq.3}$ 不同的是,$\Theta \in \mathbb{R}^{F \times F^{\prime}}$ 。
Readout layer
根据 JK-net architecture 的思想:
$s=\frac{1}{N} \sum_{i=1}^{N} x_{i} \| \max _{i=1}^{N} x_{i} \quad\quad\quad\quad(11)$
其中:
- $N$ 代表着节点的个数;
- $x_{i}$ 代表着第 $i$ 个节点的特征向量;
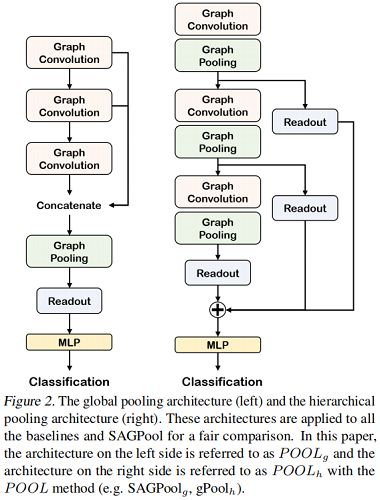
Global pooling architecture & Hierarchical pooling architecture
对比如下:
3 Experiments
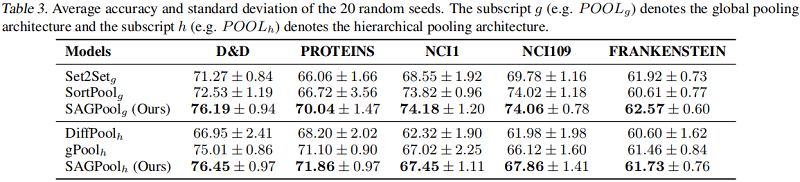
数据集

基线实验
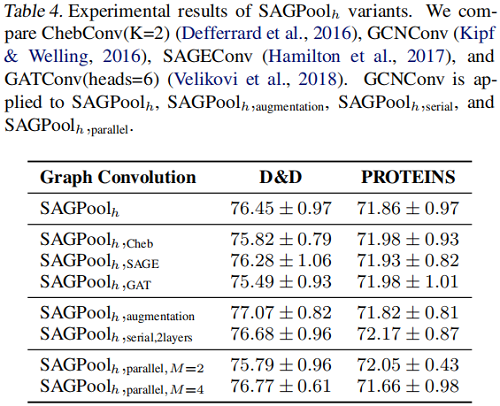
SAGPool 的变体
4 Conclusion
本文提出了一种基于自注意的SAGPool图池化方法。我们的方法具有以下特征:分层池、同时考虑节点特征和图拓扑、合理的复杂度和端到端表示学习。SAGPool使用一致数量的参数,而不管输入图的大小如何。我们工作的扩展可能包括使用可学习的池化比率来获得每个图的最优聚类大小,并研究每个池化层中多个注意掩模的影响,其中最终的表示可以通过聚合不同的层次表示来获得。
论文解读(SAGPool)《Self-Attention Graph Pooling》的更多相关文章
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读(ChebyGIN)《Understanding Attention and Generalization in Graph Neural Networks》
论文信息 论文标题:Understanding Attention and Generalization in Graph Neural Networks论文作者:Boris Knyazev, Gra ...
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
随机推荐
- Homebrew 卸载后重新安装mysql
1.卸载https://blog.csdn.net/liuxw1/article/details/81434005 https://jingyan.baidu.com/article/5553fa82 ...
- Dubbo telnet 命令能做什么?
dubbo 服务发布之后,我们可以利用 telnet 命令进行调试.管理. Dubbo2.0.5 以上版本服务提供端口支持 telnet 命令 连接服务 telnet localhost 20880 ...
- Redis 常见性能问题和解决方案?
1.Master 最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave 函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性 暂停服务 2.如果数据 ...
- 学习docker(三)
一.Docker介绍 1.docker容器 docker是宿主机的一个进程,通过namespace实现了资源隔离,通过cgroup实现了资源限制, 通过写时复制技术(copy-on-write)实现了 ...
- EMC EMI EMS定义与区别
一.EMC EMI EMS定义: EMC(ElectromagneticCompatibility) 电磁兼容,是指设备或系统在电磁环境中性能不降级的状态.电磁兼容,一方面要求系统内没有严重的干扰源, ...
- iView 一周年了,同时发布了 2.0 正式版,但这只是开始...
两年前,我开始接触 Vue.js 框架,当时就被它的轻量.组件化和友好的 API 所吸引.之后我将 Vue.js 和 Webpack 技术栈引入我的公司(TalkingData)可视化团队,并经过一年 ...
- 惠普电脑win10系统中WLAN不见了
原文链接:笔记本电脑win10系统中WLAN不见了 怎么解决? - 知乎 (zhihu.com)
- Android的Activity屏幕切换动画左右滑动切换
在Android开发过程中,经常会碰到Activity之间的切换效果的问题,下面介绍一下如何实现左右滑动的切换效果,首先了解一下Activity切换的实现,从Android2.0开始在Activity ...
- ubantu14.04搜狗拼音安装
1. 先卸载fcitx: sudo apt-get purge fcitx*2. 安装fcitx和libssh2-1: sudo apt-get install fcitx 和 sudo apt-ge ...
- Python找出列表中的最大数和最小数
Python找出列表中数字的最大值和最小值 思路: 先使用冒泡排序将列表中的数字从小到大依次排序 取出数组首元素和尾元素 运行结果: 源代码: 1 ''' 2 4.编写函数,功能:找出多个数中的最大值 ...