深入浅出理解SVM支持向量机算法
支持向量机是Vapnik等人于1995年首先提出的,它是基于VC维理论和结构风险最小化原则的学习机器。它在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在一定程度上克服了“维数灾难”和“过学习”等传统困难,再加上它具有坚实的理论基础,简单明了的数学模型,使得支持向量机从提出以来受到广泛的关注,并取得了长足的发展 。支持向量机(Support Vector Machine, SVM)本身是一个二元分类算法,是对感知机算法模型的一种扩展,现在的 SVM 算法支持线性分类和非线性分类的分类应用,并且也能够直接将 SVM 应用于回归应用中,同时通过 OvR 或者 OvO 的方式我们也可以将 SVM 应用在多元分类领域中。在不考虑集成学习算法,不考虑特定的数据集的时候,在分类算法中 SVM 可以说是特别优秀的。 ## SVM算法思想 支持向量机最初是在模式识别中提出的。假定训练样本集合(xi, yi),i-1,… ,l, xi∈R ,y∈{-1,+1},可以被超平面x·w+b=0无错误地分开 ,并且离超平面最近的向量离超平面的距离是最大的 ,则这个超平面称为最优超平面。 对于下图哪条分界线最好,这便是SVM要解决的问题
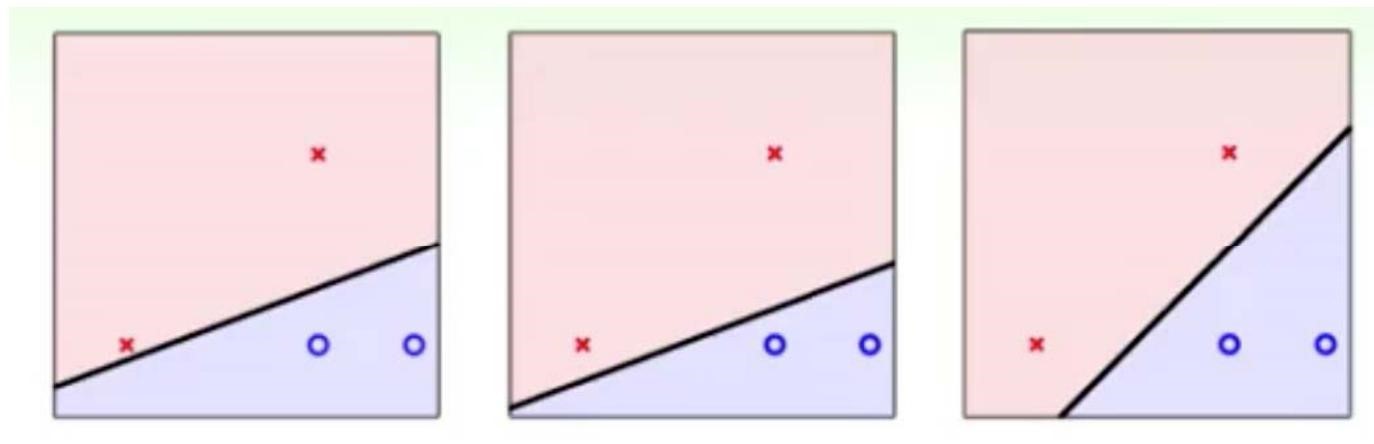
假设未来拿到的数据含有一部分噪声,那么不同的超平面对于噪声的容忍度是不同的,最右边的线是最 robust 的。
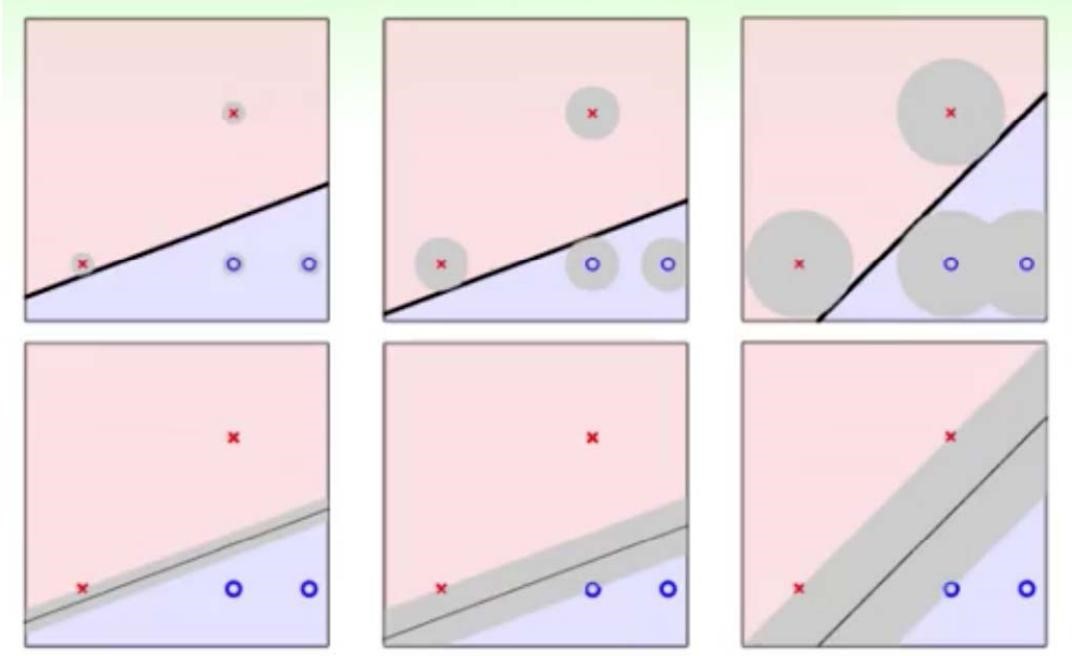
所以说我们只要让离超平面比较近的点尽可能的远离这个超平面,那么我们的模型分类效果应该就会比较不错。SVM 其实就是这个思想。
函数间隔
在超平面确定的情况下,
可以相对地表示点
距离超平面的远近。对于两类分类问题,如果
,则
的类别被判定为1;否则判定为-1。所以如果
,则认为
的分类结果是正确的,否则是错误的。且
的值越大,分类结果的确信度越大。反之亦然。所以样本点
与超平面
之间的函数间隔定义为
。但是该定义存在问题:即
和
同时缩小或放大M倍后,超平面并没有变化,但是函数间隔却变化了。所以,需要将
的大小固定,如
,使得函数间隔固定。这时的间隔也就是几何间隔 。
几何间隔
定义超平面关于样本点(xi,yi)的几何间隔为:
实际上,几何间隔就是点到超平面的距离。想像下中学学习的点到直线
的距离公式:
所以在二维空间中,几何间隔就是点到直线的距离。在三维及以上空间中,就是点到超平面的距离。而函数距离,就是上述距离公式中的分子,即未归一化的距离。
定义训练集到超平面的最小几何间隔是:
可以发现函数间隔与几何间隔有如下关系:

当我们取分母即W的L2范数为1时,函数间隔和几何间隔相等。
如果超平面参数w和b成比例地改变(超平面没有改变),函数间隔也按此比例改变,而几何间隔不变。
SVM训练分类器的方法是寻找到超平面,使正负样本在超平面的两侧,且样本到超平面的几何间隔最大。所以SVM可以表述为求解下列优化问题:
以上关于间隔问题在《统计学习方法》中有详细讲解
线性可分支持向量机
给定一个线性可分的训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为:
w · x + b = 0
决策函数为:
f(x)=sign(wx+b)
在二维空间上,两类点被一条直线完全分开叫做线性可分。
硬间隔最大化
我们寻找的超平面应当满足:这个超平面不仅可以将数据集中的所有正负实例点分开,而且对最难区分的实例点(离超平面最近的点,也就是支持向量)也有足够大的间隔将它们分开。
寻找几何间隔最大的分离超平面问题可表示为下面的约束最优化问题:
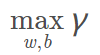
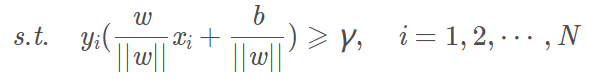
即我们要最大化超平面关于数据集T的几何间隔γ,约束条件则表示训练集中每个点与超平面的几何间隔都大于等于γ。
事实上我们就是要找到一对支持向量(一正例一负例两个样本点,超平面在这两个点的正中间,使得超平面对两个点的距离最远),同时这个超平面对于更远处的其他所有正负实例点都能正确区分。
可将上式的几何间隔用函数间隔表示,这个问题可改写为:
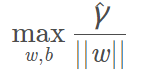
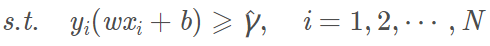
此时如果我们将w和b放大λ倍,那么右边的函数间隔也会放大λ倍。也就是说约束条件左右两边都整体放大了λ倍,对不等式约束没有影响。因此,我们不妨取:
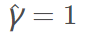
取1是为了方便推导和优化,且这样做对目标函数的优化没有影响。
那么上面的最优化问题变为:
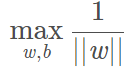
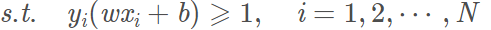
最大化1/||w||与最小化(1/2)||w||2是等价的,乘以1/2是为了后面求导时计算方便。
则我们可以得到下面的线性可分支持向量机学习的最优化问题:
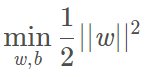

线性可分支持向量机的原始问题转化为对偶问题
我们将上面最优化问题称之为原始问题
我们可以列出一个拉格朗日函数来求解原始问题。我们定义拉格朗日函数为:
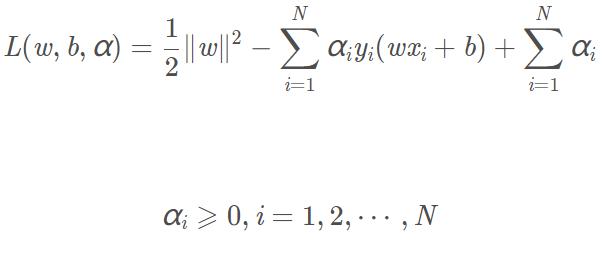
原始问题是一个极小极大问题

直接求原始问题并不好解,我们可以应用拉格朗日对偶性,通过求解对偶问题来得到原始问题的最优解。
对偶问题求解过程
根据拉格朗日对偶性,对偶问题是极大极小问题,即求:
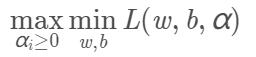
对偶问题的求解过程:
先对L(w,b,α)求对w、b的极小。我们需要求L对w、b的偏导数并令其为0。
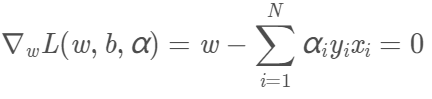
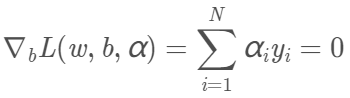
得到两个等式:

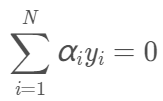
将上面两式代入拉格朗日函数,得:
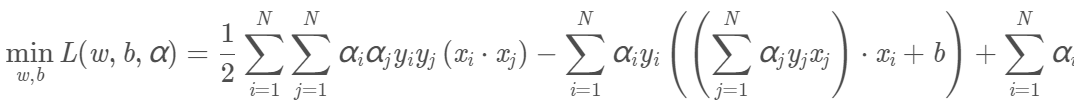
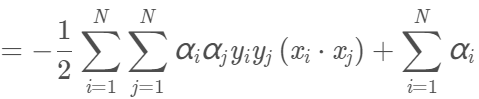
再求min L(w,b,α)对α的极大,即:

我们将上面第一个式子乘以-1,即可得到等价的对偶最优化问题:
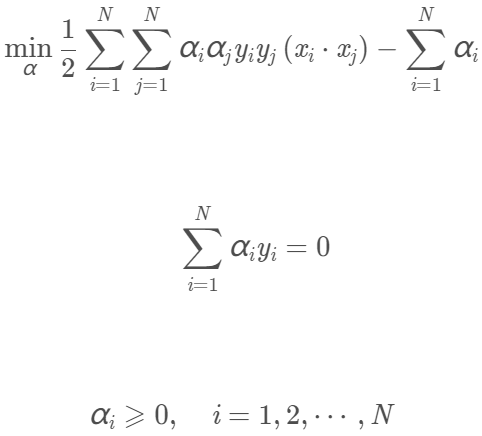
我们可以求出上面问题对α的解向量(α即为所有拉格朗日乘子)为:
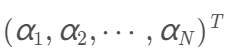
则按上面求L对w、b的偏导数并令其为0得到的等式,我们可得:
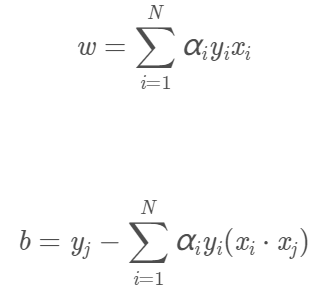
那么超平面就为
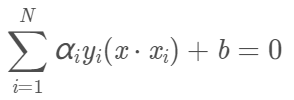
决策函数为
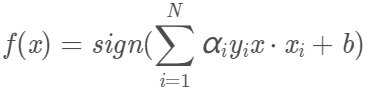
我们注意到对原始的最优化问题:
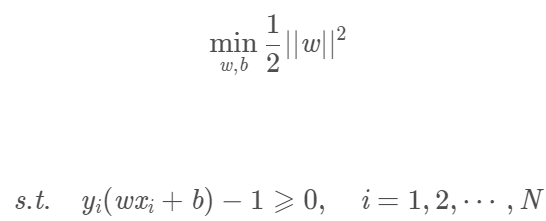
有不等式约束,因此上述过程必须满足KKT条件:
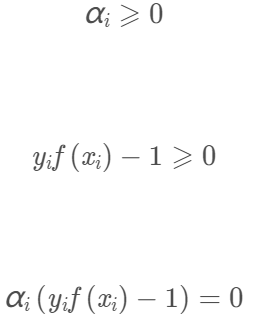
线性支持向量机
我们经常遇到这样的情况:数据集T中大部分数据线性可分,但有少部分数据线性不可分,这时使用上面的线性可分支持向量机并不可行。这时我们就要使用学习策略为软间隔最大化的线性支持向量机。
软间隔最大化
所谓软间隔最大化,就是在硬间隔最大化的基础上,对每个样本点(xi,yi)引进一个松弛变量ξi,于是我们的约束不等式变为:
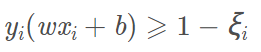
同时,我们的目标函数中对每个松弛变量ξi需要支付一个代价ξi
即目标函数变为:

这里C>0称为惩罚参数。C较大时对误分类的惩罚增大,C较小时对误分类的惩罚减小。
上面的目标函数包含两层含义:一是使间隔尽量大,二是使误分类点的个数尽量小。
松弛变量ξi表示xi在超平面下不符合真实分类,但是与超平面距离<ξi,因此我们将其归到另一类(也就是真实分类)。松弛变量用来解决异常点,它可以"容忍"异常点在错误的区域,使得支持向量机计算出的超平面不至于产生过拟合的问题,但同时,我们又不希望松弛变量太大导致超平面分类性能太差。
线性支持向量机的原始问题转化为对偶问题
原始问题
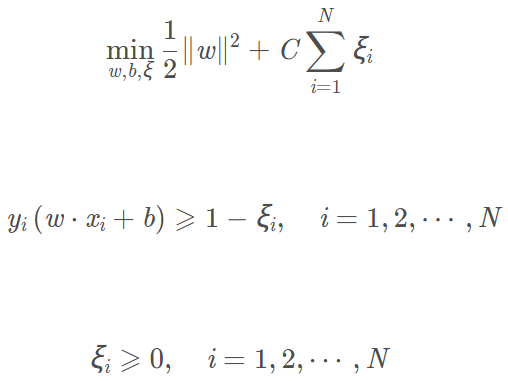
对偶问题及解题过程
原始问题的对偶问题为:
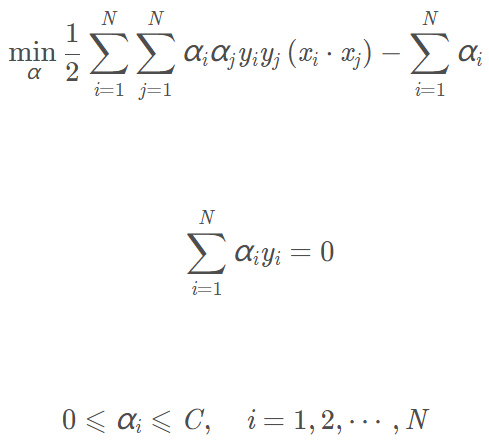
拉格朗日函数为:
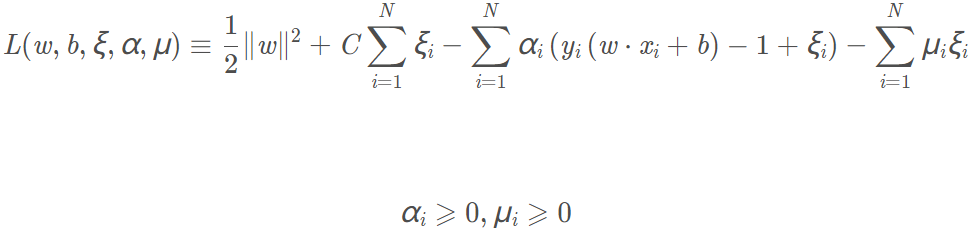
类似的,先求L对w、b、ξ的极小,求L对w、b、ξ的偏导数并令偏导数为0,最后得:
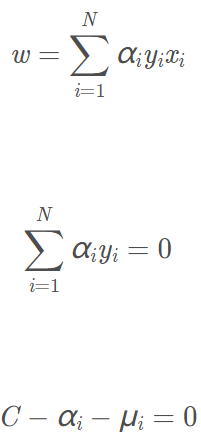
上面三式代回L,得:
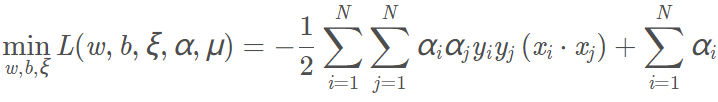
再对上式求α的极大,得到对偶问题:
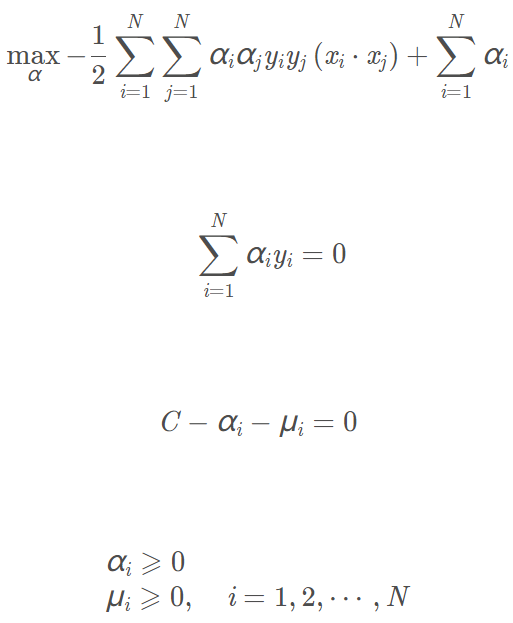
设
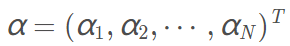
是上面对偶问题的拉格朗日乘子的解,那么有:
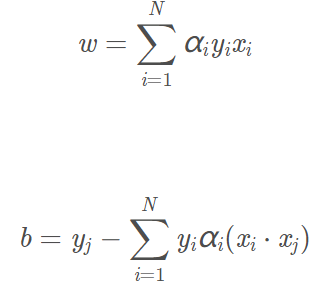
那么超平面为:
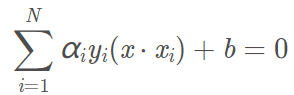
决策函数为:
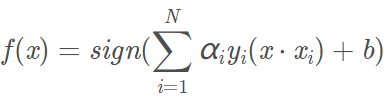
非线性支持向量机
如果我们的数据集样本是非线性可分的,我们可以使用一个映射将样本从原始空间映射到一个合适的高维空间,在这个高维空间中数据集线性可分。
核函数(Kernel Function)
设X是输入空间,H是特征空间(即高维空间),如果存在一个映射:
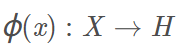
使得
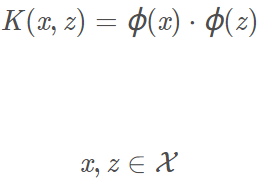
那么称K(x,z)为核函数。Φ(x)为映射函数,等式右边是内积。
常用的核函数:
1. Linear Kernel
线性核是最简单的核函数,核函数的数学公式:k(x, y) = xt · y
2. Polynomial Kernel
多项式核实一种非标准核函数,它非常适合于正交归一化后的数据,其具体形式:k(x, y) = (axt y+c)d 比较好用的,就是参数比较多,但是还算稳定
3. Gaussian Kernel
这里说一种经典的鲁棒径向基核,即高斯核函数,鲁棒径向基核对于数据中的噪音有着较好的抗干扰能力,其参数决定了函数作用范围,超过了这个范围,数据的作用就“基本消失”。高斯核函数是这一族核函数的优秀代表,也是必须尝试的核函数,其数学形式如下:
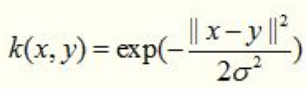
虽然被广泛使用,但是这个核函数的性能对参数十分敏感
4. Exponential Kernel
指数核函数就是高斯核函数的变种,它仅仅是将向量之间的L2距离调整为L1距离,这样改动会对参数的依赖性降低,但是适用范围相对狭窄。其数学形式如下:
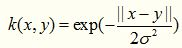
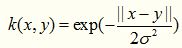
5. Sigmoid Kernel
Sigmoid 核来源于神经网络,现在已经大量应用于深度学习,它是S型的,所以被用作于“激活函数”,表达式:k(x, y) = tanh(axty+c)
核技巧
现在假设我们用映射:
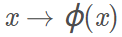
将超平面从原本低维空间的形式变成高维空间的形式:
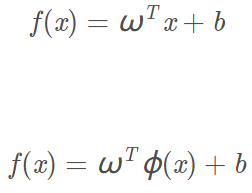
这时我们原本在低维的非线性边界在高维就变成了一个超平面,在高维中数据集变得线性可分了。
但是如果我们先将数据集从低维映射到高维,再去求超平面,由于高维空间中维数要多的多,计算量会变得很大。
核技巧是一种方法,我们用它可以简化计算。它就是用低维空间的内积来求高维空间的内积,省去了先做映射变换再在高维空间中求内积的麻烦。
举例:
以多项式核为例,若样本x有d个分量:
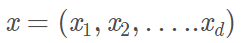
我们做一个二维的多项式变换,将d维扩展:
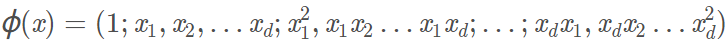
注意上面的式子中有很多重复项可以合并。
我们对变换后的样本作内积:
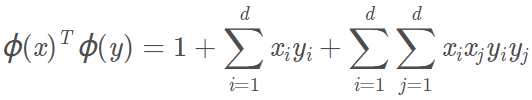
其中,最后一项可以拆成:
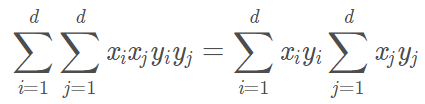
又低维空间的内积可表示为:
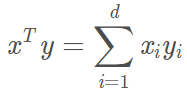
所以上面变换后的多项式内积可以写成:
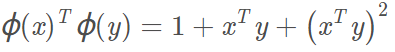
我们就可以不先进行高维变换,再在高维空间做内积,而是直接利用低维空间的内积计算即可。
SVM中的核技巧:
不使用核函数时支持向量机的最优化问题为:
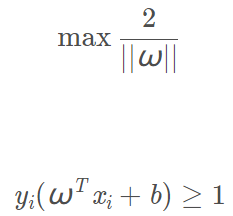
使用核函数将数据集样本从低维映射到高维空间后最优化问题变为:
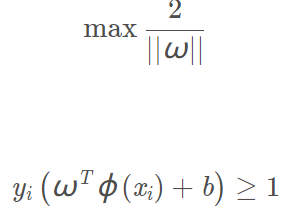
于是我们可以得到类似的对偶问题:
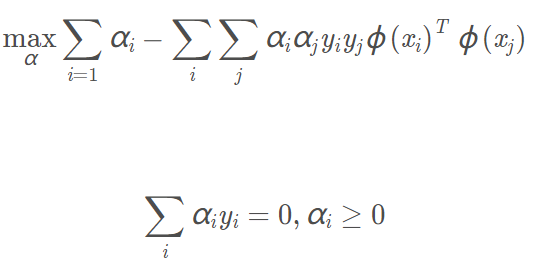
我们在计算其中的

内积时就可以使用核技巧。使用核函数表示对偶问题为:
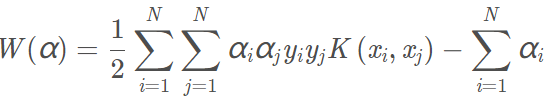
分类决策函数表示为:

SVM算法小结
SVM 算法是一个很优秀的算法,在集成学习和神经网络之类的算法没有表现出优越性能之前,SVM 算法基本占据了分类模型的统治地位。目前在大数据时代的大样本背景下,SVM由于其在大样本时超级大的计算量,热度有所下降,但仍然是一个常用的机器学习算法。
优点:
1) 解决高维特征的分类问题和回归问题很有效,在特征维度大于样本数时依然有很好的
效果。
2) 仅仅使用一部分支持向量来做超平面的决策,无需依赖全部数据。
3) 有大量的核函数可以使用,从而可以很灵活的来解决各种非线性的分类回归问题。
4) 样本量不是海量数据的时候,分类准确率高,泛化能力强。
缺点:
1) 如果特征维度远远大于样本数,则 SVM 表现一般。
2) SVM 在样本量非常大,核函数映射维度非常高时,计算量过大,不太适合使用。
3) 非线性问题的核函数的选择没有通用标准,难以选择一个合适的核函数。
4) SVM 对缺失数据敏感。
深入浅出理解SVM支持向量机算法的更多相关文章
- SVM 支持向量机算法-实战篇
公号:码农充电站pro 主页:https://codeshellme.github.io 上一篇介绍了 SVM 的原理和一些基本概念,本篇来介绍如何用 SVM 处理实际问题. 1,SVM 的实现 SV ...
- SVM(支持向量机)算法
第一步.初步了解SVM 1.0.什么是支持向量机SVM 要明白什么是SVM,便得从分类说起. 分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向 ...
- SVM 支持向量机算法介绍
转自:https://zhuanlan.zhihu.com/p/21932911?refer=baina 参考:http://www.cnblogs.com/LeftNotEasy/archive/2 ...
- SVM支持向量机算法
支持向量机(SVM)是另一类的学习系统,其众多的优点使得他成为最流行的算法之一.其不仅有扎实的理论基础,而且在许多应用领域比大多数其他算法更准确. 1.线性支持向量机:可分情况 根据公式(1)< ...
- 跟我学算法-svm支持向量机算法推导
Svm算法又称为支持向量机,是一种有监督的学习分类算法,目的是为了找到两个支持点,用来使得平面到达这两个支持点的距离最近. 通俗的说:找到一条直线,使得离该线最近的点与该线的距离最远. 我使用手写进行 ...
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- 支持向量机通俗导论(理解SVM的三层境界)
原文链接:http://blog.csdn.net/v_july_v/article/details/7624837 作者:July.pluskid :致谢:白石.JerryLead 出处:结构之法算 ...
- 支持向量机通俗导论(理解SVM的三层境地)
支持向量机通俗导论(理解SVM的三层境地) 作者:July :致谢:pluskid.白石.JerryLead.出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vector ...
- 支持向量机通俗导论(理解SVM的三层境界)(ZT)
支持向量机通俗导论(理解SVM的三层境界) 原文:http://blog.csdn.net/v_JULY_v/article/details/7624837 作者:July .致谢:pluskid.白 ...
随机推荐
- Sliding Window - 题解【单调队列】
题面: An array of size n ≤ 106 is given to you. There is a sliding window of size k which is moving fr ...
- 不care工具,在大数据平台中Hive能自动处理SQL
摘要:有没有更简单的办法,可以直接将SQL运行在大数据平台? 本文分享自华为云社区<Hive执行原理>,作者: JavaEdge . MapReduce简化了大数据编程的难度,使得大数据计 ...
- 广度优先搜索 BFS 学习笔记
广度优先搜索 BFS 学习笔记 引入 广搜是图论中的基础算法之一,属于一种盲目搜寻方法. 广搜需要使用队列来实现,分以下几步: 将起点插入队尾: 取队首 \(u\),如果 $u\to v $ 有一条路 ...
- XCTF练习题---MISC---Ditf
XCTF练习题---MISC---Ditf flag:flag{Oz_4nd_Hir0_lov3_For3ver} 解题步骤: 1.观察题目,下载附件 2.这道题是安恒办的一场比赛题目,下载附件以后是 ...
- 聊聊 node 如何优雅地获取 mac 系统版本
背景 今天突然碰到了一个兼容性需求,需要根据不同 macOS 版本,进行不同的兼容性处理. 没想到看似简单的需求,中间也经历了一番波折,好在最后解决了问题. 在此记录一下解决问题的过程,也方便其他有类 ...
- Android 解析包时出现问题 的解决方案(应用检查更新)
问题描述我们在进行Android开发的时候,一般都会在应用里检测有没有更新,并且从网上下载最新的版本包,覆盖本地的旧版本.在我的项目中,出现了一个问题,就是当安装包下载到本地的时候,产生了" ...
- Redis设计与实现3.1:主从复制
主从复制 这是<Redis设计与实现>系列的文章,系列导航:Redis设计与实现笔记 SLAVEOF 新旧复制功能 旧版复制功能 旧版复制功能的实现为 同步 和 命令传播: 当刚连上Mas ...
- 535. Encode and Decode TinyURL - LeetCode
Question 535. Encode and Decode TinyURL Solution 题目大意:实现长链接加密成短链接,短链接解密成长链接 思路:加密成短链接+key,将长链接按key保存 ...
- 好客租房18-jsx阶段总结
JSX 1jsx是react的核心内容 2jsx是在js代码中写HTML结构,是react中声明式的提现 3使用jsx配合嵌入的js表达式,条件渲染,列表渲染,可以描述任意ui结构 4推荐使用cals ...
- 从头创建一个新的vue项目------用npm|yarn下载vue-cli|vue-ui创建vue
1.下载node或者是nvm node可以直接去node官网下载,http://nodejs.cn/,默认是长期维护的版本 如果想管理node的版本,可以下载nvm.这个是可选的.但是作为一个前端工程 ...