Python数据科学手册-Pandas:累计与分组
简单累计功能
Series sum() 返回一个 统计值
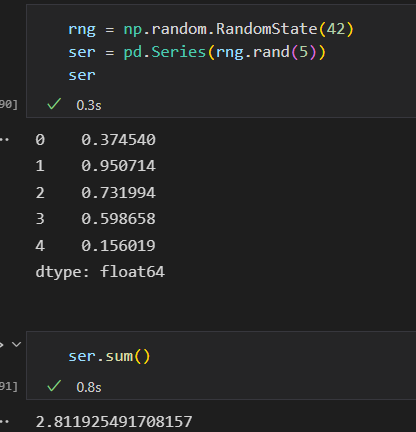
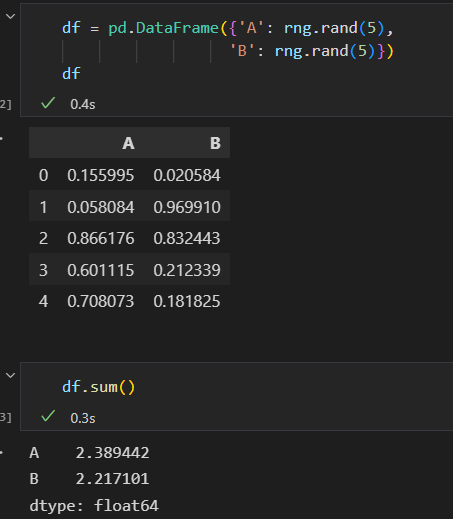
DataFrame sum。默认对每列进行统计
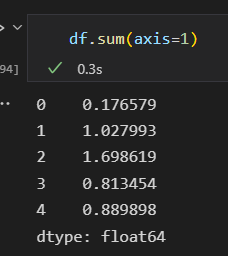
设置axis参数,对每一行 进行统计
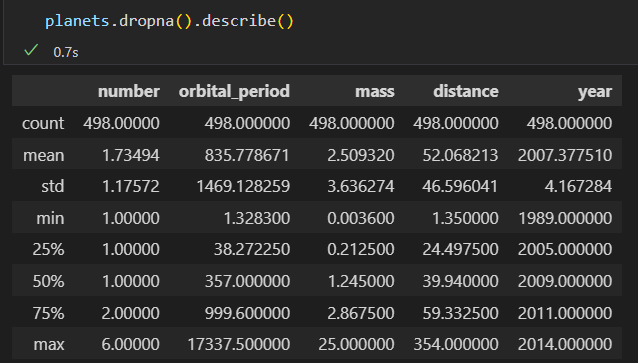
describe()可以计算每一列的若干常用统计值。
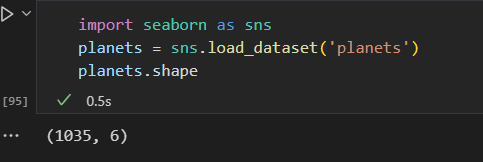
获取seaborn planets数据
github: https://github.com/mwaskom/seaborn-data.git
windows: 放在用户目录下(在线下载卡。超时。)
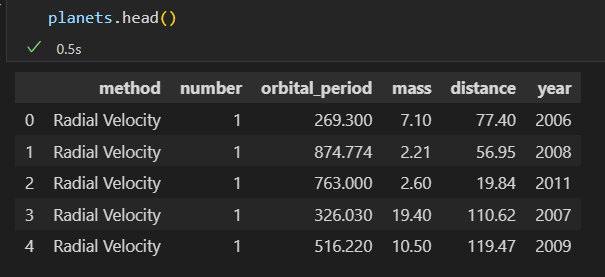
dropna()丢弃有缺失值的行。
Pandas累计方法
| Aggregation | Description |
|---|---|
| count() | Total number of items |
| first(), last() | First and last item |
| mean(), median() | Mean and median |
| min(), max() | Minimum and maximum |
| std(), var() | Standard deviation and variance |
| mad() | Mean absolute deviation |
| prod() | Product of all items |
| sum() | Sum of all items |
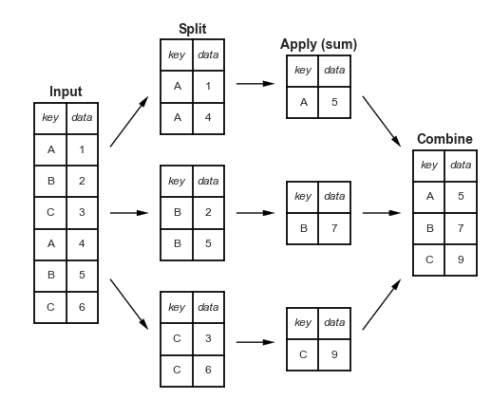
Groupy: 分割、应用和组合
split、 apply、combine
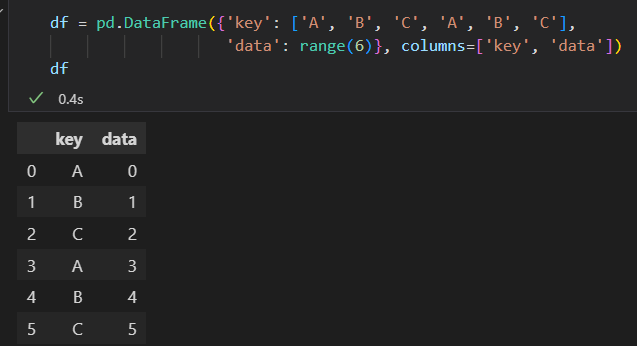
groupby()方法传递参数列名。返回值是个DataFrameGroupBy对象。

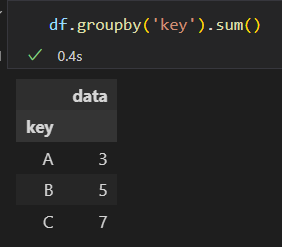
GroupBy对象。
可以看成是DataFrame的集合。
常用的操作:aggregate(累计)、filter(过滤)、transform(转换)、apply(应用)
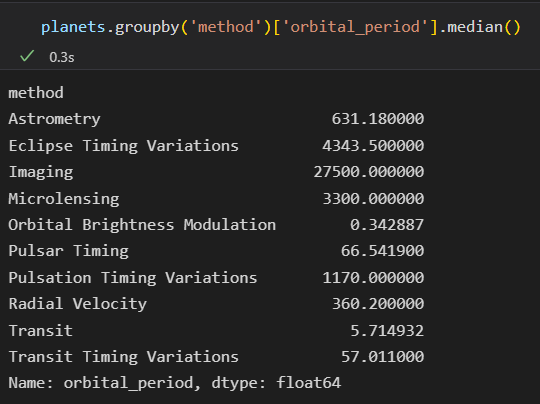
1)按列取值
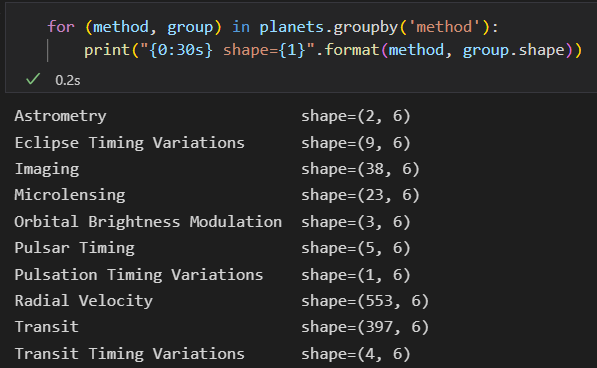
2)按组迭代,返回的每一组都是Series 或 DataFrame
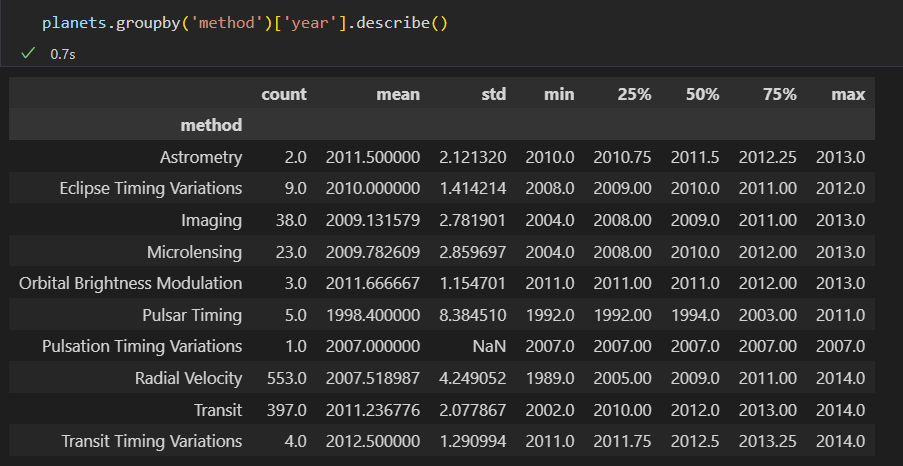
3) 调用方法
累计 过滤 转换 应用
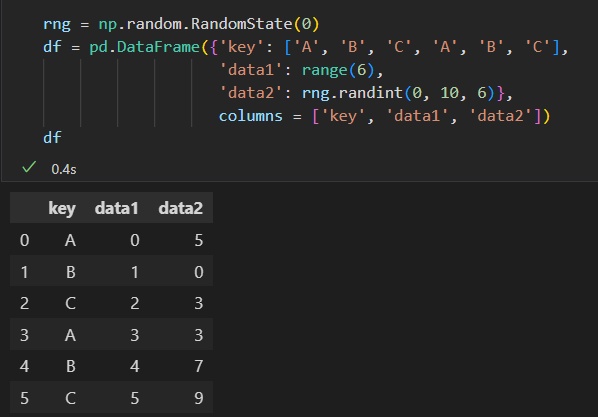
1)累计 aggregate
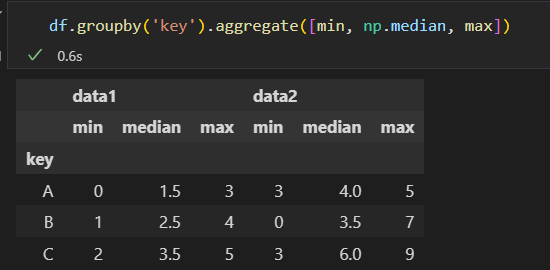
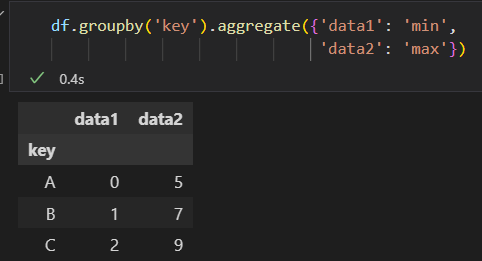
2) 过滤 filter
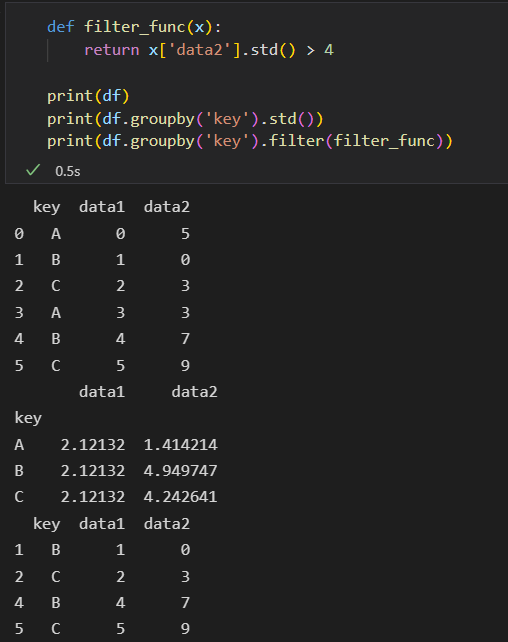
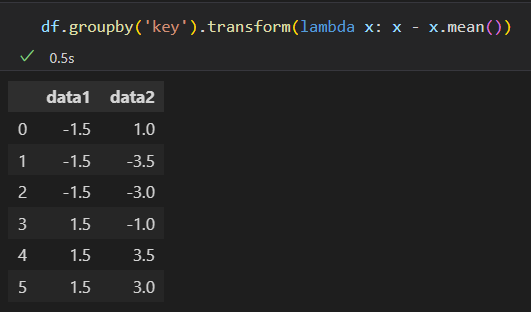
- 转换 transform
累计操作 对组内全量数据缩减的结果。 而 转换 操作 会返回一个新的全量数据
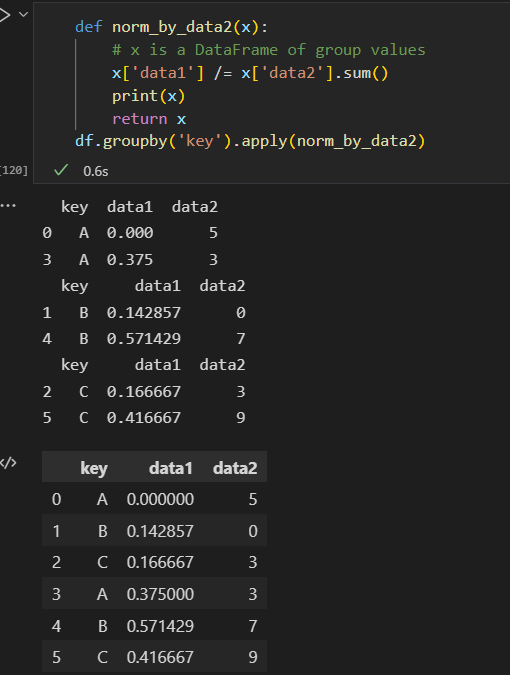
4)apply()
输入一个DataFrame 对象,f返回一个Pandas对象 或 单个数值。 组合操作会 适应返回结果类型。
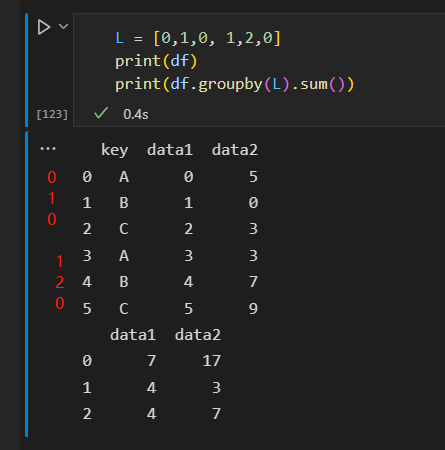
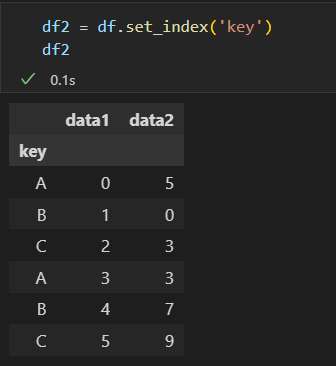
设置分割的键
1)将列表、数组、Series或 索引作为分组键
2)用字典或 Series将索引 映射到 分组名称
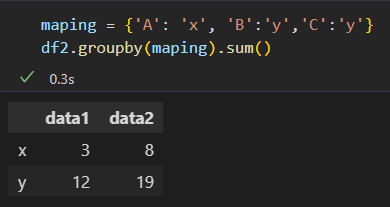
3)任意python函数,函数映射到索引
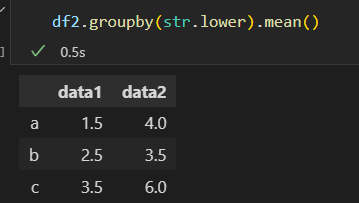
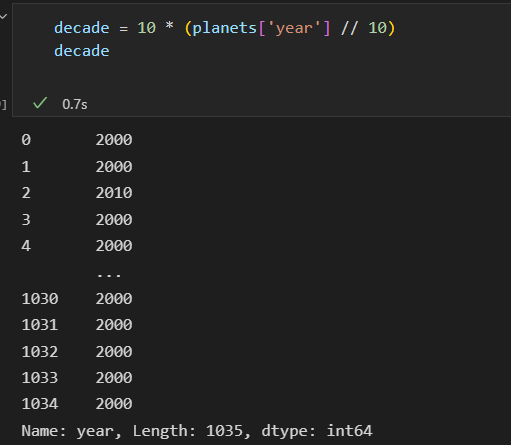
分组案例
以十年为一个时间段。
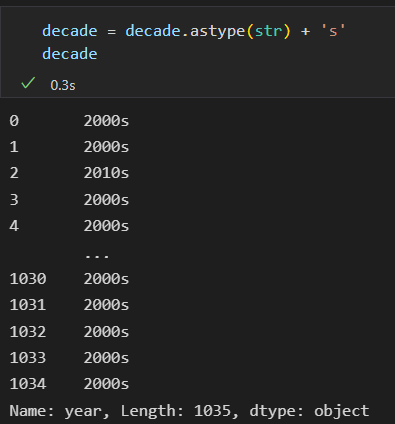
加上s
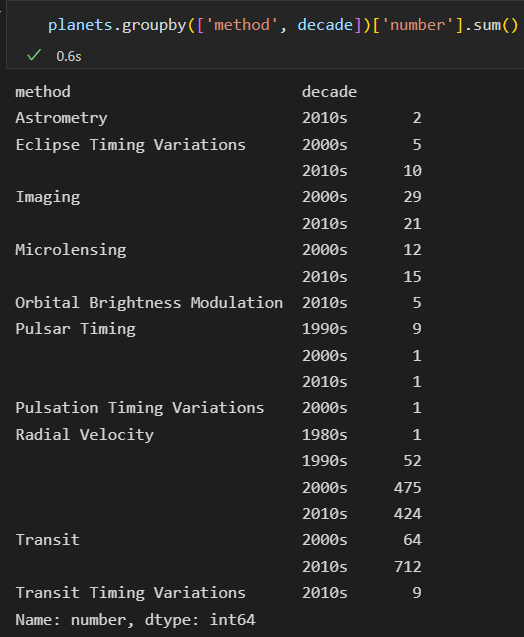
这里 groupby 俩个值。懵逼了。
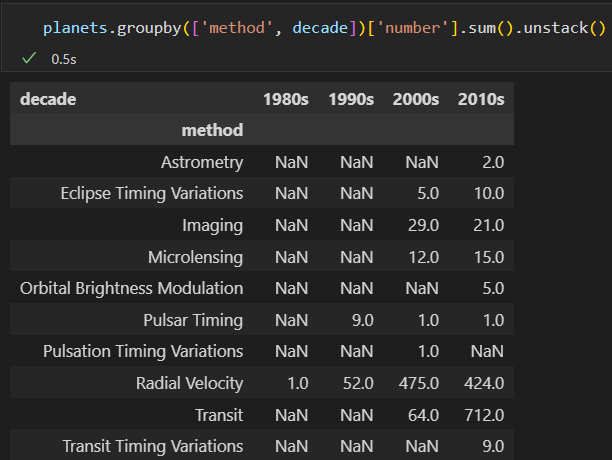
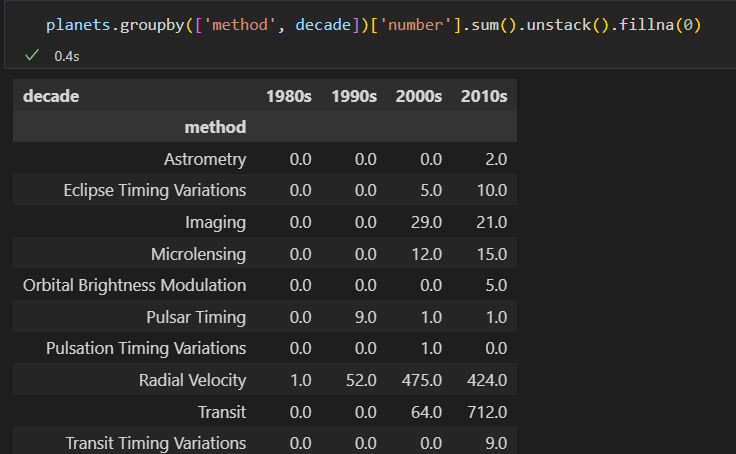
数据透视表
groupby 是探索数据内部的关联性 。
数据透视表: pivottable 是一种类似的操作方法。常见与Excel与类似的表格 应用中。
数据透视表 将每一列 数据作为输入, 输出将数据不断细分 成多个维度累计信息的 二维数据表。
是多维的GroupBy累计操作。
泰坦尼克号 乘客 数据
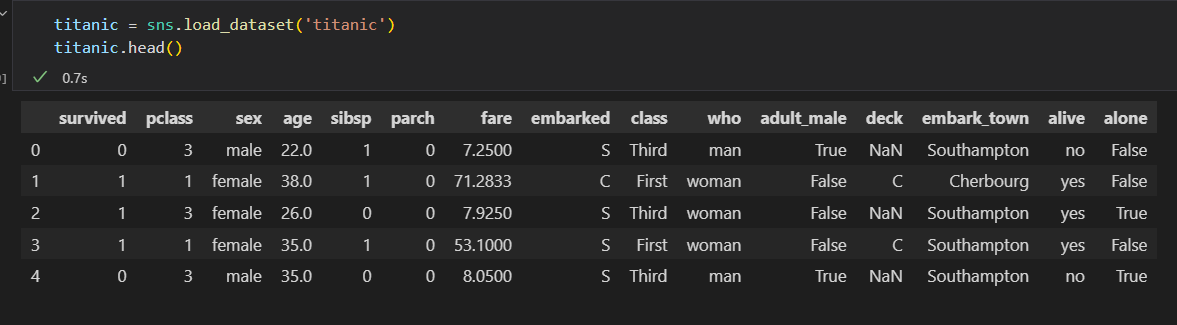
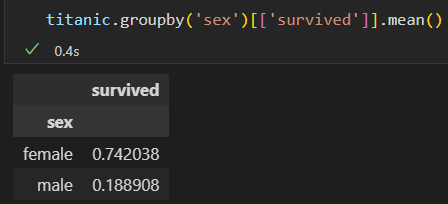
1)按照性别 、最终生还状态 进行分组
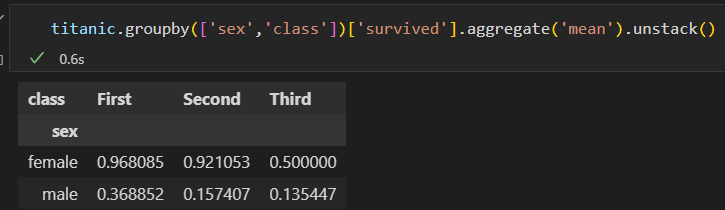
2)进一步 探索,不同性别与船舱 等级的生还情况。
3)上面这个是不是感觉很复杂。使用pivot_table 就会简单
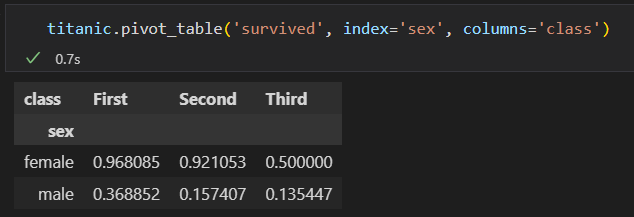
一等舱的女性 生还率最高。 三等舱的生还率 最低
好好努力
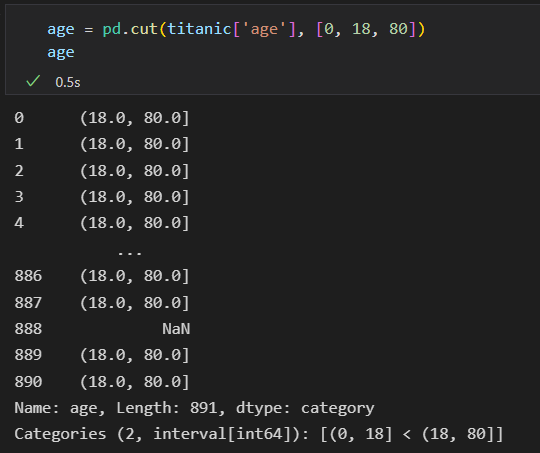
4)再把年龄也加进去。 多级数据透视表
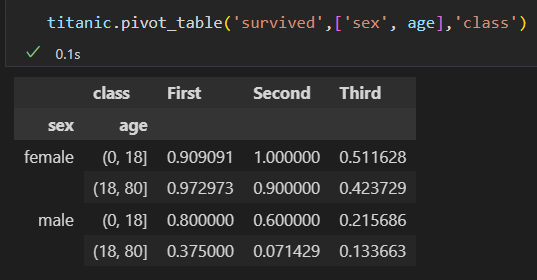
5)其他选项
Python数据科学手册-Pandas:累计与分组的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- Eclipse 想运行一个java文件,结果却运行了另外一个
参考: Eclipse 想运行一个java文件,结果却运行了另外一个_小鹰信息技术服务部-CSDN博客_eclipse怎么运行另一个
- ReentrantLock 公平锁源码 第0篇
ReentrantLock 0 关于ReentrantLock的文章其实写过的,但当时写的感觉不是太好,就给删了,那为啥又要再写一遍呢 最近闲着没事想自己写个锁,然后整了几天出来后不是跑丢线程就是和没 ...
- java---数组(重点概念)
一.什么是数组 程序=算法+数据结构 数据结构:把数据按照某种特定的结构保存,设计一个合理的数据是解决问题的关键: 数组:是一种用于存储多个相同类型数据类型 的存储模型: 数组的特定结构:相同类型组成 ...
- OneOS家族,LITE版小兄弟诞生了!
号外,号外!OneOS-Lite诞生啦!前有大哥OneOS,以及一众优秀的RTOS,正所谓珠玉在前,我很难啊.但我可不能怂,大哥叫小O,我就叫小L,站在大哥的肩上,小小L也有发光发热的机会. 小L代码 ...
- Pytorch分布式训练
用单机单卡训练模型的时代已经过去,单机多卡已经成为主流配置.如何最大化发挥多卡的作用呢?本文介绍Pytorch中的DistributedDataParallel方法. 1. DataParallel ...
- [javaweb]javaweb中HttpServletResponse实现文件下载,验证码和请求重定向功能
HttpServletResponse web服务器接受到客户端的http请求之后,针对这个请求,分别创建一个代表请求的httpServletRequest和代表响应的HttpServletRespo ...
- Running Median_via牛客网
题目 链接:https://ac.nowcoder.com/acm/contest/28886/1002 来源:牛客网 时间限制:C/C++ 5秒,其他语言10秒 空间限制:C/C++ 65536K, ...
- 技术分享|MySQL caching_sha2_password认证异常问题分析
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 0. 导读 相同的账号.密码,手动客户端连接可以成功,通过MySQL Conne ...
- gitpod.io,云端开发调试工具。
gitpod,一款在线开发调试工具,使用它你可以在网页上直接开发软件项目了. 比如你的项目仓库在github上,你可以直接在网址的前面添加gitpod.io/#,然后回车就能在网页上使用vscode打 ...
- Dolphin Scheduler 1.2.0 部署参数分析
本文章经授权转载 1 组件介绍 Apache Dolphin Scheduler是一个分布式易扩展的可视化DAG工作流任务调度系统.致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程 ...