Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景
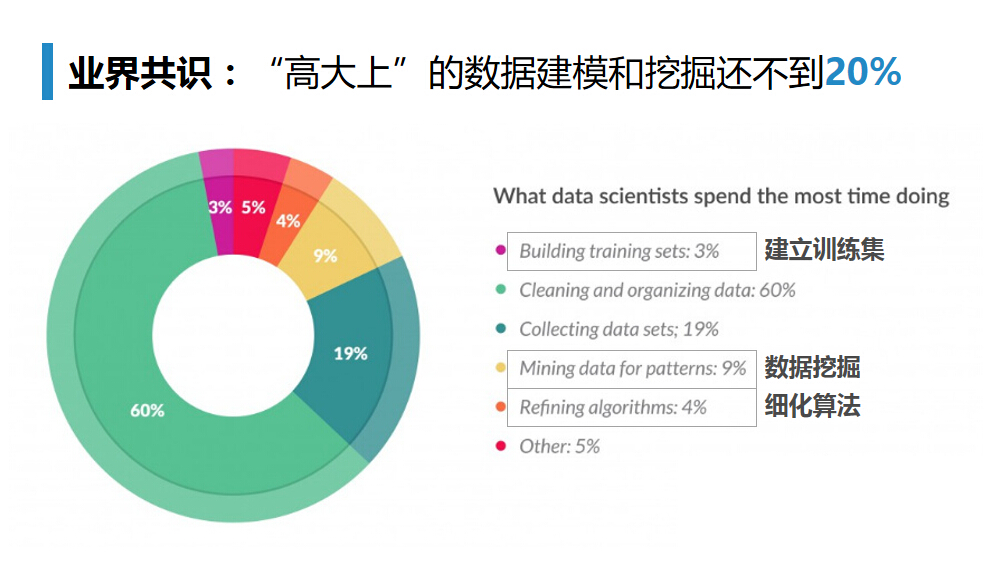
在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作中。
这个项目推出以后受到很大关注,因为开放源码,大家可以在现成源码基础上进一步开发。然而,Python3和Python2是有区别的,《Python即时网络爬虫项目: 内容提取器的定义》 一文的源码无法在Python2.7下使用,本文将发布一个Python2.7的内容提取器。
2. 解决方案
为了解决这个问题,我们把影响通用性和工作效率的提取器隔离出来,描述了如下的数据处理流程图:
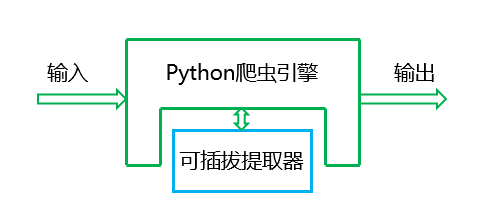
图中“可插拔提取器”必须很强的模块化,那么关键的接口有:
- 标准化的输入:以标准的HTML DOM对象为输入
- 标准化的内容提取:使用标准的xslt模板提取网页内容
- 标准化的输出:以标准的XML格式输出从网页上提取到的内容
- 明确的提取器插拔接口:提取器是一个明确定义的类,通过类方法与爬虫引擎模块交互
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义成一个类: GsExtractor
适用python2.7的源代码文件及其说明文档请从 github 下载
使用模式是这样的:
- 实例化一个GsExtractor对象
- 为这个对象设定xslt提取器,相当于把这个对象配置好(使用三类setXXX()方法)
- 把html dom输入给它,就能获得xml输出(使用extract()方法)
下面是这个GsExtractor类的源代码(适用于Python2.7)

4. 用法示例
下面是一个示例程序,演示怎样使用GsExtractor类提取豆瓣讨论组话题。本示例有如下特征:
- 提取器的内容通过GooSeeker平台上的api获得
- 保存结果文件到当前文件夹
下面是源代码,都可从 github 下载

提取结果如下图所示:

5. 接下来阅读
本文已经说明了提取器的价值和用法,但是没有说怎样生成它,只有快速生成提取器才能达到节省开发者时间的目的,这个问题将在其他文章讲解,请看《1分钟快速生成用于网页内容提取的xslt模板》
6. 集搜客GooSeeker开源代码下载源
1. GooSeeker开源Python网络爬虫GitHub源
7. 文档修改历史
2016-08-05:V1.0,Python2.7下的内容提取器类首次发布
Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)的更多相关文章
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
- API例子:用Java/JavaScript下载内容提取器
1,引言 本文讲解怎样用Java和JavaScript使用 GooSeeker API 接口下载内容提取器,这是一个示例程序.什么是内容提取器?为什么用这种方式?源自Python即时网络爬虫开源项目: ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
随机推荐
- Jasper_dataSource_CSV data source config
(1) open eclipse Repository Explorer Window->Show View->Other-> Repository Explorer-> ...
- Blogger建立新文章 - Blog透视镜
使用Blogger,建立好Blog部落格之后,接着就是建立新文章,它是Blog部落格的灵魂,先从简单开始,来了解建立新文章的标题,文章中如何上传图片,建立卷标,及设定排程日期,定时自动发布等这些功能, ...
- Transposed Matrix
Transposed Matrix In linear algebra, the transpose of a matrix A is another matrix AT (also written ...
- HTTP常见的状态码
状态码的职责是当客户端向服务器端发送请求时,描述返回请求结果.借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了什么错误.RFC2616定义的状态码,由3位数字和原因短信组成.数字中的第一位 ...
- 原生javascript添加引用js文件
function addScriptTag(src) { var script = document.createElement(&qu ...
- Sqrt(x) 解答
Question Implement int sqrt(int x). Compute and return the square root of x. Solution 1 -- O(log n) ...
- [bzoj1003][ZJOI2006][物流运输] (最短路+dp)
Description 物流公司要把一批货物从码头A运到码头B.由于货物量比较大,需要n天才能运完.货物运输过程中一般要转停好几个码头.物流公司通常会设计一条固定的运输路线,以便对整个运输过程实施严格 ...
- servlet核心API的UML图
- [J2EE框架][Debug]
注意xml头部问题 比如在xx-servlet中注意: <mvc:annotation-driven/> <context:component-scan base-package=& ...
- 写一个简易web服务器、ASP.NET核心知识(4)--转载
第一次尝试(V1.0) 1.理论支持 这里主要要说的关于Socket方面的.主要是一个例子,关于Socket如何建立服务端程序的简单的代码. static void Main(string[] arg ...