elasticsearch 分析器 分词器
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
在全文搜索(Fulltext Search)中,词(Term)是一个搜索单元,表示文本中的一个词,标记(Token)表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,其工作流程是:
- 首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
- 过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记,
- 然后,标记过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
- 最终,过滤之后的标记流被存储在倒排索引中;
- ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
可见,分析器扮演的是处理索引数据和查询条件的重要角色。在2.4版本中,ElasticSearch 预定义了7个分析器,并且支持用户根据预定义的字符过滤器,分词器和标记过滤器创建自定义的分析器,以满足用户多样性的文本分析需求。
用户在创建索引时配置索引的分析,通过向ElasticSearch发送请求,在请求body的settings 配置节中设置索引的分析器,例如,为索引配置默认的分析器:
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"default": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
}一,字符过滤器(Char Filter)
字符过滤器对未经分析的文本起作用,作用于被分析的文本字段(该字段的index属性为analyzed),字符过滤器在分词器之前工作,用于从文档的原始文本去除HTML标记(markup),或者把字符“&”转换为单词“and”。ElasticSearch 2.4版本内置3个字符过滤器,分别是:映射字符过滤器(Mapping Char Filter)、HTML标记字符过滤器(HTML Strip Char Filter)和模式替换字符过滤器(Pattern Replace Char Filter)。
1,映射字符过滤器
映射字符过滤器,类型是mapping,需要建立一个查找字符和替换字符的映射(Mapping),过滤器根据映射把文本中的字符替换成指定的字符。
PUT /my_index
{
"index" : {
"analysis" : {
"char_filter" : {
"my_mapping" : {
"type" : "mapping",
"mappings" : [
"c# => csharp",
"c++ => cplus"
]
}
},
"analyzer" : {
"custom_with_char_filter" : {
"tokenizer" : "standard",
"char_filter" : ["my_mapping"]
}
}
}
}
}
或
{
"settings": {
"analysis": {
"char_filter": {
"mapping_filter": {
"type": "mapping",
"mappings": [
"c# => csharp",
"c++ => cplus"
]
}
}
}
}
}也可以通过文件载入字符映射表
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"mapping_filter": {
"type": "mapping",
"mappings_path": "mappings.txt"
}
}
}
}
}2,HTML标记字符过滤器
HTML标记字符过滤器,类型是html_strip,用于从原始文本中去除HTML标记,例如“<a>”就会变成“a”。
3,模式替换字符过滤器
模式替换字符过滤器,类型是pattern_replace,它使用正则表达式(Regular Expression)匹配字符,把匹配到的字符替换为指定的替换字符串。
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}pattern参数:指定Java正则表达式;
replacement参数:指定替换字符串,把正则表达式匹配的字符串替换为replacement参数指定的字符串;
二,分词器(Tokenizer)
分词器在字符过滤器之后工作,用于把文本分割成多个标记(Token),一个标记基本上是词加上一些额外信息,分词器的处理结果是标记流,它是一个接一个的标记,准备被过滤器处理。ElasticSearch 2.4版本内置很多分词器,本节简单介绍常用的分词器。
1,标准分词器(Standard Tokenizer)
标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词。
2,字母分词器(Letter Tokenizer)
字符分词器类型是letter,在非字母位置上分割文本,这就是说,根据相邻的词之间是否存在非字母(例如空格,逗号等)的字符,对文本进行分词,对大多数欧洲语言非常有用。
3,空格分词器(Whitespace Tokenizer)
空格分词类型是whitespace,在空格处分割文本
4,小写分词器(Lowercase Tokenizer)
小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
5,经典分词器(Classic Tokenizer)
经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好。
三,标记过滤器(Token Filter)
分析器包含零个或多个标记过滤器,标记过滤器在分词器之后工作,用来处理标记流中的标记。标记过滤从分词器中接收标记流,能够删除标记,转换标记,或添加标记。ElasticSearch 2.4版本内置很多标记过滤器,本节简单介绍常用的过滤器。
1,小写标记过滤器(Lowercase)
类型是lowercase,用于把标记转换为小写形式,通过language参数指定语言,小写标记过滤器支持的语言有:Greek, Irish, and Turkish
PUT index
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": [],
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"type": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
}参考:https://www.elastic.co/guide/en/elasticsearch/reference/6.0/normalizer.html
2,停用词标记过滤器(Stopwords)
类型是stop,用于从标记流中移除停用词。参数stopwords用于指定停用词,ElasticSearch 2.4版本提供的预定义的停用词列表:预定义的英语停用词是_english_,使用预定义的英语停用词列表是 “stopwords” :"_english_"
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_stop": {
"type": "stop",
"stopwords": ["and", "is", "the"]
}
}
}
}
}3,词干过滤器(Stemmer)
类型是stemmer,用于把词转换为其词根形式存储在倒排索引,能够减少标记。
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "standard",
"filter" : ["standard", "lowercase", "my_stemmer"]
}
},
"filter" : {
"my_stemmer" : {
"type" : "stemmer",
"name" : "english"
}
}
}
}
}4,同义词过滤器(Synonym)
类型是synonym,在分析阶段,基于同义词规则,把词转换为其同义词存储在倒排索引中
{
"index" : {
"analysis" : {
"analyzer" : {
"synonym" : {
"tokenizer" : "whitespace",
"filter" : ["synonym"]
}
},
"filter" : {
"synonym" : {
"type" : "synonym",
"synonyms_path" : "analysis/synonym.txt"
}
}
}
}
}同义词文件的格式示例:
# Blank lines and lines starting with pound are comments.
# Explicit mappings match any token sequence on the LHS of "=>"
# and replace with all alternatives on the RHS. These types of mappings
# ignore the expand parameter in the schema.
# Examples:
i-pod, i pod => ipod,
sea biscuit, sea biscit => seabiscuit
# Equivalent synonyms may be separated with commas and give
# no explicit mapping. In this case the mapping behavior will
# be taken from the expand parameter in the schema. This allows
# the same synonym file to be used in different synonym handling strategies.
# Examples:
ipod, i-pod, i pod
foozball , foosball
universe , cosmos
# If expand==true, "ipod, i-pod, i pod" is equivalent
# to the explicit mapping:
ipod, i-pod, i pod => ipod, i-pod, i pod
# If expand==false, "ipod, i-pod, i pod" is equivalent
# to the explicit mapping:
ipod, i-pod, i pod => ipod
# Multiple synonym mapping entries are merged.
foo => foo bar
foo => baz
# is equivalent to
foo => foo bar, baz四,系统预定义的分析器
在创建索引映射时引用分析器,如果没有定义分析器,那么ElasticSearch将使用默认的分析器,用户可以通过API设置默认的分析器。
default 逻辑名称用于配置在索引和搜索时使用的分析器,default_search 逻辑名称用于配置在搜索时使用的分析器。
index :
analysis :
analyzer :
default :
tokenizer : keyword1,标准分析器(Standard)
分析器类型是standard,由标准分词器(Standard Tokenizer),标准标记过滤器(Standard Token Filter),小写标记过滤器(Lower Case Token Filter)和停用词标记过滤器(Stopwords Token Filter)组成。参数stopwords用于初始化停用词列表,默认是空的。
2,简单分析器(Simple)
分析器类型是simple,实际上是小写标记分词器(Lower Case Tokenizer),在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
3,空格分析器(Whitespace)
分析器类型是whitespace,实际上是空格分词器(Whitespace Tokenizer)。
4,停用词分析器(Stopwords)
分析器类型是stop,由小写分词器(Lower Case Tokenizer)和停用词标记过滤器(Stop Token Filter)构成,配置参数stopwords 或 stopwords_path指定停用词列表。
5,雪球分析器(Snowball)
分析器类型是snowball,由标准分词器(Standard Tokenizer),标准过滤器(Standard Filter),小写过滤器(Lowercase Filter),停用词过滤器(Stop Filter)和雪球过滤器(Snowball Filter)构成。参数language用于指定语言。
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"type" : "snowball",
"language" : "English"
}
}
}
}
}6,自定义分析器
ES内置了很多Analyzer, 还有很多第三方的Analyzer插件, 比如一些处理中文的Analyzer(中文分词)。
analyzer、 tokenizer、 filter可以在elasticsearch.yml 配置, 下面是配置例子
分析器类型是custom,允许用户定制分析器。参数tokenizer 用于指定分词器,filter用于指定过滤器,char_filter用于指定字符过滤器。
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myTokenFilter2]
char_filter : [my_html]
position_increment_gap: 256
tokenizer :
myTokenizer1 :
type : standard
max_token_length : 900
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myTokenFilter2 :
type : length
min : 0
max : 2000
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead : 1024PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "& => and "]
}},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}
}
}参照:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html
https://www.jianshu.com/p/5b6cd1165383
https://www.biaodianfu.com/elasticsearch-install-chinese-segmenter-plugin.html
https://www.cnblogs.com/qindongliang/p/4989525.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
五,查询分析
在分析(_ayalyze)端点上执行分析查询,用于对查询参数进行分析,并返回分析的结果
1,使用默认的分析器执行查询分析
例如,在索引ebrite上执行分析查询,分析字符“After School”,从返回的结果中,可以看到两个标记(Token):“after”和“school”,类型(type)是字符数字类型(<ALPHANUM>),偏移量(offset)从1开始计数,位置(position)从0开始计数。
POST myindex/_analyze -d
"After School"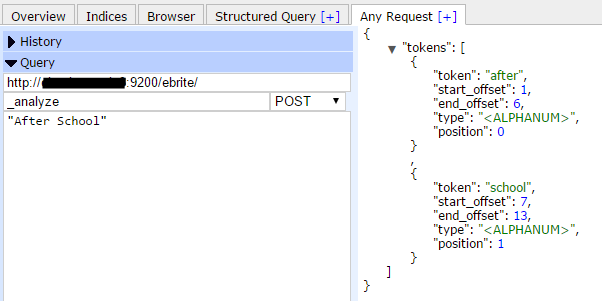
2,指定分析器
POST myindex/_analyze?analyzer=standard -d
"After School"
3,指定分词器和过滤器
POST myindex/_analyze?tokenizer=standard&filters=lowercase -d
"After School"4,在特定的字段上执行分析查询
POST myindex/_analyze?field=doc_field&tokenizer=standard&filters=lowercase -d
"After School"附,在创建索引时,指定默认的分析器
示例代码,使用PUT动词,在创建索引时指定默认的分析器,ElasticSearch引擎在索引文档时,使用默认的分析器对index属性为analyzed的文本字段执行分析操作,而非分析字段,将不会应用分析操作。
{
"settings":{
"number_of_shards":5,
"number_of_replicas":0,
"index":{
"analysis":{
"analyzer":{
"default":{
"type":"standard"
,"stopwords":"_english_"
}
}
}
}
},
"mappings":{
"events":{
"dynamic":"false",
"properties":{
"eventid":{
"type":"long",
"store":false,
"index":"not_analyzed"
},
"eventname":{
"type":"string",
"store":false,
"index":"analyzed",
"fields":{
"raw":{
"type":"string",
"store":false,
"index":"not_analyzed"
}
}
}
}
}
}
}参考文档:
Elasticsearch: Analyzing Text with the Analyze API
Elasticsearch: The Definitive Guide [2.x] » Dealing with Human Language
Elasticsearch Reference [2.4] » Analysis
elasticsearch 分析器 分词器的更多相关文章
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
- elasticsearch中文分词器ik-analyzer安装
前面我们介绍了Centos安装elasticsearch 6.4.2 教程,elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,别急,已经有大拿把中文分词器做好了, ...
- 【分词器及自定义】Elasticsearch中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文”北京大学”来查询结果es将其分拆为”北”,”京”,”大”,”学”四个汉字,这显然不符合我的预期.这是因为Es默认的是英文分词器我需要为 ...
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- ElasticSearch中分词器组件配置详解
首先要明确一点,ElasticSearch是基于Lucene的,它的很多基础性组件,都是由Apache Lucene提供的,而es则提供了更高层次的封装以及分布式方面的增强与扩展. 所以要想熟练的掌握 ...
随机推荐
- java插件提示安全设定高,不能加载解决方法
当不可信小应用程序或应用程序在 Web 浏览器中运行时,我应当如何控制? 本文适用于: Java 版本: 7.0, 8.0 通过 Java 控制面板设置安全级别 在 Java 控制面板中,单击 Sec ...
- java ArrayList的几种方法使用
package java06; import java.util.ArrayList; /* ArrayList的常用的几个方法: public boolean add(E e) : 向集合汇总添加元 ...
- springBoot02- 配置文件读取测试
1.照例登陆http://start.spring.io/ ,改个项目名(Artifact),然后下载导入Eclipse 2. 项目结构如下, 在pom中添加web依赖(不添加,就找不到RestCon ...
- Windows系统启动iis方法详解
很多网友一般都用Windows 系统自带的iis服务器来配置web网站,在本地进行调试和修改后才正式上线.虽说操作不难,但是小白来说却无从下手,很多人根本不知道iss在哪,怎么启动,更谈不上配置或者其 ...
- POJ 3348 Cows (凸包模板+凸包面积)
Description Your friend to the south is interested in building fences and turning plowshares into sw ...
- chromedriver与chrome版本映射表(更新至v2.46)
chromedriver版本 支持的Chrome版本 v2.46 v71-73 v2.45 v70-72 v2.44 v69-71 v2.43 v69-71 v2.42 v68-70 v2.41 v6 ...
- python使用开源图片识别第三方库tesseract
详细安装博客:https://blog.csdn.net/luanyongli/article/details/81385284 第一步tesseract-ocr的安装如果不会请参照:https:// ...
- 20180914-Java实例03
Java 实例 – 字符串性能比较测试 以下实例演示了通过两种方式创建字符串,并测试其性能: // StringComparePerformance.java 文件 public class Stri ...
- CMMI模型
CMMI的成熟度级别 初始级(过程不可预测,管理和控制差,是反应式的)管理级(过程处于项目级,经常是反应式的)定义级(过程已经提升到组织级(OSSP))定量管理级(对过程进行度量,并进行统计控制)优化 ...
- python中的装饰器基本理论
装饰器 : 本质上 是一个 函数 原则 : 1,不修改原函数的源代码 2,不修改原函数的调用方式. 装饰器的知识储备 装饰器 = 高阶函数 + 函数嵌套 +闭包 我的理解是,函数名也是一个变量,将函数 ...