Python每日一题 008
题目
基于多线程的网络爬虫项目,爬取该站点http://www.tvtv.hk 的电视剧收视率排行榜
分析
robots.txt
User-agent: Yisouspider
Disallow: /wp-admin
User-agent: ChinasoSpider
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: YandexBot
Disallow: /
一级URL:http://www.tvtv.hk/archives/category/dianshiju/page/1
二级URL格式:http://www.tvtv.hk/archives/8078.html
从一级URL页面中获取二级URL
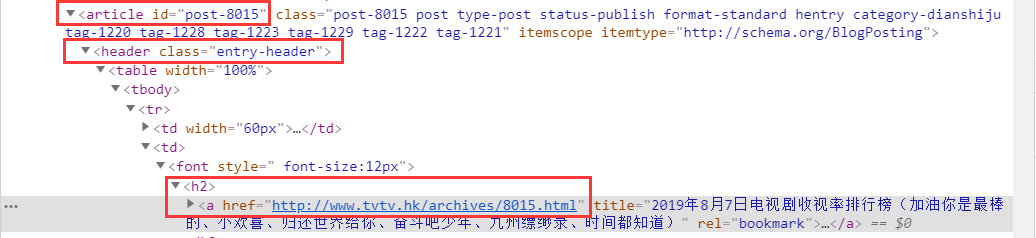
分析二级URL页面下的内容获取数据:

代码
# coding:"utf-8"
import urllib.request
from bs4 import BeautifulSoup
import re
# 爬取网页内容
def download(url):
print("正在爬取:", url)
try:
html = urllib.request.urlopen(url).read()
html = BeautifulSoup(html, 'lxml')
except urllib.request.URLError as e:
print("爬取错误:", e.reason)
html = None
return html
# 获取下一级网页中的URL
def find_url(page, tag):
page = str(page.find_all(tag))
url_list = re.findall('<a href="(.*?)" rel="bookmark"', page)
return url_list
# 爬取收视数据
def get_content(url_list):
word_data = []
for i in url_list:
html = download(i)
contents = html.find_all('p')
word_data.extend(re.findall('<p>(.*?)</p>, <p>', str(contents)))
return word_data
# 爬取图片
def img_data(url_list):
img_src = []
for j in url_list:
html = download(j)
contents = html.find_all('p')
img_src.extend(re.findall('src="(.*?)"/></p>', str(contents)))
return img_src
def write_content_tofile(filename1, filename2):
# 保存文本内容
with open(filename1, 'w+', encoding='utf-8') as f1:
data = get_content(url_list)
for i in data:
f1.write(i + "\n")
# 保存图片
img = img_data(url_list)
for j in range(len(img)):
print('正在下载第'+str(j+1)+'张图片')
path = str(j+1)
with open(filename2 + path + '.jpg', 'wb') as f2:
image_data = urllib.request.urlopen(img[j]).read()
f2.write(image_data)
if __name__ == "__main__":
url = "http://www.tvtv.hk/archives/category/dianshiju/page/1"
filename1 = "E:\\1.txt"
filename2 = "E:\\img\\"
page = download(url)
url_list = find_url(page, 'h2')
write_content_tofile(filename1, filename2)
暂时只是爬取单个页面的内容,后续更新多线程以及批量爬取!
Python每日一题 008的更多相关文章
- Python:每日一题008
题目: 判断101-200之间有多少个素数,并输出所有素数. 程序分析: 判断素数的方法:用一个数分别去除2到sqrt(这个数),如果能被整除,则表明此数不是素数,反之是素数. 个人思路及代码: li ...
- Python每日一题 004
将 0001 题生成的 200 个激活码(或者优惠券)保存到 Redis 非关系型数据库中. 代码 import redis import uuid # 创建实例 r=redis.Redis(&quo ...
- Python每日一题 003
将 002 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中. 代码 import pymysql import uuid def get_id(): for i in ra ...
- Python每日一题 002
做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)? 在此生成由数字,字母组成的20位字 ...
- Python每日一题 009
题目 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码.包括空行和注释,但是要分别列出来. 代码 参照网络上代码 # coding: utf-8 import os import re # ...
- Python每日一题 007
题目 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词. 很难客观的说每篇日记中最重要的词是什么,所以在这里就仅仅是将每篇日记中出 ...
- Python每日一题 006
题目 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小. 如果只是单纯的通过将图片缩放到iPhone5分辨率大小,显然最后呈现出来的效果会很糟糕.所以等比例缩放到长( ...
- Python每日一题 005
任一个英文的纯文本文件,统计其中的单词出现的个数. 代码 # coding:utf-8 import re def get_word(filename): fp=open(filename," ...
- Python每日一题 001
Github地址:https://github.com/Yixiaohan/show-me-the-code Talk is Cheap, show me the code. --Linus Torv ...
随机推荐
- http_load(基于linux平台的一种性能测试工具)
http_load 是运行在linux操作系统上的命令行测试工具, 用来对网站做压力测试.http_load以并行复用的方式运行,用以测试web服务器的吞吐量和负载.但是它不同于大多数压力测试工具, ...
- [CSP-S模拟测试]:字符消除2(hash+KMP)
题目背景 生牛哥终于打通了“字符消除”,可是他又被它的续集难倒了. 题目传送门(内部题52) 输入格式 第一行$n$表示数据组书.接下来每行一个字符串.(只包含大写字母) 输出格式 每组数据输出一个$ ...
- C# foreach和for比较
foreach优点: 1.语句更简洁 2.不需要强制类型转换(比如输出的时候要进行一下乘运算) 3.多维数组遍历只需一行代码 4.不用对索引进行检查 缺点: 1.不能对数据进行修改 参考:https: ...
- 2018-2019-2 《Java程序设计》第10周学习总结
20175319 2018-2019-2 <Java程序设计>第10周学习总结 教材学习内容总结 本周学习<Java程序设计>第十二章java多线程机制: - 进程与线程 程序 ...
- 两个图层一上一下div view
<view class="main"> <view class="user-info"> </view> <view ...
- 关于Http请求Cookie问题
在Http请求中,很多时候我们要设置Cookie和获取返回的Cookie,在这个问题上踩了一个很大的坑,主要是两个问题: 1.不能获取到重定向返回的Cookie: 2.两次请求返回的Cookie是相同 ...
- printf输出各种类型,cout控制输出各式
; char c = 'A'; int *p = &a; char *st = "ahj"; float x = 3.1415926; cout << & ...
- [BOI 2008]Elect 选举
题目描述 N个政党要组成一个联合内阁,每个党都有自己的席位数. 现在希望你找出一种方案,你选中的党的席位数要大于总数的一半,并且联合内阁的席位数越多越好. 对于一个联合内阁,如果某个政党退出后,其它党 ...
- java多态的实现机制
Java提供了编译时多态和运行时多态两种多态机制.前者是通过方法重载实现的,后者是通过方法的覆盖实现的. 在方法覆盖中,子类可以覆盖父类的方法,因此同类的方法会在父类与子类中有着不同的表现形式. 在J ...
- Oracle学习笔记<5>
组函数(多值函数) 数据库中函数的分类:1)单值函数 Single Rows Functions 特点:n条数据参与函数处理,最终得到n条结果.2)多值函数(组函数) Multiple Rows Fu ...